




डीप कॉगिटो के एलएलएम आईडीए का उपयोग करते हुए समान आकार के मॉडल को बेहतर बनाते हैं
सैन फ्रांसिस्को स्थित कंपनी दीप कॉगिटो, ओपन लार्ज लैंग्वेज मॉडल (एलएलएम) की नवीनतम रिलीज के साथ एआई समुदाय में लहरें बना रही है। ये मॉडल, जो 3 बिलियन से 70 बिलियन मापदंडों तक के विभिन्न आकारों में आते हैं, केवल एआई टूल का एक और सेट नहीं हैं; वे इस बात की ओर एक साहसिक कदम हैं कि कंपनी "सामान्य अधीक्षण" कहती है। दीप कॉगिटो का दावा है कि उनके प्रत्येक मॉडल में समान आकार के अग्रणी खुले मॉडल को बेहतर बनाया गया है, जिसमें लामा, दीपसेक और क्यूवेन के अधिकांश मानक बेंचमार्क शामिल हैं। यह काफी दावा है, लेकिन जो भी अधिक प्रभावशाली है, वह यह है कि उनके 70B मॉडल ने कथित तौर पर हाल ही में जारी लामा 4 109B मिक्सचर-ऑफ-एक्सपेर्ट्स (MOE) मॉडल को रेखांकित किया है।
पुनरावृत्त आसवन और प्रवर्धन (आईडीए)
डीप कोगिटो की सफलता के केंद्र में एक नया प्रशिक्षण दृष्टिकोण है जिसे वे पुनरावृत्त आसवन और प्रवर्धन (आईडीए) कहते हैं। इस पद्धति को "पुनरावृत्त आत्म-सुधार का उपयोग करके सामान्य अधीक्षण के लिए एक स्केलेबल और कुशल संरेखण रणनीति के रूप में वर्णित किया गया है।" यह पारंपरिक एलएलएम प्रशिक्षण की सीमाओं को आगे बढ़ाने के लिए डिज़ाइन किया गया है, जहां मॉडल की बुद्धिमत्ता अक्सर बड़े "ओवरसियर" मॉडल या मानव क्यूरेटर द्वारा परिभाषित छत को हिट करती है।
IDA प्रक्रिया दो प्रमुख चरणों के आसपास घूमती है जो बार -बार दोहराई जाती हैं:
- प्रवर्धन: यह कदम मॉडल को बेहतर समाधान या क्षमताओं के साथ आने में मदद करने के लिए अधिक कम्प्यूटेशनल शक्ति का उपयोग करता है, बहुत कुछ उन्नत तर्क तकनीकों की तरह।
- आसवन: यहाँ, मॉडल इन बेहतर क्षमताओं को आंतरिक करता है, अपने मापदंडों को परिष्कृत करता है।
दीप कॉगिटो का तर्क है कि यह एक "सकारात्मक प्रतिक्रिया लूप" बनाता है, जिससे मॉडल की बुद्धिमत्ता को कम्प्यूटेशनल संसाधनों और आईडीए प्रक्रिया की दक्षता के साथ सीधे बढ़ने की अनुमति मिलती है, बजाय एक ओवरसियर की बुद्धिमत्ता द्वारा सीमित होने के।
कंपनी अल्फागो जैसी ऐतिहासिक सफलताओं की ओर इशारा करती है, इस बात पर जोर देती है कि "उन्नत तर्क और पुनरावृत्ति आत्म-सुधार" महत्वपूर्ण थे। आईडीए, वे दावा करते हैं, इन तत्वों को एलएलएम प्रशिक्षण में लाता है। वे आईडीए की दक्षता को भी बताते हैं, यह देखते हुए कि उनकी टीम, हालांकि छोटी थी, इन मॉडलों को लगभग 75 दिनों में विकसित करने में कामयाब रही। जब मानव प्रतिक्रिया (RLHF) से सुदृढीकरण सीखने या बड़े मॉडलों से मानक आसवन जैसे अन्य तरीकों की तुलना में, IDA को बेहतर स्केलेबिलिटी की पेशकश करने के लिए कहा जाता है।
सबूत के रूप में, डीप कॉगिटो ने कहा कि कैसे उनके 70B मॉडल ने Llama 3.3 70B (405B मॉडल से डिस्टिल्ड) और Llama 4 स्काउट 109B (2T पैरामीटर मॉडल से डिस्टिल्ड) दोनों को बेहतर बनाया।
गहरे कोगिटो मॉडल की क्षमता और प्रदर्शन
नए कोगिटो मॉडल, जो लामा और क्यूवेन चौकियों पर निर्माण करते हैं, कोडिंग, फ़ंक्शन कॉलिंग और एजेंटिक अनुप्रयोगों के लिए सिलवाया जाता है। एक स्टैंडआउट सुविधा उनकी दोहरी कार्यक्षमता है: "प्रत्येक मॉडल सीधे जवाब दे सकता है (मानक एलएलएम), या उत्तर देने से पहले आत्म-प्रतिबिंब (जैसे तर्क मॉडल)।" यह दर्पण क्षमताओं को क्लाउड 3.5 जैसे मॉडल में देखा गया है। हालांकि, डीप कॉगिटो में उल्लेख किया गया है कि उन्होंने बहुत लंबी तर्क श्रृंखलाओं पर ध्यान केंद्रित नहीं किया है, तेजी से उत्तरों को प्राथमिकता देते हुए और छोटी श्रृंखलाओं को दूर करने की दक्षता।
कंपनी ने व्यापक बेंचमार्क परिणाम साझा किए हैं, जो अपने कॉगिटो मॉडल की तुलना करते हैं, जो आकार-समतुल्य अत्याधुनिक ओपन मॉडल के खिलाफ प्रत्यक्ष और तर्क दोनों मोड में हैं। MMLU, MMLU-PRO, ARC, GSM8K, और Math जैसे बेंचमार्क की एक श्रृंखला के पार, और विभिन्न मॉडल आकारों (3b, 8b, 14b, 32b, 70b) में, Cogito मॉडल आम तौर पर महत्वपूर्ण प्रदर्शन सुधार दिखाते हैं। उदाहरण के लिए, COGITO 70B मॉडल स्टैंडर्ड मोड में MMLU पर 91.73%, Llama 3.3 70B पर +6.40% सुधार और सोच मोड में 91.00%, DeepSeek R1 डिस्टिल 70B पर +4.40% बढ़ावा देता है। LiveBench स्कोर भी इन लाभों को दर्शाते हैं।
मध्यम आकार की तुलना के लिए यहां 14 बी मॉडल के बेंचमार्क हैं:
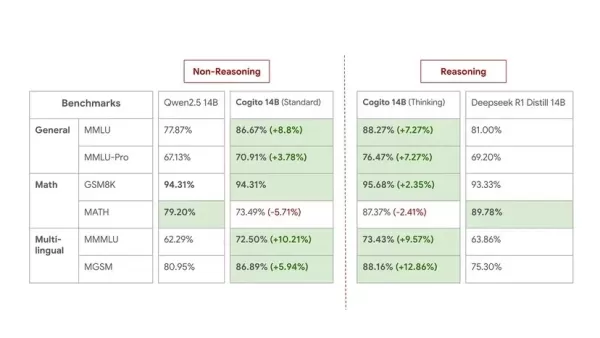
जबकि डीप कोगिटो स्वीकार करता है कि बेंचमार्क वास्तविक दुनिया की उपयोगिता को पूरी तरह से पकड़ नहीं पाते हैं, वे अपने मॉडल के व्यावहारिक प्रदर्शन में आश्वस्त रहते हैं। इस रिलीज को एक पूर्वावलोकन माना जाता है, कंपनी ने कहा कि वे "अभी भी इस स्केलिंग वक्र के शुरुआती चरणों में हैं।" वे आने वाले हफ्तों और महीनों में वर्तमान आकारों के लिए बेहतर चौकियों को जारी करने और बड़े एमओई मॉडल (109 बी, 400 बी, 671 बी) को जारी करने की योजना बनाते हैं। भविष्य के सभी मॉडल भी खुले-स्रोत होंगे।
संबंधित लेख
 AI가 역사적 언어를 모방하는 데 어려움을 겪는다
미국과 캐나다의 연구팀은 ChatGPT와 같은 대형 언어 모델이 광범위하고 비용이 많이 드는 사전 훈련 없이 역사적 관용구를 정확히 재현하는 데 어려움을 겪는다는 것을 발견했다. 이 문제는 AI를 사용해 찰스 디킨스의 미완성 마지막 소설을 완성하는 것과 같은 야심찬 프로젝트를 학술 및 엔터테인먼트 분야에서 실현하기 어렵게 만든다.연구팀은 역사적으로 정확한
억만장자들이 이번 주 AI 업데이트에서 일자리 자동화에 대해 논의하다
안녕하세요, TechCrunch의 AI 뉴스레터에 다시 오신 것을 환영합니다! 아직 구독하지 않으셨다면, 매주 수요일마다 받은 편지함으로 바로 배달받을 수 있도록 여기를 클릭해 구독하세요.지난주에는 잠시 쉬었지만, 그럴만한 이유가 있었습니다—중국의 AI 회사 DeepSeek의 갑작스러운 급부상 덕분에 AI 뉴스 사이클이 뜨거웠습니다. 정신없는 시간이였지만,
NotebookLM 앱 출시: AI 기반 지식 도구
NotebookLM 모바일 출시: 이제 Android와 iOS에서 만나는 AI 연구 보조 도구NotebookLM에 대한 여러분의 뜨거운 반응에 깊이 감사드립니다. 수백만 사용자가 복잡한 정보를 이해하는 필수 도구로 NotebookLM을 선택해주셨습니다. 하지만 가장 많이 받은 요청은 바로 "언제 모바일에서 사용할 수 있나
सूचना (25)
0/200
AI가 역사적 언어를 모방하는 데 어려움을 겪는다
미국과 캐나다의 연구팀은 ChatGPT와 같은 대형 언어 모델이 광범위하고 비용이 많이 드는 사전 훈련 없이 역사적 관용구를 정확히 재현하는 데 어려움을 겪는다는 것을 발견했다. 이 문제는 AI를 사용해 찰스 디킨스의 미완성 마지막 소설을 완성하는 것과 같은 야심찬 프로젝트를 학술 및 엔터테인먼트 분야에서 실현하기 어렵게 만든다.연구팀은 역사적으로 정확한
억만장자들이 이번 주 AI 업데이트에서 일자리 자동화에 대해 논의하다
안녕하세요, TechCrunch의 AI 뉴스레터에 다시 오신 것을 환영합니다! 아직 구독하지 않으셨다면, 매주 수요일마다 받은 편지함으로 바로 배달받을 수 있도록 여기를 클릭해 구독하세요.지난주에는 잠시 쉬었지만, 그럴만한 이유가 있었습니다—중국의 AI 회사 DeepSeek의 갑작스러운 급부상 덕분에 AI 뉴스 사이클이 뜨거웠습니다. 정신없는 시간이였지만,
NotebookLM 앱 출시: AI 기반 지식 도구
NotebookLM 모바일 출시: 이제 Android와 iOS에서 만나는 AI 연구 보조 도구NotebookLM에 대한 여러분의 뜨거운 반응에 깊이 감사드립니다. 수백만 사용자가 복잡한 정보를 이해하는 필수 도구로 NotebookLM을 선택해주셨습니다. 하지만 가장 많이 받은 요청은 바로 "언제 모바일에서 사용할 수 있나
सूचना (25)
0/200
![EricKing]() EricKing
EricKing
 20 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
20 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
Deep Cogito's LLMs are impressive, but the app could use a better UI. It's a bit clunky to navigate through the different model sizes. Still, the performance is top-notch, especially with the IDA tech. Definitely worth a look if you're into AI and want to see what's possible with large language models! 🤖💡


 0
0
![EricRoberts]() EricRoberts
20 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
EricRoberts
20 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡
0
![RichardThomas]() RichardThomas
19 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
RichardThomas
19 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
Os LLMs da Deep Cogito são impressionantes, mas o app poderia ter uma UI melhor. É um pouco desajeitado navegar pelos diferentes tamanhos de modelo. Ainda assim, o desempenho é de primeira linha, especialmente com a tecnologia IDA. Vale a pena dar uma olhada se você gosta de IA e quer ver o que é possível com modelos de linguagem grandes! 🤖💡
0
![WillMitchell]() WillMitchell
19 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
WillMitchell
19 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
Los LLMs de Deep Cogito son impresionantes, pero la app podría tener una mejor UI. Es un poco torpe navegar entre los diferentes tamaños de modelo. Aún así, el rendimiento es de primera, especialmente con la tecnología IDA. Vale la pena echar un vistazo si te interesa la IA y quieres ver lo que es posible con modelos de lenguaje grandes! 🤖💡
0
![GregoryCarter]() GregoryCarter
21 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
GregoryCarter
21 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
0
![JackHernández]() JackHernández
19 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
JackHernández
19 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
Deep Cogito's LLMs are a game-changer! The performance boost over similar-sized models is impressive. I've been using the 70 billion parameter model for my research, and it's like having a super-smart assistant. Only downside? It's a bit resource-heavy. Still, totally worth it! 🚀
0
सैन फ्रांसिस्को स्थित कंपनी दीप कॉगिटो, ओपन लार्ज लैंग्वेज मॉडल (एलएलएम) की नवीनतम रिलीज के साथ एआई समुदाय में लहरें बना रही है। ये मॉडल, जो 3 बिलियन से 70 बिलियन मापदंडों तक के विभिन्न आकारों में आते हैं, केवल एआई टूल का एक और सेट नहीं हैं; वे इस बात की ओर एक साहसिक कदम हैं कि कंपनी "सामान्य अधीक्षण" कहती है। दीप कॉगिटो का दावा है कि उनके प्रत्येक मॉडल में समान आकार के अग्रणी खुले मॉडल को बेहतर बनाया गया है, जिसमें लामा, दीपसेक और क्यूवेन के अधिकांश मानक बेंचमार्क शामिल हैं। यह काफी दावा है, लेकिन जो भी अधिक प्रभावशाली है, वह यह है कि उनके 70B मॉडल ने कथित तौर पर हाल ही में जारी लामा 4 109B मिक्सचर-ऑफ-एक्सपेर्ट्स (MOE) मॉडल को रेखांकित किया है।
पुनरावृत्त आसवन और प्रवर्धन (आईडीए)
डीप कोगिटो की सफलता के केंद्र में एक नया प्रशिक्षण दृष्टिकोण है जिसे वे पुनरावृत्त आसवन और प्रवर्धन (आईडीए) कहते हैं। इस पद्धति को "पुनरावृत्त आत्म-सुधार का उपयोग करके सामान्य अधीक्षण के लिए एक स्केलेबल और कुशल संरेखण रणनीति के रूप में वर्णित किया गया है।" यह पारंपरिक एलएलएम प्रशिक्षण की सीमाओं को आगे बढ़ाने के लिए डिज़ाइन किया गया है, जहां मॉडल की बुद्धिमत्ता अक्सर बड़े "ओवरसियर" मॉडल या मानव क्यूरेटर द्वारा परिभाषित छत को हिट करती है।
IDA प्रक्रिया दो प्रमुख चरणों के आसपास घूमती है जो बार -बार दोहराई जाती हैं:
- प्रवर्धन: यह कदम मॉडल को बेहतर समाधान या क्षमताओं के साथ आने में मदद करने के लिए अधिक कम्प्यूटेशनल शक्ति का उपयोग करता है, बहुत कुछ उन्नत तर्क तकनीकों की तरह।
- आसवन: यहाँ, मॉडल इन बेहतर क्षमताओं को आंतरिक करता है, अपने मापदंडों को परिष्कृत करता है।
दीप कॉगिटो का तर्क है कि यह एक "सकारात्मक प्रतिक्रिया लूप" बनाता है, जिससे मॉडल की बुद्धिमत्ता को कम्प्यूटेशनल संसाधनों और आईडीए प्रक्रिया की दक्षता के साथ सीधे बढ़ने की अनुमति मिलती है, बजाय एक ओवरसियर की बुद्धिमत्ता द्वारा सीमित होने के।
कंपनी अल्फागो जैसी ऐतिहासिक सफलताओं की ओर इशारा करती है, इस बात पर जोर देती है कि "उन्नत तर्क और पुनरावृत्ति आत्म-सुधार" महत्वपूर्ण थे। आईडीए, वे दावा करते हैं, इन तत्वों को एलएलएम प्रशिक्षण में लाता है। वे आईडीए की दक्षता को भी बताते हैं, यह देखते हुए कि उनकी टीम, हालांकि छोटी थी, इन मॉडलों को लगभग 75 दिनों में विकसित करने में कामयाब रही। जब मानव प्रतिक्रिया (RLHF) से सुदृढीकरण सीखने या बड़े मॉडलों से मानक आसवन जैसे अन्य तरीकों की तुलना में, IDA को बेहतर स्केलेबिलिटी की पेशकश करने के लिए कहा जाता है।
सबूत के रूप में, डीप कॉगिटो ने कहा कि कैसे उनके 70B मॉडल ने Llama 3.3 70B (405B मॉडल से डिस्टिल्ड) और Llama 4 स्काउट 109B (2T पैरामीटर मॉडल से डिस्टिल्ड) दोनों को बेहतर बनाया।
गहरे कोगिटो मॉडल की क्षमता और प्रदर्शन
नए कोगिटो मॉडल, जो लामा और क्यूवेन चौकियों पर निर्माण करते हैं, कोडिंग, फ़ंक्शन कॉलिंग और एजेंटिक अनुप्रयोगों के लिए सिलवाया जाता है। एक स्टैंडआउट सुविधा उनकी दोहरी कार्यक्षमता है: "प्रत्येक मॉडल सीधे जवाब दे सकता है (मानक एलएलएम), या उत्तर देने से पहले आत्म-प्रतिबिंब (जैसे तर्क मॉडल)।" यह दर्पण क्षमताओं को क्लाउड 3.5 जैसे मॉडल में देखा गया है। हालांकि, डीप कॉगिटो में उल्लेख किया गया है कि उन्होंने बहुत लंबी तर्क श्रृंखलाओं पर ध्यान केंद्रित नहीं किया है, तेजी से उत्तरों को प्राथमिकता देते हुए और छोटी श्रृंखलाओं को दूर करने की दक्षता।
कंपनी ने व्यापक बेंचमार्क परिणाम साझा किए हैं, जो अपने कॉगिटो मॉडल की तुलना करते हैं, जो आकार-समतुल्य अत्याधुनिक ओपन मॉडल के खिलाफ प्रत्यक्ष और तर्क दोनों मोड में हैं। MMLU, MMLU-PRO, ARC, GSM8K, और Math जैसे बेंचमार्क की एक श्रृंखला के पार, और विभिन्न मॉडल आकारों (3b, 8b, 14b, 32b, 70b) में, Cogito मॉडल आम तौर पर महत्वपूर्ण प्रदर्शन सुधार दिखाते हैं। उदाहरण के लिए, COGITO 70B मॉडल स्टैंडर्ड मोड में MMLU पर 91.73%, Llama 3.3 70B पर +6.40% सुधार और सोच मोड में 91.00%, DeepSeek R1 डिस्टिल 70B पर +4.40% बढ़ावा देता है। LiveBench स्कोर भी इन लाभों को दर्शाते हैं।
मध्यम आकार की तुलना के लिए यहां 14 बी मॉडल के बेंचमार्क हैं:
जबकि डीप कोगिटो स्वीकार करता है कि बेंचमार्क वास्तविक दुनिया की उपयोगिता को पूरी तरह से पकड़ नहीं पाते हैं, वे अपने मॉडल के व्यावहारिक प्रदर्शन में आश्वस्त रहते हैं। इस रिलीज को एक पूर्वावलोकन माना जाता है, कंपनी ने कहा कि वे "अभी भी इस स्केलिंग वक्र के शुरुआती चरणों में हैं।" वे आने वाले हफ्तों और महीनों में वर्तमान आकारों के लिए बेहतर चौकियों को जारी करने और बड़े एमओई मॉडल (109 बी, 400 बी, 671 बी) को जारी करने की योजना बनाते हैं। भविष्य के सभी मॉडल भी खुले-स्रोत होंगे।










 AI가 역사적 언어를 모방하는 데 어려움을 겪는다
미국과 캐나다의 연구팀은 ChatGPT와 같은 대형 언어 모델이 광범위하고 비용이 많이 드는 사전 훈련 없이 역사적 관용구를 정확히 재현하는 데 어려움을 겪는다는 것을 발견했다. 이 문제는 AI를 사용해 찰스 디킨스의 미완성 마지막 소설을 완성하는 것과 같은 야심찬 프로젝트를 학술 및 엔터테인먼트 분야에서 실현하기 어렵게 만든다.연구팀은 역사적으로 정확한
AI가 역사적 언어를 모방하는 데 어려움을 겪는다
미국과 캐나다의 연구팀은 ChatGPT와 같은 대형 언어 모델이 광범위하고 비용이 많이 드는 사전 훈련 없이 역사적 관용구를 정확히 재현하는 데 어려움을 겪는다는 것을 발견했다. 이 문제는 AI를 사용해 찰스 디킨스의 미완성 마지막 소설을 완성하는 것과 같은 야심찬 프로젝트를 학술 및 엔터테인먼트 분야에서 실현하기 어렵게 만든다.연구팀은 역사적으로 정확한
 억만장자들이 이번 주 AI 업데이트에서 일자리 자동화에 대해 논의하다
안녕하세요, TechCrunch의 AI 뉴스레터에 다시 오신 것을 환영합니다! 아직 구독하지 않으셨다면, 매주 수요일마다 받은 편지함으로 바로 배달받을 수 있도록 여기를 클릭해 구독하세요.지난주에는 잠시 쉬었지만, 그럴만한 이유가 있었습니다—중국의 AI 회사 DeepSeek의 갑작스러운 급부상 덕분에 AI 뉴스 사이클이 뜨거웠습니다. 정신없는 시간이였지만,
억만장자들이 이번 주 AI 업데이트에서 일자리 자동화에 대해 논의하다
안녕하세요, TechCrunch의 AI 뉴스레터에 다시 오신 것을 환영합니다! 아직 구독하지 않으셨다면, 매주 수요일마다 받은 편지함으로 바로 배달받을 수 있도록 여기를 클릭해 구독하세요.지난주에는 잠시 쉬었지만, 그럴만한 이유가 있었습니다—중국의 AI 회사 DeepSeek의 갑작스러운 급부상 덕분에 AI 뉴스 사이클이 뜨거웠습니다. 정신없는 시간이였지만,
 NotebookLM 앱 출시: AI 기반 지식 도구
NotebookLM 모바일 출시: 이제 Android와 iOS에서 만나는 AI 연구 보조 도구NotebookLM에 대한 여러분의 뜨거운 반응에 깊이 감사드립니다. 수백만 사용자가 복잡한 정보를 이해하는 필수 도구로 NotebookLM을 선택해주셨습니다. 하지만 가장 많이 받은 요청은 바로 "언제 모바일에서 사용할 수 있나
20 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
NotebookLM 앱 출시: AI 기반 지식 도구
NotebookLM 모바일 출시: 이제 Android와 iOS에서 만나는 AI 연구 보조 도구NotebookLM에 대한 여러분의 뜨거운 반응에 깊이 감사드립니다. 수백만 사용자가 복잡한 정보를 이해하는 필수 도구로 NotebookLM을 선택해주셨습니다. 하지만 가장 많이 받은 요청은 바로 "언제 모바일에서 사용할 수 있나
20 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
Deep Cogito's LLMs are impressive, but the app could use a better UI. It's a bit clunky to navigate through the different model sizes. Still, the performance is top-notch, especially with the IDA tech. Definitely worth a look if you're into AI and want to see what's possible with large language models! 🤖💡
0
20 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡
0
19 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
Os LLMs da Deep Cogito são impressionantes, mas o app poderia ter uma UI melhor. É um pouco desajeitado navegar pelos diferentes tamanhos de modelo. Ainda assim, o desempenho é de primeira linha, especialmente com a tecnologia IDA. Vale a pena dar uma olhada se você gosta de IA e quer ver o que é possível com modelos de linguagem grandes! 🤖💡
0
19 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
Los LLMs de Deep Cogito son impresionantes, pero la app podría tener una mejor UI. Es un poco torpe navegar entre los diferentes tamaños de modelo. Aún así, el rendimiento es de primera, especialmente con la tecnología IDA. Vale la pena echar un vistazo si te interesa la IA y quieres ver lo que es posible con modelos de lenguaje grandes! 🤖💡
0
21 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
0
19 अप्रैल 2025 12:00:00 पूर्वाह्न GMT
Deep Cogito's LLMs are a game-changer! The performance boost over similar-sized models is impressive. I've been using the 70 billion parameter model for my research, and it's like having a super-smart assistant. Only downside? It's a bit resource-heavy. Still, totally worth it! 🚀
0













