
















 Maison
MaisonLes LLM de Deep Cogito surpassent les modèles de taille similaire à l'aide d'IDA
Deep Cogito, une entreprise basée à San Francisco, fait des vagues dans la communauté de l'IA avec sa dernière sortie de modèles de langage de grande échelle (LLMs) ouverts. Ces modèles, qui varient en taille de 3 milliards à 70 milliards de paramètres, ne sont pas seulement un nouvel ensemble d'outils d'IA ; ils représentent un pas audacieux vers ce que l'entreprise appelle une "superintelligence générale". Deep Cogito affirme que chacun de leurs modèles surpasse les principaux modèles ouverts de tailles similaires, y compris ceux de LLAMA, DeepSeek et Qwen, dans la plupart des benchmarks standards. C'est une affirmation impressionnante, mais ce qui est encore plus remarquable, c'est que leur modèle 70B aurait surpassé le modèle Llama 4 109B Mixture-of-Experts (MoE) récemment publié.
Distillation et Amplification Itérées (IDA)
Au cœur de la percée de Deep Cogito se trouve une nouvelle approche d'entraînement qu'ils appellent Distillation et Amplification Itérées (IDA). Cette méthode est décrite comme "une stratégie d'alignement évolutive et efficace pour la superintelligence générale utilisant l'auto-amélioration itérative". Elle est conçue pour dépasser les limites de l'entraînement traditionnel des LLMs, où l'intelligence du modèle atteint souvent un plafond défini par des modèles "superviseurs" plus grands ou des curateurs humains.
Le processus IDA repose sur deux étapes clés répétées encore et encore :
- Amplification : Cette étape utilise plus de puissance de calcul pour aider le modèle à trouver de meilleures solutions ou capacités, un peu comme des techniques de raisonnement avancées.
- Distillation : Ici, le modèle internalise ces capacités améliorées, affinant ses paramètres.
Deep Cogito soutient que cela crée une "boucle de rétroaction positive", permettant à l'intelligence du modèle de croître plus directement avec les ressources computationnelles et l'efficacité du processus IDA lui-même, plutôt que d'être limitée par l'intelligence d'un superviseur.
L'entreprise pointe du doigt des succès historiques comme AlphaGo, soulignant que "le raisonnement avancé et l'auto-amélioration itérative" étaient cruciaux. L'IDA, affirment-ils, intègre ces éléments dans l'entraînement des LLMs. Ils vantent également l'efficacité de l'IDA, notant que leur équipe, bien que petite, a réussi à développer ces modèles en seulement environ 75 jours. Comparée à d'autres méthodes comme l'Apprentissage par Renforcement à partir des Retours Humains (RLHF) ou la distillation standard à partir de modèles plus grands, l'IDA est censée offrir une meilleure évolutivité.
Comme preuve, Deep Cogito met en avant la performance de leur modèle 70B, qui surpasse à la fois le Llama 3.3 70B (distillé d'un modèle 405B) et le Llama 4 Scout 109B (distillé d'un modèle de 2T paramètres).
Capacités et Performance des Modèles Deep Cogito
Les nouveaux modèles Cogito, qui s'appuient sur les checkpoints de Llama et Qwen, sont conçus pour le codage, l'appel de fonctions et les applications agentiques. Une caractéristique notable est leur double fonctionnalité : "Chaque modèle peut répondre directement (LLM standard), ou réfléchir avant de répondre (comme les modèles de raisonnement)." Cela reflète des capacités observées dans des modèles comme Claude 3.5. Cependant, Deep Cogito mentionne qu'ils n'ont pas mis l'accent sur des chaînes de raisonnement très longues, privilégiant des réponses plus rapides et l'efficacité de la distillation de chaînes plus courtes.
L'entreprise a partagé des résultats de benchmarks détaillés, comparant leurs modèles Cogito à des modèles ouverts de pointe de taille équivalente en modes direct et de raisonnement. À travers une gamme de benchmarks comme MMLU, MMLU-Pro, ARC, GSM8K et MATH, et à travers différentes tailles de modèles (3B, 8B, 14B, 32B, 70B), les modèles Cogito montrent généralement des améliorations significatives de performance. Par exemple, le modèle Cogito 70B obtient un score de 91,73 % sur MMLU en mode standard, une amélioration de +6,40 % par rapport à Llama 3.3 70B, et 91,00 % en mode réflexion, une augmentation de +4,40 % par rapport à Deepseek R1 Distill 70B. Les scores Livebench reflètent également ces gains.
Voici les benchmarks des modèles 14B pour une comparaison de taille moyenne :
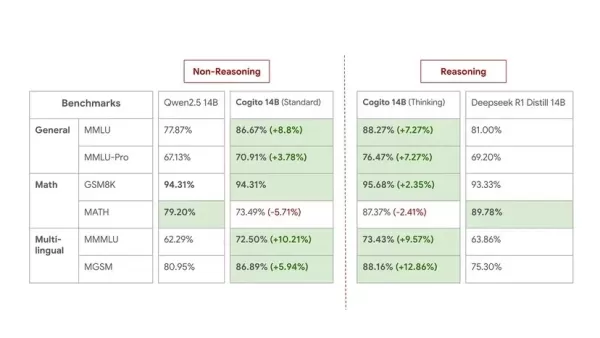
Bien que Deep Cogito reconnaisse que les benchmarks ne capturent pas pleinement l'utilité réelle, ils restent confiants dans la performance pratique de leurs modèles. Cette sortie est considérée comme un aperçu, l'entreprise déclarant qu'ils sont "encore aux premiers stades de cette courbe d'évolutivité". Ils prévoient de publier des checkpoints améliorés pour les tailles actuelles et d'introduire de plus grands modèles MoE (109B, 400B, 671B) dans les semaines et mois à venir. Tous les futurs modèles seront également open-source.
Article connexe
 Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
Barry Diller : la confiance en Sam Altman n'a plus d'importance à l'approche de l'IA générale
Barry Diller, le magnat milliardaire des médias, ne considère pas que Sam Altman, PDG d’OpenAI, soit indigne de confiance, malgré des informations récentes suggérant le contraire. S’exprimant cette se
YouTube étend sa détection des deepfakes par IA aux personnalités politiques, aux responsables gouvernementaux et aux journalistes
Mardi, YouTube a annoncé qu’il étendait sa technologie de détection des deepfakes à un groupe restreint de responsables gouvernementaux, de candidats politiques et de journalistes. Cet outil identifie
Recommandations de sujets spéciaux liés
Entreprise
Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
Barry Diller : la confiance en Sam Altman n'a plus d'importance à l'approche de l'IA générale
Barry Diller, le magnat milliardaire des médias, ne considère pas que Sam Altman, PDG d’OpenAI, soit indigne de confiance, malgré des informations récentes suggérant le contraire. S’exprimant cette se
YouTube étend sa détection des deepfakes par IA aux personnalités politiques, aux responsables gouvernementaux et aux journalistes
Mardi, YouTube a annoncé qu’il étendait sa technologie de détection des deepfakes à un groupe restreint de responsables gouvernementaux, de candidats politiques et de journalistes. Cet outil identifie
Recommandations de sujets spéciaux liés
Entreprise
 Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
 10 outils
10 outils
 xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai
chatbot
Les meilleurs outils d'IA pour apprendre à flirter et à converser : renforcez votre charisme social et votre confiance en vous en temps réel
Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai
code
Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai

 commentaires (29)
commentaires (29)
![FrankMoore]()
看起来这家叫做Deep Cogito的新公司有点门道。IDA架构?之前没听说过这个技术,好奇跟MoE比怎么样。要是能出个小点的模型让大家体验一下就好了,毕竟现在动辄几十B参数量,普通开发者根本玩不起。希望别只是实验室数据漂亮,实际应用打折扣。
![HenryJackson]()
このモデルの性能、ほかの同サイズのモデルより優れてるの?IDAの手法が効いてるのかな。個人的には倫理的な側面も気になるけど、オープンソースなのはすごく良いと思う👍 実際に使ってみたい!
![RoyWhite]()
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
![PaulThomas]()
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
![GregoryCarter]()
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
![EricRoberts]()
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡
Deep Cogito, une entreprise basée à San Francisco, fait des vagues dans la communauté de l'IA avec sa dernière sortie de modèles de langage de grande échelle (LLMs) ouverts. Ces modèles, qui varient en taille de 3 milliards à 70 milliards de paramètres, ne sont pas seulement un nouvel ensemble d'outils d'IA ; ils représentent un pas audacieux vers ce que l'entreprise appelle une "superintelligence générale". Deep Cogito affirme que chacun de leurs modèles surpasse les principaux modèles ouverts de tailles similaires, y compris ceux de LLAMA, DeepSeek et Qwen, dans la plupart des benchmarks standards. C'est une affirmation impressionnante, mais ce qui est encore plus remarquable, c'est que leur modèle 70B aurait surpassé le modèle Llama 4 109B Mixture-of-Experts (MoE) récemment publié.
Distillation et Amplification Itérées (IDA)
Au cœur de la percée de Deep Cogito se trouve une nouvelle approche d'entraînement qu'ils appellent Distillation et Amplification Itérées (IDA). Cette méthode est décrite comme "une stratégie d'alignement évolutive et efficace pour la superintelligence générale utilisant l'auto-amélioration itérative". Elle est conçue pour dépasser les limites de l'entraînement traditionnel des LLMs, où l'intelligence du modèle atteint souvent un plafond défini par des modèles "superviseurs" plus grands ou des curateurs humains.
Le processus IDA repose sur deux étapes clés répétées encore et encore :
- Amplification : Cette étape utilise plus de puissance de calcul pour aider le modèle à trouver de meilleures solutions ou capacités, un peu comme des techniques de raisonnement avancées.
- Distillation : Ici, le modèle internalise ces capacités améliorées, affinant ses paramètres.
Deep Cogito soutient que cela crée une "boucle de rétroaction positive", permettant à l'intelligence du modèle de croître plus directement avec les ressources computationnelles et l'efficacité du processus IDA lui-même, plutôt que d'être limitée par l'intelligence d'un superviseur.
L'entreprise pointe du doigt des succès historiques comme AlphaGo, soulignant que "le raisonnement avancé et l'auto-amélioration itérative" étaient cruciaux. L'IDA, affirment-ils, intègre ces éléments dans l'entraînement des LLMs. Ils vantent également l'efficacité de l'IDA, notant que leur équipe, bien que petite, a réussi à développer ces modèles en seulement environ 75 jours. Comparée à d'autres méthodes comme l'Apprentissage par Renforcement à partir des Retours Humains (RLHF) ou la distillation standard à partir de modèles plus grands, l'IDA est censée offrir une meilleure évolutivité.
Comme preuve, Deep Cogito met en avant la performance de leur modèle 70B, qui surpasse à la fois le Llama 3.3 70B (distillé d'un modèle 405B) et le Llama 4 Scout 109B (distillé d'un modèle de 2T paramètres).
Capacités et Performance des Modèles Deep Cogito
Les nouveaux modèles Cogito, qui s'appuient sur les checkpoints de Llama et Qwen, sont conçus pour le codage, l'appel de fonctions et les applications agentiques. Une caractéristique notable est leur double fonctionnalité : "Chaque modèle peut répondre directement (LLM standard), ou réfléchir avant de répondre (comme les modèles de raisonnement)." Cela reflète des capacités observées dans des modèles comme Claude 3.5. Cependant, Deep Cogito mentionne qu'ils n'ont pas mis l'accent sur des chaînes de raisonnement très longues, privilégiant des réponses plus rapides et l'efficacité de la distillation de chaînes plus courtes.
L'entreprise a partagé des résultats de benchmarks détaillés, comparant leurs modèles Cogito à des modèles ouverts de pointe de taille équivalente en modes direct et de raisonnement. À travers une gamme de benchmarks comme MMLU, MMLU-Pro, ARC, GSM8K et MATH, et à travers différentes tailles de modèles (3B, 8B, 14B, 32B, 70B), les modèles Cogito montrent généralement des améliorations significatives de performance. Par exemple, le modèle Cogito 70B obtient un score de 91,73 % sur MMLU en mode standard, une amélioration de +6,40 % par rapport à Llama 3.3 70B, et 91,00 % en mode réflexion, une augmentation de +4,40 % par rapport à Deepseek R1 Distill 70B. Les scores Livebench reflètent également ces gains.
Voici les benchmarks des modèles 14B pour une comparaison de taille moyenne :
Bien que Deep Cogito reconnaisse que les benchmarks ne capturent pas pleinement l'utilité réelle, ils restent confiants dans la performance pratique de leurs modèles. Cette sortie est considérée comme un aperçu, l'entreprise déclarant qu'ils sont "encore aux premiers stades de cette courbe d'évolutivité". Ils prévoient de publier des checkpoints améliorés pour les tailles actuelles et d'introduire de plus grands modèles MoE (109B, 400B, 671B) dans les semaines et mois à venir. Tous les futurs modèles seront également open-source.









 Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
 Barry Diller : la confiance en Sam Altman n'a plus d'importance à l'approche de l'IA générale
Barry Diller, le magnat milliardaire des médias, ne considère pas que Sam Altman, PDG d’OpenAI, soit indigne de confiance, malgré des informations récentes suggérant le contraire. S’exprimant cette se
Barry Diller : la confiance en Sam Altman n'a plus d'importance à l'approche de l'IA générale
Barry Diller, le magnat milliardaire des médias, ne considère pas que Sam Altman, PDG d’OpenAI, soit indigne de confiance, malgré des informations récentes suggérant le contraire. S’exprimant cette se
 YouTube étend sa détection des deepfakes par IA aux personnalités politiques, aux responsables gouvernementaux et aux journalistes
Mardi, YouTube a annoncé qu’il étendait sa technologie de détection des deepfakes à un groupe restreint de responsables gouvernementaux, de candidats politiques et de journalistes. Cet outil identifie
YouTube étend sa détection des deepfakes par IA aux personnalités politiques, aux responsables gouvernementaux et aux journalistes
Mardi, YouTube a annoncé qu’il étendait sa technologie de détection des deepfakes à un groupe restreint de responsables gouvernementaux, de candidats politiques et de journalistes. Cet outil identifie

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai

Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai

看起来这家叫做Deep Cogito的新公司有点门道。IDA架构?之前没听说过这个技术,好奇跟MoE比怎么样。要是能出个小点的模型让大家体验一下就好了,毕竟现在动辄几十B参数量,普通开发者根本玩不起。希望别只是实验室数据漂亮,实际应用打折扣。
このモデルの性能、ほかの同サイズのモデルより優れてるの?IDAの手法が効いてるのかな。個人的には倫理的な側面も気になるけど、オープンソースなのはすごく良いと思う👍 実際に使ってみたい!
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡













