




Problème du Test de Turing Exposé par le GPT-4.5 d'OpenAI
Le test de Turing, conçu par le légendaire Alan Turing, est depuis longtemps une référence dans le monde de l'intelligence artificielle. Mais clarifions un malentendu dès le départ : réussir le test de Turing ne signifie pas nécessairement qu'une machine "pense" comme un humain. Il s'agit plutôt de convaincre les humains qu'elle l'est.
Des recherches récentes de l'Université de Californie à San Diego ont mis en lumière le dernier modèle d'OpenAI, GPT-4.5. Cette IA peut désormais tromper les humains en leur faisant croire qu'ils discutent avec une autre personne, encore plus efficacement que les humains ne peuvent se convaincre mutuellement de leur humanité. C'est un événement majeur dans le monde de l'IA—c'est comme regarder un tour de magie où l'on connaît le secret, mais qui reste époustouflant.
Preuve d'une AGI ?
Mais voici le hic : même les chercheurs de l'UC San Diego ne sont pas prêts à déclarer que nous avons atteint l'intelligence artificielle générale (AGI) simplement parce qu'un modèle d'IA réussit le test de Turing. L'AGI serait le Graal de l'IA—des machines capables de penser et de traiter l'information comme les humains.
Melanie Mitchell, une spécialiste de l'IA de l'Institut Santa Fe, soutient dans la revue Science que le test de Turing évalue davantage les présomptions humaines que l'intelligence réelle. Bien sûr, une IA peut sembler fluide et convaincante, mais cela ne signifie pas qu'elle est généralement intelligente. C'est comme être doué aux échecs—c'est impressionnant, mais ce n'est pas l'ensemble du tableau.
Le dernier engouement vient d'un article de Cameron Jones et Benjamin Bergen à l'UC San Diego, intitulé "Les grands modèles de langage réussissent le test de Turing", publié sur le serveur de prépublication arXiv. Ils mènent cette expérience depuis des années, avec l'aide d'étudiants de l'UC San Diego, et cela s'inscrit dans une longue lignée de recherches—plus de 800 affirmations et contre-arguments ont été faits sur des ordinateurs passant le test de Turing.
Comment fonctionne le test de Turing
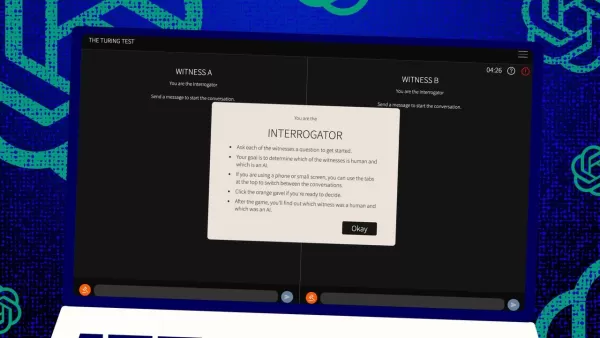
Alors, comment fonctionne ce test ? À l'origine, Turing l'imaginait comme un jeu de messages texte entre un "juge" humain et deux "témoins"—l'un humain, l'autre informatique. Le défi pour les témoins est de convaincre le juge qu'ils sont humains. Le juge sait que l'un est humain, mais ne sait pas lequel, et doit deviner. C'est une configuration à trois qui repose autant sur la perception et la croyance que sur les capacités de l'ordinateur.
Jones et Bergen ont apporté leur propre touche à cette configuration classique, et vous pouvez même l'essayer en ligne, en jouant soit le rôle du juge, soit celui du témoin. Dans leur version, des étudiants de l'UC San Diego ont utilisé une application de chat texte. Certains jouaient le juge, d'autres le témoin humain, tandis que GPT-4.5 prenait le rôle du témoin informatique. Chaque juge discutait simultanément avec un humain et un ordinateur, restant fidèle au format original de Turing.
Pour jouer le témoin informatique, ils ont utilisé différents grands modèles de langage, en leur fournissant des instructions basées sur les défis du juge. GPT-4.5 a été testé avec deux instructions différentes : une avec des informations minimales, et une autre appelée PERSONA, qui incluait des instructions détaillées pour agir comme une personne jeune, introvertie, experte en internet et utilisant de l'argot.
Les résultats
Ils ont également testé trois autres programmes d'IA : le modèle précédent d'OpenAI, GPT-4o ; Llama 3.1 405b de Meta Platforms ; et le chatbot des années 1960, ELIZA. Ils ont inclus ELIZA pour voir si les grands modèles de langage trompaient les humains par hasard ou s'ils étaient réellement meilleurs.
Selon Jones et Bergen, GPT-4.5 a trompé les juges humains en leur faisant croire qu'il était humain dans 73 % des cas—un "taux de réussite" comme ils l'appellent. C'est bien meilleur que les autres modèles, qui ont obtenu entre 21 % et 56 %, même avec des instructions détaillées similaires. Et c'est un bond énorme par rapport au test de l'année dernière sur GPT-4, qui avait un taux de réussite de seulement 54 %, à peine au-dessus du hasard.
Jones et Bergen ont constaté que les juges étaient non seulement trompés par l'IA, mais étaient en réalité plus susceptibles de croire qu'elle était humaine que les véritables participants humains.
Le test est-il vraiment une mesure de l'intelligence ?
Alors, qu'est-ce que cela signifie si les humains ne peuvent pas distinguer un ordinateur d'une personne dans un chat ? La grande question, débattue depuis des décennies, est de savoir si le test de Turing mesure vraiment l'intelligence. Jones et Bergen suggèrent que peut-être les machines sont devenues si douées pour s'adapter à différents scénarios qu'elles peuvent passer pour humaines de manière convaincante. L'instruction PERSONA, créée par des humains, est quelque chose que GPT-4.5 a adapté et utilisé à son avantage.
Mais il y a un hic : peut-être que les humains sont simplement mauvais à reconnaître l'intelligence. Les auteurs soulignent qu'ELIZA, le chatbot ancien, a trompé les juges dans 23 % des cas, non pas parce qu'il était plus intelligent, mais parce qu'il ne correspondait pas à leurs attentes de ce que devrait être une IA. Certains juges pensaient qu'il était humain parce qu'il était "sarcastique" ou "grossier", ce qu'ils n'attendaient pas d'une IA.
Cela suggère que les juges sont influencés par leurs présomptions sur la façon dont les humains et les IA devraient se comporter, plutôt que de choisir l'agent qui semble le plus intelligent. Fait intéressant, les juges ne se sont pas beaucoup concentrés sur les connaissances, que Turing pensait être clés. Au contraire, ils étaient plus susceptibles de penser qu'un témoin était humain s'il semblait manquer de connaissances.
Sociabilité, pas intelligence
Tout cela indique que les humains repéraient la sociabilité plutôt que l'intelligence. Jones et Bergen concluent que le test de Turing n'est pas vraiment un test d'intelligence—c'est un test de ressemblance humaine.
Turing pensait peut-être que l'intelligence était le plus grand obstacle à paraître humain, mais à mesure que les machines se rapprochent de nous, d'autres différences deviennent plus évidentes. L'intelligence seule ne suffit plus à sembler convaincamment humain.
Ce qui n'est pas dit directement dans l'article, c'est que les humains sont tellement habitués à taper sur des ordinateurs, que ce soit à une personne ou à une machine, que le test de Turing n'est plus le test novateur d'interaction homme-machine qu'il était autrefois. C'est plus un test des habitudes humaines en ligne maintenant.
Les auteurs suggèrent que le test pourrait devoir être élargi, car l'intelligence est si complexe et multifacette qu'aucun test unique ne peut être décisif. Ils proposent des conceptions différentes, comme utiliser des experts en IA comme juges ou ajouter des incitations financières pour que les juges examinent plus attentivement. Ces changements pourraient montrer à quel point les attitudes et les attentes influencent les résultats.
Ils concluent que, bien que le test de Turing puisse faire partie du tableau, il devrait être considéré aux côtés d'autres types de preuves. Cela s'aligne avec une tendance croissante dans la recherche en IA à impliquer les humains "dans la boucle", évaluant ce que font les machines.
Le jugement humain est-il suffisant ?
Mais il reste la question de savoir si le jugement humain sera suffisant à long terme. Dans le film Blade Runner, les humains utilisent une machine, le "Voight-Kampff", pour distinguer les humains des robots réplicants. Alors que nous poursuivons l'AGI, et luttons pour définir ce que c'est, nous pourrions finir par compter sur des machines pour évaluer l'intelligence des machines.
Ou, à tout le moins, nous pourrions devoir demander aux machines ce qu'elles "pensent" des humains essayant de tromper d'autres humains avec des instructions. C'est un monde fou dans la recherche en IA, et ça devient de plus en plus intéressant.
Article connexe
 Master Emerald Kaizo Nuzlocke : Guide ultime de survie et de stratégie
Emerald Kaizo est l'un des plus formidables hacks de ROM Pokémon jamais conçus. Bien que tenter une course Nuzlocke augmente exponentiellement le défi, la victoire reste possible grâce à une planifica
Lettres de motivation alimentées par l'IA : Guide d'experts pour les soumissions à des revues
Dans l'environnement compétitif de l'édition universitaire d'aujourd'hui, l'élaboration d'une lettre de motivation efficace peut faire la différence cruciale dans l'acceptation de votre manuscrit. Déc
Les États-Unis vont sanctionner des fonctionnaires étrangers en raison de la réglementation sur les médias sociaux
Les États-Unis prennent position contre les réglementations mondiales en matière de contenu numériqueCette semaine, le département d'État américain a émis un blâme diplomatique sévère à l'encontre d
commentaires (4)
0/200
Master Emerald Kaizo Nuzlocke : Guide ultime de survie et de stratégie
Emerald Kaizo est l'un des plus formidables hacks de ROM Pokémon jamais conçus. Bien que tenter une course Nuzlocke augmente exponentiellement le défi, la victoire reste possible grâce à une planifica
Lettres de motivation alimentées par l'IA : Guide d'experts pour les soumissions à des revues
Dans l'environnement compétitif de l'édition universitaire d'aujourd'hui, l'élaboration d'une lettre de motivation efficace peut faire la différence cruciale dans l'acceptation de votre manuscrit. Déc
Les États-Unis vont sanctionner des fonctionnaires étrangers en raison de la réglementation sur les médias sociaux
Les États-Unis prennent position contre les réglementations mondiales en matière de contenu numériqueCette semaine, le département d'État américain a émis un blâme diplomatique sévère à l'encontre d
commentaires (4)
0/200
![CarlLewis]() CarlLewis
CarlLewis
 20 août 2025 11:01:15 UTC+02:00
20 août 2025 11:01:15 UTC+02:00
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?


 0
0
![JamesLopez]() JamesLopez
11 août 2025 08:20:39 UTC+02:00
JamesLopez
11 août 2025 08:20:39 UTC+02:00
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
0
![DavidGonzález]() DavidGonzález
2 août 2025 17:07:14 UTC+02:00
DavidGonzález
2 août 2025 17:07:14 UTC+02:00
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
0
![PaulWilson]() PaulWilson
1 août 2025 08:08:50 UTC+02:00
PaulWilson
1 août 2025 08:08:50 UTC+02:00
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
0
Le test de Turing, conçu par le légendaire Alan Turing, est depuis longtemps une référence dans le monde de l'intelligence artificielle. Mais clarifions un malentendu dès le départ : réussir le test de Turing ne signifie pas nécessairement qu'une machine "pense" comme un humain. Il s'agit plutôt de convaincre les humains qu'elle l'est.
Des recherches récentes de l'Université de Californie à San Diego ont mis en lumière le dernier modèle d'OpenAI, GPT-4.5. Cette IA peut désormais tromper les humains en leur faisant croire qu'ils discutent avec une autre personne, encore plus efficacement que les humains ne peuvent se convaincre mutuellement de leur humanité. C'est un événement majeur dans le monde de l'IA—c'est comme regarder un tour de magie où l'on connaît le secret, mais qui reste époustouflant.
Preuve d'une AGI ?
Mais voici le hic : même les chercheurs de l'UC San Diego ne sont pas prêts à déclarer que nous avons atteint l'intelligence artificielle générale (AGI) simplement parce qu'un modèle d'IA réussit le test de Turing. L'AGI serait le Graal de l'IA—des machines capables de penser et de traiter l'information comme les humains.
Melanie Mitchell, une spécialiste de l'IA de l'Institut Santa Fe, soutient dans la revue Science que le test de Turing évalue davantage les présomptions humaines que l'intelligence réelle. Bien sûr, une IA peut sembler fluide et convaincante, mais cela ne signifie pas qu'elle est généralement intelligente. C'est comme être doué aux échecs—c'est impressionnant, mais ce n'est pas l'ensemble du tableau.
Le dernier engouement vient d'un article de Cameron Jones et Benjamin Bergen à l'UC San Diego, intitulé "Les grands modèles de langage réussissent le test de Turing", publié sur le serveur de prépublication arXiv. Ils mènent cette expérience depuis des années, avec l'aide d'étudiants de l'UC San Diego, et cela s'inscrit dans une longue lignée de recherches—plus de 800 affirmations et contre-arguments ont été faits sur des ordinateurs passant le test de Turing.
Comment fonctionne le test de Turing
Alors, comment fonctionne ce test ? À l'origine, Turing l'imaginait comme un jeu de messages texte entre un "juge" humain et deux "témoins"—l'un humain, l'autre informatique. Le défi pour les témoins est de convaincre le juge qu'ils sont humains. Le juge sait que l'un est humain, mais ne sait pas lequel, et doit deviner. C'est une configuration à trois qui repose autant sur la perception et la croyance que sur les capacités de l'ordinateur.
Jones et Bergen ont apporté leur propre touche à cette configuration classique, et vous pouvez même l'essayer en ligne, en jouant soit le rôle du juge, soit celui du témoin. Dans leur version, des étudiants de l'UC San Diego ont utilisé une application de chat texte. Certains jouaient le juge, d'autres le témoin humain, tandis que GPT-4.5 prenait le rôle du témoin informatique. Chaque juge discutait simultanément avec un humain et un ordinateur, restant fidèle au format original de Turing.
Pour jouer le témoin informatique, ils ont utilisé différents grands modèles de langage, en leur fournissant des instructions basées sur les défis du juge. GPT-4.5 a été testé avec deux instructions différentes : une avec des informations minimales, et une autre appelée PERSONA, qui incluait des instructions détaillées pour agir comme une personne jeune, introvertie, experte en internet et utilisant de l'argot.
Les résultats
Ils ont également testé trois autres programmes d'IA : le modèle précédent d'OpenAI, GPT-4o ; Llama 3.1 405b de Meta Platforms ; et le chatbot des années 1960, ELIZA. Ils ont inclus ELIZA pour voir si les grands modèles de langage trompaient les humains par hasard ou s'ils étaient réellement meilleurs.
Selon Jones et Bergen, GPT-4.5 a trompé les juges humains en leur faisant croire qu'il était humain dans 73 % des cas—un "taux de réussite" comme ils l'appellent. C'est bien meilleur que les autres modèles, qui ont obtenu entre 21 % et 56 %, même avec des instructions détaillées similaires. Et c'est un bond énorme par rapport au test de l'année dernière sur GPT-4, qui avait un taux de réussite de seulement 54 %, à peine au-dessus du hasard.
Jones et Bergen ont constaté que les juges étaient non seulement trompés par l'IA, mais étaient en réalité plus susceptibles de croire qu'elle était humaine que les véritables participants humains.
Le test est-il vraiment une mesure de l'intelligence ?
Alors, qu'est-ce que cela signifie si les humains ne peuvent pas distinguer un ordinateur d'une personne dans un chat ? La grande question, débattue depuis des décennies, est de savoir si le test de Turing mesure vraiment l'intelligence. Jones et Bergen suggèrent que peut-être les machines sont devenues si douées pour s'adapter à différents scénarios qu'elles peuvent passer pour humaines de manière convaincante. L'instruction PERSONA, créée par des humains, est quelque chose que GPT-4.5 a adapté et utilisé à son avantage.
Mais il y a un hic : peut-être que les humains sont simplement mauvais à reconnaître l'intelligence. Les auteurs soulignent qu'ELIZA, le chatbot ancien, a trompé les juges dans 23 % des cas, non pas parce qu'il était plus intelligent, mais parce qu'il ne correspondait pas à leurs attentes de ce que devrait être une IA. Certains juges pensaient qu'il était humain parce qu'il était "sarcastique" ou "grossier", ce qu'ils n'attendaient pas d'une IA.
Cela suggère que les juges sont influencés par leurs présomptions sur la façon dont les humains et les IA devraient se comporter, plutôt que de choisir l'agent qui semble le plus intelligent. Fait intéressant, les juges ne se sont pas beaucoup concentrés sur les connaissances, que Turing pensait être clés. Au contraire, ils étaient plus susceptibles de penser qu'un témoin était humain s'il semblait manquer de connaissances.
Sociabilité, pas intelligence
Tout cela indique que les humains repéraient la sociabilité plutôt que l'intelligence. Jones et Bergen concluent que le test de Turing n'est pas vraiment un test d'intelligence—c'est un test de ressemblance humaine.
Turing pensait peut-être que l'intelligence était le plus grand obstacle à paraître humain, mais à mesure que les machines se rapprochent de nous, d'autres différences deviennent plus évidentes. L'intelligence seule ne suffit plus à sembler convaincamment humain.
Ce qui n'est pas dit directement dans l'article, c'est que les humains sont tellement habitués à taper sur des ordinateurs, que ce soit à une personne ou à une machine, que le test de Turing n'est plus le test novateur d'interaction homme-machine qu'il était autrefois. C'est plus un test des habitudes humaines en ligne maintenant.
Les auteurs suggèrent que le test pourrait devoir être élargi, car l'intelligence est si complexe et multifacette qu'aucun test unique ne peut être décisif. Ils proposent des conceptions différentes, comme utiliser des experts en IA comme juges ou ajouter des incitations financières pour que les juges examinent plus attentivement. Ces changements pourraient montrer à quel point les attitudes et les attentes influencent les résultats.
Ils concluent que, bien que le test de Turing puisse faire partie du tableau, il devrait être considéré aux côtés d'autres types de preuves. Cela s'aligne avec une tendance croissante dans la recherche en IA à impliquer les humains "dans la boucle", évaluant ce que font les machines.
Le jugement humain est-il suffisant ?
Mais il reste la question de savoir si le jugement humain sera suffisant à long terme. Dans le film Blade Runner, les humains utilisent une machine, le "Voight-Kampff", pour distinguer les humains des robots réplicants. Alors que nous poursuivons l'AGI, et luttons pour définir ce que c'est, nous pourrions finir par compter sur des machines pour évaluer l'intelligence des machines.
Ou, à tout le moins, nous pourrions devoir demander aux machines ce qu'elles "pensent" des humains essayant de tromper d'autres humains avec des instructions. C'est un monde fou dans la recherche en IA, et ça devient de plus en plus intéressant.










 Master Emerald Kaizo Nuzlocke : Guide ultime de survie et de stratégie
Emerald Kaizo est l'un des plus formidables hacks de ROM Pokémon jamais conçus. Bien que tenter une course Nuzlocke augmente exponentiellement le défi, la victoire reste possible grâce à une planifica
Master Emerald Kaizo Nuzlocke : Guide ultime de survie et de stratégie
Emerald Kaizo est l'un des plus formidables hacks de ROM Pokémon jamais conçus. Bien que tenter une course Nuzlocke augmente exponentiellement le défi, la victoire reste possible grâce à une planifica
 Lettres de motivation alimentées par l'IA : Guide d'experts pour les soumissions à des revues
Dans l'environnement compétitif de l'édition universitaire d'aujourd'hui, l'élaboration d'une lettre de motivation efficace peut faire la différence cruciale dans l'acceptation de votre manuscrit. Déc
Lettres de motivation alimentées par l'IA : Guide d'experts pour les soumissions à des revues
Dans l'environnement compétitif de l'édition universitaire d'aujourd'hui, l'élaboration d'une lettre de motivation efficace peut faire la différence cruciale dans l'acceptation de votre manuscrit. Déc
 Les États-Unis vont sanctionner des fonctionnaires étrangers en raison de la réglementation sur les médias sociaux
Les États-Unis prennent position contre les réglementations mondiales en matière de contenu numériqueCette semaine, le département d'État américain a émis un blâme diplomatique sévère à l'encontre d
20 août 2025 11:01:15 UTC+02:00
Les États-Unis vont sanctionner des fonctionnaires étrangers en raison de la réglementation sur les médias sociaux
Les États-Unis prennent position contre les réglementations mondiales en matière de contenu numériqueCette semaine, le département d'État américain a émis un blâme diplomatique sévère à l'encontre d
20 août 2025 11:01:15 UTC+02:00
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?
0
11 août 2025 08:20:39 UTC+02:00
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
0
2 août 2025 17:07:14 UTC+02:00
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
0
1 août 2025 08:08:50 UTC+02:00
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
0













