




图灵测试问题被OpenAI的GPT-4.5暴露
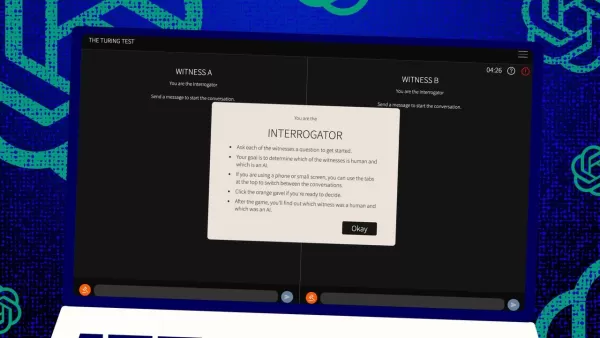
图灵测试,传奇人物艾伦·图灵的创举,长期以来一直是人工智能领域的基准。但让我们先澄清一个常见的误解:通过图灵测试并不一定意味着机器像人类一样“思考”。它更多是关于说服人类相信它是人类。
加州大学圣地亚哥分校的最新研究聚焦于OpenAI的最新模型GPT-4.5。这一人工智能现在能比人类更有效地欺骗人类,让他们相信自己正在与另一个人交谈。这在人工智能领域可是件大事——就像看一场魔术表演,你知道其中的秘密,但它依然让你瞠目结舌。
AGI的证明?
但关键在于:即使是加州大学圣地亚哥分校的研究人员也不准备仅仅因为一个人工智能模型通过了图灵测试就宣布我们达到了“通用人工智能”(AGI)。AGI是人工智能的圣杯——能够像人类一样思考和处理信息的机器。
来自圣塔菲研究所的人工智能学者梅兰妮·米切尔在《科学》期刊中指出,图灵测试更多是测试人类的假设,而非真正的智能。当然,人工智能可能听起来流畅且令人信服,但这与真正的通用智能不同。这就像擅长下棋——很了不起,但并非全貌。
围绕这一话题的最新热议来自加州大学圣地亚哥分校卡梅伦·琼斯和本杰明·伯根的一篇论文,题为“大型语言模型通过图灵测试”,发表在arXiv预印本服务器上。他们多年来一直在进行这项实验,得到了加州大学圣地亚哥分校本科生的帮助,这是一系列研究的延续——关于计算机通过图灵测试的争论已有超过800个主张和反驳。
图灵测试如何运作
那么,这个测试是如何进行的呢?最初,图灵设想它是一场人类“评判者”与两个“证人”——一个人类,一个计算机——之间的文本消息游戏。证人的挑战是说服评判者他们是人类。评判者知道其中一个是人类,但不知道是哪一个,必须做出猜测。这个三方设置既关乎计算机的能力,也关乎感知和信念。
琼斯和伯根对这一经典设置进行了自己的改编,你甚至可以在线尝试,扮演评判者或证人。在他们的版本中,加州大学圣地亚哥分校的学生使用了一个文本聊天应用。一些人扮演评判者,另一些人扮演人类证人,而GPT-4.5则扮演计算机证人。每个评判者同时与一个人类和一个计算机交谈,忠于图灵的原始格式。
为了扮演计算机证人,他们使用了不同的大型语言模型,根据评判者的挑战输入提示。GPT-4.5测试了两种不同的提示:一种信息最少,另一种称为PERSONA,包含详细指令,要求其表现得像一个年轻、内向、精通网络且使用俚语的人。
测试结果
他们还测试了其他三个人工智能程序:OpenAI的上一代模型GPT-4o、Meta Platforms的Llama 3.1 405b,以及1960年代的古老聊天机器人ELIZA。他们加入ELIZA是为了验证大型语言模型是否只是偶然欺骗了人类,或者它们确实表现更佳。
据琼斯和伯根称,GPT-4.5在73%的情况下成功让人类评判者认为它是人类——他们称之为“胜率”。这远超其他模型的得分,介于21%到56%之间,即使使用了类似的详细提示。相比之下,去年的GPT-4测试胜率仅为54%,勉强高于随机概率。
琼斯和伯根发现,评判者不仅被人工智能欺骗,甚至更倾向于相信它是人类,而非真正的人类参与者。
测试真是智能的衡量标准吗?
那么,人类无法在聊天中区分计算机和人的意义何在?几十年来一直争论的大问题是,图灵测试是否真的在衡量智能。琼斯和伯根认为,也许机器只是变得非常擅长适应不同场景,以至于它们能令人信服地冒充人类。由人类创建的PERSONA提示被GPT-4.5充分利用,发挥了优势。
但有一个问题:也许人类只是不擅长识别智能。作者指出,古老的聊天机器人ELIZA在23%的情况下欺骗了评判者,不是因为它更聪明,而是因为它不符合评判者对人工智能的预期。一些评判者认为它是人类,因为它显得“讽刺”或“粗鲁”,这超出了他们对人工智能的预期。
这表明评判者受到他们对人类和人工智能行为假设的影响,而不仅仅是选择看似最智能的个体。有趣的是,评判者并未过多关注知识,而图灵认为知识是关键。相反,他们更倾向于认为缺乏知识的证人是人类。
社交能力,而非智能
所有这些都指向一个观点:人类在意的更多是社交能力,而非智能。琼斯和伯根得出结论,图灵测试并不是真正的智能测试——它是对人类相似性的测试。
图灵可能认为智能是表现得像人类的最大障碍,但随着机器越来越接近人类,其他差异变得更加明显。单靠智能已不足以令人信服地表现得像人类。
论文中未直接提及的是,人类如此习惯于在计算机上打字,无论是与人还是与机器交流,图灵测试已不再是曾经新奇的人机交互测试。现在它更像是对在线人类习惯的测试。
作者建议,测试可能需要扩展,因为智能是如此复杂和多方面的,单一测试无法决定一切。他们提出不同的设计,如使用人工智能专家作为评判者,或增加经济激励以让评判者更仔细审查。这些变化可以揭示态度和期望对结果的影响程度。
他们得出结论,虽然图灵测试可能是整体图景的一部分,但应与其他证据结合考虑。这与人工智能研究中日益增长的趋势一致,即让人类“参与其中”,评估机器的行为。
人类判断足够吗?
但长期来看,人类判断是否足够仍是一个问题。在电影《银翼杀手》中,人类使用“沃伊特-坎普夫”机器来区分人类和复制人机器人。随着我们追逐AGI,并努力定义它究竟是什么,我们可能最终需要依靠机器来评估机器的智能。
或者,至少,我们可能需要询问机器,它们对人类试图用提示欺骗其他人类的“想法”是什么。人工智能研究领域真是一个奇妙的世界,而且只会变得更有趣。
相关文章
 谷歌的人工智能现在能帮你处理电话了
谷歌已通过搜索将人工智能呼叫功能扩展到所有美国用户,使客户无需电话交谈即可向本地企业询问价格和可用性。该功能最初于 1 月份进行测试,目前支持服务型企业,包括宠物美容师、洗衣服务和汽车修理店。搜索者会发现,在符合条件的企业列表下方出现了 "让人工智能查询价格 "选项。人工智能界面会提示用户服务的具体内容--对于宠物美容查询,它会要求用户提供动物类型、品种、所需服务等详细信息,以及更新信息的首选联系
特朗普豁免智能手机、电脑和芯片关税上涨
据彭博社报道,特朗普政府已允许智能手机、电脑和各种电子设备免受近期关税上调的影响,即使是从中国进口。不过,这些产品仍需遵守4月9日之前实施的关税。彭博社的消息来源证实,美国海关和边境保护局周三晚些时候发布了最新的指导方针,对包括智能手机、笔记本电脑、计算机组件和半导体制造设备在内的重要科技产品免征新的125%的中国进口关税,以及对大多数国家征收的10%的基准关税。*彭博社随后对其报道进行了补充,澄
人工智能通过令人惊叹的数字转换,在元宇宙中重塑迈克尔-杰克逊的形象
人工智能正在从根本上重塑我们对创造力、娱乐和文化遗产的理解。对人工智能生成的迈克尔-杰克逊演绎的探索,揭示了尖端技术如何为传奇文化人物注入新的生命。从超级英雄的化身到奇幻境界的战士,这些突破性的转变展示了人工智能重塑流行音乐之王的非凡能力,同时也拓展了数字艺术和虚拟世界体验的视野。主要见解人工智能通过富有想象力的角色转换重新定义迈克尔-杰克逊戏剧性的可视化包括超级英雄、绝地武士和装甲骑士角色探索数
评论 (4)
0/200
谷歌的人工智能现在能帮你处理电话了
谷歌已通过搜索将人工智能呼叫功能扩展到所有美国用户,使客户无需电话交谈即可向本地企业询问价格和可用性。该功能最初于 1 月份进行测试,目前支持服务型企业,包括宠物美容师、洗衣服务和汽车修理店。搜索者会发现,在符合条件的企业列表下方出现了 "让人工智能查询价格 "选项。人工智能界面会提示用户服务的具体内容--对于宠物美容查询,它会要求用户提供动物类型、品种、所需服务等详细信息,以及更新信息的首选联系
特朗普豁免智能手机、电脑和芯片关税上涨
据彭博社报道,特朗普政府已允许智能手机、电脑和各种电子设备免受近期关税上调的影响,即使是从中国进口。不过,这些产品仍需遵守4月9日之前实施的关税。彭博社的消息来源证实,美国海关和边境保护局周三晚些时候发布了最新的指导方针,对包括智能手机、笔记本电脑、计算机组件和半导体制造设备在内的重要科技产品免征新的125%的中国进口关税,以及对大多数国家征收的10%的基准关税。*彭博社随后对其报道进行了补充,澄
人工智能通过令人惊叹的数字转换,在元宇宙中重塑迈克尔-杰克逊的形象
人工智能正在从根本上重塑我们对创造力、娱乐和文化遗产的理解。对人工智能生成的迈克尔-杰克逊演绎的探索,揭示了尖端技术如何为传奇文化人物注入新的生命。从超级英雄的化身到奇幻境界的战士,这些突破性的转变展示了人工智能重塑流行音乐之王的非凡能力,同时也拓展了数字艺术和虚拟世界体验的视野。主要见解人工智能通过富有想象力的角色转换重新定义迈克尔-杰克逊戏剧性的可视化包括超级英雄、绝地武士和装甲骑士角色探索数
评论 (4)
0/200
![CarlLewis]() CarlLewis
CarlLewis
 2025-08-20 17:01:15
2025-08-20 17:01:15
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?


 0
0
![JamesLopez]() JamesLopez
2025-08-11 14:20:39
JamesLopez
2025-08-11 14:20:39
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
0
![DavidGonzález]() DavidGonzález
2025-08-02 23:07:14
DavidGonzález
2025-08-02 23:07:14
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
0
![PaulWilson]() PaulWilson
2025-08-01 14:08:50
PaulWilson
2025-08-01 14:08:50
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
0
图灵测试,传奇人物艾伦·图灵的创举,长期以来一直是人工智能领域的基准。但让我们先澄清一个常见的误解:通过图灵测试并不一定意味着机器像人类一样“思考”。它更多是关于说服人类相信它是人类。
加州大学圣地亚哥分校的最新研究聚焦于OpenAI的最新模型GPT-4.5。这一人工智能现在能比人类更有效地欺骗人类,让他们相信自己正在与另一个人交谈。这在人工智能领域可是件大事——就像看一场魔术表演,你知道其中的秘密,但它依然让你瞠目结舌。
AGI的证明?
但关键在于:即使是加州大学圣地亚哥分校的研究人员也不准备仅仅因为一个人工智能模型通过了图灵测试就宣布我们达到了“通用人工智能”(AGI)。AGI是人工智能的圣杯——能够像人类一样思考和处理信息的机器。
来自圣塔菲研究所的人工智能学者梅兰妮·米切尔在《科学》期刊中指出,图灵测试更多是测试人类的假设,而非真正的智能。当然,人工智能可能听起来流畅且令人信服,但这与真正的通用智能不同。这就像擅长下棋——很了不起,但并非全貌。
围绕这一话题的最新热议来自加州大学圣地亚哥分校卡梅伦·琼斯和本杰明·伯根的一篇论文,题为“大型语言模型通过图灵测试”,发表在arXiv预印本服务器上。他们多年来一直在进行这项实验,得到了加州大学圣地亚哥分校本科生的帮助,这是一系列研究的延续——关于计算机通过图灵测试的争论已有超过800个主张和反驳。
图灵测试如何运作
那么,这个测试是如何进行的呢?最初,图灵设想它是一场人类“评判者”与两个“证人”——一个人类,一个计算机——之间的文本消息游戏。证人的挑战是说服评判者他们是人类。评判者知道其中一个是人类,但不知道是哪一个,必须做出猜测。这个三方设置既关乎计算机的能力,也关乎感知和信念。
琼斯和伯根对这一经典设置进行了自己的改编,你甚至可以在线尝试,扮演评判者或证人。在他们的版本中,加州大学圣地亚哥分校的学生使用了一个文本聊天应用。一些人扮演评判者,另一些人扮演人类证人,而GPT-4.5则扮演计算机证人。每个评判者同时与一个人类和一个计算机交谈,忠于图灵的原始格式。
为了扮演计算机证人,他们使用了不同的大型语言模型,根据评判者的挑战输入提示。GPT-4.5测试了两种不同的提示:一种信息最少,另一种称为PERSONA,包含详细指令,要求其表现得像一个年轻、内向、精通网络且使用俚语的人。
测试结果
他们还测试了其他三个人工智能程序:OpenAI的上一代模型GPT-4o、Meta Platforms的Llama 3.1 405b,以及1960年代的古老聊天机器人ELIZA。他们加入ELIZA是为了验证大型语言模型是否只是偶然欺骗了人类,或者它们确实表现更佳。
据琼斯和伯根称,GPT-4.5在73%的情况下成功让人类评判者认为它是人类——他们称之为“胜率”。这远超其他模型的得分,介于21%到56%之间,即使使用了类似的详细提示。相比之下,去年的GPT-4测试胜率仅为54%,勉强高于随机概率。
琼斯和伯根发现,评判者不仅被人工智能欺骗,甚至更倾向于相信它是人类,而非真正的人类参与者。
测试真是智能的衡量标准吗?
那么,人类无法在聊天中区分计算机和人的意义何在?几十年来一直争论的大问题是,图灵测试是否真的在衡量智能。琼斯和伯根认为,也许机器只是变得非常擅长适应不同场景,以至于它们能令人信服地冒充人类。由人类创建的PERSONA提示被GPT-4.5充分利用,发挥了优势。
但有一个问题:也许人类只是不擅长识别智能。作者指出,古老的聊天机器人ELIZA在23%的情况下欺骗了评判者,不是因为它更聪明,而是因为它不符合评判者对人工智能的预期。一些评判者认为它是人类,因为它显得“讽刺”或“粗鲁”,这超出了他们对人工智能的预期。
这表明评判者受到他们对人类和人工智能行为假设的影响,而不仅仅是选择看似最智能的个体。有趣的是,评判者并未过多关注知识,而图灵认为知识是关键。相反,他们更倾向于认为缺乏知识的证人是人类。
社交能力,而非智能
所有这些都指向一个观点:人类在意的更多是社交能力,而非智能。琼斯和伯根得出结论,图灵测试并不是真正的智能测试——它是对人类相似性的测试。
图灵可能认为智能是表现得像人类的最大障碍,但随着机器越来越接近人类,其他差异变得更加明显。单靠智能已不足以令人信服地表现得像人类。
论文中未直接提及的是,人类如此习惯于在计算机上打字,无论是与人还是与机器交流,图灵测试已不再是曾经新奇的人机交互测试。现在它更像是对在线人类习惯的测试。
作者建议,测试可能需要扩展,因为智能是如此复杂和多方面的,单一测试无法决定一切。他们提出不同的设计,如使用人工智能专家作为评判者,或增加经济激励以让评判者更仔细审查。这些变化可以揭示态度和期望对结果的影响程度。
他们得出结论,虽然图灵测试可能是整体图景的一部分,但应与其他证据结合考虑。这与人工智能研究中日益增长的趋势一致,即让人类“参与其中”,评估机器的行为。
人类判断足够吗?
但长期来看,人类判断是否足够仍是一个问题。在电影《银翼杀手》中,人类使用“沃伊特-坎普夫”机器来区分人类和复制人机器人。随着我们追逐AGI,并努力定义它究竟是什么,我们可能最终需要依靠机器来评估机器的智能。
或者,至少,我们可能需要询问机器,它们对人类试图用提示欺骗其他人类的“想法”是什么。人工智能研究领域真是一个奇妙的世界,而且只会变得更有趣。










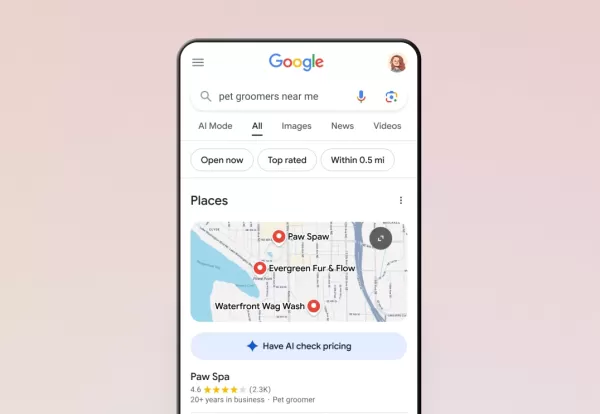 谷歌的人工智能现在能帮你处理电话了
谷歌已通过搜索将人工智能呼叫功能扩展到所有美国用户,使客户无需电话交谈即可向本地企业询问价格和可用性。该功能最初于 1 月份进行测试,目前支持服务型企业,包括宠物美容师、洗衣服务和汽车修理店。搜索者会发现,在符合条件的企业列表下方出现了 "让人工智能查询价格 "选项。人工智能界面会提示用户服务的具体内容--对于宠物美容查询,它会要求用户提供动物类型、品种、所需服务等详细信息,以及更新信息的首选联系
谷歌的人工智能现在能帮你处理电话了
谷歌已通过搜索将人工智能呼叫功能扩展到所有美国用户,使客户无需电话交谈即可向本地企业询问价格和可用性。该功能最初于 1 月份进行测试,目前支持服务型企业,包括宠物美容师、洗衣服务和汽车修理店。搜索者会发现,在符合条件的企业列表下方出现了 "让人工智能查询价格 "选项。人工智能界面会提示用户服务的具体内容--对于宠物美容查询,它会要求用户提供动物类型、品种、所需服务等详细信息,以及更新信息的首选联系
 特朗普豁免智能手机、电脑和芯片关税上涨
据彭博社报道,特朗普政府已允许智能手机、电脑和各种电子设备免受近期关税上调的影响,即使是从中国进口。不过,这些产品仍需遵守4月9日之前实施的关税。彭博社的消息来源证实,美国海关和边境保护局周三晚些时候发布了最新的指导方针,对包括智能手机、笔记本电脑、计算机组件和半导体制造设备在内的重要科技产品免征新的125%的中国进口关税,以及对大多数国家征收的10%的基准关税。*彭博社随后对其报道进行了补充,澄
特朗普豁免智能手机、电脑和芯片关税上涨
据彭博社报道,特朗普政府已允许智能手机、电脑和各种电子设备免受近期关税上调的影响,即使是从中国进口。不过,这些产品仍需遵守4月9日之前实施的关税。彭博社的消息来源证实,美国海关和边境保护局周三晚些时候发布了最新的指导方针,对包括智能手机、笔记本电脑、计算机组件和半导体制造设备在内的重要科技产品免征新的125%的中国进口关税,以及对大多数国家征收的10%的基准关税。*彭博社随后对其报道进行了补充,澄
 人工智能通过令人惊叹的数字转换,在元宇宙中重塑迈克尔-杰克逊的形象
人工智能正在从根本上重塑我们对创造力、娱乐和文化遗产的理解。对人工智能生成的迈克尔-杰克逊演绎的探索,揭示了尖端技术如何为传奇文化人物注入新的生命。从超级英雄的化身到奇幻境界的战士,这些突破性的转变展示了人工智能重塑流行音乐之王的非凡能力,同时也拓展了数字艺术和虚拟世界体验的视野。主要见解人工智能通过富有想象力的角色转换重新定义迈克尔-杰克逊戏剧性的可视化包括超级英雄、绝地武士和装甲骑士角色探索数
2025-08-20 17:01:15
人工智能通过令人惊叹的数字转换,在元宇宙中重塑迈克尔-杰克逊的形象
人工智能正在从根本上重塑我们对创造力、娱乐和文化遗产的理解。对人工智能生成的迈克尔-杰克逊演绎的探索,揭示了尖端技术如何为传奇文化人物注入新的生命。从超级英雄的化身到奇幻境界的战士,这些突破性的转变展示了人工智能重塑流行音乐之王的非凡能力,同时也拓展了数字艺术和虚拟世界体验的视野。主要见解人工智能通过富有想象力的角色转换重新定义迈克尔-杰克逊戏剧性的可视化包括超级英雄、绝地武士和装甲骑士角色探索数
2025-08-20 17:01:15
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?
0
2025-08-11 14:20:39
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
0
2025-08-02 23:07:14
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
0
2025-08-01 14:08:50
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
0













