




OpenAI의 GPT-4.5가 드러낸 튜링 테스트 문제
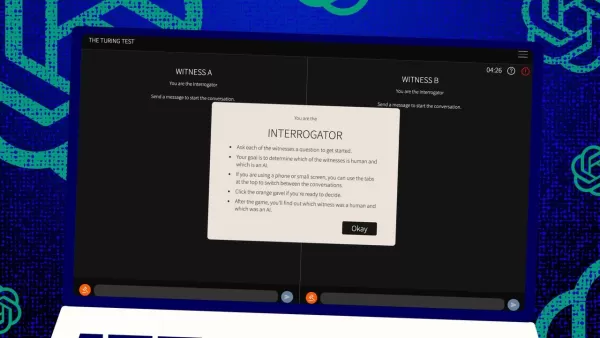
튜링 테스트, 전설적인 앨런 튜링의 아이디어는 인공지능 세계에서 오랫동안 기준이 되어 왔습니다. 하지만 흔한 오해를 바로잡자면, 튜링 테스트를 통과했다고 해서 기계가 인간처럼 "생각"하는 것은 아닙니다. 이는 인간을 설득하는 데 더 가깝습니다.
샌디에이고 캘리포니아 대학의 최근 연구는 OpenAI의 최신 모델 GPT-4.5에 주목했습니다. 이 AI는 이제 인간이 다른 사람과 대화하고 있다고 믿게 만들 정도로 속일 수 있으며, 인간이 서로의 인간성을 설득하는 것보다 더 효과적입니다. AI 세계에서는 꽤 큰 사건입니다—마술을 보는 것 같지만 비밀을 알아도 여전히 놀랍습니다.
AGI의 증거?
하지만 여기서 중요한 점: UC 샌디에이고 연구진도 AI 모델이 튜링 테스트를 통과했다고 해서 "인공지능 일반" (AGI)에 도달했다고 선언할 준비가 되어 있지 않습니다. AGI는 AI의 성배로, 인간처럼 생각하고 정보를 처리할 수 있는 기계입니다.
산타페 연구소의 AI 학자 멜라니 미첼은 Science 저널에서 튜링 테스트가 실제 지능보다는 인간의 가정을 테스트하는 것이라고 주장합니다. AI가 유창하고 설득력 있게 들릴 수 있지만, 그것이 일반적인 지능을 의미하는 것은 아닙니다. 체스 잘하는 것과 비슷—인상적이지만 전체 그림은 아닙니다.
이와 관련된 최신 논란은 UC 샌디에이고의 카메론 존스와 벤자민 버겐이 arXiv 프리프린트 서버에 발표한 "대규모 언어 모델이 튜링 테스트를 통과하다"라는 논문에서 비롯됩니다. 그들은 UC 샌디에이고 학부생들의 도움을 받아 수년간 이 실험을 진행했으며, 이는 컴퓨터가 튜링 테스트를 통과했다는 800개 이상의 주장과 반론의 긴 연구의 일환입니다.
튜링 테스트의 작동 방식
그렇다면 이 테스트는 어떻게 작동할까요? 원래 튜링은 인간 "심판"과 두 명의 "증인"—한 명은 인간, 한 명은 컴퓨터—간의 문자 메시지 게임으로 상상했습니다. 증인의 과제는 심판에게 자신이 인간이라고 설득하는 것입니다. 심판은 한 명이 인간임을 알지만 누가 인간인지 모르며 추측해야 합니다. 이는 컴퓨터의 능력만큼이나 인식과 믿음에 관한 삼자 구도입니다.
존스와 버겐은 이 고전적 설정에 자신들만의 변화를 주었으며, 온라인에서 심판이나 증인으로 참여해 볼 수도 있습니다. 그들의 버전에서는 UC 샌디에이고 학생들이 텍스트 채팅 앱을 사용했습니다. 일부는 심판, 일부는 인간 증인, GPT-4.5는 컴퓨터 증인 역할을 맡았습니다. 각 심판은 튜링의 원래 형식에 충실하게 인간과 컴퓨터와 동시에 대화했습니다.
컴퓨터 증인 역할을 위해 다양한 대규모 언어 모델을 사용했으며, 심판의 도전에 따라 프롬프트를 제공했습니다. GPT-4.5는 최소 정보 프롬프트와 젊고 내성적이며 인터넷에 능통하고 속어를 사용하는 사람처럼 행동하라는 상세 지침이 포함된 PERSONA라는 두 가지 프롬프트로 테스트되었습니다.
결과
그들은 또한 OpenAI의 이전 모델 GPT-4o, Meta Platforms의 Llama 3.1 405b, 1960년대 챗봇 ELIZA 등 세 가지 다른 AI 프로그램을 테스트했습니다. ELIZA는 대규모 언어 모델이 우연히 인간을 속이는지, 아니면 실제로 더 나은지 확인하기 위해 포함되었습니다.
존스와 버겐에 따르면, GPT-4.5는 73%의 시간 동안 인간 심판을 속여 인간이라고 믿게 만들었습니다—그들이 말하는 "승률"입니다. 이는 다른 모델들(21%에서 56% 사이)보다 훨씬 나은 성적으로, 비슷한 상세 프롬프트에도 불구하고 그렇습니다. 작년 GPT-4 테스트의 승률 54%에서 크게 도약한 것으로, 이는 무작위 확률을 간신히 넘는 수준이었습니다.
존스와 버겐은 심판이 AI에 속았을 뿐만 아니라 실제 인간 참가자보다 AI가 인간이라고 믿을 가능성이 더 높았다는 것을 발견했습니다.
테스트가 정말 지능을 측정하는가?
그렇다면 인간이 채팅에서 컴퓨터와 사람을 구분하지 못한다는 것은 무엇을 의미할까요? 수십 년간 논쟁된 큰 질문은 튜링 테스트가 정말 지능을 측정하는지입니다. 존스와 버겐은 기계가 다양한 시나리오에 적응하는 데 너무 능숙해져서 인간으로 설득력 있게 통과할 수 있다고 제안합니다. 인간이 만든 PERSONA 프롬프트는 GPT-4.5가 적응해 활용한 것입니다.
하지만 문제는 인간이 지능을 인식하는 데 서툴 수도 있다는 점입니다. 저자들은 고대 챗봇 ELIZA가 23%의 시간 동안 심판을 속였는데, 이는 더 똑똑해서가 아니라 AI에 대한 기대를 충족하지 않았기 때문이라고 지적합니다. 일부 심판은 ELIZA가 "냉소적"이거나 "무례"하다고 생각해 인간이라고 믿었는데, 이는 AI에서 기대하지 않은 특성이었습니다.
이는 심판이 인간과 AI가 어떻게 행동해야 한다는 가정에 영향을 받는다는 것을 시사합니다. 흥미롭게도 심판은 튜링이 중요하다고 생각했던 지식에 많이 집중하지 않았습니다. 대신, 지식이 부족해 보이는 증인을 인간으로 간주할 가능성이 더 높았습니다.
사교성, 지능 아님
이 모든 것은 인간이 지능보다는 사교성을 포착했다는 아이디어를 가리킵니다. 존스와 버겐은 튜링 테스트가 실제로 지능 테스트가 아니라 인간다움 테스트라고 결론짓습니다.
튜링은 지능이 인간다움을 보이는 데 가장 큰 장애물이라고 생각했을지 모르지만, 기계가 우리에게 가까워질수록 다른 차이점이 더 두드러집니다. 지능만으로는 더 이상 설득력 있는 인간다움을 보일 수 없습니다.
논문에서 직접 언급되지 않은 것은 인간이 사람이나 기계와 컴퓨터로 타이핑하는 데 너무 익숙해져 튜링 테스트가 예전처럼 새로운 인간-컴퓨터 상호작용 테스트가 아니라는 점입니다. 이제는 온라인 인간 습관 테스트에 더 가깝습니다.
저자들은 지능이 너무 복잡하고 다면적이어서 단일 테스트로는 결정적이지 않다고 제안하며 테스트 확장을 제안합니다. AI 전문가를 심판으로 사용하거나 금전적 인센티브를 추가해 심판이 더 면밀히 조사하도록 하는 등의 다른 설계가 결과에 대한 태도와 기대의 영향을 보여줄 수 있습니다.
그들은 튜링 테스트가 그림의 일부일 수 있지만, 다른 종류의 증거와 함께 고려해야 한다고 결론짓습니다. 이는 AI 연구에서 인간을 "루프에 포함"시켜 기계의 행동을 평가하는 추세와 일치합니다.
인간 판단이 충분한가?
하지만 장기적으로 인간 판단이 충분할지에 대한 질문이 여전히 남아 있습니다. 영화 Blade Runner에서 인간은 인간과 복제 로봇을 구분하기 위해 "Voight-Kampff"라는 기계를 사용합니다. AGI를 추구하며 그것이 무엇인지 정의하는 데 어려움을 겪으면서, 우리는 기계 지능을 평가하기 위해 기계에 의존하게 될지도 모릅니다.
최소한, 인간이 다른 인간을 속이려는 프롬프트로 무엇을 "생각"하는지 기계에 물어볼 필요가 있을지도 모릅니다. AI 연구의 세상은 점점 더 흥미로워지고 있습니다.
관련 기사
 놀라운 디지털 혁신으로 메타버스에서 마이클 잭슨을 재창조하는 AI
인공지능은 창의성, 엔터테인먼트, 문화 유산에 대한 우리의 이해를 근본적으로 바꾸고 있습니다. 마이클 잭슨에 대한 인공지능의 해석을 통해 최첨단 기술이 어떻게 전설적인 문화 인물에 새로운 생명을 불어넣을 수 있는지 살펴봅니다. 슈퍼 히어로의 화신에서 판타지 세계의 전사에 이르기까지 획기적인 변신은 디지털 아트와 가상 세계 경험의 지평을 넓히는 동시에 팝의
훈련이 AI로 인한 인지 오프로딩 효과를 완화할 수 있나요?
최근 Unite.ai의 'ChatGPT가 뇌를 고갈시킬 수 있습니다: 인공지능 시대의 인지적 부채'라는 제목의 기사에서 MIT의 연구 결과를 조명했습니다. 저널리스트 알렉스 맥팔랜드는 과도한 AI 의존도가 어떻게 필수적인 인지 능력, 특히 비판적 사고와 판단력을 약화시킬 수 있는지에 대한 설득력 있는 증거를 자세히 설명했습니다. 이러한 연구 결과는 다른 수
더 나은 데이터 인사이트를 위한 AI 기반 그래프 및 시각화를 쉽게 생성하기
최신 데이터 분석에는 복잡한 정보를 직관적으로 시각화할 수 있어야 합니다. AI 기반 그래프 생성 솔루션은 전문가들이 원시 데이터를 매력적인 시각적 스토리로 변환하는 방법에 혁신을 일으키며 필수적인 자산으로 부상했습니다. 이러한 지능형 시스템은 정밀도를 유지하면서 수동 차트 생성을 제거하여 기술 및 비기술 사용자 모두 자동화된 시각화를 통해 실행 가능한 인
의견 (4)
0/200
놀라운 디지털 혁신으로 메타버스에서 마이클 잭슨을 재창조하는 AI
인공지능은 창의성, 엔터테인먼트, 문화 유산에 대한 우리의 이해를 근본적으로 바꾸고 있습니다. 마이클 잭슨에 대한 인공지능의 해석을 통해 최첨단 기술이 어떻게 전설적인 문화 인물에 새로운 생명을 불어넣을 수 있는지 살펴봅니다. 슈퍼 히어로의 화신에서 판타지 세계의 전사에 이르기까지 획기적인 변신은 디지털 아트와 가상 세계 경험의 지평을 넓히는 동시에 팝의
훈련이 AI로 인한 인지 오프로딩 효과를 완화할 수 있나요?
최근 Unite.ai의 'ChatGPT가 뇌를 고갈시킬 수 있습니다: 인공지능 시대의 인지적 부채'라는 제목의 기사에서 MIT의 연구 결과를 조명했습니다. 저널리스트 알렉스 맥팔랜드는 과도한 AI 의존도가 어떻게 필수적인 인지 능력, 특히 비판적 사고와 판단력을 약화시킬 수 있는지에 대한 설득력 있는 증거를 자세히 설명했습니다. 이러한 연구 결과는 다른 수
더 나은 데이터 인사이트를 위한 AI 기반 그래프 및 시각화를 쉽게 생성하기
최신 데이터 분석에는 복잡한 정보를 직관적으로 시각화할 수 있어야 합니다. AI 기반 그래프 생성 솔루션은 전문가들이 원시 데이터를 매력적인 시각적 스토리로 변환하는 방법에 혁신을 일으키며 필수적인 자산으로 부상했습니다. 이러한 지능형 시스템은 정밀도를 유지하면서 수동 차트 생성을 제거하여 기술 및 비기술 사용자 모두 자동화된 시각화를 통해 실행 가능한 인
의견 (4)
0/200
![CarlLewis]() CarlLewis
CarlLewis
 2025년 8월 20일 오후 6시 1분 15초 GMT+09:00
2025년 8월 20일 오후 6시 1분 15초 GMT+09:00
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?


 0
0
![JamesLopez]() JamesLopez
2025년 8월 11일 오후 3시 20분 39초 GMT+09:00
JamesLopez
2025년 8월 11일 오후 3시 20분 39초 GMT+09:00
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
0
![DavidGonzález]() DavidGonzález
2025년 8월 3일 오전 12시 7분 14초 GMT+09:00
DavidGonzález
2025년 8월 3일 오전 12시 7분 14초 GMT+09:00
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
0
![PaulWilson]() PaulWilson
2025년 8월 1일 오후 3시 8분 50초 GMT+09:00
PaulWilson
2025년 8월 1일 오후 3시 8분 50초 GMT+09:00
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
0
튜링 테스트, 전설적인 앨런 튜링의 아이디어는 인공지능 세계에서 오랫동안 기준이 되어 왔습니다. 하지만 흔한 오해를 바로잡자면, 튜링 테스트를 통과했다고 해서 기계가 인간처럼 "생각"하는 것은 아닙니다. 이는 인간을 설득하는 데 더 가깝습니다.
샌디에이고 캘리포니아 대학의 최근 연구는 OpenAI의 최신 모델 GPT-4.5에 주목했습니다. 이 AI는 이제 인간이 다른 사람과 대화하고 있다고 믿게 만들 정도로 속일 수 있으며, 인간이 서로의 인간성을 설득하는 것보다 더 효과적입니다. AI 세계에서는 꽤 큰 사건입니다—마술을 보는 것 같지만 비밀을 알아도 여전히 놀랍습니다.
AGI의 증거?
하지만 여기서 중요한 점: UC 샌디에이고 연구진도 AI 모델이 튜링 테스트를 통과했다고 해서 "인공지능 일반" (AGI)에 도달했다고 선언할 준비가 되어 있지 않습니다. AGI는 AI의 성배로, 인간처럼 생각하고 정보를 처리할 수 있는 기계입니다.
산타페 연구소의 AI 학자 멜라니 미첼은 Science 저널에서 튜링 테스트가 실제 지능보다는 인간의 가정을 테스트하는 것이라고 주장합니다. AI가 유창하고 설득력 있게 들릴 수 있지만, 그것이 일반적인 지능을 의미하는 것은 아닙니다. 체스 잘하는 것과 비슷—인상적이지만 전체 그림은 아닙니다.
이와 관련된 최신 논란은 UC 샌디에이고의 카메론 존스와 벤자민 버겐이 arXiv 프리프린트 서버에 발표한 "대규모 언어 모델이 튜링 테스트를 통과하다"라는 논문에서 비롯됩니다. 그들은 UC 샌디에이고 학부생들의 도움을 받아 수년간 이 실험을 진행했으며, 이는 컴퓨터가 튜링 테스트를 통과했다는 800개 이상의 주장과 반론의 긴 연구의 일환입니다.
튜링 테스트의 작동 방식
그렇다면 이 테스트는 어떻게 작동할까요? 원래 튜링은 인간 "심판"과 두 명의 "증인"—한 명은 인간, 한 명은 컴퓨터—간의 문자 메시지 게임으로 상상했습니다. 증인의 과제는 심판에게 자신이 인간이라고 설득하는 것입니다. 심판은 한 명이 인간임을 알지만 누가 인간인지 모르며 추측해야 합니다. 이는 컴퓨터의 능력만큼이나 인식과 믿음에 관한 삼자 구도입니다.
존스와 버겐은 이 고전적 설정에 자신들만의 변화를 주었으며, 온라인에서 심판이나 증인으로 참여해 볼 수도 있습니다. 그들의 버전에서는 UC 샌디에이고 학생들이 텍스트 채팅 앱을 사용했습니다. 일부는 심판, 일부는 인간 증인, GPT-4.5는 컴퓨터 증인 역할을 맡았습니다. 각 심판은 튜링의 원래 형식에 충실하게 인간과 컴퓨터와 동시에 대화했습니다.
컴퓨터 증인 역할을 위해 다양한 대규모 언어 모델을 사용했으며, 심판의 도전에 따라 프롬프트를 제공했습니다. GPT-4.5는 최소 정보 프롬프트와 젊고 내성적이며 인터넷에 능통하고 속어를 사용하는 사람처럼 행동하라는 상세 지침이 포함된 PERSONA라는 두 가지 프롬프트로 테스트되었습니다.
결과
그들은 또한 OpenAI의 이전 모델 GPT-4o, Meta Platforms의 Llama 3.1 405b, 1960년대 챗봇 ELIZA 등 세 가지 다른 AI 프로그램을 테스트했습니다. ELIZA는 대규모 언어 모델이 우연히 인간을 속이는지, 아니면 실제로 더 나은지 확인하기 위해 포함되었습니다.
존스와 버겐에 따르면, GPT-4.5는 73%의 시간 동안 인간 심판을 속여 인간이라고 믿게 만들었습니다—그들이 말하는 "승률"입니다. 이는 다른 모델들(21%에서 56% 사이)보다 훨씬 나은 성적으로, 비슷한 상세 프롬프트에도 불구하고 그렇습니다. 작년 GPT-4 테스트의 승률 54%에서 크게 도약한 것으로, 이는 무작위 확률을 간신히 넘는 수준이었습니다.
존스와 버겐은 심판이 AI에 속았을 뿐만 아니라 실제 인간 참가자보다 AI가 인간이라고 믿을 가능성이 더 높았다는 것을 발견했습니다.
테스트가 정말 지능을 측정하는가?
그렇다면 인간이 채팅에서 컴퓨터와 사람을 구분하지 못한다는 것은 무엇을 의미할까요? 수십 년간 논쟁된 큰 질문은 튜링 테스트가 정말 지능을 측정하는지입니다. 존스와 버겐은 기계가 다양한 시나리오에 적응하는 데 너무 능숙해져서 인간으로 설득력 있게 통과할 수 있다고 제안합니다. 인간이 만든 PERSONA 프롬프트는 GPT-4.5가 적응해 활용한 것입니다.
하지만 문제는 인간이 지능을 인식하는 데 서툴 수도 있다는 점입니다. 저자들은 고대 챗봇 ELIZA가 23%의 시간 동안 심판을 속였는데, 이는 더 똑똑해서가 아니라 AI에 대한 기대를 충족하지 않았기 때문이라고 지적합니다. 일부 심판은 ELIZA가 "냉소적"이거나 "무례"하다고 생각해 인간이라고 믿었는데, 이는 AI에서 기대하지 않은 특성이었습니다.
이는 심판이 인간과 AI가 어떻게 행동해야 한다는 가정에 영향을 받는다는 것을 시사합니다. 흥미롭게도 심판은 튜링이 중요하다고 생각했던 지식에 많이 집중하지 않았습니다. 대신, 지식이 부족해 보이는 증인을 인간으로 간주할 가능성이 더 높았습니다.
사교성, 지능 아님
이 모든 것은 인간이 지능보다는 사교성을 포착했다는 아이디어를 가리킵니다. 존스와 버겐은 튜링 테스트가 실제로 지능 테스트가 아니라 인간다움 테스트라고 결론짓습니다.
튜링은 지능이 인간다움을 보이는 데 가장 큰 장애물이라고 생각했을지 모르지만, 기계가 우리에게 가까워질수록 다른 차이점이 더 두드러집니다. 지능만으로는 더 이상 설득력 있는 인간다움을 보일 수 없습니다.
논문에서 직접 언급되지 않은 것은 인간이 사람이나 기계와 컴퓨터로 타이핑하는 데 너무 익숙해져 튜링 테스트가 예전처럼 새로운 인간-컴퓨터 상호작용 테스트가 아니라는 점입니다. 이제는 온라인 인간 습관 테스트에 더 가깝습니다.
저자들은 지능이 너무 복잡하고 다면적이어서 단일 테스트로는 결정적이지 않다고 제안하며 테스트 확장을 제안합니다. AI 전문가를 심판으로 사용하거나 금전적 인센티브를 추가해 심판이 더 면밀히 조사하도록 하는 등의 다른 설계가 결과에 대한 태도와 기대의 영향을 보여줄 수 있습니다.
그들은 튜링 테스트가 그림의 일부일 수 있지만, 다른 종류의 증거와 함께 고려해야 한다고 결론짓습니다. 이는 AI 연구에서 인간을 "루프에 포함"시켜 기계의 행동을 평가하는 추세와 일치합니다.
인간 판단이 충분한가?
하지만 장기적으로 인간 판단이 충분할지에 대한 질문이 여전히 남아 있습니다. 영화 Blade Runner에서 인간은 인간과 복제 로봇을 구분하기 위해 "Voight-Kampff"라는 기계를 사용합니다. AGI를 추구하며 그것이 무엇인지 정의하는 데 어려움을 겪으면서, 우리는 기계 지능을 평가하기 위해 기계에 의존하게 될지도 모릅니다.
최소한, 인간이 다른 인간을 속이려는 프롬프트로 무엇을 "생각"하는지 기계에 물어볼 필요가 있을지도 모릅니다. AI 연구의 세상은 점점 더 흥미로워지고 있습니다.










 놀라운 디지털 혁신으로 메타버스에서 마이클 잭슨을 재창조하는 AI
인공지능은 창의성, 엔터테인먼트, 문화 유산에 대한 우리의 이해를 근본적으로 바꾸고 있습니다. 마이클 잭슨에 대한 인공지능의 해석을 통해 최첨단 기술이 어떻게 전설적인 문화 인물에 새로운 생명을 불어넣을 수 있는지 살펴봅니다. 슈퍼 히어로의 화신에서 판타지 세계의 전사에 이르기까지 획기적인 변신은 디지털 아트와 가상 세계 경험의 지평을 넓히는 동시에 팝의
놀라운 디지털 혁신으로 메타버스에서 마이클 잭슨을 재창조하는 AI
인공지능은 창의성, 엔터테인먼트, 문화 유산에 대한 우리의 이해를 근본적으로 바꾸고 있습니다. 마이클 잭슨에 대한 인공지능의 해석을 통해 최첨단 기술이 어떻게 전설적인 문화 인물에 새로운 생명을 불어넣을 수 있는지 살펴봅니다. 슈퍼 히어로의 화신에서 판타지 세계의 전사에 이르기까지 획기적인 변신은 디지털 아트와 가상 세계 경험의 지평을 넓히는 동시에 팝의
 훈련이 AI로 인한 인지 오프로딩 효과를 완화할 수 있나요?
최근 Unite.ai의 'ChatGPT가 뇌를 고갈시킬 수 있습니다: 인공지능 시대의 인지적 부채'라는 제목의 기사에서 MIT의 연구 결과를 조명했습니다. 저널리스트 알렉스 맥팔랜드는 과도한 AI 의존도가 어떻게 필수적인 인지 능력, 특히 비판적 사고와 판단력을 약화시킬 수 있는지에 대한 설득력 있는 증거를 자세히 설명했습니다. 이러한 연구 결과는 다른 수
훈련이 AI로 인한 인지 오프로딩 효과를 완화할 수 있나요?
최근 Unite.ai의 'ChatGPT가 뇌를 고갈시킬 수 있습니다: 인공지능 시대의 인지적 부채'라는 제목의 기사에서 MIT의 연구 결과를 조명했습니다. 저널리스트 알렉스 맥팔랜드는 과도한 AI 의존도가 어떻게 필수적인 인지 능력, 특히 비판적 사고와 판단력을 약화시킬 수 있는지에 대한 설득력 있는 증거를 자세히 설명했습니다. 이러한 연구 결과는 다른 수
 더 나은 데이터 인사이트를 위한 AI 기반 그래프 및 시각화를 쉽게 생성하기
최신 데이터 분석에는 복잡한 정보를 직관적으로 시각화할 수 있어야 합니다. AI 기반 그래프 생성 솔루션은 전문가들이 원시 데이터를 매력적인 시각적 스토리로 변환하는 방법에 혁신을 일으키며 필수적인 자산으로 부상했습니다. 이러한 지능형 시스템은 정밀도를 유지하면서 수동 차트 생성을 제거하여 기술 및 비기술 사용자 모두 자동화된 시각화를 통해 실행 가능한 인
2025년 8월 20일 오후 6시 1분 15초 GMT+09:00
더 나은 데이터 인사이트를 위한 AI 기반 그래프 및 시각화를 쉽게 생성하기
최신 데이터 분석에는 복잡한 정보를 직관적으로 시각화할 수 있어야 합니다. AI 기반 그래프 생성 솔루션은 전문가들이 원시 데이터를 매력적인 시각적 스토리로 변환하는 방법에 혁신을 일으키며 필수적인 자산으로 부상했습니다. 이러한 지능형 시스템은 정밀도를 유지하면서 수동 차트 생성을 제거하여 기술 및 비기술 사용자 모두 자동화된 시각화를 통해 실행 가능한 인
2025년 8월 20일 오후 6시 1분 15초 GMT+09:00
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?
0
2025년 8월 11일 오후 3시 20분 39초 GMT+09:00
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
0
2025년 8월 3일 오전 12시 7분 14초 GMT+09:00
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
0
2025년 8월 1일 오후 3시 8분 50초 GMT+09:00
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
0













