
















 首頁
首頁圖靈測試問題被OpenAI的GPT-4.5暴露
圖靈測試,傳奇人物艾倫·圖靈的創意結晶,長期以來一直是人工智慧領域的基準。但讓我們先澄清一個常見的誤解:通過圖靈測試並不一定意味著機器能像人類一樣「思考」。它更多是關於說服人類相信它是人類。
加州大學聖地牙哥分校的最新研究將焦點投向了OpenAI的最新模型GPT-4.5。這款AI現在能比人類更有效地騙過人類,讓人相信他們在與另一個人聊天。這在AI界可是件大事——就像看一場魔術表演,你知道背後的秘密,但仍然感到震驚。
人工通用智慧的證明?
但關鍵在於:即使是加州大學聖地牙哥分校的研究人員也不願僅因AI模型通過圖靈測試就宣稱我們已實現「人工通用智慧」(AGI)。AGI是AI的聖杯——能像人類一樣思考和處理資訊的機器。
來自聖塔菲研究所的AI學者梅蘭妮·米契爾在《科學》期刊中指出,圖靈測試更多是測試人類的假設,而非真正的智慧。當然,AI可能聽起來流暢且令人信服,但這與真正的通用智慧不同。這就像擅長下棋——令人印象深刻,但並非全貌。
這股熱潮源自加州大學聖地牙哥分校的卡梅倫·瓊斯和本傑明·伯根發表在arXiv預印伺服器上的論文,標題為「大型語言模型通過圖靈測試」。他們多年來在加州大學聖地牙哥分校本科生的協助下進行這項實驗,這是超過800項關於電腦通過圖靈測試的聲明與反駁的一部分。
圖靈測試如何運作
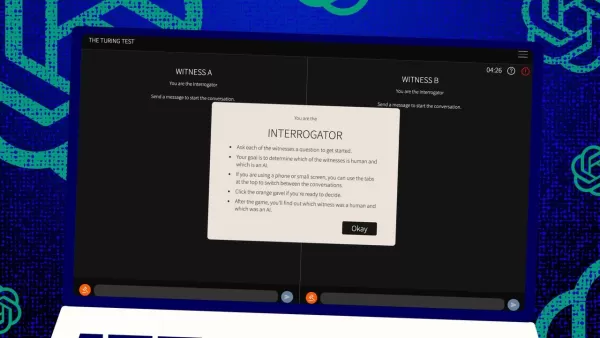
那麼,這項測試是如何進行的?最初,圖靈設想它是一個由人類「評審」與兩個「證人」(一個是人類,一個是電腦)通過文字訊息進行的遊戲。證人的挑戰是說服評審他們是人類。評審知道其中一個是人類,但不知道是哪個,必須做出猜測。這是一個三方設置,既關乎電腦的能力,也關乎感知與信念。
瓊斯和伯根對這一經典設置進行了改進,你甚至可以在線上試玩,扮演評審或證人。在他們的版本中,加州大學聖地牙哥分校的學生使用文字聊天應用程式。有些人扮演評審,其他人扮演人類證人,而GPT-4.5則扮演電腦證人。每位評審同時與人類和電腦聊天,忠於圖靈的原始格式。
為了扮演電腦證人,他們使用了不同的大型語言模型,根據評審的挑戰提供提示。GPT-4.5接受了兩種不同的提示測試:一種提供最少資訊,另一種名為PERSONA,包含詳細指令,要求其表現得像一個年輕、內向、熟悉網路並使用俚語的人。
測試結果
他們還測試了三個其他AI程式:OpenAI的先前模型GPT-4o、Meta Platforms的Llama 3.1 405b,以及1960年代的古老聊天機器人ELIZA。他們納入ELIZA是為了檢驗大型語言模型是否只是偶然欺騙人類,或者它們確實更出色。
根據瓊斯和伯根的說法,GPT-4.5在73%的情況下成功讓人類評審相信它是人類——他們稱之為「勝率」。這比其他模型(得分在21%至56%之間,即使使用類似的詳細提示)表現好得多。與去年的GPT-4測試相比,這是一個巨大的進步,當時的勝率僅為54%,勉強高於隨機猜測。
瓊斯和伯根發現,評審不僅被AI欺騙,甚至更可能相信AI是人類,而不是真正的人類參與者。
這項測試真的是智慧的衡量標準嗎?
那麼,人類無法在聊天中分辨電腦與人的意義何在?數十年來一直爭論的大問題是,圖靈測試是否真正衡量智慧。瓊斯和伯根認為,或許機器只是變得非常擅長適應不同情境,以致能令人信服地冒充人類。由人類創建的PERSONA提示被GPT-4.5充分利用,成為其優勢。
但問題在於:也許人類只是不擅長辨識智慧。作者指出,古老的聊天機器人ELIZA在23%的情況下騙過評審,不是因為它更聰明,而是因為它不符合評審對AI的預期。有些評審認為它是人類,因為它顯得「諷刺」或「粗魯」,這是他們未預料的AI行為。
這表明評審受到對人類和AI行為的假設影響,而非僅選擇看似最聰明的對象。有趣的是,評審並未過多關注知識,而圖靈認為知識是關鍵。相反,如果證人似乎缺乏知識,他們更可能被認為是人類。
社交能力,而非智慧
這一切都指向一個觀點:人類更注重社交能力而非智慧。瓊斯和伯根得出結論,圖靈測試其實不是智慧的測試,而是人類相似度的測試。
圖靈可能認為智慧是表現得像人類的最大障礙,但隨著機器越來越接近人類,其他差異變得更顯著。僅靠智慧已不足以令人信服地像人類。
論文中未直接提到的是,人類如此習慣在電腦上打字,無論是與人還是機器互動,圖靈測試已不再是過去那種新奇的人機交互測試。它現在更像是對線上人類習慣的測試。
作者建議,鑑於智慧的複雜性和多面性,圖靈測試可能需要擴展,單一測試無法決定一切。他們提出不同的設計,例如使用AI專家作為評審,或加入經濟激勵讓評審更仔細審查。這些改變可能顯示出態度和期望對結果的影響有多大。
他們得出結論,圖靈測試可能只是整體的一部分,應與其他證據一同考慮。這與AI研究中越來越多的趨勢一致,即讓人類「參與其中」,評估機器的表現。
人類判斷足夠嗎?
但長期來看,人類判斷是否足夠仍是一個問題。在電影《銀翼殺手》中,人類使用「沃伊特-坎普夫」機器來區分人類與複製人機器人。隨著我們追求AGI,並努力定義它究竟是什麼,我們最終可能需要依靠機器來評估機器的智慧。
或者,至少,我們可能需要問機器它們對人類試圖用提示欺騙其他人類的「看法」。AI研究的世界充滿驚奇,且越來越有趣。
相關文章
 Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
馬斯克的 Grok:1.5 兆個參數與游標程式碼吸收——是遊戲規則的改變者,還是虛張聲勢?
伊隆·馬斯克終於有所行動。在人工智慧程式設計的競賽中,OpenAI 和 Anthropic 正加速前進,而 xAI 似乎落後了。馬斯克曾多次表示其目標是與 Claude 抗衡,然而儘管 Grok4.X 系列已進行多次更新,成果在理論上看似不錯,但在實際應用中卻未能達標,兩者之間的差距幾乎未見縮小。不過,這次他握有一張新王牌。馬斯克在 X 平台上證實,Grok 的新版本即將問世。 這款基礎模型第九版
相關專題推薦
商業
Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
馬斯克的 Grok:1.5 兆個參數與游標程式碼吸收——是遊戲規則的改變者,還是虛張聲勢?
伊隆·馬斯克終於有所行動。在人工智慧程式設計的競賽中,OpenAI 和 Anthropic 正加速前進,而 xAI 似乎落後了。馬斯克曾多次表示其目標是與 Claude 抗衡,然而儘管 Grok4.X 系列已進行多次更新,成果在理論上看似不錯,但在實際應用中卻未能達標,兩者之間的差距幾乎未見縮小。不過,這次他握有一張新王牌。馬斯克在 X 平台上證實,Grok 的新版本即將問世。 這款基礎模型第九版
相關專題推薦
商業
 最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
 10 個工具
10 個工具
 xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai
教育與學習
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai
聊天機器人
最佳 AI 調情與對話訓練工具:即時提升社交魅力與自信
在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai
代碼
最適合自動化單元測試的最佳AI工具:一鍵生成Jest、PyTest和JUnit測試用例
探索2026年最新評選出的頂級AI工具,這些工具專為自動化單元測試而設計。我們精心挑選了那些功能強大、能夠改變開發流程的工具,它們能夠幫助您快速生成Jest、PyTest和JUnit測試用例。在XIX.AI平臺上,您可以免費檢視各種選項,並透過實際測試結果以及每週更新的排名來了解它們的優劣。立即利用這些AI工具,提升您的開發效率吧!
10 個工具
xix.ai

 評論 (4)
0/500
評論 (4)
0/500
![CarlLewis]()
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?
![JamesLopez]()
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
![DavidGonzález]()
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
![PaulWilson]()
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
圖靈測試,傳奇人物艾倫·圖靈的創意結晶,長期以來一直是人工智慧領域的基準。但讓我們先澄清一個常見的誤解:通過圖靈測試並不一定意味著機器能像人類一樣「思考」。它更多是關於說服人類相信它是人類。
加州大學聖地牙哥分校的最新研究將焦點投向了OpenAI的最新模型GPT-4.5。這款AI現在能比人類更有效地騙過人類,讓人相信他們在與另一個人聊天。這在AI界可是件大事——就像看一場魔術表演,你知道背後的秘密,但仍然感到震驚。
人工通用智慧的證明?
但關鍵在於:即使是加州大學聖地牙哥分校的研究人員也不願僅因AI模型通過圖靈測試就宣稱我們已實現「人工通用智慧」(AGI)。AGI是AI的聖杯——能像人類一樣思考和處理資訊的機器。
來自聖塔菲研究所的AI學者梅蘭妮·米契爾在《科學》期刊中指出,圖靈測試更多是測試人類的假設,而非真正的智慧。當然,AI可能聽起來流暢且令人信服,但這與真正的通用智慧不同。這就像擅長下棋——令人印象深刻,但並非全貌。
這股熱潮源自加州大學聖地牙哥分校的卡梅倫·瓊斯和本傑明·伯根發表在arXiv預印伺服器上的論文,標題為「大型語言模型通過圖靈測試」。他們多年來在加州大學聖地牙哥分校本科生的協助下進行這項實驗,這是超過800項關於電腦通過圖靈測試的聲明與反駁的一部分。
圖靈測試如何運作
那麼,這項測試是如何進行的?最初,圖靈設想它是一個由人類「評審」與兩個「證人」(一個是人類,一個是電腦)通過文字訊息進行的遊戲。證人的挑戰是說服評審他們是人類。評審知道其中一個是人類,但不知道是哪個,必須做出猜測。這是一個三方設置,既關乎電腦的能力,也關乎感知與信念。
瓊斯和伯根對這一經典設置進行了改進,你甚至可以在線上試玩,扮演評審或證人。在他們的版本中,加州大學聖地牙哥分校的學生使用文字聊天應用程式。有些人扮演評審,其他人扮演人類證人,而GPT-4.5則扮演電腦證人。每位評審同時與人類和電腦聊天,忠於圖靈的原始格式。
為了扮演電腦證人,他們使用了不同的大型語言模型,根據評審的挑戰提供提示。GPT-4.5接受了兩種不同的提示測試:一種提供最少資訊,另一種名為PERSONA,包含詳細指令,要求其表現得像一個年輕、內向、熟悉網路並使用俚語的人。
測試結果
他們還測試了三個其他AI程式:OpenAI的先前模型GPT-4o、Meta Platforms的Llama 3.1 405b,以及1960年代的古老聊天機器人ELIZA。他們納入ELIZA是為了檢驗大型語言模型是否只是偶然欺騙人類,或者它們確實更出色。
根據瓊斯和伯根的說法,GPT-4.5在73%的情況下成功讓人類評審相信它是人類——他們稱之為「勝率」。這比其他模型(得分在21%至56%之間,即使使用類似的詳細提示)表現好得多。與去年的GPT-4測試相比,這是一個巨大的進步,當時的勝率僅為54%,勉強高於隨機猜測。
瓊斯和伯根發現,評審不僅被AI欺騙,甚至更可能相信AI是人類,而不是真正的人類參與者。
這項測試真的是智慧的衡量標準嗎?
那麼,人類無法在聊天中分辨電腦與人的意義何在?數十年來一直爭論的大問題是,圖靈測試是否真正衡量智慧。瓊斯和伯根認為,或許機器只是變得非常擅長適應不同情境,以致能令人信服地冒充人類。由人類創建的PERSONA提示被GPT-4.5充分利用,成為其優勢。
但問題在於:也許人類只是不擅長辨識智慧。作者指出,古老的聊天機器人ELIZA在23%的情況下騙過評審,不是因為它更聰明,而是因為它不符合評審對AI的預期。有些評審認為它是人類,因為它顯得「諷刺」或「粗魯」,這是他們未預料的AI行為。
這表明評審受到對人類和AI行為的假設影響,而非僅選擇看似最聰明的對象。有趣的是,評審並未過多關注知識,而圖靈認為知識是關鍵。相反,如果證人似乎缺乏知識,他們更可能被認為是人類。
社交能力,而非智慧
這一切都指向一個觀點:人類更注重社交能力而非智慧。瓊斯和伯根得出結論,圖靈測試其實不是智慧的測試,而是人類相似度的測試。
圖靈可能認為智慧是表現得像人類的最大障礙,但隨著機器越來越接近人類,其他差異變得更顯著。僅靠智慧已不足以令人信服地像人類。
論文中未直接提到的是,人類如此習慣在電腦上打字,無論是與人還是機器互動,圖靈測試已不再是過去那種新奇的人機交互測試。它現在更像是對線上人類習慣的測試。
作者建議,鑑於智慧的複雜性和多面性,圖靈測試可能需要擴展,單一測試無法決定一切。他們提出不同的設計,例如使用AI專家作為評審,或加入經濟激勵讓評審更仔細審查。這些改變可能顯示出態度和期望對結果的影響有多大。
他們得出結論,圖靈測試可能只是整體的一部分,應與其他證據一同考慮。這與AI研究中越來越多的趨勢一致,即讓人類「參與其中」,評估機器的表現。
人類判斷足夠嗎?
但長期來看,人類判斷是否足夠仍是一個問題。在電影《銀翼殺手》中,人類使用「沃伊特-坎普夫」機器來區分人類與複製人機器人。隨著我們追求AGI,並努力定義它究竟是什麼,我們最終可能需要依靠機器來評估機器的智慧。
或者,至少,我們可能需要問機器它們對人類試圖用提示欺騙其他人類的「看法」。AI研究的世界充滿驚奇,且越來越有趣。










 Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
 DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
 馬斯克的 Grok:1.5 兆個參數與游標程式碼吸收——是遊戲規則的改變者,還是虛張聲勢?
伊隆·馬斯克終於有所行動。在人工智慧程式設計的競賽中,OpenAI 和 Anthropic 正加速前進,而 xAI 似乎落後了。馬斯克曾多次表示其目標是與 Claude 抗衡,然而儘管 Grok4.X 系列已進行多次更新,成果在理論上看似不錯,但在實際應用中卻未能達標,兩者之間的差距幾乎未見縮小。不過,這次他握有一張新王牌。馬斯克在 X 平台上證實,Grok 的新版本即將問世。 這款基礎模型第九版
馬斯克的 Grok:1.5 兆個參數與游標程式碼吸收——是遊戲規則的改變者,還是虛張聲勢?
伊隆·馬斯克終於有所行動。在人工智慧程式設計的競賽中,OpenAI 和 Anthropic 正加速前進,而 xAI 似乎落後了。馬斯克曾多次表示其目標是與 Claude 抗衡,然而儘管 Grok4.X 系列已進行多次更新,成果在理論上看似不錯,但在實際應用中卻未能達標,兩者之間的差距幾乎未見縮小。不過,這次他握有一張新王牌。馬斯克在 X 平台上證實,Grok 的新版本即將問世。 這款基礎模型第九版

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

探索2026年最新評選出的頂級AI工具,這些工具專為自動化單元測試而設計。我們精心挑選了那些功能強大、能夠改變開發流程的工具,它們能夠幫助您快速生成Jest、PyTest和JUnit測試用例。在XIX.AI平臺上,您可以免費檢視各種選項,並透過實際測試結果以及每週更新的排名來了解它們的優劣。立即利用這些AI工具,提升您的開發效率吧!
10 個工具
xix.ai

Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?













