
















 Heim
HeimGPT-4.5 enthüllt Problem des Turing-Tests
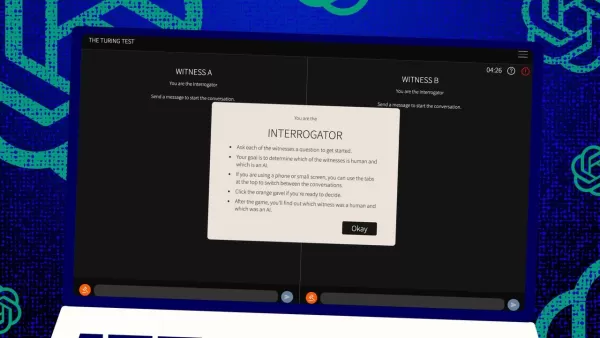
Der Turing-Test, eine Erfindung des legendären Alan Turing, ist seit Langem ein Maßstab in der Welt der künstlichen Intelligenz. Aber lassen Sie uns gleich zu Beginn ein weitverbreitetes Missverständnis klären: Das Bestehen des Turing-Tests bedeutet nicht unbedingt, dass eine Maschine „denkt“ wie ein Mensch. Es geht mehr darum, Menschen davon zu überzeugen, dass sie es tut.
Jüngste Forschungsergebnisse der University of California in San Diego haben OpenAI's neuestes Modell, GPT-4.5, ins Rampenlicht gerückt. Diese KI kann Menschen nun noch effektiver täuschen, indem sie sie glauben lässt, sie chatten mit einer anderen Person, sogar besser als Menschen einander von ihrer Menschlichkeit überzeugen können. Das ist eine ziemlich große Sache in der Welt der KI – es ist, als würde man einem Zaubertrick zusehen, bei dem man das Geheimnis kennt, aber es einem trotzdem den Verstand raubt.
Beweis für AGI?
Doch hier kommt der Haken: Selbst die Forscher an der UC San Diego sind nicht bereit zu behaupten, dass wir „künstliche allgemeine Intelligenz“ (AGI) erreicht haben, nur weil ein KI-Modell den Turing-Test besteht. AGI wäre der heilige Gral der KI – Maschinen, die genauso denken und Informationen verarbeiten können wie Menschen.
Melanie Mitchell, eine KI-Wissenschaftlerin am Santa Fe Institute, argumentiert in der Zeitschrift Science, dass der Turing-Test mehr die menschlichen Annahmen prüft als tatsächliche Intelligenz. Sicher, eine KI mag flüssig und überzeugend klingen, aber das ist nicht dasselbe wie allgemeine Intelligenz. Es ist, als wäre man gut im Schach – beeindruckend, aber nicht das ganze Bild.
Der neueste Hype dazu stammt aus einem Paper von Cameron Jones und Benjamin Bergen an der UC San Diego, betitelt „Large Language Models Pass the Turing Test“, veröffentlicht auf dem arXiv Pre-Print-Server. Sie führen dieses Experiment seit Jahren durch, mit Unterstützung von UC San Diego-Studenten, und es ist Teil einer langen Forschungsreihe – über 800 Behauptungen und Gegenargumente wurden über Computer gemacht, die den Turing-Test bestehen.
Wie der Turing-Test funktioniert
Wie funktioniert dieser Test also? Ursprünglich stellte Turing ihn sich als ein Spiel mit Textnachrichten zwischen einem menschlichen „Richter“ und zwei „Zeugen“ vor – einer menschlich, einer ein Computer. Die Herausforderung für die Zeugen besteht darin, den Richter davon zu überzeugen, dass sie menschlich sind. Der Richter weiß, dass einer menschlich ist, aber nicht welcher, und muss raten. Es ist ein Dreier-Setup, bei dem es genauso sehr um Wahrnehmung und Glauben geht wie um die Fähigkeiten des Computers.
Jones und Bergen haben diesem klassischen Setup ihre eigene Note gegeben, und Sie können es sogar online ausprobieren, indem Sie als Richter oder Zeuge spielen. In ihrer Version nutzten UC San Diego-Studenten eine Text-Chat-App. Einige spielten den Richter, andere den menschlichen Zeugen, während GPT-4.5 die Rolle des Computerzeugen übernahm. Jeder Richter chattete gleichzeitig mit einem Menschen und einem Computer, getreu Turings ursprünglichem Format.
Um den Computerzeugen zu spielen, verwendeten sie verschiedene große Sprachmodelle, die sie mit Prompts basierend auf den Herausforderungen des Richters fütterten. GPT-4.5 wurde mit zwei verschiedenen Prompts getestet: einer mit minimalen Informationen und ein anderer namens PERSONA, der detaillierte Anweisungen enthielt, sich wie eine junge, introvertierte, internetaffine Person zu verhalten, die Slang verwendet.
Die Ergebnisse
Sie testeten auch drei weitere KI-Programme: OpenAI's vorheriges Modell, GPT-4o; Meta Platforms' Llama 3.1 405b; und den uralten Chatbot aus den 1960er Jahren, ELIZA. Sie nahmen ELIZA auf, um zu sehen, ob die großen Sprachmodelle die Menschen nur zufällig täuschten oder ob sie tatsächlich besser waren.
Laut Jones und Bergen täuschte GPT-4.5 menschliche Richter in 73 % der Fälle, indem es sie glauben ließ, es sei menschlich – eine „Gewinnrate“, wie sie es nennen. Das ist viel besser als die anderen Modelle, die zwischen 21 % und 56 % erreichten, selbst mit ähnlich detaillierten Prompts. Und es ist ein riesiger Sprung gegenüber dem Test von GPT-4 im letzten Jahr, der eine Gewinnrate von nur 54 % hatte, knapp über dem Zufall.
Jones und Bergen stellten fest, dass die Richter nicht nur von der KI getäuscht wurden, sondern tatsächlich eher glaubten, sie sei menschlich als die echten menschlichen Teilnehmer.
Ist der Test wirklich ein Maß für Intelligenz?
Was bedeutet es also, dass Menschen in einem Chat keinen Computer von einem Menschen unterscheiden können? Die große Frage, die seit Jahrzehnten diskutiert wird, ist, ob der Turing-Test wirklich Intelligenz misst. Jones und Bergen legen nahe, dass Maschinen vielleicht einfach so gut darin geworden sind, sich an verschiedene Szenarien anzupassen, dass sie überzeugend als menschlich durchgehen können. Der PERSONA-Prompt, von Menschen erstellt, ist etwas, das GPT-4.5 zu seinem Vorteil anpasste und nutzte.
Aber es gibt einen Haken: Vielleicht sind Menschen einfach schlecht darin, Intelligenz zu erkennen. Die Autoren weisen darauf hin, dass ELIZA, der uralte Chatbot, die Richter in 23 % der Fälle täuschte, nicht weil er schlauer war, sondern weil er nicht den Erwartungen entsprach, die sie an eine KI hatten. Einige Richter dachten, er sei menschlich, weil er „sarkastisch“ oder „grob“ war, was sie von einer KI nicht erwarteten.
Dies deutet darauf hin, dass Richter von ihren Annahmen darüber beeinflusst werden, wie Menschen und KIs sich verhalten sollten, anstatt nur den intelligentesten Akteur auszuwählen. Interessanterweise konzentrierten sich die Richter nicht stark auf Wissen, was Turing für entscheidend hielt. Stattdessen hielten sie einen Zeugen eher für menschlich, wenn er Wissen zu fehlen schien.
Geselligkeit, nicht Intelligenz
All dies deutet darauf hin, dass Menschen eher auf Geselligkeit als auf Intelligenz reagierten. Jones und Bergen schlussfolgern, dass der Turing-Test nicht wirklich ein Test der Intelligenz ist – sondern ein Test der Menschähnlichkeit.
Turing mag gedacht haben, dass Intelligenz die größte Hürde sei, um menschlich zu wirken, aber je näher Maschinen uns kommen, desto offensichtlicher werden andere Unterschiede. Intelligenz allein reicht nicht mehr aus, um überzeugend menschlich zu wirken.
Was im Paper nicht direkt gesagt wird, ist, dass Menschen so sehr daran gewöhnt sind, auf Computern zu tippen, ob mit einer Person oder einer Maschine, dass der Turing-Test nicht mehr der neuartige Mensch-Computer-Interaktionstest ist, der er einmal war. Er ist jetzt eher ein Test für menschliche Online-Gewohnheiten.
Die Autoren schlagen vor, dass der Test erweitert werden müsste, da Intelligenz so komplex und vielschichtig ist, dass kein einzelner Test entscheidend sein kann. Sie schlagen verschiedene Designs vor, wie die Verwendung von KI-Experten als Richter oder das Hinzufügen finanzieller Anreize, um die Richter genauer prüfen zu lassen. Diese Änderungen könnten zeigen, wie sehr Einstellungen und Erwartungen die Ergebnisse beeinflussen.
Sie schlussfolgern, dass der Turing-Test zwar Teil des Bildes sein mag, aber neben anderen Arten von Beweisen betrachtet werden sollte. Dies steht im Einklang mit einem wachsenden Trend in der KI-Forschung, Menschen „in die Schleife“ einzubeziehen, um zu bewerten, was Maschinen tun.
Reicht menschliches Urteil aus?
Aber es bleibt die Frage, ob menschliches Urteil auf lange Sicht ausreichen wird. Im Film Blade Runner verwenden Menschen eine Maschine, den „Voight-Kampff“, um Menschen von Replikanten-Robotern zu unterscheiden. Während wir nach AGI streben und darum kämpfen, überhaupt zu definieren, was es ist, könnten wir am Ende darauf angewiesen sein, Maschinen die Intelligenz von Maschinen bewerten zu lassen.
Oder zumindest könnten wir Maschinen fragen müssen, was sie „denken“ über Menschen, die versuchen, andere Menschen mit Prompts zu täuschen. Es ist eine wilde Welt dort draußen in der KI-Forschung, und sie wird nur noch interessanter.
Verwandter Artikel
 DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko
OpenAI ändert heimlich seine Satzung, um die Entlassung von Altman zu erschweren
Nach dem putschähnlichen Vorfall im Jahr 2023 hat OpenAI den Schutz für CEO Sam Altman durch eine Aktualisierung der Unternehmenssatzung weiter gefestigt. Kürzlich veröffentlichte Gerichtsdokumente ze
Empfehlungen zu verwandten Spezialthemen
Geschäft
DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko
OpenAI ändert heimlich seine Satzung, um die Entlassung von Altman zu erschweren
Nach dem putschähnlichen Vorfall im Jahr 2023 hat OpenAI den Schutz für CEO Sam Altman durch eine Aktualisierung der Unternehmenssatzung weiter gefestigt. Kürzlich veröffentlichte Gerichtsdokumente ze
Empfehlungen zu verwandten Spezialthemen
Geschäft
 Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
 10 Tools
10 Tools
 xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai
Code
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

 Kommentare (4)
Kommentare (4)
![CarlLewis]()
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?
![JamesLopez]()
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
![DavidGonzález]()
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
![PaulWilson]()
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
Der Turing-Test, eine Erfindung des legendären Alan Turing, ist seit Langem ein Maßstab in der Welt der künstlichen Intelligenz. Aber lassen Sie uns gleich zu Beginn ein weitverbreitetes Missverständnis klären: Das Bestehen des Turing-Tests bedeutet nicht unbedingt, dass eine Maschine „denkt“ wie ein Mensch. Es geht mehr darum, Menschen davon zu überzeugen, dass sie es tut.
Jüngste Forschungsergebnisse der University of California in San Diego haben OpenAI's neuestes Modell, GPT-4.5, ins Rampenlicht gerückt. Diese KI kann Menschen nun noch effektiver täuschen, indem sie sie glauben lässt, sie chatten mit einer anderen Person, sogar besser als Menschen einander von ihrer Menschlichkeit überzeugen können. Das ist eine ziemlich große Sache in der Welt der KI – es ist, als würde man einem Zaubertrick zusehen, bei dem man das Geheimnis kennt, aber es einem trotzdem den Verstand raubt.
Beweis für AGI?
Doch hier kommt der Haken: Selbst die Forscher an der UC San Diego sind nicht bereit zu behaupten, dass wir „künstliche allgemeine Intelligenz“ (AGI) erreicht haben, nur weil ein KI-Modell den Turing-Test besteht. AGI wäre der heilige Gral der KI – Maschinen, die genauso denken und Informationen verarbeiten können wie Menschen.
Melanie Mitchell, eine KI-Wissenschaftlerin am Santa Fe Institute, argumentiert in der Zeitschrift Science, dass der Turing-Test mehr die menschlichen Annahmen prüft als tatsächliche Intelligenz. Sicher, eine KI mag flüssig und überzeugend klingen, aber das ist nicht dasselbe wie allgemeine Intelligenz. Es ist, als wäre man gut im Schach – beeindruckend, aber nicht das ganze Bild.
Der neueste Hype dazu stammt aus einem Paper von Cameron Jones und Benjamin Bergen an der UC San Diego, betitelt „Large Language Models Pass the Turing Test“, veröffentlicht auf dem arXiv Pre-Print-Server. Sie führen dieses Experiment seit Jahren durch, mit Unterstützung von UC San Diego-Studenten, und es ist Teil einer langen Forschungsreihe – über 800 Behauptungen und Gegenargumente wurden über Computer gemacht, die den Turing-Test bestehen.
Wie der Turing-Test funktioniert
Wie funktioniert dieser Test also? Ursprünglich stellte Turing ihn sich als ein Spiel mit Textnachrichten zwischen einem menschlichen „Richter“ und zwei „Zeugen“ vor – einer menschlich, einer ein Computer. Die Herausforderung für die Zeugen besteht darin, den Richter davon zu überzeugen, dass sie menschlich sind. Der Richter weiß, dass einer menschlich ist, aber nicht welcher, und muss raten. Es ist ein Dreier-Setup, bei dem es genauso sehr um Wahrnehmung und Glauben geht wie um die Fähigkeiten des Computers.
Jones und Bergen haben diesem klassischen Setup ihre eigene Note gegeben, und Sie können es sogar online ausprobieren, indem Sie als Richter oder Zeuge spielen. In ihrer Version nutzten UC San Diego-Studenten eine Text-Chat-App. Einige spielten den Richter, andere den menschlichen Zeugen, während GPT-4.5 die Rolle des Computerzeugen übernahm. Jeder Richter chattete gleichzeitig mit einem Menschen und einem Computer, getreu Turings ursprünglichem Format.
Um den Computerzeugen zu spielen, verwendeten sie verschiedene große Sprachmodelle, die sie mit Prompts basierend auf den Herausforderungen des Richters fütterten. GPT-4.5 wurde mit zwei verschiedenen Prompts getestet: einer mit minimalen Informationen und ein anderer namens PERSONA, der detaillierte Anweisungen enthielt, sich wie eine junge, introvertierte, internetaffine Person zu verhalten, die Slang verwendet.
Die Ergebnisse
Sie testeten auch drei weitere KI-Programme: OpenAI's vorheriges Modell, GPT-4o; Meta Platforms' Llama 3.1 405b; und den uralten Chatbot aus den 1960er Jahren, ELIZA. Sie nahmen ELIZA auf, um zu sehen, ob die großen Sprachmodelle die Menschen nur zufällig täuschten oder ob sie tatsächlich besser waren.
Laut Jones und Bergen täuschte GPT-4.5 menschliche Richter in 73 % der Fälle, indem es sie glauben ließ, es sei menschlich – eine „Gewinnrate“, wie sie es nennen. Das ist viel besser als die anderen Modelle, die zwischen 21 % und 56 % erreichten, selbst mit ähnlich detaillierten Prompts. Und es ist ein riesiger Sprung gegenüber dem Test von GPT-4 im letzten Jahr, der eine Gewinnrate von nur 54 % hatte, knapp über dem Zufall.
Jones und Bergen stellten fest, dass die Richter nicht nur von der KI getäuscht wurden, sondern tatsächlich eher glaubten, sie sei menschlich als die echten menschlichen Teilnehmer.
Ist der Test wirklich ein Maß für Intelligenz?
Was bedeutet es also, dass Menschen in einem Chat keinen Computer von einem Menschen unterscheiden können? Die große Frage, die seit Jahrzehnten diskutiert wird, ist, ob der Turing-Test wirklich Intelligenz misst. Jones und Bergen legen nahe, dass Maschinen vielleicht einfach so gut darin geworden sind, sich an verschiedene Szenarien anzupassen, dass sie überzeugend als menschlich durchgehen können. Der PERSONA-Prompt, von Menschen erstellt, ist etwas, das GPT-4.5 zu seinem Vorteil anpasste und nutzte.
Aber es gibt einen Haken: Vielleicht sind Menschen einfach schlecht darin, Intelligenz zu erkennen. Die Autoren weisen darauf hin, dass ELIZA, der uralte Chatbot, die Richter in 23 % der Fälle täuschte, nicht weil er schlauer war, sondern weil er nicht den Erwartungen entsprach, die sie an eine KI hatten. Einige Richter dachten, er sei menschlich, weil er „sarkastisch“ oder „grob“ war, was sie von einer KI nicht erwarteten.
Dies deutet darauf hin, dass Richter von ihren Annahmen darüber beeinflusst werden, wie Menschen und KIs sich verhalten sollten, anstatt nur den intelligentesten Akteur auszuwählen. Interessanterweise konzentrierten sich die Richter nicht stark auf Wissen, was Turing für entscheidend hielt. Stattdessen hielten sie einen Zeugen eher für menschlich, wenn er Wissen zu fehlen schien.
Geselligkeit, nicht Intelligenz
All dies deutet darauf hin, dass Menschen eher auf Geselligkeit als auf Intelligenz reagierten. Jones und Bergen schlussfolgern, dass der Turing-Test nicht wirklich ein Test der Intelligenz ist – sondern ein Test der Menschähnlichkeit.
Turing mag gedacht haben, dass Intelligenz die größte Hürde sei, um menschlich zu wirken, aber je näher Maschinen uns kommen, desto offensichtlicher werden andere Unterschiede. Intelligenz allein reicht nicht mehr aus, um überzeugend menschlich zu wirken.
Was im Paper nicht direkt gesagt wird, ist, dass Menschen so sehr daran gewöhnt sind, auf Computern zu tippen, ob mit einer Person oder einer Maschine, dass der Turing-Test nicht mehr der neuartige Mensch-Computer-Interaktionstest ist, der er einmal war. Er ist jetzt eher ein Test für menschliche Online-Gewohnheiten.
Die Autoren schlagen vor, dass der Test erweitert werden müsste, da Intelligenz so komplex und vielschichtig ist, dass kein einzelner Test entscheidend sein kann. Sie schlagen verschiedene Designs vor, wie die Verwendung von KI-Experten als Richter oder das Hinzufügen finanzieller Anreize, um die Richter genauer prüfen zu lassen. Diese Änderungen könnten zeigen, wie sehr Einstellungen und Erwartungen die Ergebnisse beeinflussen.
Sie schlussfolgern, dass der Turing-Test zwar Teil des Bildes sein mag, aber neben anderen Arten von Beweisen betrachtet werden sollte. Dies steht im Einklang mit einem wachsenden Trend in der KI-Forschung, Menschen „in die Schleife“ einzubeziehen, um zu bewerten, was Maschinen tun.
Reicht menschliches Urteil aus?
Aber es bleibt die Frage, ob menschliches Urteil auf lange Sicht ausreichen wird. Im Film Blade Runner verwenden Menschen eine Maschine, den „Voight-Kampff“, um Menschen von Replikanten-Robotern zu unterscheiden. Während wir nach AGI streben und darum kämpfen, überhaupt zu definieren, was es ist, könnten wir am Ende darauf angewiesen sein, Maschinen die Intelligenz von Maschinen bewerten zu lassen.
Oder zumindest könnten wir Maschinen fragen müssen, was sie „denken“ über Menschen, die versuchen, andere Menschen mit Prompts zu täuschen. Es ist eine wilde Welt dort draußen in der KI-Forschung, und sie wird nur noch interessanter.










 DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
 Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko
Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko
 OpenAI ändert heimlich seine Satzung, um die Entlassung von Altman zu erschweren
Nach dem putschähnlichen Vorfall im Jahr 2023 hat OpenAI den Schutz für CEO Sam Altman durch eine Aktualisierung der Unternehmenssatzung weiter gefestigt. Kürzlich veröffentlichte Gerichtsdokumente ze
OpenAI ändert heimlich seine Satzung, um die Entlassung von Altman zu erschweren
Nach dem putschähnlichen Vorfall im Jahr 2023 hat OpenAI den Schutz für CEO Sam Altman durch eine Aktualisierung der Unternehmenssatzung weiter gefestigt. Kürzlich veröffentlichte Gerichtsdokumente ze

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?













