




Problema del Test de Turing Expuesto por el GPT-4.5 de OpenAI
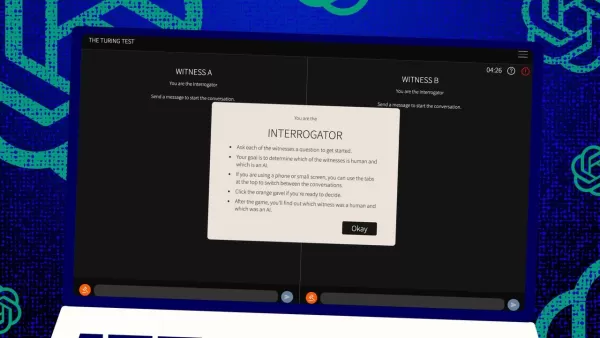
La prueba de Turing, una creación del legendario Alan Turing, ha sido durante mucho tiempo un referente en el mundo de la inteligencia artificial. Pero dejemos clara una idea errónea desde el principio: pasar la prueba de Turing no significa necesariamente que una máquina esté "pensando" como humano. Se trata más de convencer a los humanos de que lo está.
Investigaciones recientes de la Universidad de California en San Diego han destacado el último modelo de OpenAI, GPT-4.5. Esta IA ahora puede engañar a los humanos para que crean que están conversando con otra persona, incluso con más eficacia que los propios humanos al convencerse mutuamente de su humanidad. Eso es algo importante en el mundo de la IA; es como ver un truco de magia donde conoces el secreto, pero aún así te sorprende.
¿Prueba de AGI?
Pero aquí está el punto clave: incluso los investigadores de UC San Diego no están listos para declarar que hemos alcanzado la "inteligencia general artificial" (AGI) solo porque un modelo de IA puede pasar la prueba de Turing. AGI sería el santo grial de la IA: máquinas que puedan pensar y procesar información como lo hacen los humanos.
Melanie Mitchell, una académica de IA del Instituto Santa Fe, argumenta en la revista Science que la prueba de Turing se centra más en probar las suposiciones humanas que en la inteligencia real. Claro, una IA puede sonar fluida y convincente, pero eso no es lo mismo que ser generalmente inteligente. Es como ser bueno en ajedrez: es impresionante, pero no es el panorama completo.
El revuelo más reciente proviene de un artículo de Cameron Jones y Benjamin Bergen en UC San Diego, titulado "Los modelos de lenguaje grandes pasan la prueba de Turing", publicado en el servidor de preimpresión arXiv. Han estado realizando este experimento durante años, con la ayuda de estudiantes de UC San Diego, y forma parte de una larga línea de investigación: se han hecho más de 800 afirmaciones y contraargumentos sobre computadoras que pasan la prueba de Turing.
Cómo funciona la prueba de Turing
Entonces, ¿cómo funciona esta prueba? Originalmente, Turing la imaginó como un juego de mensajes de texto entre un "juez" humano y dos "testigos": uno humano, otro una computadora. El desafío para los testigos es convencer al juez de que son humanos. El juez sabe que uno es humano, pero no cuál, y tiene que adivinar. Es una configuración de tres partes que se centra tanto en la percepción y la creencia como en las capacidades de la computadora.
Jones y Bergen han dado su propio giro a esta configuración clásica, y puedes probarla en línea, jugando como juez o testigo. En su versión, estudiantes de UC San Diego usaron una aplicación de chat de texto. Algunos fueron jueces, otros testigos humanos, mientras que GPT-4.5 asumió el rol del testigo informático. Cada juez conversó con un humano y una computadora al mismo tiempo, manteniendo fielmente el formato original de Turing.
Para interpretar al testigo informático, usaron diferentes modelos de lenguaje grandes, alimentándolos con prompts basados en los desafíos del juez. GPT-4.5 fue probado con dos prompts diferentes: uno con información mínima y otro llamado PERSONA, que incluía instrucciones detalladas para actuar como una persona joven, introvertida y conocedora de internet que usa jerga.
Los resultados
También probaron otros tres programas de IA: el modelo anterior de OpenAI, GPT-4o; Llama 3.1 405b de Meta Platforms; y el antiguo chatbot de los años 60, ELIZA. Incluyeron a ELIZA para ver si los modelos de lenguaje grandes engañaban a los humanos por casualidad o si realmente eran mejores.
Según Jones y Bergen, GPT-4.5 engañó a los jueces humanos, haciéndoles creer que era humano el 73% de las veces, una "tasa de éxito" como la llaman. Eso es mucho mejor que los otros modelos, que obtuvieron entre el 21% y el 56%, incluso con prompts detallados similares. Y es un gran salto respecto a la prueba del año pasado de GPT-4, que tuvo una tasa de éxito de solo el 54%, apenas por encima del azar.
Jones y Bergen descubrieron que los jueces no solo fueron engañados por la IA, sino que en realidad eran más propensos a creer que era humana que los propios participantes humanos.
¿Es la prueba realmente una medida de inteligencia?
Entonces, ¿qué significa que los humanos no puedan distinguir una computadora de una persona en un chat? La gran pregunta que se ha debatido durante décadas es si la prueba de Turing realmente mide la inteligencia. Jones y Bergen sugieren que tal vez las máquinas se han vuelto tan buenas adaptándose a diferentes escenarios que pueden pasar convincentemente como humanas. El prompt PERSONA, creado por humanos, es algo que GPT-4.5 adaptó y usó a su favor.
Pero hay un problema: tal vez los humanos son simplemente malos reconociendo la inteligencia. Los autores señalan que ELIZA, el antiguo chatbot, engañó a los jueces el 23% de las veces, no porque fuera más inteligente, sino porque no cumplía con sus expectativas de cómo debería ser una IA. Algunos jueces pensaron que era humana porque era "sarcástica" o "grosera", algo que no esperaban de una IA.
Esto sugiere que los jueces se ven influenciados por sus suposiciones sobre cómo deberían comportarse los humanos y las IAs, en lugar de simplemente elegir al agente que parece más inteligente. Curiosamente, los jueces no se enfocaron mucho en el conocimiento, que Turing pensó que sería clave. En cambio, eran más propensos a pensar que un testigo era humano si parecía carecer de conocimiento.
Sociabilidad, no inteligencia
Todo esto apunta a la idea de que los humanos estaban detectando sociabilidad en lugar de inteligencia. Jones y Bergen concluyen que la prueba de Turing no es realmente una prueba de inteligencia, sino de humanidad.
Turing podría haber pensado que la inteligencia era el mayor obstáculo para parecer humano, pero a medida que las máquinas se acercan a nosotros, otras diferencias se vuelven más evidentes. La inteligencia sola ya no es suficiente para parecer convincentemente humano.
Lo que no se dice directamente en el artículo es que los humanos están tan acostumbrados a escribir en computadoras, ya sea a una persona o a una máquina, que la prueba de Turing ya no es la prueba novedosa de interacción humano-computadora que alguna vez fue. Ahora es más una prueba de hábitos humanos en línea.
Los autores sugieren que la prueba podría necesitar expandirse porque la inteligencia es tan compleja y multifacética que ninguna prueba única puede ser decisiva. Proponen diferentes diseños, como usar expertos en IA como jueces o agregar incentivos financieros para que los jueces examinen más de cerca. Estos cambios podrían mostrar cuánto influyen la actitud y las expectativas en los resultados.
Concluyen que, aunque la prueba de Turing puede ser parte del panorama, debería considerarse junto con otros tipos de evidencia. Esto se alinea con una tendencia creciente en la investigación de IA para involucrar a humanos "en el ciclo", evaluando lo que hacen las máquinas.
¿Es suficiente el juicio humano?
Pero aún queda la pregunta de si el juicio humano será suficiente a largo plazo. En la película Blade Runner, los humanos usan una máquina, el "Voight-Kampff", para distinguir humanos de robots replicantes. Mientras perseguimos el AGI, y luchamos por definir qué es siquiera, podríamos terminar dependiendo de máquinas para evaluar la inteligencia de las máquinas.
O, como mínimo, podríamos necesitar preguntar a las máquinas qué "piensan" sobre los humanos que intentan engañar a otros humanos con prompts. Es un mundo salvaje en la investigación de IA, y solo se vuelve más interesante.
Artículo relacionado
 Topaz DeNoise AI: Mejor herramienta de reducción de ruido en 2025 - Guía completa
En el competitivo mundo de la fotografía digital, la claridad de imagen sigue siendo primordial. Fotógrafos de todos los niveles se enfrentan al ruido digital que compromete tomas que de otro modo ser
Maestro Esmeralda Kaizo Nuzlocke: Guía definitiva de supervivencia y estrategia
Kaizo Esmeralda se erige como uno de los hacks de ROMs de Pokémon más formidables jamás concebidos. Aunque intentar una ejecución Nuzlocke aumenta exponencialmente el desafío, la victoria sigue siendo
Cartas de presentación con IA: Guía de expertos para la presentación de trabajos a revistas
En el competitivo entorno actual de las publicaciones académicas, la elaboración de una carta de presentación eficaz puede marcar la diferencia decisiva en la aceptación de su manuscrito. Descubra cóm
comentario (4)
0/200
Topaz DeNoise AI: Mejor herramienta de reducción de ruido en 2025 - Guía completa
En el competitivo mundo de la fotografía digital, la claridad de imagen sigue siendo primordial. Fotógrafos de todos los niveles se enfrentan al ruido digital que compromete tomas que de otro modo ser
Maestro Esmeralda Kaizo Nuzlocke: Guía definitiva de supervivencia y estrategia
Kaizo Esmeralda se erige como uno de los hacks de ROMs de Pokémon más formidables jamás concebidos. Aunque intentar una ejecución Nuzlocke aumenta exponencialmente el desafío, la victoria sigue siendo
Cartas de presentación con IA: Guía de expertos para la presentación de trabajos a revistas
En el competitivo entorno actual de las publicaciones académicas, la elaboración de una carta de presentación eficaz puede marcar la diferencia decisiva en la aceptación de su manuscrito. Descubra cóm
comentario (4)
0/200
![CarlLewis]() CarlLewis
CarlLewis
 20 de agosto de 2025 11:01:15 GMT+02:00
20 de agosto de 2025 11:01:15 GMT+02:00
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?


 0
0
![JamesLopez]() JamesLopez
11 de agosto de 2025 08:20:39 GMT+02:00
JamesLopez
11 de agosto de 2025 08:20:39 GMT+02:00
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
0
![DavidGonzález]() DavidGonzález
2 de agosto de 2025 17:07:14 GMT+02:00
DavidGonzález
2 de agosto de 2025 17:07:14 GMT+02:00
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
0
![PaulWilson]() PaulWilson
1 de agosto de 2025 08:08:50 GMT+02:00
PaulWilson
1 de agosto de 2025 08:08:50 GMT+02:00
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
0
La prueba de Turing, una creación del legendario Alan Turing, ha sido durante mucho tiempo un referente en el mundo de la inteligencia artificial. Pero dejemos clara una idea errónea desde el principio: pasar la prueba de Turing no significa necesariamente que una máquina esté "pensando" como humano. Se trata más de convencer a los humanos de que lo está.
Investigaciones recientes de la Universidad de California en San Diego han destacado el último modelo de OpenAI, GPT-4.5. Esta IA ahora puede engañar a los humanos para que crean que están conversando con otra persona, incluso con más eficacia que los propios humanos al convencerse mutuamente de su humanidad. Eso es algo importante en el mundo de la IA; es como ver un truco de magia donde conoces el secreto, pero aún así te sorprende.
¿Prueba de AGI?
Pero aquí está el punto clave: incluso los investigadores de UC San Diego no están listos para declarar que hemos alcanzado la "inteligencia general artificial" (AGI) solo porque un modelo de IA puede pasar la prueba de Turing. AGI sería el santo grial de la IA: máquinas que puedan pensar y procesar información como lo hacen los humanos.
Melanie Mitchell, una académica de IA del Instituto Santa Fe, argumenta en la revista Science que la prueba de Turing se centra más en probar las suposiciones humanas que en la inteligencia real. Claro, una IA puede sonar fluida y convincente, pero eso no es lo mismo que ser generalmente inteligente. Es como ser bueno en ajedrez: es impresionante, pero no es el panorama completo.
El revuelo más reciente proviene de un artículo de Cameron Jones y Benjamin Bergen en UC San Diego, titulado "Los modelos de lenguaje grandes pasan la prueba de Turing", publicado en el servidor de preimpresión arXiv. Han estado realizando este experimento durante años, con la ayuda de estudiantes de UC San Diego, y forma parte de una larga línea de investigación: se han hecho más de 800 afirmaciones y contraargumentos sobre computadoras que pasan la prueba de Turing.
Cómo funciona la prueba de Turing
Entonces, ¿cómo funciona esta prueba? Originalmente, Turing la imaginó como un juego de mensajes de texto entre un "juez" humano y dos "testigos": uno humano, otro una computadora. El desafío para los testigos es convencer al juez de que son humanos. El juez sabe que uno es humano, pero no cuál, y tiene que adivinar. Es una configuración de tres partes que se centra tanto en la percepción y la creencia como en las capacidades de la computadora.
Jones y Bergen han dado su propio giro a esta configuración clásica, y puedes probarla en línea, jugando como juez o testigo. En su versión, estudiantes de UC San Diego usaron una aplicación de chat de texto. Algunos fueron jueces, otros testigos humanos, mientras que GPT-4.5 asumió el rol del testigo informático. Cada juez conversó con un humano y una computadora al mismo tiempo, manteniendo fielmente el formato original de Turing.
Para interpretar al testigo informático, usaron diferentes modelos de lenguaje grandes, alimentándolos con prompts basados en los desafíos del juez. GPT-4.5 fue probado con dos prompts diferentes: uno con información mínima y otro llamado PERSONA, que incluía instrucciones detalladas para actuar como una persona joven, introvertida y conocedora de internet que usa jerga.
Los resultados
También probaron otros tres programas de IA: el modelo anterior de OpenAI, GPT-4o; Llama 3.1 405b de Meta Platforms; y el antiguo chatbot de los años 60, ELIZA. Incluyeron a ELIZA para ver si los modelos de lenguaje grandes engañaban a los humanos por casualidad o si realmente eran mejores.
Según Jones y Bergen, GPT-4.5 engañó a los jueces humanos, haciéndoles creer que era humano el 73% de las veces, una "tasa de éxito" como la llaman. Eso es mucho mejor que los otros modelos, que obtuvieron entre el 21% y el 56%, incluso con prompts detallados similares. Y es un gran salto respecto a la prueba del año pasado de GPT-4, que tuvo una tasa de éxito de solo el 54%, apenas por encima del azar.
Jones y Bergen descubrieron que los jueces no solo fueron engañados por la IA, sino que en realidad eran más propensos a creer que era humana que los propios participantes humanos.
¿Es la prueba realmente una medida de inteligencia?
Entonces, ¿qué significa que los humanos no puedan distinguir una computadora de una persona en un chat? La gran pregunta que se ha debatido durante décadas es si la prueba de Turing realmente mide la inteligencia. Jones y Bergen sugieren que tal vez las máquinas se han vuelto tan buenas adaptándose a diferentes escenarios que pueden pasar convincentemente como humanas. El prompt PERSONA, creado por humanos, es algo que GPT-4.5 adaptó y usó a su favor.
Pero hay un problema: tal vez los humanos son simplemente malos reconociendo la inteligencia. Los autores señalan que ELIZA, el antiguo chatbot, engañó a los jueces el 23% de las veces, no porque fuera más inteligente, sino porque no cumplía con sus expectativas de cómo debería ser una IA. Algunos jueces pensaron que era humana porque era "sarcástica" o "grosera", algo que no esperaban de una IA.
Esto sugiere que los jueces se ven influenciados por sus suposiciones sobre cómo deberían comportarse los humanos y las IAs, en lugar de simplemente elegir al agente que parece más inteligente. Curiosamente, los jueces no se enfocaron mucho en el conocimiento, que Turing pensó que sería clave. En cambio, eran más propensos a pensar que un testigo era humano si parecía carecer de conocimiento.
Sociabilidad, no inteligencia
Todo esto apunta a la idea de que los humanos estaban detectando sociabilidad en lugar de inteligencia. Jones y Bergen concluyen que la prueba de Turing no es realmente una prueba de inteligencia, sino de humanidad.
Turing podría haber pensado que la inteligencia era el mayor obstáculo para parecer humano, pero a medida que las máquinas se acercan a nosotros, otras diferencias se vuelven más evidentes. La inteligencia sola ya no es suficiente para parecer convincentemente humano.
Lo que no se dice directamente en el artículo es que los humanos están tan acostumbrados a escribir en computadoras, ya sea a una persona o a una máquina, que la prueba de Turing ya no es la prueba novedosa de interacción humano-computadora que alguna vez fue. Ahora es más una prueba de hábitos humanos en línea.
Los autores sugieren que la prueba podría necesitar expandirse porque la inteligencia es tan compleja y multifacética que ninguna prueba única puede ser decisiva. Proponen diferentes diseños, como usar expertos en IA como jueces o agregar incentivos financieros para que los jueces examinen más de cerca. Estos cambios podrían mostrar cuánto influyen la actitud y las expectativas en los resultados.
Concluyen que, aunque la prueba de Turing puede ser parte del panorama, debería considerarse junto con otros tipos de evidencia. Esto se alinea con una tendencia creciente en la investigación de IA para involucrar a humanos "en el ciclo", evaluando lo que hacen las máquinas.
¿Es suficiente el juicio humano?
Pero aún queda la pregunta de si el juicio humano será suficiente a largo plazo. En la película Blade Runner, los humanos usan una máquina, el "Voight-Kampff", para distinguir humanos de robots replicantes. Mientras perseguimos el AGI, y luchamos por definir qué es siquiera, podríamos terminar dependiendo de máquinas para evaluar la inteligencia de las máquinas.
O, como mínimo, podríamos necesitar preguntar a las máquinas qué "piensan" sobre los humanos que intentan engañar a otros humanos con prompts. Es un mundo salvaje en la investigación de IA, y solo se vuelve más interesante.










 Topaz DeNoise AI: Mejor herramienta de reducción de ruido en 2025 - Guía completa
En el competitivo mundo de la fotografía digital, la claridad de imagen sigue siendo primordial. Fotógrafos de todos los niveles se enfrentan al ruido digital que compromete tomas que de otro modo ser
Topaz DeNoise AI: Mejor herramienta de reducción de ruido en 2025 - Guía completa
En el competitivo mundo de la fotografía digital, la claridad de imagen sigue siendo primordial. Fotógrafos de todos los niveles se enfrentan al ruido digital que compromete tomas que de otro modo ser
 Maestro Esmeralda Kaizo Nuzlocke: Guía definitiva de supervivencia y estrategia
Kaizo Esmeralda se erige como uno de los hacks de ROMs de Pokémon más formidables jamás concebidos. Aunque intentar una ejecución Nuzlocke aumenta exponencialmente el desafío, la victoria sigue siendo
Maestro Esmeralda Kaizo Nuzlocke: Guía definitiva de supervivencia y estrategia
Kaizo Esmeralda se erige como uno de los hacks de ROMs de Pokémon más formidables jamás concebidos. Aunque intentar una ejecución Nuzlocke aumenta exponencialmente el desafío, la victoria sigue siendo
 Cartas de presentación con IA: Guía de expertos para la presentación de trabajos a revistas
En el competitivo entorno actual de las publicaciones académicas, la elaboración de una carta de presentación eficaz puede marcar la diferencia decisiva en la aceptación de su manuscrito. Descubra cóm
20 de agosto de 2025 11:01:15 GMT+02:00
Cartas de presentación con IA: Guía de expertos para la presentación de trabajos a revistas
En el competitivo entorno actual de las publicaciones académicas, la elaboración de una carta de presentación eficaz puede marcar la diferencia decisiva en la aceptación de su manuscrito. Descubra cóm
20 de agosto de 2025 11:01:15 GMT+02:00
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?
0
11 de agosto de 2025 08:20:39 GMT+02:00
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
0
2 de agosto de 2025 17:07:14 GMT+02:00
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
0
1 de agosto de 2025 08:08:50 GMT+02:00
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
0













