




Problema do Teste de Turing Exposto pelo GPT-4.5 da OpenAI
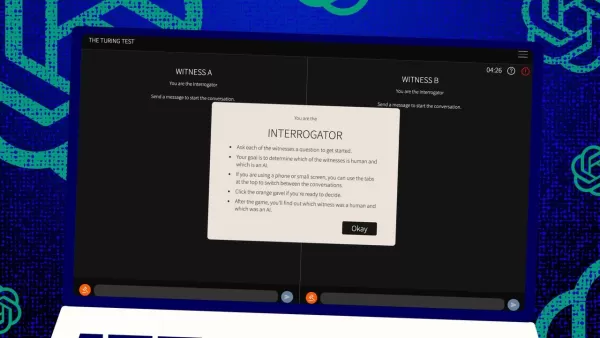
O Teste de Turing, uma criação do lendário Alan Turing, tem sido há muito tempo um marco no mundo da inteligência artificial. Mas vamos esclarecer um equívoco comum logo de início: passar no Teste de Turing não significa necessariamente que uma máquina está "pensando" como um humano. É mais sobre convencer humanos de que ela é.
Pesquisas recentes da Universidade da Califórnia em San Diego destacaram o mais recente modelo da OpenAI, o GPT-4.5. Essa IA agora pode enganar humanos fazendo-os acreditar que estão conversando com outra pessoa, de forma ainda mais eficaz do que humanos conseguem convencer uns aos outros de sua humanidade. Isso é algo bem significativo no mundo da IA — é como assistir a um truque de mágica onde você conhece o segredo, mas ainda assim fica impressionado.
Prova de AGI?
Mas aqui está o ponto crucial: mesmo os pesquisadores da UC San Diego não estão prontos para declarar que alcançamos a "inteligência geral artificial" (AGI) só porque um modelo de IA pode passar no Teste de Turing. AGI seria o santo graal da IA — máquinas que podem pensar e processar informações exatamente como humanos.
Melanie Mitchell, uma estudiosa de IA do Santa Fe Institute, argumenta na revista Science que o Teste de Turing é mais sobre testar suposições humanas do que inteligência real. Claro, uma IA pode soar fluente e convincente, mas isso não é o mesmo que ser geralmente inteligente. É como ser bom em xadrez — é impressionante, mas não é o quadro completo.
O mais recente burburinho sobre isso vem de um artigo de Cameron Jones e Benjamin Bergen na UC San Diego, intitulado "Modelos de Linguagem de Grande Escala Passam no Teste de Turing", publicado no servidor de pré-impressão arXiv. Eles têm conduzido esse experimento por anos, com a ajuda de estudantes de graduação da UC San Diego, e isso faz parte de uma longa linha de pesquisa — mais de 800 afirmações e contra-argumentos foram feitos sobre computadores passando no Teste de Turing.
Como Funciona o Teste de Turing
Então, como funciona esse teste? Originalmente, Turing imaginou-o como um jogo de mensagens de texto entre um "juiz" humano e dois "testemunhas" — um humano, um computador. O desafio para as testemunhas é convencer o juiz de que são humanas. O juiz sabe que uma é humana, mas não sabe qual, e precisa fazer um palpite. É uma configuração tripla que envolve tanto percepção e crença quanto as habilidades do computador.
Jones e Bergen deram seu próprio toque a essa configuração clássica, e você pode até experimentá-la online, jogando como juiz ou testemunha. Na versão deles, estudantes da UC San Diego usaram um aplicativo de chat de texto. Alguns foram juízes, outros testemunhas humanas, enquanto o GPT-4.5 assumiu o papel de testemunha computacional. Cada juiz conversou com um humano e um computador ao mesmo tempo, mantendo-se fiel ao formato original de Turing.
Para interpretar a testemunha computacional, eles usaram diferentes modelos de linguagem de grande escala, fornecendo-lhes prompts baseados nos desafios do juiz. O GPT-4.5 foi testado com dois prompts diferentes: um com informações mínimas e outro chamado PERSONA, que incluía instruções detalhadas para agir como uma pessoa jovem, introvertida e conhecedora da internet, que usa gírias.
Os Resultados
Eles também testaram outros três programas de IA: o modelo anterior da OpenAI, GPT-4o; o Llama 3.1 405b da Meta Platforms; e o chatbot dos anos 1960, ELIZA. Eles incluíram o ELIZA para verificar se os modelos de linguagem de grande escala estavam apenas enganando humanos por acaso ou se eram genuinamente melhores.
Segundo Jones e Bergen, o GPT-4.5 enganou juízes humanos, fazendo-os pensar que era humano em 73% das vezes — uma "taxa de vitória", como eles chamam. Isso é muito melhor do que os outros modelos, que marcaram entre 21% e 56%, mesmo com prompts detalhados semelhantes. E é um salto enorme em relação ao teste do ano passado com o GPT-4, que teve uma taxa de vitória de apenas 54%, mal acima do acaso.
Jones e Bergen descobriram que os juízes não apenas foram enganados pela IA, mas também eram mais propensos a acreditar que ela era humana do que os participantes humanos reais.
O Teste é Realmente uma Medida de Inteligência?
Então, o que significa que humanos não conseguem distinguir um computador de uma pessoa em um chat? A grande questão que tem sido debatida por décadas é se o Teste de Turing está realmente medindo inteligência. Jones e Bergen sugerem que talvez as máquinas tenham se tornado tão boas em se adaptar a diferentes cenários que podem passar convincentemente por humanas. O prompt PERSONA, criado por humanos, é algo que o GPT-4.5 adaptou e usou a seu favor.
Mas há um porém: talvez os humanos sejam apenas ruins em reconhecer inteligência. Os autores apontam que o ELIZA, o antigo chatbot, enganou juízes em 23% das vezes, não porque era mais inteligente, mas porque não atendia às expectativas deles sobre o que uma IA deveria ser. Alguns juízes pensaram que era humano porque era "sarcástico" ou "rude", o que eles não esperavam de uma IA.
Isso sugere que os juízes são influenciados por suas suposições sobre como humanos e IAs devem se comportar, em vez de apenas escolher o agente que parece mais inteligente. Curiosamente, os juízes não se concentraram muito no conhecimento, que Turing achava que seria fundamental. Em vez disso, eram mais propensos a pensar que uma testemunha era humana se parecesse ter falta de conhecimento.
Sociabilidade, Não Inteligência
Tudo isso aponta para a ideia de que os humanos estavam captando sociabilidade em vez de inteligência. Jones e Bergen concluem que o Teste de Turing não é realmente um teste de inteligência — é um teste de semelhança com humanos.
Turing pode ter pensado que a inteligência era o maior obstáculo para parecer humano, mas, à medida que as máquinas se aproximam de nós, outras diferenças se tornam mais evidentes. A inteligência por si só não é mais suficiente para parecer convincentemente humano.
O que não é dito diretamente no artigo é que os humanos estão tão acostumados a digitar em computadores, seja para uma pessoa ou uma máquina, que o Teste de Turing não é mais o teste inovador de interação humano-computador que já foi. Agora é mais um teste de hábitos humanos online.
Os autores sugerem que o teste pode precisar ser expandido porque a inteligência é tão complexa e multifacetada que nenhum teste único pode ser decisivo. Eles propõem diferentes designs, como usar especialistas em IA como juízes ou adicionar incentivos financeiros para fazer os juízes examinarem mais de perto. Essas mudanças poderiam mostrar o quanto atitude e expectativas influenciam os resultados.
Eles concluem que, embora o Teste de Turing possa fazer parte do quadro, ele deve ser considerado ao lado de outros tipos de evidências. Isso se alinha com uma tendência crescente na pesquisa de IA de envolver humanos "no ciclo", avaliando o que as máquinas fazem.
O Julgamento Humano é Suficiente?
Mas ainda há a questão de se o julgamento humano será suficiente a longo prazo. No filme Blade Runner, os humanos usam uma máquina, o "Voight-Kampff", para distinguir humanos de robôs replicantes. À medida que perseguimos o AGI, e lutamos para definir o que ele realmente é, podemos acabar dependendo de máquinas para avaliar a inteligência das máquinas.
Ou, no mínimo, podemos precisar perguntar às máquinas o que elas "pensam" sobre humanos tentando enganar outros humanos com prompts. É um mundo selvagem na pesquisa de IA, e está ficando cada vez mais interessante.
Artigo relacionado
 Melhores ferramentas de IA para criar infográficos educacionais - Dicas e técnicas de design
No cenário educacional atual, impulsionado pelo digital, os infográficos surgiram como um meio de comunicação transformador que converte informações complexas em formatos visualmente atraentes e facil
Topaz DeNoise AI: a melhor ferramenta de redução de ruído em 2025 - Guia completo
No competitivo mundo da fotografia digital, a nitidez da imagem continua sendo fundamental. Fotógrafos de todos os níveis de habilidade enfrentam o ruído digital que compromete fotos que, de outra for
Master Emerald Kaizo Nuzlocke: Guia definitivo de sobrevivência e estratégia
O Emerald Kaizo é um dos mais formidáveis hacks de ROM de Pokémon já concebidos. Embora a tentativa de executar um Nuzlocke aumente exponencialmente o desafio, a vitória continua sendo possível por me
Comentários (4)
0/200
Melhores ferramentas de IA para criar infográficos educacionais - Dicas e técnicas de design
No cenário educacional atual, impulsionado pelo digital, os infográficos surgiram como um meio de comunicação transformador que converte informações complexas em formatos visualmente atraentes e facil
Topaz DeNoise AI: a melhor ferramenta de redução de ruído em 2025 - Guia completo
No competitivo mundo da fotografia digital, a nitidez da imagem continua sendo fundamental. Fotógrafos de todos os níveis de habilidade enfrentam o ruído digital que compromete fotos que, de outra for
Master Emerald Kaizo Nuzlocke: Guia definitivo de sobrevivência e estratégia
O Emerald Kaizo é um dos mais formidáveis hacks de ROM de Pokémon já concebidos. Embora a tentativa de executar um Nuzlocke aumente exponencialmente o desafio, a vitória continua sendo possível por me
Comentários (4)
0/200
![CarlLewis]() CarlLewis
CarlLewis
 20 de Agosto de 2025 à15 10:01:15 WEST
20 de Agosto de 2025 à15 10:01:15 WEST
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?


 0
0
![JamesLopez]() JamesLopez
11 de Agosto de 2025 à39 07:20:39 WEST
JamesLopez
11 de Agosto de 2025 à39 07:20:39 WEST
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
0
![DavidGonzález]() DavidGonzález
2 de Agosto de 2025 à14 16:07:14 WEST
DavidGonzález
2 de Agosto de 2025 à14 16:07:14 WEST
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
0
![PaulWilson]() PaulWilson
1 de Agosto de 2025 à50 07:08:50 WEST
PaulWilson
1 de Agosto de 2025 à50 07:08:50 WEST
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
0
O Teste de Turing, uma criação do lendário Alan Turing, tem sido há muito tempo um marco no mundo da inteligência artificial. Mas vamos esclarecer um equívoco comum logo de início: passar no Teste de Turing não significa necessariamente que uma máquina está "pensando" como um humano. É mais sobre convencer humanos de que ela é.
Pesquisas recentes da Universidade da Califórnia em San Diego destacaram o mais recente modelo da OpenAI, o GPT-4.5. Essa IA agora pode enganar humanos fazendo-os acreditar que estão conversando com outra pessoa, de forma ainda mais eficaz do que humanos conseguem convencer uns aos outros de sua humanidade. Isso é algo bem significativo no mundo da IA — é como assistir a um truque de mágica onde você conhece o segredo, mas ainda assim fica impressionado.
Prova de AGI?
Mas aqui está o ponto crucial: mesmo os pesquisadores da UC San Diego não estão prontos para declarar que alcançamos a "inteligência geral artificial" (AGI) só porque um modelo de IA pode passar no Teste de Turing. AGI seria o santo graal da IA — máquinas que podem pensar e processar informações exatamente como humanos.
Melanie Mitchell, uma estudiosa de IA do Santa Fe Institute, argumenta na revista Science que o Teste de Turing é mais sobre testar suposições humanas do que inteligência real. Claro, uma IA pode soar fluente e convincente, mas isso não é o mesmo que ser geralmente inteligente. É como ser bom em xadrez — é impressionante, mas não é o quadro completo.
O mais recente burburinho sobre isso vem de um artigo de Cameron Jones e Benjamin Bergen na UC San Diego, intitulado "Modelos de Linguagem de Grande Escala Passam no Teste de Turing", publicado no servidor de pré-impressão arXiv. Eles têm conduzido esse experimento por anos, com a ajuda de estudantes de graduação da UC San Diego, e isso faz parte de uma longa linha de pesquisa — mais de 800 afirmações e contra-argumentos foram feitos sobre computadores passando no Teste de Turing.
Como Funciona o Teste de Turing
Então, como funciona esse teste? Originalmente, Turing imaginou-o como um jogo de mensagens de texto entre um "juiz" humano e dois "testemunhas" — um humano, um computador. O desafio para as testemunhas é convencer o juiz de que são humanas. O juiz sabe que uma é humana, mas não sabe qual, e precisa fazer um palpite. É uma configuração tripla que envolve tanto percepção e crença quanto as habilidades do computador.
Jones e Bergen deram seu próprio toque a essa configuração clássica, e você pode até experimentá-la online, jogando como juiz ou testemunha. Na versão deles, estudantes da UC San Diego usaram um aplicativo de chat de texto. Alguns foram juízes, outros testemunhas humanas, enquanto o GPT-4.5 assumiu o papel de testemunha computacional. Cada juiz conversou com um humano e um computador ao mesmo tempo, mantendo-se fiel ao formato original de Turing.
Para interpretar a testemunha computacional, eles usaram diferentes modelos de linguagem de grande escala, fornecendo-lhes prompts baseados nos desafios do juiz. O GPT-4.5 foi testado com dois prompts diferentes: um com informações mínimas e outro chamado PERSONA, que incluía instruções detalhadas para agir como uma pessoa jovem, introvertida e conhecedora da internet, que usa gírias.
Os Resultados
Eles também testaram outros três programas de IA: o modelo anterior da OpenAI, GPT-4o; o Llama 3.1 405b da Meta Platforms; e o chatbot dos anos 1960, ELIZA. Eles incluíram o ELIZA para verificar se os modelos de linguagem de grande escala estavam apenas enganando humanos por acaso ou se eram genuinamente melhores.
Segundo Jones e Bergen, o GPT-4.5 enganou juízes humanos, fazendo-os pensar que era humano em 73% das vezes — uma "taxa de vitória", como eles chamam. Isso é muito melhor do que os outros modelos, que marcaram entre 21% e 56%, mesmo com prompts detalhados semelhantes. E é um salto enorme em relação ao teste do ano passado com o GPT-4, que teve uma taxa de vitória de apenas 54%, mal acima do acaso.
Jones e Bergen descobriram que os juízes não apenas foram enganados pela IA, mas também eram mais propensos a acreditar que ela era humana do que os participantes humanos reais.
O Teste é Realmente uma Medida de Inteligência?
Então, o que significa que humanos não conseguem distinguir um computador de uma pessoa em um chat? A grande questão que tem sido debatida por décadas é se o Teste de Turing está realmente medindo inteligência. Jones e Bergen sugerem que talvez as máquinas tenham se tornado tão boas em se adaptar a diferentes cenários que podem passar convincentemente por humanas. O prompt PERSONA, criado por humanos, é algo que o GPT-4.5 adaptou e usou a seu favor.
Mas há um porém: talvez os humanos sejam apenas ruins em reconhecer inteligência. Os autores apontam que o ELIZA, o antigo chatbot, enganou juízes em 23% das vezes, não porque era mais inteligente, mas porque não atendia às expectativas deles sobre o que uma IA deveria ser. Alguns juízes pensaram que era humano porque era "sarcástico" ou "rude", o que eles não esperavam de uma IA.
Isso sugere que os juízes são influenciados por suas suposições sobre como humanos e IAs devem se comportar, em vez de apenas escolher o agente que parece mais inteligente. Curiosamente, os juízes não se concentraram muito no conhecimento, que Turing achava que seria fundamental. Em vez disso, eram mais propensos a pensar que uma testemunha era humana se parecesse ter falta de conhecimento.
Sociabilidade, Não Inteligência
Tudo isso aponta para a ideia de que os humanos estavam captando sociabilidade em vez de inteligência. Jones e Bergen concluem que o Teste de Turing não é realmente um teste de inteligência — é um teste de semelhança com humanos.
Turing pode ter pensado que a inteligência era o maior obstáculo para parecer humano, mas, à medida que as máquinas se aproximam de nós, outras diferenças se tornam mais evidentes. A inteligência por si só não é mais suficiente para parecer convincentemente humano.
O que não é dito diretamente no artigo é que os humanos estão tão acostumados a digitar em computadores, seja para uma pessoa ou uma máquina, que o Teste de Turing não é mais o teste inovador de interação humano-computador que já foi. Agora é mais um teste de hábitos humanos online.
Os autores sugerem que o teste pode precisar ser expandido porque a inteligência é tão complexa e multifacetada que nenhum teste único pode ser decisivo. Eles propõem diferentes designs, como usar especialistas em IA como juízes ou adicionar incentivos financeiros para fazer os juízes examinarem mais de perto. Essas mudanças poderiam mostrar o quanto atitude e expectativas influenciam os resultados.
Eles concluem que, embora o Teste de Turing possa fazer parte do quadro, ele deve ser considerado ao lado de outros tipos de evidências. Isso se alinha com uma tendência crescente na pesquisa de IA de envolver humanos "no ciclo", avaliando o que as máquinas fazem.
O Julgamento Humano é Suficiente?
Mas ainda há a questão de se o julgamento humano será suficiente a longo prazo. No filme Blade Runner, os humanos usam uma máquina, o "Voight-Kampff", para distinguir humanos de robôs replicantes. À medida que perseguimos o AGI, e lutamos para definir o que ele realmente é, podemos acabar dependendo de máquinas para avaliar a inteligência das máquinas.
Ou, no mínimo, podemos precisar perguntar às máquinas o que elas "pensam" sobre humanos tentando enganar outros humanos com prompts. É um mundo selvagem na pesquisa de IA, e está ficando cada vez mais interessante.










 Melhores ferramentas de IA para criar infográficos educacionais - Dicas e técnicas de design
No cenário educacional atual, impulsionado pelo digital, os infográficos surgiram como um meio de comunicação transformador que converte informações complexas em formatos visualmente atraentes e facil
Melhores ferramentas de IA para criar infográficos educacionais - Dicas e técnicas de design
No cenário educacional atual, impulsionado pelo digital, os infográficos surgiram como um meio de comunicação transformador que converte informações complexas em formatos visualmente atraentes e facil
 Topaz DeNoise AI: a melhor ferramenta de redução de ruído em 2025 - Guia completo
No competitivo mundo da fotografia digital, a nitidez da imagem continua sendo fundamental. Fotógrafos de todos os níveis de habilidade enfrentam o ruído digital que compromete fotos que, de outra for
Topaz DeNoise AI: a melhor ferramenta de redução de ruído em 2025 - Guia completo
No competitivo mundo da fotografia digital, a nitidez da imagem continua sendo fundamental. Fotógrafos de todos os níveis de habilidade enfrentam o ruído digital que compromete fotos que, de outra for
 Master Emerald Kaizo Nuzlocke: Guia definitivo de sobrevivência e estratégia
O Emerald Kaizo é um dos mais formidáveis hacks de ROM de Pokémon já concebidos. Embora a tentativa de executar um Nuzlocke aumente exponencialmente o desafio, a vitória continua sendo possível por me
20 de Agosto de 2025 à15 10:01:15 WEST
Master Emerald Kaizo Nuzlocke: Guia definitivo de sobrevivência e estratégia
O Emerald Kaizo é um dos mais formidáveis hacks de ROM de Pokémon já concebidos. Embora a tentativa de executar um Nuzlocke aumente exponencialmente o desafio, a vitória continua sendo possível por me
20 de Agosto de 2025 à15 10:01:15 WEST
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?
0
11 de Agosto de 2025 à39 07:20:39 WEST
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
0
2 de Agosto de 2025 à14 16:07:14 WEST
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
0
1 de Agosto de 2025 à50 07:08:50 WEST
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
0













