
















 Дом
ДомНедостаток теста Тьюринга, раскрытый OpenAI's GPT-4.5
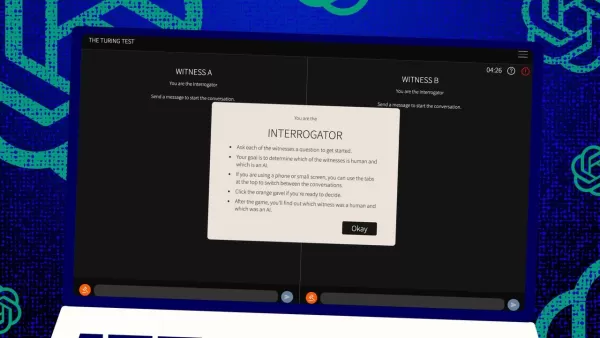
Тест Тьюринга, детище легендарного Алана Тьюринга, долгое время был эталоном в мире искусственного интеллекта. Но давайте сразу развеем распространённое заблуждение: прохождение теста Тьюринга не обязательно означает, что машина «мыслит» как человек. Это скорее о том, чтобы убедить людей, что она такова.
Недавние исследования Калифорнийского университета в Сан-Диего привлекли внимание к последней модели OpenAI, GPT-4.5. Этот ИИ теперь может обманывать людей, заставляя их думать, что они общаются с человеком, причём эффективнее, чем люди сами убеждают друг друга в своей человечности. Это довольно большое событие в мире ИИ — как фокус, где вы знаете секрет, но он всё равно поражает.
Доказательство AGI?
Но вот загвоздка: даже исследователи из UC San Diego не готовы заявить, что мы достигли «искусственного общего интеллекта» (AGI) только потому, что модель ИИ прошла тест Тьюринга. AGI — это святой Грааль ИИ, машины, которые могут думать и обрабатывать информацию, как люди.
Мелани Митчелл, учёный в области ИИ из Института Санта-Фе, утверждает в журнале Science, что тест Тьюринга больше проверяет человеческие предположения, чем реальный интеллект. Конечно, ИИ может звучать бегло и убедительно, но это не то же самое, что быть универсально разумным. Это как быть мастером в шахматах — впечатляюще, но не вся картина.
Последний ажиотаж вызван статьёй Кэмерона Джонса и Бенджамина Бергена из UC San Diego под названием «Большие языковые модели проходят тест Тьюринга», опубликованной на сервере препринтов arXiv. Они проводили этот эксперимент годами с помощью студентов UC San Diego, и это часть длинной линии исследований — более 800 заявлений и контраргументов о прохождении компьютерами теста Тьюринга.
Как работает тест Тьюринга
Итак, как работает этот тест? Изначально Тьюринг представлял его как игру в текстовые сообщения между человеком-«судьёй» и двумя «свидетелями» — одним человеком и одним компьютером. Задача свидетелей — убедить судью, что они люди. Судья знает, что один из них человек, но не знает, кто именно, и должен угадать. Это трёхсторонняя установка, где важны восприятие и убеждение не меньше, чем способности компьютера.
Джонс и Берген добавили свою изюминку в эту классическую схему, и вы даже можете попробовать это онлайн, играя роль судьи или свидетеля. В их версии студенты UC San Diego использовали приложение для текстового чата. Одни играли судей, другие — свидетелей-людей, а GPT-4.5 выступал в роли свидетеля-компьютера. Каждый судья одновременно общался с человеком и компьютером, следуя оригинальному формату Тьюринга.
Для роли свидетеля-компьютера использовали разные большие языковые модели, предоставляя им подсказки на основе вопросов судьи. GPT-4.5 тестировали с двумя разными подсказками: одной с минимальной информацией и другой, названной PERSONA, с подробными инструкциями вести себя как молодой, интровертированный, разбирающийся в интернете человек, использующий сленг.
Результаты
Они также тестировали три других ИИ-программы: предыдущую модель OpenAI, GPT-4o; Llama 3.1 405b от Meta Platforms; и древний чат-бот 1960-х годов, ELIZA. ELIZA включили, чтобы проверить, обманывают ли большие языковые модели людей случайно или они действительно лучше.
По словам Джонса и Бергена, GPT-4.5 обманывал судей, заставස
System:
Тест Тьюринга, детище легендарного Алана Тьюринга, долгое время был эталоном в мире искусственного интеллекта. Но давайте сразу развеем распространённое заблуждение: прохождение теста Тьюринга не обязательно означает, что машина «мыслит» как человек. Это скорее о том, чтобы убедить людей, что она такова.
Недавние исследования Калифорнийского университета в Сан-Диего привлекли внимание к последней модели OpenAI, GPT-4.5. Этот ИИ теперь может обманывать людей, заставляя их думать, что они общаются с человеком, причём эффективнее, чем люди сами убеждают друг друга в своей человечности. Это довольно большое событие в мире ИИ — как фокус, где вы знаете секрет, но он всё равно поражает.
Доказательство AGI?
Но вот загвоздка: даже исследователи из UC San Diego не готовы заявить, что мы достигли «искусственного общего интеллекта» (AGI) только потому, что модель ИИ прошла тест Тьюринга. AGI — это святой Грааль ИИ, машины, которые могут думать и обрабатывать информацию, как люди.
Мелани Митчелл, учёный в области ИИ из Института Санта-Фе, утверждает в журнале Science, что тест Тьюринга больше проверяет человеческие предположения, чем реальный интеллект. Конечно, ИИ может звучать бегло и убедительно, но это не то же самое, что быть универсально разумным. Это как быть мастером в шахматах — впечатляюще, но не вся картина.
Последний ажиотаж вызван статьёй Кэмерона Джонса и Бенджамина Бергена из UC San Diego под названием «Большие языковые модели проходят тест Тьюринга», опубликованной на сервере препринтов arXiv. Они проводили этот эксперимент годами с помощью студентов UC San Diego, и это часть длинной линии исследований — более 800 заявлений и контраргументов о прохождении компьютерами теста Тьюринга.
Как работает тест Тьюринга
Итак, как работает этот тест? Изначально Тьюринг представлял его как игру в текстовые сообщения между человеком-«судьёй» и двумя «свидетелями» — одним человеком и одним компьютером. Задача свидетелей — убедить судью, что они люди. Судья знает, что один из них человек, но не знает, кто именно, и должен угадать. Это трёхсторонняя установка, где важны восприятие и убеждение не меньше, чем способности компьютера.
Джонс и Берген добавили свою изюминку в эту классическую схему, и вы даже можете попробовать это онлайн, играя роль судьи или свидетеля. В их версии студенты UC San Diego использовали приложение для текстового чата. Одни играли судей, другие — свидетелей-людей, а GPT-4.5 выступал в роли свидетеля-компьютера. Каждый судья одновременно общался с человеком и компьютером, следуя оригинальному формату Тьюринга.
Для роли свидетеля-компьютера использовали разные большие языковые модели, предоставляя им подсказки на основе вопросов судьи. GPT-4.5 тестировали с двумя разными подсказками: одной с минимальной информацией и другой, названной PERSONA, с подробными инструкциями вести себя как молодой, интровертированный, разбирающийся в интернете человек, использующий сленг.
Результаты
Они также тестировали три других ИИ-программы: предыдущую модель OpenAI, GPT-4o; Llama 3.1 405b от Meta Platforms; и древний чат-бот 1960-х годов, ELIZA. ELIZA включили, чтобы проверить, обманывают ли большие языковые модели людей случайно или они действительно лучше.
По словам Джонса и Бергена, GPT-4.5 обманывал судей, заставляя их думать, что он человек, в 73% случаев — это они называют «процентом побед». Это значительно лучше, чем у других моделей, которые набрали от 21% до 56%, даже с похожими подробными подсказками. И это огромный скачок по сравнению с прошлогодним тестом GPT-4, у которого процент побед был всего 54%, чуть выше случайного уровня.
Джонс и Берген обнаружили, что судьи не только были обмануты ИИ, но и чаще верили, что он человек, чем настоящие участники-люди.
Является ли тест настоящей мерой интеллекта?
Итак, что значит, что люди не могут отличить компьютер от человека в чате? Большой вопрос, обсуждаемый десятилетиями, — действительно ли тест Тьюринга измеряет интеллект. Джонс и Берген предполагают, что, возможно, машины просто стали настолько хороши в адаптации к разным сценариям, что могут убедительно выдавать себя за людей. Подсказка PERSONA, созданная людьми, — это то, к чему GPT-4.5 приспособился и использовал в свою пользу.
Но есть загвоздка: возможно, люди просто плохо распознают интеллект. Авторы отмечают, что ELIZA, древний чат-бот, обманывал судей в 23% случаев не потому, что был умнее, а потому, что не соответствовал их ожиданиям от ИИ. Некоторые судьи считали его человеком, потому что он был «саркастичным» или «грубым», чего они не ожидали от ИИ.
Это говорит о том, что судьи руководствуются своими предположениями о том, как должны вести себя люди и ИИ, а не просто выбирают наиболее разумного агента. Интересно, что судьи не особо обращали внимание на знания, которые Тьюринг считал ключевыми. Вместо этого они чаще считали свидетеля человеком, если он казался менее осведомлённым.
Общительность, а не интеллект
Всё это указывает на то, что люди улавливали скорее общительность, чем интеллект. Джонс и Берген заключают, что тест Тьюринга на самом деле не тест интеллекта — это тест на человеческое сходство.
Тьюринг мог считать, что интеллект — главное препятствие для человекоподобия, но по мере того, как машины становятся ближе к нам, другие различия становятся заметнее. Интеллекта самого по себе уже недостаточно, чтобы казаться убедительно человеком.
В статье прямо не говорится, что люди так привыкли печатать на компьютерах, будь то общение с человеком или машиной, что тест Тьюринга уже не тот уникальный тест взаимодействия человека и компьютера, каким он был раньше. Теперь это скорее тест на человеческие привычки в интернете.
Авторы предлагают расширить тест, потому что интеллект слишком сложен и многогранен, чтобы один тест мог быть решающим. Они предлагают разные подходы, например, использовать экспертов по ИИ в качестве судей или добавить финансовые стимулы, чтобы судьи внимательнее анализировали. Эти изменения могли бы показать, как сильно отношение и ожидания влияют на результаты.
Они заключают, что, хотя тест Тьюринга может быть частью картины, его следует рассматривать в совокупности с другими видами доказательств. Это соответствует растущей тенденции в исследованиях ИИ вовлекать людей «в процесс», оценивая действия машин.
Достаточно ли человеческого суждения?
Но остаётся вопрос, будет ли человеческое суждение достаточным в долгосрочной перспективе. В фильме Blade Runner люди используют машину «Voight-Kampff», чтобы отличить людей от роботов-репликантов. Пока мы стремимся к AGI и пытаемся определить, что это вообще такое, мы можем в итоге полагаться на машины для оценки машинного интеллекта.
Или, по крайней мере, нам, возможно, придётся спрашивать у машин, что они «думают» о людях, пытающихся обмануть других людей с помощью подсказок. Это дикий мир в исследованиях ИИ, и он становится только интереснее.
Связанная статья
 WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
DeepSeek Code готовится к запуску
На фоне стремительного развития технологий искусственного интеллекта компания DeepSeek находится на захватывающем этапе своего развития. Недавно эта компания, специализирующаяся на ИИ, объявила о прив
Рекомендации по связанным специальным темам
Бизнес
WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
DeepSeek Code готовится к запуску
На фоне стремительного развития технологий искусственного интеллекта компания DeepSeek находится на захватывающем этапе своего развития. Недавно эта компания, специализирующаяся на ИИ, объявила о прив
Рекомендации по связанным специальным темам
Бизнес
 Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
 10 инструментов
10 инструментов
 xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие романтические чат-боты на базе ИИ: постройте долгосрочные отношения с помощью чат-ботов с устойчивой индивидуальностью
Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai
Образование и обучение
Лучшие наставники в области искусственного интеллекта и науки о данных: мастерство работы с SQL, библиотекой Pandas и рабочими процессами машинного обучения
Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие тренажеры по флирту и общению на базе ИИ: повышайте свою харизму и уверенность в себе в режиме реального времени
Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
10 инструментов
xix.ai

 Комментарии (4)
Комментарии (4)
![CarlLewis]()
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?
![JamesLopez]()
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
![DavidGonzález]()
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
![PaulWilson]()
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
Тест Тьюринга, детище легендарного Алана Тьюринга, долгое время был эталоном в мире искусственного интеллекта. Но давайте сразу развеем распространённое заблуждение: прохождение теста Тьюринга не обязательно означает, что машина «мыслит» как человек. Это скорее о том, чтобы убедить людей, что она такова.
Недавние исследования Калифорнийского университета в Сан-Диего привлекли внимание к последней модели OpenAI, GPT-4.5. Этот ИИ теперь может обманывать людей, заставляя их думать, что они общаются с человеком, причём эффективнее, чем люди сами убеждают друг друга в своей человечности. Это довольно большое событие в мире ИИ — как фокус, где вы знаете секрет, но он всё равно поражает.
Доказательство AGI?
Но вот загвоздка: даже исследователи из UC San Diego не готовы заявить, что мы достигли «искусственного общего интеллекта» (AGI) только потому, что модель ИИ прошла тест Тьюринга. AGI — это святой Грааль ИИ, машины, которые могут думать и обрабатывать информацию, как люди.
Мелани Митчелл, учёный в области ИИ из Института Санта-Фе, утверждает в журнале Science, что тест Тьюринга больше проверяет человеческие предположения, чем реальный интеллект. Конечно, ИИ может звучать бегло и убедительно, но это не то же самое, что быть универсально разумным. Это как быть мастером в шахматах — впечатляюще, но не вся картина.
Последний ажиотаж вызван статьёй Кэмерона Джонса и Бенджамина Бергена из UC San Diego под названием «Большие языковые модели проходят тест Тьюринга», опубликованной на сервере препринтов arXiv. Они проводили этот эксперимент годами с помощью студентов UC San Diego, и это часть длинной линии исследований — более 800 заявлений и контраргументов о прохождении компьютерами теста Тьюринга.
Как работает тест Тьюринга
Итак, как работает этот тест? Изначально Тьюринг представлял его как игру в текстовые сообщения между человеком-«судьёй» и двумя «свидетелями» — одним человеком и одним компьютером. Задача свидетелей — убедить судью, что они люди. Судья знает, что один из них человек, но не знает, кто именно, и должен угадать. Это трёхсторонняя установка, где важны восприятие и убеждение не меньше, чем способности компьютера.
Джонс и Берген добавили свою изюминку в эту классическую схему, и вы даже можете попробовать это онлайн, играя роль судьи или свидетеля. В их версии студенты UC San Diego использовали приложение для текстового чата. Одни играли судей, другие — свидетелей-людей, а GPT-4.5 выступал в роли свидетеля-компьютера. Каждый судья одновременно общался с человеком и компьютером, следуя оригинальному формату Тьюринга.
Для роли свидетеля-компьютера использовали разные большие языковые модели, предоставляя им подсказки на основе вопросов судьи. GPT-4.5 тестировали с двумя разными подсказками: одной с минимальной информацией и другой, названной PERSONA, с подробными инструкциями вести себя как молодой, интровертированный, разбирающийся в интернете человек, использующий сленг.
Результаты
Они также тестировали три других ИИ-программы: предыдущую модель OpenAI, GPT-4o; Llama 3.1 405b от Meta Platforms; и древний чат-бот 1960-х годов, ELIZA. ELIZA включили, чтобы проверить, обманывают ли большие языковые модели людей случайно или они действительно лучше.
По словам Джонса и Бергена, GPT-4.5 обманывал судей, заставස
System:
Тест Тьюринга, детище легендарного Алана Тьюринга, долгое время был эталоном в мире искусственного интеллекта. Но давайте сразу развеем распространённое заблуждение: прохождение теста Тьюринга не обязательно означает, что машина «мыслит» как человек. Это скорее о том, чтобы убедить людей, что она такова.
Недавние исследования Калифорнийского университета в Сан-Диего привлекли внимание к последней модели OpenAI, GPT-4.5. Этот ИИ теперь может обманывать людей, заставляя их думать, что они общаются с человеком, причём эффективнее, чем люди сами убеждают друг друга в своей человечности. Это довольно большое событие в мире ИИ — как фокус, где вы знаете секрет, но он всё равно поражает.
Доказательство AGI?
Но вот загвоздка: даже исследователи из UC San Diego не готовы заявить, что мы достигли «искусственного общего интеллекта» (AGI) только потому, что модель ИИ прошла тест Тьюринга. AGI — это святой Грааль ИИ, машины, которые могут думать и обрабатывать информацию, как люди.
Мелани Митчелл, учёный в области ИИ из Института Санта-Фе, утверждает в журнале Science, что тест Тьюринга больше проверяет человеческие предположения, чем реальный интеллект. Конечно, ИИ может звучать бегло и убедительно, но это не то же самое, что быть универсально разумным. Это как быть мастером в шахматах — впечатляюще, но не вся картина.
Последний ажиотаж вызван статьёй Кэмерона Джонса и Бенджамина Бергена из UC San Diego под названием «Большие языковые модели проходят тест Тьюринга», опубликованной на сервере препринтов arXiv. Они проводили этот эксперимент годами с помощью студентов UC San Diego, и это часть длинной линии исследований — более 800 заявлений и контраргументов о прохождении компьютерами теста Тьюринга.
Как работает тест Тьюринга
Итак, как работает этот тест? Изначально Тьюринг представлял его как игру в текстовые сообщения между человеком-«судьёй» и двумя «свидетелями» — одним человеком и одним компьютером. Задача свидетелей — убедить судью, что они люди. Судья знает, что один из них человек, но не знает, кто именно, и должен угадать. Это трёхсторонняя установка, где важны восприятие и убеждение не меньше, чем способности компьютера.
Джонс и Берген добавили свою изюминку в эту классическую схему, и вы даже можете попробовать это онлайн, играя роль судьи или свидетеля. В их версии студенты UC San Diego использовали приложение для текстового чата. Одни играли судей, другие — свидетелей-людей, а GPT-4.5 выступал в роли свидетеля-компьютера. Каждый судья одновременно общался с человеком и компьютером, следуя оригинальному формату Тьюринга.
Для роли свидетеля-компьютера использовали разные большие языковые модели, предоставляя им подсказки на основе вопросов судьи. GPT-4.5 тестировали с двумя разными подсказками: одной с минимальной информацией и другой, названной PERSONA, с подробными инструкциями вести себя как молодой, интровертированный, разбирающийся в интернете человек, использующий сленг.
Результаты
Они также тестировали три других ИИ-программы: предыдущую модель OpenAI, GPT-4o; Llama 3.1 405b от Meta Platforms; и древний чат-бот 1960-х годов, ELIZA. ELIZA включили, чтобы проверить, обманывают ли большие языковые модели людей случайно или они действительно лучше.
По словам Джонса и Бергена, GPT-4.5 обманывал судей, заставляя их думать, что он человек, в 73% случаев — это они называют «процентом побед». Это значительно лучше, чем у других моделей, которые набрали от 21% до 56%, даже с похожими подробными подсказками. И это огромный скачок по сравнению с прошлогодним тестом GPT-4, у которого процент побед был всего 54%, чуть выше случайного уровня.
Джонс и Берген обнаружили, что судьи не только были обмануты ИИ, но и чаще верили, что он человек, чем настоящие участники-люди.
Является ли тест настоящей мерой интеллекта?
Итак, что значит, что люди не могут отличить компьютер от человека в чате? Большой вопрос, обсуждаемый десятилетиями, — действительно ли тест Тьюринга измеряет интеллект. Джонс и Берген предполагают, что, возможно, машины просто стали настолько хороши в адаптации к разным сценариям, что могут убедительно выдавать себя за людей. Подсказка PERSONA, созданная людьми, — это то, к чему GPT-4.5 приспособился и использовал в свою пользу.
Но есть загвоздка: возможно, люди просто плохо распознают интеллект. Авторы отмечают, что ELIZA, древний чат-бот, обманывал судей в 23% случаев не потому, что был умнее, а потому, что не соответствовал их ожиданиям от ИИ. Некоторые судьи считали его человеком, потому что он был «саркастичным» или «грубым», чего они не ожидали от ИИ.
Это говорит о том, что судьи руководствуются своими предположениями о том, как должны вести себя люди и ИИ, а не просто выбирают наиболее разумного агента. Интересно, что судьи не особо обращали внимание на знания, которые Тьюринг считал ключевыми. Вместо этого они чаще считали свидетеля человеком, если он казался менее осведомлённым.
Общительность, а не интеллект
Всё это указывает на то, что люди улавливали скорее общительность, чем интеллект. Джонс и Берген заключают, что тест Тьюринга на самом деле не тест интеллекта — это тест на человеческое сходство.
Тьюринг мог считать, что интеллект — главное препятствие для человекоподобия, но по мере того, как машины становятся ближе к нам, другие различия становятся заметнее. Интеллекта самого по себе уже недостаточно, чтобы казаться убедительно человеком.
В статье прямо не говорится, что люди так привыкли печатать на компьютерах, будь то общение с человеком или машиной, что тест Тьюринга уже не тот уникальный тест взаимодействия человека и компьютера, каким он был раньше. Теперь это скорее тест на человеческие привычки в интернете.
Авторы предлагают расширить тест, потому что интеллект слишком сложен и многогранен, чтобы один тест мог быть решающим. Они предлагают разные подходы, например, использовать экспертов по ИИ в качестве судей или добавить финансовые стимулы, чтобы судьи внимательнее анализировали. Эти изменения могли бы показать, как сильно отношение и ожидания влияют на результаты.
Они заключают, что, хотя тест Тьюринга может быть частью картины, его следует рассматривать в совокупности с другими видами доказательств. Это соответствует растущей тенденции в исследованиях ИИ вовлекать людей «в процесс», оценивая действия машин.
Достаточно ли человеческого суждения?
Но остаётся вопрос, будет ли человеческое суждение достаточным в долгосрочной перспективе. В фильме Blade Runner люди используют машину «Voight-Kampff», чтобы отличить людей от роботов-репликантов. Пока мы стремимся к AGI и пытаемся определить, что это вообще такое, мы можем в итоге полагаться на машины для оценки машинного интеллекта.
Или, по крайней мере, нам, возможно, придётся спрашивать у машин, что они «думают» о людях, пытающихся обмануть других людей с помощью подсказок. Это дикий мир в исследованиях ИИ, и он становится только интереснее.










 WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
WordPress.com теперь позволяет ИИ-ботам создавать и публиковать посты, а также выполнять другие задачи
WordPress.com, популярная платформа для веб-хостинга и публикации контента, теперь внедряет ИИ-агентов — шаг, который может кардинально изменить облик и функциональность Интернета. В пятницу компания
 Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
 DeepSeek Code готовится к запуску
На фоне стремительного развития технологий искусственного интеллекта компания DeepSeek находится на захватывающем этапе своего развития. Недавно эта компания, специализирующаяся на ИИ, объявила о прив
DeepSeek Code готовится к запуску
На фоне стремительного развития технологий искусственного интеллекта компания DeepSeek находится на захватывающем этапе своего развития. Недавно эта компания, специализирующаяся на ИИ, объявила о прив

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
10 инструментов
xix.ai

Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?













