




OpenAIのGPT-4.5が暴露したチューリングテストの問題
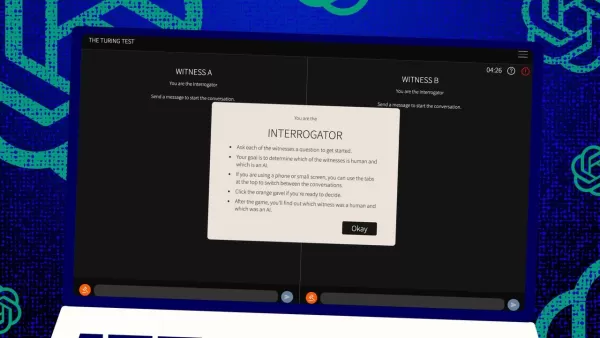
チューリングテストは、伝説的なアラン・チューリングの発案であり、人工知能の世界で長い間ベンチマークとされてきました。しかし、最初に一般的な誤解を解いておきましょう。チューリングテストに合格することは、必ずしもマシンが人間のよう に「思考」していることを意味するわけではありません。それよりも、人間を説得してそう思わせることに関係しています。
カリフォルニア大学サンディエゴ校の最近の研究は、OpenAIの最新モデル、GPT-4.5に注目を集めています。このAIは、人間が他の人とチャットしていると信じ込ませる能力が、人間が互いに自分の人間性を説得するよりもさらに効果的です。これはAIの世界ではかなり大きな出来事です。まるでマジックのトリックを見ているようで、秘密を知っていても驚かされます。
AGIの証明?
しかし、ここで重要なのは、カリフォルニア大学サンディエゴ校の研究者たちでさえ、AIモデルがチューリングテストに合格したからといって「人工汎用知能」(AGI)に到達したと宣言する準備ができていないことです。AGIはAIの聖杯であり、人間と同じように思考し情報を処理できるマシンです。
サンタフェ研究所のAI研究者メラニー・ミッチェルは、ジャーナルScienceで、チューリングテストは実際の知能よりも人間の前提をテストするものだと主張しています。確かに、AIは流暢で説得力があるように聞こえるかもしれませんが、それは一般的な知能を持っていることと同じではありません。チェスが得意なのと同じで、素晴らしいことですが、全体像ではありません。
この話題の最新の話題は、カリフォルニア大学サンディエゴ校のキャメロン・ジョーンズとベンジャミン・バーゲンによる論文「Large Language Models Pass the Turing Test」で、arXivプレプリントサーバーに公開されています。彼らは何年もこの実験を行っており、カリフォルニア大学サンディエゴ校の学部生の協力を得て、コンピュータがチューリングテストに合格したという800以上の主張と反論がこれまでに行われてきた長い研究の一環です。
チューリングテストの仕組み
では、このテストはどのように機能するのでしょうか?元々、チューリングはこれを人間の「裁判官」と2人の「証人」—1人は人間、1人はコンピュータ—とのテキストメッセージのゲームとして想像しました。証人の課題は、裁判官に自分が人間だと説得することです。裁判官はどちらか一方が人間だと知っていますが、どちらが人間かを知らず、推測する必要があります。これは、コンピュータの能力と同じくらい、知覚と信念に関する3者間の設定です。
ジョーンズとバーゲンはこの古典的な設定に独自のひねりを加えており、オンラインで試すこともでき、裁判官または証人としてプレイできます。彼らのバージョンでは、カリフォルニア大学サンディエゴ校の学生がテキストチャットアプリを使用しました。一部は裁判官を務め、他は人間の証人として、GPT-4.5がコンピュータの証人として参加しました。各裁判官は、チューリングの元の形式に忠実に、人間とコンピュータの両方と同時にチャットしました。
コンピュータの証人を演じるために、彼らは異なる大規模言語モデルを使用し、裁判官の挑戦に基づいたプロンプトを入力しました。GPT-4.5は2つの異なるプロンプトでテストされました。1つは最小限の情報、もう1つはPERSONAと呼ばれるもので、若くて内向的でインターネットに精通したスラングを使う人物として振る舞う詳細な指示が含まれていました。
結果
彼らはまた、3つの他のAIプログラムをテストしました:OpenAIの以前のモデル、GPT-4o、Meta PlatformsのLlama 3.1 405b、そして1960年代の古いチャットボット、ELIZAです。ELIZAをテストに含めたのは、大規模言語モデルが単に偶然人間を騙しているのか、それとも本当により優れているのかを確認するためでした。
ジョーンズとバーゲンによると、GPT-4.5は人間の裁判官を73%の確率で人間だと信じ込ませました。これは彼らが「勝率」と呼ぶもので、他のモデル(21%から56%のスコア)よりもはるかに優れていました。詳細なプロンプトを使用しても同様の結果でした。そして、昨年のGPT-4のテストでの勝率54%(ほぼランダムな確率)からの大きな飛躍です。
ジョーンズとバーゲンは、裁判官がAIに騙されただけでなく、実際の人間の参加者よりもAIが人間だと信じられる可能性が高いことを発見しました。
テストは本当に知能を測定しているのか?
では、チャットで人間がコンピュータと人を区別できないことは何を意味するのでしょうか?何十年も議論されてきた大きな疑問は、チューリングテストが本当に知能を測定しているのかということです。ジョーンズとバーゲンは、マシンがさまざまなシナリオに適応する能力が非常に優れているため、人間として説得力を持って振る舞えるのかもしれないと示唆しています。人間が作成したPERSONAプロンプトは、GPT-4.5が適応し、活用したものです。
しかし、問題があります。人間が知能を認識するのが下手なのかもしれません。著者は、古いチャットボットELIZAが23%の確率で裁判官を騙したのは、それが賢いからではなく、AIに対する彼らの期待を満たさなかったからだと指摘しています。一部の裁判官は、ELIZAが「皮肉」や「無礼」だったため人間だと思ったとされ、AIに期待していなかった態度でした。
これは、裁判官が人間やAIがどう振る舞うべきかという前提に影響されていることを示唆しています。興味深いことに、裁判官はチューリングが重要だと考えていた知識にはあまり焦点を当てませんでした。代わりに、知識が不足しているように見える証人を人間だと考える傾向がありました。
社交性、知能ではない
これらすべては、人間が知能ではなく社交性を重視していたという考えを指しています。ジョーンズとバーゲンは、チューリングテストは本当の知能のテストではなく、人間らしさのテストだと結論付けています。
チューリングは、知能が人間らしく見えるための最大の障害だと考えていたかもしれませんが、マシンが我々に近づくにつれて、他の違いがより明らかになります。知能だけでは、もはや説得力のある人間らしさには十分ではありません。
論文では直接言及されていませんが、人間はコンピュータでのタイピングに慣れすぎており、人間とマシンのどちらと話しているかにかかわらず、チューリングテストはかつてのような斬新な人間とコンピュータの相互作用のテストではなく、オンラインの人間の習慣のテストになっています。
著者は、知能は非常に複雑で多面的であるため、単一のテストでは決定的なものにはならないとして、テストを拡張する必要があるかもしれないと提案しています。AIの専門家を裁判官にしたり、金銭的インセンティブを追加して裁判官がより厳密に精査するようにするなど、異なるデザインを提案しています。これらの変更は、態度や期待が結果にどれだけ影響するかを示す可能性があります。
彼らは、チューリングテストが全体像の一部かもしれないが、他の種類の証拠と一緒に考慮すべきだと結論付けています。これは、AI研究において人間を「ループ」に含め、マシンの行動を評価する傾向が高まっていることと一致しています。
人間の判断は十分か?
しかし、長期的に見て人間の判断が十分かどうか、という疑問が残ります。映画Blade Runnerでは、人間は「Voight-Kampff」というマシンを使用して人間とレプリカントロボットを区別します。AGIを追い求め、そもそもそれが何かを定義するのに苦労する中、結局、マシンの知能を評価するためにマシンに頼ることになるかもしれません。
あるいは、少なくとも、プロンプトを使って人間を騙そうとする人間について、マシンがどう「考える」かを尋ねる必要があるかもしれません。AI研究の世界は刺激的で、ますます興味深いものになっています。
関連記事
 トレーニングはAIによる認知オフロード効果を軽減するか?
Unite.aiの最近の調査記事「ChatGPTはあなたの脳を消耗させているかもしれない:AI時代の認知負債」と題されたUnite.iの最近の調査記事で、MITの研究に光が当てられた。ジャーナリストのアレックス・マクファーランドは、過度のAI依存がいかに本質的な認知能力、特に批判的思考や判断力を蝕むかについて、説得力のある証拠を詳述した。これらの知見は他の多くの研究と一致しているが、現在の喫緊の課
AIを活用したグラフやビジュアライゼーションを簡単に作成し、より優れたデータインサイトを実現
現代のデータ分析では、複雑な情報を直感的に視覚化することが求められています。AIを活用したグラフ生成ソリューションは、生データを説得力のあるビジュアルストーリーに変換する専門家の方法に革命をもたらし、不可欠な資産として登場しました。これらのインテリジェントなシステムは、精度を保ちながら手作業によるグラフ作成を排除し、技術的なユーザーにもそうでないユーザーにも、自動化された視覚化を通じて実用的な洞察
営業戦略を変える:VapiのAIコールドコールテクノロジー
現代のビジネスは電光石火のスピードで動いており、競争力を維持するために革新的なソリューションが求められています。AIを活用したコールドコールシステムで、代理店のアウトリーチに革命を起こすことを想像してみてください。Vapiのようなプラットフォームは、このような変革を可能にし、自然な会話を行うカスタマイズされたダイヤラーを構築することを可能にします。この包括的なガイドでは、アウトリーチを大規模にパー
コメント (4)
0/200
トレーニングはAIによる認知オフロード効果を軽減するか?
Unite.aiの最近の調査記事「ChatGPTはあなたの脳を消耗させているかもしれない:AI時代の認知負債」と題されたUnite.iの最近の調査記事で、MITの研究に光が当てられた。ジャーナリストのアレックス・マクファーランドは、過度のAI依存がいかに本質的な認知能力、特に批判的思考や判断力を蝕むかについて、説得力のある証拠を詳述した。これらの知見は他の多くの研究と一致しているが、現在の喫緊の課
AIを活用したグラフやビジュアライゼーションを簡単に作成し、より優れたデータインサイトを実現
現代のデータ分析では、複雑な情報を直感的に視覚化することが求められています。AIを活用したグラフ生成ソリューションは、生データを説得力のあるビジュアルストーリーに変換する専門家の方法に革命をもたらし、不可欠な資産として登場しました。これらのインテリジェントなシステムは、精度を保ちながら手作業によるグラフ作成を排除し、技術的なユーザーにもそうでないユーザーにも、自動化された視覚化を通じて実用的な洞察
営業戦略を変える:VapiのAIコールドコールテクノロジー
現代のビジネスは電光石火のスピードで動いており、競争力を維持するために革新的なソリューションが求められています。AIを活用したコールドコールシステムで、代理店のアウトリーチに革命を起こすことを想像してみてください。Vapiのようなプラットフォームは、このような変革を可能にし、自然な会話を行うカスタマイズされたダイヤラーを構築することを可能にします。この包括的なガイドでは、アウトリーチを大規模にパー
コメント (4)
0/200
![CarlLewis]() CarlLewis
CarlLewis
 2025年8月20日 18:01:15 JST
2025年8月20日 18:01:15 JST
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?


 0
0
![JamesLopez]() JamesLopez
2025年8月11日 15:20:39 JST
JamesLopez
2025年8月11日 15:20:39 JST
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
0
![DavidGonzález]() DavidGonzález
2025年8月3日 0:07:14 JST
DavidGonzález
2025年8月3日 0:07:14 JST
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
0
![PaulWilson]() PaulWilson
2025年8月1日 15:08:50 JST
PaulWilson
2025年8月1日 15:08:50 JST
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
0
チューリングテストは、伝説的なアラン・チューリングの発案であり、人工知能の世界で長い間ベンチマークとされてきました。しかし、最初に一般的な誤解を解いておきましょう。チューリングテストに合格することは、必ずしもマシンが人間のよう に「思考」していることを意味するわけではありません。それよりも、人間を説得してそう思わせることに関係しています。
カリフォルニア大学サンディエゴ校の最近の研究は、OpenAIの最新モデル、GPT-4.5に注目を集めています。このAIは、人間が他の人とチャットしていると信じ込ませる能力が、人間が互いに自分の人間性を説得するよりもさらに効果的です。これはAIの世界ではかなり大きな出来事です。まるでマジックのトリックを見ているようで、秘密を知っていても驚かされます。
AGIの証明?
しかし、ここで重要なのは、カリフォルニア大学サンディエゴ校の研究者たちでさえ、AIモデルがチューリングテストに合格したからといって「人工汎用知能」(AGI)に到達したと宣言する準備ができていないことです。AGIはAIの聖杯であり、人間と同じように思考し情報を処理できるマシンです。
サンタフェ研究所のAI研究者メラニー・ミッチェルは、ジャーナルScienceで、チューリングテストは実際の知能よりも人間の前提をテストするものだと主張しています。確かに、AIは流暢で説得力があるように聞こえるかもしれませんが、それは一般的な知能を持っていることと同じではありません。チェスが得意なのと同じで、素晴らしいことですが、全体像ではありません。
この話題の最新の話題は、カリフォルニア大学サンディエゴ校のキャメロン・ジョーンズとベンジャミン・バーゲンによる論文「Large Language Models Pass the Turing Test」で、arXivプレプリントサーバーに公開されています。彼らは何年もこの実験を行っており、カリフォルニア大学サンディエゴ校の学部生の協力を得て、コンピュータがチューリングテストに合格したという800以上の主張と反論がこれまでに行われてきた長い研究の一環です。
チューリングテストの仕組み
では、このテストはどのように機能するのでしょうか?元々、チューリングはこれを人間の「裁判官」と2人の「証人」—1人は人間、1人はコンピュータ—とのテキストメッセージのゲームとして想像しました。証人の課題は、裁判官に自分が人間だと説得することです。裁判官はどちらか一方が人間だと知っていますが、どちらが人間かを知らず、推測する必要があります。これは、コンピュータの能力と同じくらい、知覚と信念に関する3者間の設定です。
ジョーンズとバーゲンはこの古典的な設定に独自のひねりを加えており、オンラインで試すこともでき、裁判官または証人としてプレイできます。彼らのバージョンでは、カリフォルニア大学サンディエゴ校の学生がテキストチャットアプリを使用しました。一部は裁判官を務め、他は人間の証人として、GPT-4.5がコンピュータの証人として参加しました。各裁判官は、チューリングの元の形式に忠実に、人間とコンピュータの両方と同時にチャットしました。
コンピュータの証人を演じるために、彼らは異なる大規模言語モデルを使用し、裁判官の挑戦に基づいたプロンプトを入力しました。GPT-4.5は2つの異なるプロンプトでテストされました。1つは最小限の情報、もう1つはPERSONAと呼ばれるもので、若くて内向的でインターネットに精通したスラングを使う人物として振る舞う詳細な指示が含まれていました。
結果
彼らはまた、3つの他のAIプログラムをテストしました:OpenAIの以前のモデル、GPT-4o、Meta PlatformsのLlama 3.1 405b、そして1960年代の古いチャットボット、ELIZAです。ELIZAをテストに含めたのは、大規模言語モデルが単に偶然人間を騙しているのか、それとも本当により優れているのかを確認するためでした。
ジョーンズとバーゲンによると、GPT-4.5は人間の裁判官を73%の確率で人間だと信じ込ませました。これは彼らが「勝率」と呼ぶもので、他のモデル(21%から56%のスコア)よりもはるかに優れていました。詳細なプロンプトを使用しても同様の結果でした。そして、昨年のGPT-4のテストでの勝率54%(ほぼランダムな確率)からの大きな飛躍です。
ジョーンズとバーゲンは、裁判官がAIに騙されただけでなく、実際の人間の参加者よりもAIが人間だと信じられる可能性が高いことを発見しました。
テストは本当に知能を測定しているのか?
では、チャットで人間がコンピュータと人を区別できないことは何を意味するのでしょうか?何十年も議論されてきた大きな疑問は、チューリングテストが本当に知能を測定しているのかということです。ジョーンズとバーゲンは、マシンがさまざまなシナリオに適応する能力が非常に優れているため、人間として説得力を持って振る舞えるのかもしれないと示唆しています。人間が作成したPERSONAプロンプトは、GPT-4.5が適応し、活用したものです。
しかし、問題があります。人間が知能を認識するのが下手なのかもしれません。著者は、古いチャットボットELIZAが23%の確率で裁判官を騙したのは、それが賢いからではなく、AIに対する彼らの期待を満たさなかったからだと指摘しています。一部の裁判官は、ELIZAが「皮肉」や「無礼」だったため人間だと思ったとされ、AIに期待していなかった態度でした。
これは、裁判官が人間やAIがどう振る舞うべきかという前提に影響されていることを示唆しています。興味深いことに、裁判官はチューリングが重要だと考えていた知識にはあまり焦点を当てませんでした。代わりに、知識が不足しているように見える証人を人間だと考える傾向がありました。
社交性、知能ではない
これらすべては、人間が知能ではなく社交性を重視していたという考えを指しています。ジョーンズとバーゲンは、チューリングテストは本当の知能のテストではなく、人間らしさのテストだと結論付けています。
チューリングは、知能が人間らしく見えるための最大の障害だと考えていたかもしれませんが、マシンが我々に近づくにつれて、他の違いがより明らかになります。知能だけでは、もはや説得力のある人間らしさには十分ではありません。
論文では直接言及されていませんが、人間はコンピュータでのタイピングに慣れすぎており、人間とマシンのどちらと話しているかにかかわらず、チューリングテストはかつてのような斬新な人間とコンピュータの相互作用のテストではなく、オンラインの人間の習慣のテストになっています。
著者は、知能は非常に複雑で多面的であるため、単一のテストでは決定的なものにはならないとして、テストを拡張する必要があるかもしれないと提案しています。AIの専門家を裁判官にしたり、金銭的インセンティブを追加して裁判官がより厳密に精査するようにするなど、異なるデザインを提案しています。これらの変更は、態度や期待が結果にどれだけ影響するかを示す可能性があります。
彼らは、チューリングテストが全体像の一部かもしれないが、他の種類の証拠と一緒に考慮すべきだと結論付けています。これは、AI研究において人間を「ループ」に含め、マシンの行動を評価する傾向が高まっていることと一致しています。
人間の判断は十分か?
しかし、長期的に見て人間の判断が十分かどうか、という疑問が残ります。映画Blade Runnerでは、人間は「Voight-Kampff」というマシンを使用して人間とレプリカントロボットを区別します。AGIを追い求め、そもそもそれが何かを定義するのに苦労する中、結局、マシンの知能を評価するためにマシンに頼ることになるかもしれません。
あるいは、少なくとも、プロンプトを使って人間を騙そうとする人間について、マシンがどう「考える」かを尋ねる必要があるかもしれません。AI研究の世界は刺激的で、ますます興味深いものになっています。










 トレーニングはAIによる認知オフロード効果を軽減するか?
Unite.aiの最近の調査記事「ChatGPTはあなたの脳を消耗させているかもしれない:AI時代の認知負債」と題されたUnite.iの最近の調査記事で、MITの研究に光が当てられた。ジャーナリストのアレックス・マクファーランドは、過度のAI依存がいかに本質的な認知能力、特に批判的思考や判断力を蝕むかについて、説得力のある証拠を詳述した。これらの知見は他の多くの研究と一致しているが、現在の喫緊の課
トレーニングはAIによる認知オフロード効果を軽減するか?
Unite.aiの最近の調査記事「ChatGPTはあなたの脳を消耗させているかもしれない:AI時代の認知負債」と題されたUnite.iの最近の調査記事で、MITの研究に光が当てられた。ジャーナリストのアレックス・マクファーランドは、過度のAI依存がいかに本質的な認知能力、特に批判的思考や判断力を蝕むかについて、説得力のある証拠を詳述した。これらの知見は他の多くの研究と一致しているが、現在の喫緊の課
 AIを活用したグラフやビジュアライゼーションを簡単に作成し、より優れたデータインサイトを実現
現代のデータ分析では、複雑な情報を直感的に視覚化することが求められています。AIを活用したグラフ生成ソリューションは、生データを説得力のあるビジュアルストーリーに変換する専門家の方法に革命をもたらし、不可欠な資産として登場しました。これらのインテリジェントなシステムは、精度を保ちながら手作業によるグラフ作成を排除し、技術的なユーザーにもそうでないユーザーにも、自動化された視覚化を通じて実用的な洞察
AIを活用したグラフやビジュアライゼーションを簡単に作成し、より優れたデータインサイトを実現
現代のデータ分析では、複雑な情報を直感的に視覚化することが求められています。AIを活用したグラフ生成ソリューションは、生データを説得力のあるビジュアルストーリーに変換する専門家の方法に革命をもたらし、不可欠な資産として登場しました。これらのインテリジェントなシステムは、精度を保ちながら手作業によるグラフ作成を排除し、技術的なユーザーにもそうでないユーザーにも、自動化された視覚化を通じて実用的な洞察
 営業戦略を変える:VapiのAIコールドコールテクノロジー
現代のビジネスは電光石火のスピードで動いており、競争力を維持するために革新的なソリューションが求められています。AIを活用したコールドコールシステムで、代理店のアウトリーチに革命を起こすことを想像してみてください。Vapiのようなプラットフォームは、このような変革を可能にし、自然な会話を行うカスタマイズされたダイヤラーを構築することを可能にします。この包括的なガイドでは、アウトリーチを大規模にパー
2025年8月20日 18:01:15 JST
営業戦略を変える:VapiのAIコールドコールテクノロジー
現代のビジネスは電光石火のスピードで動いており、競争力を維持するために革新的なソリューションが求められています。AIを活用したコールドコールシステムで、代理店のアウトリーチに革命を起こすことを想像してみてください。Vapiのようなプラットフォームは、このような変革を可能にし、自然な会話を行うカスタマイズされたダイヤラーを構築することを可能にします。この包括的なガイドでは、アウトリーチを大規模にパー
2025年8月20日 18:01:15 JST
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild—makes you wonder if we're chasing the wrong AI benchmark. 🤯 What’s next, machines outsmarting us at our own game?
0
2025年8月11日 15:20:39 JST
Mind-blowing read! GPT-4.5 exposing the Turing Test's flaws is wild. Makes me wonder if we're chasing the wrong AI benchmark. 🧠 What's next?
0
2025年8月3日 0:07:14 JST
Mind blown! GPT-4.5 is shaking up the Turing Test, but it’s wild to think it’s still just mimicking, not truly thinking like us. 🤯 Makes me wonder if we’re chasing the wrong goal in AI.
0
2025年8月1日 15:08:50 JST
GPT-4.5 blowing past the Turing Test is wild! 😲 But honestly, it just shows the test’s more about trickery than true smarts. Makes you wonder if we’re measuring AI’s brainpower or just its acting skills. What’s next, an Oscar for chatbots?
0













