




Moins c'est plus: comment la récupération de moins de documents améliore les réponses de l'IA
La Génération Augmentée par Récupération (RAG) est une approche innovante pour construire des systèmes d'IA, combinant un modèle linguistique avec une source de connaissances externe pour améliorer la précision et réduire les erreurs factuelles. En essence, l'IA recherche des documents pertinents liés à la requête d'un utilisateur et utilise ces informations pour générer une réponse plus précise. Cette méthode a été reconnue pour sa capacité à maintenir les grands modèles linguistiques (LLMs) ancrés dans des données réelles, minimisant le risque d'hallucinations.
Vous pourriez supposer que fournir à une IA plus de documents conduirait à des réponses mieux informées. Cependant, une étude récente de l'Université Hébraïque de Jérusalem suggère le contraire : lorsqu'il s'agit de fournir des informations à une IA, moins peut en effet être plus.
Moins de Documents, Meilleures Réponses
L'étude a examiné comment le nombre de documents fournis à un système RAG affecte ses performances. Les chercheurs ont maintenu une longueur totale de texte constante, ajustant le nombre de documents de 20 à 2-4 documents pertinents et en augmentant ceux-ci pour correspondre au volume de texte initial. Cela leur a permis d'isoler l'effet de la quantité de documents sur les performances.
En utilisant l'ensemble de données MuSiQue, qui comprend des questions de culture générale associées à des paragraphes de Wikipédia, ils ont constaté que les modèles d'IA performaient souvent mieux avec moins de documents. La précision s'est améliorée jusqu'à 10 % (mesurée par le score F1) lorsque le système se concentrait sur quelques documents clés plutôt qu'une vaste collection. Cette tendance s'est maintenue à travers divers modèles linguistiques open-source, tels que Llama de Meta, Qwen-2 étant l'exception notable, maintenant ses performances avec plusieurs documents.
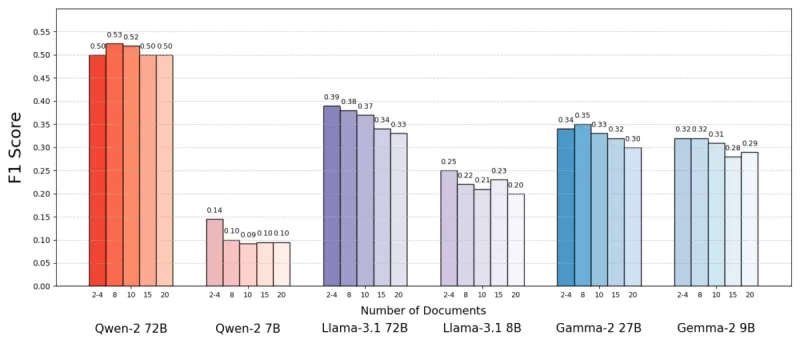 Source : Levy et al.
Source : Levy et al.
Ce résultat surprenant remet en question la croyance commune selon laquelle plus d'informations aide toujours. Même avec la même quantité de texte, la présence de plusieurs documents semblait compliquer la tâche de l'IA, introduisant plus de bruit que de signal.
Pourquoi Moins Peut Être Plus dans le RAG
Le principe "moins, c'est plus" prend tout son sens lorsque l'on considère comment les modèles d'IA traitent l'information. Avec moins de documents, mais plus pertinents, l'IA peut se concentrer sur le contexte essentiel sans distractions, tout comme un étudiant qui étudie le matériel le plus pertinent.
Dans l'étude, les modèles performaient mieux lorsqu'on leur donnait uniquement les documents directement pertinents pour la réponse, car ce contexte plus propre et ciblé facilitait l'extraction de l'information correcte. Inversement, lorsque l'IA devait trier de nombreux documents, elle avait souvent du mal à gérer le mélange de contenus pertinents et non pertinents. Des documents similaires mais non liés pouvaient induire le modèle en erreur, augmentant le risque d'hallucinations.
Il est intéressant de noter que l'étude a révélé que l'IA pouvait plus facilement ignorer les documents manifestement non pertinents que ceux légèrement hors sujet. Cela suggère que des distracteurs réalistes sont plus déroutants que des distracteurs aléatoires. En limitant les documents à ceux strictement nécessaires, nous réduisons la probabilité de tendre de tels pièges.
De plus, utiliser moins de documents réduit la surcharge computationnelle, rendant le système plus efficace et économique. Cette approche améliore non seulement la précision, mais aussi les performances globales du système RAG.
 Source : Levy et al.
Source : Levy et al.
Repenser le RAG : Orientations Futures
Ces résultats ont des implications significatives pour la conception des futurs systèmes d'IA qui s'appuient sur des connaissances externes. Ils suggèrent que se concentrer sur la qualité et la pertinence des documents récupérés, plutôt que sur leur quantité, pourrait améliorer les performances. Les auteurs de l'étude plaident pour des méthodes de récupération qui équilibrent pertinence et diversité, garantissant une couverture complète sans submerger le modèle avec du texte superflu.
Les recherches futures pourraient explorer de meilleurs systèmes de récupération ou des re-classeurs pour identifier les documents véritablement précieux et améliorer la manière dont les modèles linguistiques gèrent plusieurs sources. Améliorer les modèles eux-mêmes, comme observé avec Qwen-2, pourrait également fournir des idées pour les rendre plus robustes face à des entrées variées.
À mesure que les systèmes d'IA développent des fenêtres de contexte plus larges, la capacité à traiter plus de texte à la fois devient moins critique que de s'assurer que le texte est pertinent et bien sélectionné. L'étude, intitulée "Plus de Documents, Même Longueur," souligne l'importance de se concentrer sur l'information la plus pertinente pour améliorer la précision et l'efficacité de l'IA.
En conclusion, cette recherche remet en question nos hypothèses sur l'entrée de données dans les systèmes d'IA. En sélectionnant soigneusement moins de documents, mais de meilleure qualité, nous pouvons créer des systèmes RAG plus intelligents, plus économes, qui fournissent des réponses plus précises et fiables.
Article connexe
 Craig Federighi, d'Apple, admet que Siri, alimenté par l'IA, présentait de sérieuses lacunes à ses débuts
Les dirigeants d'Apple expliquent le retard de la mise à jour de SiriLors de la WWDC 2024, Apple avait initialement promis d'importantes améliorations de Siri, notamment une prise en compte personna
Maîtriser les techniques d'Inpainting AI : Guide d'initiation à l'édition d'images sans faille
Découvrez les capacités transformatrices de la technologie d'inpainting AI de Midjourney, une fonctionnalité révolutionnaire qui permet aux créateurs d'affiner et de perfectionner les œuvres d'art gén
Manus lance l'outil d'IA "Wide Research" avec plus de 100 agents pour l'exploration du Web
L'innovateur chinois Manus, qui a déjà attiré l'attention sur sa plateforme d'orchestration multi-agents destinée à la fois aux consommateurs et aux utilisateurs professionnels, a dévoilé une applicat
commentaires (47)
0/200
Craig Federighi, d'Apple, admet que Siri, alimenté par l'IA, présentait de sérieuses lacunes à ses débuts
Les dirigeants d'Apple expliquent le retard de la mise à jour de SiriLors de la WWDC 2024, Apple avait initialement promis d'importantes améliorations de Siri, notamment une prise en compte personna
Maîtriser les techniques d'Inpainting AI : Guide d'initiation à l'édition d'images sans faille
Découvrez les capacités transformatrices de la technologie d'inpainting AI de Midjourney, une fonctionnalité révolutionnaire qui permet aux créateurs d'affiner et de perfectionner les œuvres d'art gén
Manus lance l'outil d'IA "Wide Research" avec plus de 100 agents pour l'exploration du Web
L'innovateur chinois Manus, qui a déjà attiré l'attention sur sa plateforme d'orchestration multi-agents destinée à la fois aux consommateurs et aux utilisateurs professionnels, a dévoilé une applicat
commentaires (47)
0/200
![LarryWilliams]() LarryWilliams
LarryWilliams
 10 septembre 2025 02:30:32 UTC+02:00
10 septembre 2025 02:30:32 UTC+02:00
La RAG est révolutionnaire, mais je me demande si limiter les documents récupérés pourrait parfois manquer des infos cruciales 🤔. Perso, j'opterais pour un juste milieu entre précision et exhaustivité !


 0
0
![BruceBrown]() BruceBrown
29 juillet 2025 14:25:16 UTC+02:00
BruceBrown
29 juillet 2025 14:25:16 UTC+02:00
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?
0
![JasonMartin]() JasonMartin
26 avril 2025 08:04:32 UTC+02:00
JasonMartin
26 avril 2025 08:04:32 UTC+02:00
Adoro como essa ferramenta torna as respostas do AI mais precisas usando menos documentos. É como mágica! Mas às vezes parece que está faltando alguma informação. Ainda assim, uma ótima ferramenta para respostas rápidas e confiáveis. 👍
0
![JuanMoore]() JuanMoore
24 avril 2025 00:29:07 UTC+02:00
JuanMoore
24 avril 2025 00:29:07 UTC+02:00
I love how this tool makes AI responses more accurate by using fewer documents. It's like magic! But sometimes it feels like it's missing out on some info. Still, a great tool for quick, reliable answers. 👍
0
![GregoryJones]() GregoryJones
22 avril 2025 18:50:26 UTC+02:00
GregoryJones
22 avril 2025 18:50:26 UTC+02:00
「少ない方が良い」というAIの応答方法はかなりクール!少ないドキュメントから正確な答えを得るなんて、登録したいですね!魔法のようですが、もっと早く動いてほしいです。でも、AI技術の前進の一歩としては素晴らしいですね!🚀
0
![BrianMartinez]() BrianMartinez
21 avril 2025 13:14:10 UTC+02:00
BrianMartinez
21 avril 2025 13:14:10 UTC+02:00
This app really simplifies things! By retrieving fewer but more relevant documents, the AI responses are much more accurate and to the point. It's like having a smart assistant that knows exactly what you need. Only wish it was a bit faster. Still, a great tool! 😊
0
La Génération Augmentée par Récupération (RAG) est une approche innovante pour construire des systèmes d'IA, combinant un modèle linguistique avec une source de connaissances externe pour améliorer la précision et réduire les erreurs factuelles. En essence, l'IA recherche des documents pertinents liés à la requête d'un utilisateur et utilise ces informations pour générer une réponse plus précise. Cette méthode a été reconnue pour sa capacité à maintenir les grands modèles linguistiques (LLMs) ancrés dans des données réelles, minimisant le risque d'hallucinations.
Vous pourriez supposer que fournir à une IA plus de documents conduirait à des réponses mieux informées. Cependant, une étude récente de l'Université Hébraïque de Jérusalem suggère le contraire : lorsqu'il s'agit de fournir des informations à une IA, moins peut en effet être plus.
Moins de Documents, Meilleures Réponses
L'étude a examiné comment le nombre de documents fournis à un système RAG affecte ses performances. Les chercheurs ont maintenu une longueur totale de texte constante, ajustant le nombre de documents de 20 à 2-4 documents pertinents et en augmentant ceux-ci pour correspondre au volume de texte initial. Cela leur a permis d'isoler l'effet de la quantité de documents sur les performances.
En utilisant l'ensemble de données MuSiQue, qui comprend des questions de culture générale associées à des paragraphes de Wikipédia, ils ont constaté que les modèles d'IA performaient souvent mieux avec moins de documents. La précision s'est améliorée jusqu'à 10 % (mesurée par le score F1) lorsque le système se concentrait sur quelques documents clés plutôt qu'une vaste collection. Cette tendance s'est maintenue à travers divers modèles linguistiques open-source, tels que Llama de Meta, Qwen-2 étant l'exception notable, maintenant ses performances avec plusieurs documents.
Source : Levy et al.
Ce résultat surprenant remet en question la croyance commune selon laquelle plus d'informations aide toujours. Même avec la même quantité de texte, la présence de plusieurs documents semblait compliquer la tâche de l'IA, introduisant plus de bruit que de signal.
Pourquoi Moins Peut Être Plus dans le RAG
Le principe "moins, c'est plus" prend tout son sens lorsque l'on considère comment les modèles d'IA traitent l'information. Avec moins de documents, mais plus pertinents, l'IA peut se concentrer sur le contexte essentiel sans distractions, tout comme un étudiant qui étudie le matériel le plus pertinent.
Dans l'étude, les modèles performaient mieux lorsqu'on leur donnait uniquement les documents directement pertinents pour la réponse, car ce contexte plus propre et ciblé facilitait l'extraction de l'information correcte. Inversement, lorsque l'IA devait trier de nombreux documents, elle avait souvent du mal à gérer le mélange de contenus pertinents et non pertinents. Des documents similaires mais non liés pouvaient induire le modèle en erreur, augmentant le risque d'hallucinations.
Il est intéressant de noter que l'étude a révélé que l'IA pouvait plus facilement ignorer les documents manifestement non pertinents que ceux légèrement hors sujet. Cela suggère que des distracteurs réalistes sont plus déroutants que des distracteurs aléatoires. En limitant les documents à ceux strictement nécessaires, nous réduisons la probabilité de tendre de tels pièges.
De plus, utiliser moins de documents réduit la surcharge computationnelle, rendant le système plus efficace et économique. Cette approche améliore non seulement la précision, mais aussi les performances globales du système RAG.
Source : Levy et al.
Repenser le RAG : Orientations Futures
Ces résultats ont des implications significatives pour la conception des futurs systèmes d'IA qui s'appuient sur des connaissances externes. Ils suggèrent que se concentrer sur la qualité et la pertinence des documents récupérés, plutôt que sur leur quantité, pourrait améliorer les performances. Les auteurs de l'étude plaident pour des méthodes de récupération qui équilibrent pertinence et diversité, garantissant une couverture complète sans submerger le modèle avec du texte superflu.
Les recherches futures pourraient explorer de meilleurs systèmes de récupération ou des re-classeurs pour identifier les documents véritablement précieux et améliorer la manière dont les modèles linguistiques gèrent plusieurs sources. Améliorer les modèles eux-mêmes, comme observé avec Qwen-2, pourrait également fournir des idées pour les rendre plus robustes face à des entrées variées.
À mesure que les systèmes d'IA développent des fenêtres de contexte plus larges, la capacité à traiter plus de texte à la fois devient moins critique que de s'assurer que le texte est pertinent et bien sélectionné. L'étude, intitulée "Plus de Documents, Même Longueur," souligne l'importance de se concentrer sur l'information la plus pertinente pour améliorer la précision et l'efficacité de l'IA.
En conclusion, cette recherche remet en question nos hypothèses sur l'entrée de données dans les systèmes d'IA. En sélectionnant soigneusement moins de documents, mais de meilleure qualité, nous pouvons créer des systèmes RAG plus intelligents, plus économes, qui fournissent des réponses plus précises et fiables.










 Craig Federighi, d'Apple, admet que Siri, alimenté par l'IA, présentait de sérieuses lacunes à ses débuts
Les dirigeants d'Apple expliquent le retard de la mise à jour de SiriLors de la WWDC 2024, Apple avait initialement promis d'importantes améliorations de Siri, notamment une prise en compte personna
Craig Federighi, d'Apple, admet que Siri, alimenté par l'IA, présentait de sérieuses lacunes à ses débuts
Les dirigeants d'Apple expliquent le retard de la mise à jour de SiriLors de la WWDC 2024, Apple avait initialement promis d'importantes améliorations de Siri, notamment une prise en compte personna
 Maîtriser les techniques d'Inpainting AI : Guide d'initiation à l'édition d'images sans faille
Découvrez les capacités transformatrices de la technologie d'inpainting AI de Midjourney, une fonctionnalité révolutionnaire qui permet aux créateurs d'affiner et de perfectionner les œuvres d'art gén
Maîtriser les techniques d'Inpainting AI : Guide d'initiation à l'édition d'images sans faille
Découvrez les capacités transformatrices de la technologie d'inpainting AI de Midjourney, une fonctionnalité révolutionnaire qui permet aux créateurs d'affiner et de perfectionner les œuvres d'art gén
 Manus lance l'outil d'IA "Wide Research" avec plus de 100 agents pour l'exploration du Web
L'innovateur chinois Manus, qui a déjà attiré l'attention sur sa plateforme d'orchestration multi-agents destinée à la fois aux consommateurs et aux utilisateurs professionnels, a dévoilé une applicat
10 septembre 2025 02:30:32 UTC+02:00
Manus lance l'outil d'IA "Wide Research" avec plus de 100 agents pour l'exploration du Web
L'innovateur chinois Manus, qui a déjà attiré l'attention sur sa plateforme d'orchestration multi-agents destinée à la fois aux consommateurs et aux utilisateurs professionnels, a dévoilé une applicat
10 septembre 2025 02:30:32 UTC+02:00
La RAG est révolutionnaire, mais je me demande si limiter les documents récupérés pourrait parfois manquer des infos cruciales 🤔. Perso, j'opterais pour un juste milieu entre précision et exhaustivité !
0
29 juillet 2025 14:25:16 UTC+02:00
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?
0
26 avril 2025 08:04:32 UTC+02:00
Adoro como essa ferramenta torna as respostas do AI mais precisas usando menos documentos. É como mágica! Mas às vezes parece que está faltando alguma informação. Ainda assim, uma ótima ferramenta para respostas rápidas e confiáveis. 👍
0
24 avril 2025 00:29:07 UTC+02:00
I love how this tool makes AI responses more accurate by using fewer documents. It's like magic! But sometimes it feels like it's missing out on some info. Still, a great tool for quick, reliable answers. 👍
0
22 avril 2025 18:50:26 UTC+02:00
「少ない方が良い」というAIの応答方法はかなりクール!少ないドキュメントから正確な答えを得るなんて、登録したいですね!魔法のようですが、もっと早く動いてほしいです。でも、AI技術の前進の一歩としては素晴らしいですね!🚀
0
21 avril 2025 13:14:10 UTC+02:00
This app really simplifies things! By retrieving fewer but more relevant documents, the AI responses are much more accurate and to the point. It's like having a smart assistant that knows exactly what you need. Only wish it was a bit faster. Still, a great tool! 😊
0













