
















 Heim
HeimWeniger ist mehr: Wie das Abrufen weniger Dokumente die KI -Antworten verbessert
Retrieval-Augmented Generation (RAG) ist ein innovativer Ansatz zum Aufbau von KI-Systemen, der ein Sprachmodell mit einer externen Wissensquelle kombiniert, um die Genauigkeit zu erhöhen und faktenbasierte Fehler zu reduzieren. Im Wesentlichen sucht die KI nach relevanten Dokumenten, die mit der Anfrage eines Nutzers in Verbindung stehen, und verwendet diese Informationen, um eine präzisere Antwort zu generieren. Diese Methode hat Anerkennung für ihre Fähigkeit gefunden, große Sprachmodelle (LLMs) an realen Daten zu orientieren und das Risiko von Halluzinationen zu minimieren.
Man könnte annehmen, dass die Bereitstellung von mehr Dokumenten einer KI zu besser informierten Antworten führen würde. Eine aktuelle Studie der Hebräischen Universität Jerusalem legt jedoch nahe, dass weniger tatsächlich mehr sein kann, wenn es darum geht, Informationen an eine KI zu liefern.
Weniger Dokumente, bessere Antworten
Die Studie untersuchte, wie die Anzahl der einem RAG-System bereitgestellten Dokumente dessen Leistung beeinflusst. Die Forscher hielten die gesamte Textlänge konstant, variierten die Anzahl der Dokumente von 20 auf 2-4 relevante und erweiterten diese, um das ursprüngliche Textvolumen zu erreichen. Dies ermöglichte es ihnen, den Einfluss der Dokumentenmenge auf die Leistung zu isolieren.
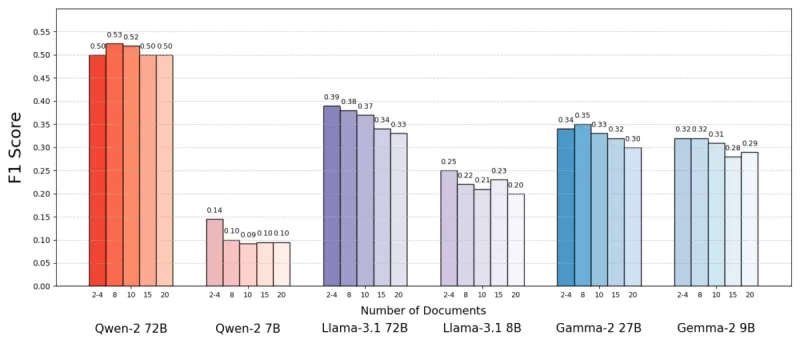
Mit dem MuSiQue-Datensatz, der Trivia-Fragen mit Wikipedia-Absätzen kombiniert, stellten sie fest, dass KI-Modelle oft besser mit weniger Dokumenten abschnitten. Die Genauigkeit verbesserte sich um bis zu 10 % (gemessen am F1-Score), wenn das System sich auf nur wenige Schlüsseldokumente konzentrierte, anstatt auf eine breite Sammlung. Dieser Trend zeigte sich bei verschiedenen Open-Source-Sprachmodellen, wie Metas Llama, mit der bemerkenswerten Ausnahme von Qwen-2, das seine Leistung auch bei mehreren Dokumenten beibehielt.
 Quelle: Levy et al.
Quelle: Levy et al.
Dieses überraschende Ergebnis stellt die gängige Annahme infrage, dass mehr Informationen immer helfen. Selbst bei gleicher Textmenge schien die Vielzahl an Dokumenten die Aufgabe der KI zu erschweren, indem sie mehr Rauschen als Signal einführte.
Warum weniger in RAG mehr sein kann
Das Prinzip „weniger ist mehr“ ergibt Sinn, wenn man bedenkt, wie KI-Modelle Informationen verarbeiten. Mit weniger, aber relevanteren Dokumenten kann sich die KI auf den wesentlichen Kontext konzentrieren, ohne abgelenkt zu werden, ähnlich wie ein Schüler, der das relevanteste Material studiert.
In der Studie schnitten Modelle besser ab, wenn ihnen nur die direkt relevanten Dokumente gegeben wurden, da dieser klarere, fokussierte Kontext das Extrahieren der korrekten Informationen erleichterte. Umgekehrt hatte die KI bei vielen Dokumenten oft Schwierigkeiten mit der Mischung aus relevantem und irrelevantem Inhalt. Ähnliche, aber nicht verwandte Dokumente konnten das Modell in die Irre führen und das Risiko von Halluzinationen erhöhen.
Interessanterweise stellte die Studie fest, dass die KI offensichtlich irrelevante Dokumente leichter ignorieren konnte als solche, die nur geringfügig vom Thema abwichen. Dies deutet darauf hin, dass realistische Ablenkungen verwirrender sind als zufällige. Durch die Begrenzung auf nur die notwendigen Dokumente wird die Wahrscheinlichkeit solcher Fallen reduziert.
Zusätzlich senkt die Verwendung weniger Dokumente den Rechenaufwand, was das System effizienter und kostengünstiger macht. Dieser Ansatz verbessert nicht nur die Genauigkeit, sondern steigert auch die Gesamtleistung des RAG-Systems.
 Quelle: Levy et al.
Quelle: Levy et al.
RAG neu denken: Zukünftige Richtungen
Diese Erkenntnisse haben bedeutende Auswirkungen auf die Gestaltung zukünftiger KI-Systeme, die auf externem Wissen basieren. Sie deuten darauf hin, dass die Fokussierung auf die Qualität und Relevanz der abgerufenen Dokumente, anstatt auf deren Menge, die Leistung verbessern könnte. Die Autoren der Studie plädieren für Abrufmethoden, die Relevanz und Vielfalt ausbalancieren, um eine umfassende Abdeckung zu gewährleisten, ohne das Modell mit überflüssigem Text zu überfordern.
Zukünftige Forschung könnte bessere Abrufsysteme oder Re-Ranker untersuchen, um wirklich wertvolle Dokumente zu identifizieren und die Verarbeitung mehrerer Quellen durch Sprachmodelle zu verbessern. Die Verbesserung der Modelle selbst, wie bei Qwen-2 zu sehen, könnte auch Einblicke liefern, wie sie robuster gegenüber vielfältigen Eingaben gemacht werden können.
Da KI-Systeme größere Kontextfenster entwickeln, wird die Fähigkeit, mehr Text auf einmal zu verarbeiten, weniger wichtig als die Sicherstellung, dass der Text relevant und kuratiert ist. Die Studie mit dem Titel „Mehr Dokumente, gleiche Länge“ unterstreicht die Bedeutung, sich auf die relevantesten Informationen zu konzentrieren, um die Genauigkeit und Effizienz der KI zu verbessern.
Zusammenfassend stellt diese Forschung unsere Annahmen über die Dateneingabe in KI-Systeme infrage. Durch sorgfältige Auswahl weniger, besserer Dokumente können wir intelligentere, schlankere RAG-Systeme schaffen, die genauere und vertrauenswürdigere Antworten liefern.
Verwandter Artikel
 China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen
Glean nimmt die KI-Infrastruktur von Unternehmen ins Visier
Der Wettlauf um die Vorherrschaft im Bereich der Unternehmens-KI gewinnt an Fahrt. Microsoft integriert Copilot in Office, Google bindet Gemini in Workspace ein, und sowohl OpenAI als auch Anthropic v
Empfehlungen zu verwandten Spezialthemen
Schreiben
China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen
Glean nimmt die KI-Infrastruktur von Unternehmen ins Visier
Der Wettlauf um die Vorherrschaft im Bereich der Unternehmens-KI gewinnt an Fahrt. Microsoft integriert Copilot in Office, Google bindet Gemini in Workspace ein, und sowohl OpenAI als auch Anthropic v
Empfehlungen zu verwandten Spezialthemen
Schreiben
 Die besten KI-Assistenten für Xianxia und Wuxia: Verfassen Sie epische Kultivierungsgeschichten und Kampfkunst-Choreografien
Die besten KI-Assistenten für Xianxia und Wuxia: Verfassen Sie epische Kultivierungsgeschichten und Kampfkunst-Choreografien
Entdecken Sie die besten KI-Assistenten des Jahres 2026 für das Verfassen epischer Xianxia- und Wuxia-Geschichten. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie den Fortschritt der Kultivierung und die Choreografie von Kampfkünsten meistern können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit dem Schreiben!
 10 Tools
10 Tools
 xix.ai
Code
AI-Mobilanwendungsentwicklungstools: Erstellen Sie plattformübergreifenden Flutter- und React Native-Code auf Basis von Eingaben.
xix.ai
Code
AI-Mobilanwendungsentwicklungstools: Erstellen Sie plattformübergreifenden Flutter- und React Native-Code auf Basis von Eingaben.
Entdecken Sie die besten AI-Programmierwerkzeuge für mobile Anwendungen im Jahr 2026 – geeignet für Flutter und React Native. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, die es ermöglichen, plattformübergreifenden Code auf Basis von Vorgaben zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests – beschleunigen Sie Ihre Entwicklung und erstellen Sie bessere Anwendungen. Erfahren Sie mehr über die Rangliste auf XIX.AI!
10 Tools
xix.ai
Code
Die besten KI-Generatoren für Chrome-Erweiterungen: Erstellen Sie individuelle Browser-Erweiterungen ganz ohne Programmierkenntnisse
Entdecken Sie die besten KI-Generatoren für Chrome-Erweiterungen des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, unverzichtbare Tools, mit denen Sie ganz ohne Programmierkenntnisse individuelle Browser-Erweiterungen erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen, sehen Sie sich Praxistests an und steigern Sie Ihre Produktivität. Entdecken Sie die aktuellen Rankings und finden Sie noch heute das perfekte Tool für sich!
10 Tools
xix.ai
Text-zu-Sprache
Die beste künstliche Intelligenz für mehrsprachige TTS-Technologie: Erzeugung authentischer Sprache mit Muttersprachakzent in über 50 Sprachen
Entdecken Sie die besten KI-basierten, mehrsprachigen TTS-Tools von 2026 – sie ermöglichen eine authentische Aussprache in natürlicher Muttersprachentonart in über 50 Sprachen. Erfahren Sie mehr über unsere hochrangig bewerteten und sorgfältig ausgewählten Tools, inklusive Vergleichen zwischen kostenlosen und kostenpflichtigen Varianten sowie Ergebnissen aus realen Tests. Finden Sie das perfekte Tool für Ihre Bedürfnisse auf XIX.AI und öffnen Sie so neue Möglichkeiten für die globale Kommunikation – noch heute!
10 Tools
xix.ai
Besprechungsassistent
Die besten AI-Tools für die Automatisierung von Besprechungen – für eine schlauere und schnellere Zusammenarbeit
Entdecken Sie die besten und am meisten bewerteten AI-Tools für die Automatisierung von Besprechungen im Jahr 2026 – sie ermöglichen eine intelligente und schnellere Zusammenarbeit. Unsere sorgfältig ausgewählte Liste bietet leistungsstarke Lösungen, mit denen Sie Notizen, Zusammenfassungen und Aufgaben automatisch erstellen können. Vergleichen Sie kostenlose und bezahlte Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings – so steigern Sie die Produktivität Ihres Teams. Entdecken Sie die besten Tools jetzt bei XIX.AI.
10 Tools
xix.ai
Prompt
KI-Vorgaben für Infrastructure-as-Code: Terraform- und Docker-Konfigurationen sicher bereitstellen
Entdecken Sie die aktuellsten und am besten bewerteten KI-Prompts für Infrastructure-as-Code aus dem Jahr 2026. Die von XIX.AI zusammengestellte Auswahl hilft Ihnen dabei, Terraform- und Docker-Konfigurationen sicher bereitzustellen, Cloud-Setups zu automatisieren und die DevOps-Produktivität zu steigern. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entdecken Sie die Möglichkeiten jetzt und sichern Sie sich Ihren KI-Vorteil.
10 Tools
xix.ai

 Kommentare (51)
Kommentare (51)
![LarryMartin]()
이런 연구 결과는 RAG 시스템을 최적화하는 데 정말 중요한 인사이트를 주는 것 같아요. 가끔 검색된 문서가 너무 많으면 AI가 오히려 핵심 내용을 놓치고 산만해지는 걸 본 적 있는데, '적게 가져올수록 더 좋다'는 아이디어가 실제 적용에서 얼마나 효과적일지 궁금해지네요. 프로젝트에 한 번 적용해 봐야겠어요! 👍
![BillyEvans]()
Interesante enfoque. A veces menos es más, y en la IA parece no ser diferente. Me pregunto si esa reducción de documentos también podría acelerar las respuestas o si hay algún riesgo de perder contexto clave. 🤔
![BruceClark]()
これ、AIが情報を少なく検索した方が精度が上がるって話?逆説的で面白いな。むしろ情報が多いとAIが混乱しちゃうんだ。人間も情報多すぎると迷うし、AIも同じなのかも。ちょっとリラックスしたなこれ。🤔
![FrankSmith]()
이거 꽤 흥미롭네요. 문서를 적게 검색할수록 AI 답변이 더 좋아진다고? 🤔 우리 팀 RAG 시스템에 적용해볼까... 그런데 이러면 검색 정밀도가 더 중요해지겠는데, 실제로 구현하기 꽤 까다롭지 않을까?
![LarryWilliams]()
La RAG est révolutionnaire, mais je me demande si limiter les documents récupérés pourrait parfois manquer des infos cruciales 🤔. Perso, j'opterais pour un juste milieu entre précision et exhaustivité !
![BruceBrown]()
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?
Retrieval-Augmented Generation (RAG) ist ein innovativer Ansatz zum Aufbau von KI-Systemen, der ein Sprachmodell mit einer externen Wissensquelle kombiniert, um die Genauigkeit zu erhöhen und faktenbasierte Fehler zu reduzieren. Im Wesentlichen sucht die KI nach relevanten Dokumenten, die mit der Anfrage eines Nutzers in Verbindung stehen, und verwendet diese Informationen, um eine präzisere Antwort zu generieren. Diese Methode hat Anerkennung für ihre Fähigkeit gefunden, große Sprachmodelle (LLMs) an realen Daten zu orientieren und das Risiko von Halluzinationen zu minimieren.
Man könnte annehmen, dass die Bereitstellung von mehr Dokumenten einer KI zu besser informierten Antworten führen würde. Eine aktuelle Studie der Hebräischen Universität Jerusalem legt jedoch nahe, dass weniger tatsächlich mehr sein kann, wenn es darum geht, Informationen an eine KI zu liefern.
Weniger Dokumente, bessere Antworten
Die Studie untersuchte, wie die Anzahl der einem RAG-System bereitgestellten Dokumente dessen Leistung beeinflusst. Die Forscher hielten die gesamte Textlänge konstant, variierten die Anzahl der Dokumente von 20 auf 2-4 relevante und erweiterten diese, um das ursprüngliche Textvolumen zu erreichen. Dies ermöglichte es ihnen, den Einfluss der Dokumentenmenge auf die Leistung zu isolieren.
Mit dem MuSiQue-Datensatz, der Trivia-Fragen mit Wikipedia-Absätzen kombiniert, stellten sie fest, dass KI-Modelle oft besser mit weniger Dokumenten abschnitten. Die Genauigkeit verbesserte sich um bis zu 10 % (gemessen am F1-Score), wenn das System sich auf nur wenige Schlüsseldokumente konzentrierte, anstatt auf eine breite Sammlung. Dieser Trend zeigte sich bei verschiedenen Open-Source-Sprachmodellen, wie Metas Llama, mit der bemerkenswerten Ausnahme von Qwen-2, das seine Leistung auch bei mehreren Dokumenten beibehielt.
Quelle: Levy et al.
Dieses überraschende Ergebnis stellt die gängige Annahme infrage, dass mehr Informationen immer helfen. Selbst bei gleicher Textmenge schien die Vielzahl an Dokumenten die Aufgabe der KI zu erschweren, indem sie mehr Rauschen als Signal einführte.
Warum weniger in RAG mehr sein kann
Das Prinzip „weniger ist mehr“ ergibt Sinn, wenn man bedenkt, wie KI-Modelle Informationen verarbeiten. Mit weniger, aber relevanteren Dokumenten kann sich die KI auf den wesentlichen Kontext konzentrieren, ohne abgelenkt zu werden, ähnlich wie ein Schüler, der das relevanteste Material studiert.
In der Studie schnitten Modelle besser ab, wenn ihnen nur die direkt relevanten Dokumente gegeben wurden, da dieser klarere, fokussierte Kontext das Extrahieren der korrekten Informationen erleichterte. Umgekehrt hatte die KI bei vielen Dokumenten oft Schwierigkeiten mit der Mischung aus relevantem und irrelevantem Inhalt. Ähnliche, aber nicht verwandte Dokumente konnten das Modell in die Irre führen und das Risiko von Halluzinationen erhöhen.
Interessanterweise stellte die Studie fest, dass die KI offensichtlich irrelevante Dokumente leichter ignorieren konnte als solche, die nur geringfügig vom Thema abwichen. Dies deutet darauf hin, dass realistische Ablenkungen verwirrender sind als zufällige. Durch die Begrenzung auf nur die notwendigen Dokumente wird die Wahrscheinlichkeit solcher Fallen reduziert.
Zusätzlich senkt die Verwendung weniger Dokumente den Rechenaufwand, was das System effizienter und kostengünstiger macht. Dieser Ansatz verbessert nicht nur die Genauigkeit, sondern steigert auch die Gesamtleistung des RAG-Systems.
Quelle: Levy et al.
RAG neu denken: Zukünftige Richtungen
Diese Erkenntnisse haben bedeutende Auswirkungen auf die Gestaltung zukünftiger KI-Systeme, die auf externem Wissen basieren. Sie deuten darauf hin, dass die Fokussierung auf die Qualität und Relevanz der abgerufenen Dokumente, anstatt auf deren Menge, die Leistung verbessern könnte. Die Autoren der Studie plädieren für Abrufmethoden, die Relevanz und Vielfalt ausbalancieren, um eine umfassende Abdeckung zu gewährleisten, ohne das Modell mit überflüssigem Text zu überfordern.
Zukünftige Forschung könnte bessere Abrufsysteme oder Re-Ranker untersuchen, um wirklich wertvolle Dokumente zu identifizieren und die Verarbeitung mehrerer Quellen durch Sprachmodelle zu verbessern. Die Verbesserung der Modelle selbst, wie bei Qwen-2 zu sehen, könnte auch Einblicke liefern, wie sie robuster gegenüber vielfältigen Eingaben gemacht werden können.
Da KI-Systeme größere Kontextfenster entwickeln, wird die Fähigkeit, mehr Text auf einmal zu verarbeiten, weniger wichtig als die Sicherstellung, dass der Text relevant und kuratiert ist. Die Studie mit dem Titel „Mehr Dokumente, gleiche Länge“ unterstreicht die Bedeutung, sich auf die relevantesten Informationen zu konzentrieren, um die Genauigkeit und Effizienz der KI zu verbessern.
Zusammenfassend stellt diese Forschung unsere Annahmen über die Dateneingabe in KI-Systeme infrage. Durch sorgfältige Auswahl weniger, besserer Dokumente können wir intelligentere, schlankere RAG-Systeme schaffen, die genauere und vertrauenswürdigere Antworten liefern.










 China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
China Telecom investiert in Mianbi Intelligence und erhöht das Kapital für LLM und Dateninfrastruktur auf 713.000 Yuan
Das „Nationalteam“ und die führende Persönlichkeit der Tsinghua-Universität im Bereich der großen Modelle vertiefen ihre strategische Zusammenarbeit. Am 1. März 2026 unterzog sich die Beijing Mianbi I
 Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen
Die Taotian Group treibt ihre KI-orientierte Umstrukturierung voran und gewährt Praktikanten kostenlose Token-Kontingente
Die TaoTian Group hat kürzlich den „AI Productivity Plan“ eingeführt, der darauf abzielt, die Integration von KI-Technologie in E-Commerce-Abläufe und F&E-Workflows durch die Zuweisung von Ressourcen
 Glean nimmt die KI-Infrastruktur von Unternehmen ins Visier
Der Wettlauf um die Vorherrschaft im Bereich der Unternehmens-KI gewinnt an Fahrt. Microsoft integriert Copilot in Office, Google bindet Gemini in Workspace ein, und sowohl OpenAI als auch Anthropic v
Glean nimmt die KI-Infrastruktur von Unternehmen ins Visier
Der Wettlauf um die Vorherrschaft im Bereich der Unternehmens-KI gewinnt an Fahrt. Microsoft integriert Copilot in Office, Google bindet Gemini in Workspace ein, und sowohl OpenAI als auch Anthropic v

Entdecken Sie die besten KI-Assistenten des Jahres 2026 für das Verfassen epischer Xianxia- und Wuxia-Geschichten. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie den Fortschritt der Kultivierung und die Choreografie von Kampfkünsten meistern können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit dem Schreiben!
10 Tools
xix.ai

Entdecken Sie die besten AI-Programmierwerkzeuge für mobile Anwendungen im Jahr 2026 – geeignet für Flutter und React Native. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, die es ermöglichen, plattformübergreifenden Code auf Basis von Vorgaben zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests – beschleunigen Sie Ihre Entwicklung und erstellen Sie bessere Anwendungen. Erfahren Sie mehr über die Rangliste auf XIX.AI!
10 Tools
xix.ai

Entdecken Sie die besten KI-Generatoren für Chrome-Erweiterungen des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, unverzichtbare Tools, mit denen Sie ganz ohne Programmierkenntnisse individuelle Browser-Erweiterungen erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen, sehen Sie sich Praxistests an und steigern Sie Ihre Produktivität. Entdecken Sie die aktuellen Rankings und finden Sie noch heute das perfekte Tool für sich!
10 Tools
xix.ai

Entdecken Sie die besten KI-basierten, mehrsprachigen TTS-Tools von 2026 – sie ermöglichen eine authentische Aussprache in natürlicher Muttersprachentonart in über 50 Sprachen. Erfahren Sie mehr über unsere hochrangig bewerteten und sorgfältig ausgewählten Tools, inklusive Vergleichen zwischen kostenlosen und kostenpflichtigen Varianten sowie Ergebnissen aus realen Tests. Finden Sie das perfekte Tool für Ihre Bedürfnisse auf XIX.AI und öffnen Sie so neue Möglichkeiten für die globale Kommunikation – noch heute!
10 Tools
xix.ai

Entdecken Sie die besten und am meisten bewerteten AI-Tools für die Automatisierung von Besprechungen im Jahr 2026 – sie ermöglichen eine intelligente und schnellere Zusammenarbeit. Unsere sorgfältig ausgewählte Liste bietet leistungsstarke Lösungen, mit denen Sie Notizen, Zusammenfassungen und Aufgaben automatisch erstellen können. Vergleichen Sie kostenlose und bezahlte Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings – so steigern Sie die Produktivität Ihres Teams. Entdecken Sie die besten Tools jetzt bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie die aktuellsten und am besten bewerteten KI-Prompts für Infrastructure-as-Code aus dem Jahr 2026. Die von XIX.AI zusammengestellte Auswahl hilft Ihnen dabei, Terraform- und Docker-Konfigurationen sicher bereitzustellen, Cloud-Setups zu automatisieren und die DevOps-Produktivität zu steigern. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entdecken Sie die Möglichkeiten jetzt und sichern Sie sich Ihren KI-Vorteil.
10 Tools
xix.ai

이런 연구 결과는 RAG 시스템을 최적화하는 데 정말 중요한 인사이트를 주는 것 같아요. 가끔 검색된 문서가 너무 많으면 AI가 오히려 핵심 내용을 놓치고 산만해지는 걸 본 적 있는데, '적게 가져올수록 더 좋다'는 아이디어가 실제 적용에서 얼마나 효과적일지 궁금해지네요. 프로젝트에 한 번 적용해 봐야겠어요! 👍
Interesante enfoque. A veces menos es más, y en la IA parece no ser diferente. Me pregunto si esa reducción de documentos también podría acelerar las respuestas o si hay algún riesgo de perder contexto clave. 🤔
これ、AIが情報を少なく検索した方が精度が上がるって話?逆説的で面白いな。むしろ情報が多いとAIが混乱しちゃうんだ。人間も情報多すぎると迷うし、AIも同じなのかも。ちょっとリラックスしたなこれ。🤔
이거 꽤 흥미롭네요. 문서를 적게 검색할수록 AI 답변이 더 좋아진다고? 🤔 우리 팀 RAG 시스템에 적용해볼까... 그런데 이러면 검색 정밀도가 더 중요해지겠는데, 실제로 구현하기 꽤 까다롭지 않을까?
La RAG est révolutionnaire, mais je me demande si limiter les documents récupérés pourrait parfois manquer des infos cruciales 🤔. Perso, j'opterais pour un juste milieu entre précision et exhaustivité !
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?













