




Less Is More: How Retrieving Fewer Documents Enhances AI Responses
Retrieval-Augmented Generation (RAG) is an innovative approach to building AI systems, combining a language model with an external knowledge source to enhance accuracy and reduce factual errors. In essence, the AI searches for relevant documents related to a user's query and uses this information to generate a more precise response. This method has gained recognition for its ability to keep large language models (LLMs) grounded in real data, minimizing the risk of hallucinations.
You might assume that providing an AI with more documents would lead to better-informed answers. However, a recent study from the Hebrew University of Jerusalem suggests otherwise: when it comes to feeding information to an AI, less can indeed be more.
Fewer Documents, Better Answers
The study delved into how the number of documents provided to a RAG system impacts its performance. The researchers maintained a consistent total text length, adjusting the document count from 20 down to 2-4 relevant ones and expanding these to match the original text volume. This allowed them to isolate the effect of document quantity on performance.
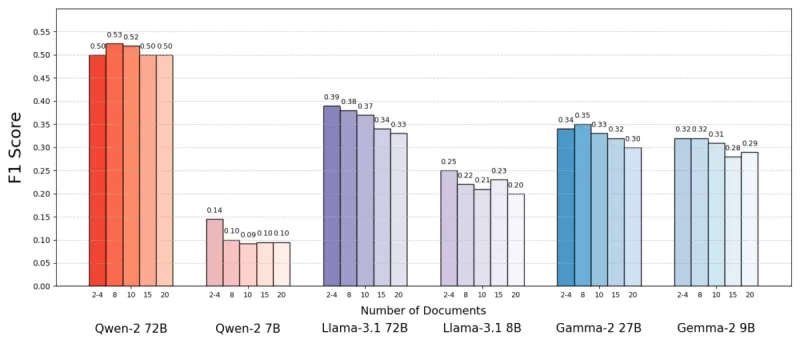
Using the MuSiQue dataset, which includes trivia questions paired with Wikipedia paragraphs, they found that AI models often performed better with fewer documents. Accuracy improved by up to 10% (measured by F1 score) when the system focused on just a few key documents rather than a broad collection. This trend held across various open-source language models, such as Meta's Llama, with Qwen-2 being the notable exception, maintaining its performance with multiple documents.
 Source: Levy et al.
Source: Levy et al.
This surprising result challenges the common belief that more information always helps. Even with the same amount of text, the presence of multiple documents seemed to complicate the AI's task, introducing more noise than signal.
Why Less Can Be More in RAG
The "less is more" principle makes sense when we consider how AI models process information. With fewer, more relevant documents, the AI can focus on the essential context without distractions, much like a student studying the most pertinent material.
In the study, models performed better when given only the documents directly relevant to the answer, as this cleaner, focused context made it easier to extract the correct information. Conversely, when the AI had to sift through many documents, it often struggled with the mix of relevant and irrelevant content. Similar but unrelated documents could mislead the model, increasing the risk of hallucinations.
Interestingly, the study found that the AI could more easily ignore obviously irrelevant documents than those subtly off-topic. This suggests that realistic distractors are more confusing than random ones. By limiting documents to only the necessary ones, we reduce the likelihood of setting such traps.
Additionally, using fewer documents lowers the computational overhead, making the system more efficient and cost-effective. This approach not only improves accuracy but also enhances the overall performance of the RAG system.
 Source: Levy et al.
Source: Levy et al.
Rethinking RAG: Future Directions
These findings have significant implications for the design of future AI systems that rely on external knowledge. It suggests that focusing on the quality and relevance of retrieved documents, rather than their quantity, could enhance performance. The study's authors advocate for retrieval methods that balance relevance and diversity, ensuring comprehensive coverage without overwhelming the model with extraneous text.
Future research may explore better retriever systems or re-rankers to identify truly valuable documents and improve how language models handle multiple sources. Enhancing the models themselves, as seen with Qwen-2, could also provide insights into making them more robust to diverse inputs.
As AI systems develop larger context windows, the ability to process more text at once becomes less critical than ensuring the text is relevant and curated. The study, titled "More Documents, Same Length," underscores the importance of focusing on the most pertinent information to improve AI accuracy and efficiency.
In conclusion, this research challenges our assumptions about data input in AI systems. By carefully selecting fewer, better documents, we can create smarter, leaner RAG systems that deliver more accurate and trustworthy answers.
Related article
 Manus Debuts 'Wide Research' AI Tool with 100+ Agents for Web Scraping
Chinese AI innovator Manus, which previously gained attention for its pioneering multi-agent orchestration platform catering to both consumers and professional users, has unveiled a groundbreaking application of its technology that challenges convent
Why LLMs Ignore Instructions & How to Fix It Effectively
Understanding Why Large Language Models Skip Instructions
Large Language Models (LLMs) have transformed how we interact with AI, enabling advanced applications ranging from conversational interfaces to automated content generation and programming ass
Pebble Reclaims Its Original Brand Name After Legal Battle
The Return of Pebble: Name and AllPebble enthusiasts can rejoice - the beloved smartwatch brand isn't just making a comeback, it's reclaiming its iconic name. "We've successfully regained the Pebble trademark, which honestly surprised me with how smo
Comments (47)
0/200
Manus Debuts 'Wide Research' AI Tool with 100+ Agents for Web Scraping
Chinese AI innovator Manus, which previously gained attention for its pioneering multi-agent orchestration platform catering to both consumers and professional users, has unveiled a groundbreaking application of its technology that challenges convent
Why LLMs Ignore Instructions & How to Fix It Effectively
Understanding Why Large Language Models Skip Instructions
Large Language Models (LLMs) have transformed how we interact with AI, enabling advanced applications ranging from conversational interfaces to automated content generation and programming ass
Pebble Reclaims Its Original Brand Name After Legal Battle
The Return of Pebble: Name and AllPebble enthusiasts can rejoice - the beloved smartwatch brand isn't just making a comeback, it's reclaiming its iconic name. "We've successfully regained the Pebble trademark, which honestly surprised me with how smo
Comments (47)
0/200
![LarryWilliams]() LarryWilliams
LarryWilliams
 September 9, 2025 at 8:30:32 PM EDT
September 9, 2025 at 8:30:32 PM EDT
La RAG est révolutionnaire, mais je me demande si limiter les documents récupérés pourrait parfois manquer des infos cruciales 🤔. Perso, j'opterais pour un juste milieu entre précision et exhaustivité !


 0
0
![BruceBrown]() BruceBrown
July 29, 2025 at 8:25:16 AM EDT
BruceBrown
July 29, 2025 at 8:25:16 AM EDT
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?
0
![JasonMartin]() JasonMartin
April 26, 2025 at 2:04:32 AM EDT
JasonMartin
April 26, 2025 at 2:04:32 AM EDT
Adoro como essa ferramenta torna as respostas do AI mais precisas usando menos documentos. É como mágica! Mas às vezes parece que está faltando alguma informação. Ainda assim, uma ótima ferramenta para respostas rápidas e confiáveis. 👍
0
![JuanMoore]() JuanMoore
April 23, 2025 at 6:29:07 PM EDT
JuanMoore
April 23, 2025 at 6:29:07 PM EDT
I love how this tool makes AI responses more accurate by using fewer documents. It's like magic! But sometimes it feels like it's missing out on some info. Still, a great tool for quick, reliable answers. 👍
0
![GregoryJones]() GregoryJones
April 22, 2025 at 12:50:26 PM EDT
GregoryJones
April 22, 2025 at 12:50:26 PM EDT
「少ない方が良い」というAIの応答方法はかなりクール!少ないドキュメントから正確な答えを得るなんて、登録したいですね!魔法のようですが、もっと早く動いてほしいです。でも、AI技術の前進の一歩としては素晴らしいですね!🚀
0
![BrianMartinez]() BrianMartinez
April 21, 2025 at 7:14:10 AM EDT
BrianMartinez
April 21, 2025 at 7:14:10 AM EDT
This app really simplifies things! By retrieving fewer but more relevant documents, the AI responses are much more accurate and to the point. It's like having a smart assistant that knows exactly what you need. Only wish it was a bit faster. Still, a great tool! 😊
0
Retrieval-Augmented Generation (RAG) is an innovative approach to building AI systems, combining a language model with an external knowledge source to enhance accuracy and reduce factual errors. In essence, the AI searches for relevant documents related to a user's query and uses this information to generate a more precise response. This method has gained recognition for its ability to keep large language models (LLMs) grounded in real data, minimizing the risk of hallucinations.
You might assume that providing an AI with more documents would lead to better-informed answers. However, a recent study from the Hebrew University of Jerusalem suggests otherwise: when it comes to feeding information to an AI, less can indeed be more.
Fewer Documents, Better Answers
The study delved into how the number of documents provided to a RAG system impacts its performance. The researchers maintained a consistent total text length, adjusting the document count from 20 down to 2-4 relevant ones and expanding these to match the original text volume. This allowed them to isolate the effect of document quantity on performance.
Using the MuSiQue dataset, which includes trivia questions paired with Wikipedia paragraphs, they found that AI models often performed better with fewer documents. Accuracy improved by up to 10% (measured by F1 score) when the system focused on just a few key documents rather than a broad collection. This trend held across various open-source language models, such as Meta's Llama, with Qwen-2 being the notable exception, maintaining its performance with multiple documents.
Source: Levy et al.
This surprising result challenges the common belief that more information always helps. Even with the same amount of text, the presence of multiple documents seemed to complicate the AI's task, introducing more noise than signal.
Why Less Can Be More in RAG
The "less is more" principle makes sense when we consider how AI models process information. With fewer, more relevant documents, the AI can focus on the essential context without distractions, much like a student studying the most pertinent material.
In the study, models performed better when given only the documents directly relevant to the answer, as this cleaner, focused context made it easier to extract the correct information. Conversely, when the AI had to sift through many documents, it often struggled with the mix of relevant and irrelevant content. Similar but unrelated documents could mislead the model, increasing the risk of hallucinations.
Interestingly, the study found that the AI could more easily ignore obviously irrelevant documents than those subtly off-topic. This suggests that realistic distractors are more confusing than random ones. By limiting documents to only the necessary ones, we reduce the likelihood of setting such traps.
Additionally, using fewer documents lowers the computational overhead, making the system more efficient and cost-effective. This approach not only improves accuracy but also enhances the overall performance of the RAG system.
Source: Levy et al.
Rethinking RAG: Future Directions
These findings have significant implications for the design of future AI systems that rely on external knowledge. It suggests that focusing on the quality and relevance of retrieved documents, rather than their quantity, could enhance performance. The study's authors advocate for retrieval methods that balance relevance and diversity, ensuring comprehensive coverage without overwhelming the model with extraneous text.
Future research may explore better retriever systems or re-rankers to identify truly valuable documents and improve how language models handle multiple sources. Enhancing the models themselves, as seen with Qwen-2, could also provide insights into making them more robust to diverse inputs.
As AI systems develop larger context windows, the ability to process more text at once becomes less critical than ensuring the text is relevant and curated. The study, titled "More Documents, Same Length," underscores the importance of focusing on the most pertinent information to improve AI accuracy and efficiency.
In conclusion, this research challenges our assumptions about data input in AI systems. By carefully selecting fewer, better documents, we can create smarter, leaner RAG systems that deliver more accurate and trustworthy answers.










 Manus Debuts 'Wide Research' AI Tool with 100+ Agents for Web Scraping
Chinese AI innovator Manus, which previously gained attention for its pioneering multi-agent orchestration platform catering to both consumers and professional users, has unveiled a groundbreaking application of its technology that challenges convent
Manus Debuts 'Wide Research' AI Tool with 100+ Agents for Web Scraping
Chinese AI innovator Manus, which previously gained attention for its pioneering multi-agent orchestration platform catering to both consumers and professional users, has unveiled a groundbreaking application of its technology that challenges convent
 Why LLMs Ignore Instructions & How to Fix It Effectively
Understanding Why Large Language Models Skip Instructions
Large Language Models (LLMs) have transformed how we interact with AI, enabling advanced applications ranging from conversational interfaces to automated content generation and programming ass
Why LLMs Ignore Instructions & How to Fix It Effectively
Understanding Why Large Language Models Skip Instructions
Large Language Models (LLMs) have transformed how we interact with AI, enabling advanced applications ranging from conversational interfaces to automated content generation and programming ass
 Pebble Reclaims Its Original Brand Name After Legal Battle
The Return of Pebble: Name and AllPebble enthusiasts can rejoice - the beloved smartwatch brand isn't just making a comeback, it's reclaiming its iconic name. "We've successfully regained the Pebble trademark, which honestly surprised me with how smo
September 9, 2025 at 8:30:32 PM EDT
Pebble Reclaims Its Original Brand Name After Legal Battle
The Return of Pebble: Name and AllPebble enthusiasts can rejoice - the beloved smartwatch brand isn't just making a comeback, it's reclaiming its iconic name. "We've successfully regained the Pebble trademark, which honestly surprised me with how smo
September 9, 2025 at 8:30:32 PM EDT
La RAG est révolutionnaire, mais je me demande si limiter les documents récupérés pourrait parfois manquer des infos cruciales 🤔. Perso, j'opterais pour un juste milieu entre précision et exhaustivité !
0
July 29, 2025 at 8:25:16 AM EDT
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?
0
April 26, 2025 at 2:04:32 AM EDT
Adoro como essa ferramenta torna as respostas do AI mais precisas usando menos documentos. É como mágica! Mas às vezes parece que está faltando alguma informação. Ainda assim, uma ótima ferramenta para respostas rápidas e confiáveis. 👍
0
April 23, 2025 at 6:29:07 PM EDT
I love how this tool makes AI responses more accurate by using fewer documents. It's like magic! But sometimes it feels like it's missing out on some info. Still, a great tool for quick, reliable answers. 👍
0
April 22, 2025 at 12:50:26 PM EDT
「少ない方が良い」というAIの応答方法はかなりクール!少ないドキュメントから正確な答えを得るなんて、登録したいですね!魔法のようですが、もっと早く動いてほしいです。でも、AI技術の前進の一歩としては素晴らしいですね!🚀
0
April 21, 2025 at 7:14:10 AM EDT
This app really simplifies things! By retrieving fewer but more relevant documents, the AI responses are much more accurate and to the point. It's like having a smart assistant that knows exactly what you need. Only wish it was a bit faster. Still, a great tool! 😊
0













