




«Меньше больше: как получение меньшего количества документов усиливает ответы ИИ»
Генерация с дополненным извлечением (RAG) — это инновационный подход к созданию систем ИИ, сочетающий языковую модель с внешним источником знаний для повышения точности и уменьшения фактических ошибок. По сути, ИИ ищет релевантные документы, связанные с запросом пользователя, и использует эту информацию для формирования более точного ответа. Этот метод получил признание благодаря своей способности удерживать большие языковые модели (LLMs) в рамках реальных данных, минимизируя риск галлюцинаций.
Можно предположить, что предоставление ИИ большего количества документов приведет к более информированным ответам. Однако недавнее исследование Еврейского университета в Иерусалиме показывает обратное: когда речь идет о предоставлении информации ИИ, меньше действительно может быть лучше.
Меньше документов, лучше ответы
Исследование изучило, как количество документов, предоставленных системе RAG, влияет на ее производительность. Исследователи сохраняли постоянную общую длину текста, варьируя количество документов от 20 до 2–4 релевантных и расширяя их, чтобы соответствовать исходному объему текста. Это позволило изолировать влияние количества документов на производительность.
Используя набор данных MuSiQue, который включает вопросы по тривии в сочетании с параграфами из Википедии, они обнаружили, что модели ИИ часто работали лучше с меньшим количеством документов. Точность улучшалась до 10% (по метрике F1) при использовании лишь нескольких ключевых документов вместо широкого набора. Эта тенденция сохранялась для различных языковых моделей с открытым исходным кодом, таких как Llama от Meta, за исключением Qwen-2, которая сохраняла свою производительность при использовании нескольких документов.
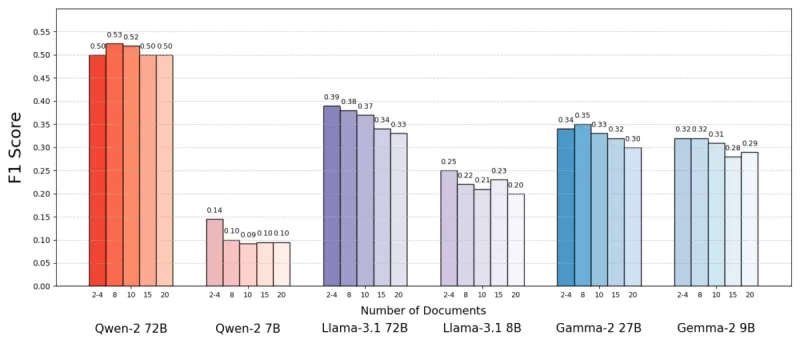 Источник: Леви и др.
Источник: Леви и др.
Этот неожиданный результат опровергает распространенное мнение, что больше информации всегда лучше. Даже при одинаковом объеме текста наличие множества документов, похоже, усложняло задачу ИИ, внося больше шума, чем сигнала.
Почему меньше может быть лучше в RAG
Принцип «меньше — значит больше» имеет смысл, если учесть, как модели ИИ обрабатывают информацию. С меньшим количеством более релевантных документов ИИ может сосредоточиться на основном контексте без отвлечений, подобно студенту, изучающему наиболее подходящий материал.
В исследовании модели работали лучше, когда получали только документы, непосредственно связанные с ответом, поскольку этот более чистый и сфокусированный контекст облегчал извлечение правильной информации. Напротив, когда ИИ приходилось просеивать множество документов, он часто испытывал трудности с сочетанием релевантного и нерелевантного контента. Похожие, но не связанные документы могли ввести модель в заблуждение, увеличивая риск галлюцинаций.
Интересно, что исследование показало, что ИИ легче игнорировал явно нерелевантные документы, чем те, которые были слегка не по теме. Это говорит о том, что реалистичные отвлекающие факторы более запутывают, чем случайные. Ограничивая количество документов только необходимыми, мы снижаем вероятность создания таких ловушек.
Кроме того, использование меньшего количества документов снижает вычислительные затраты, делая систему более эффективной и экономичной. Этот подход не только повышает точность, но и улучшает общую производительность системы RAG.
 Источник: Леви и др.
Источник: Леви и др.
Переосмысление RAG: будущие направления
Эти выводы имеют значительные последствия для проектирования будущих систем ИИ, зависящих от внешних знаний. Они предполагают, что сосредоточение на качестве и релевантности извлеченных документов, а не на их количестве, может повысить производительность. Авторы исследования выступают за методы извлечения, которые балансируют релевантность и разнообразие, обеспечивая всестороннее покрытие без перегрузки модели лишним текстом.
Будущие исследования могут быть направлены на разработку лучших систем извлечения или алгоритмов переранжирования для определения действительно ценных документов и улучшения того, как языковые модели обрабатывают множественные источники. Усовершенствование самих моделей, как видно на примере Qwen-2, также может дать понимание того, как сделать их более устойчивыми к разнообразным входным данным.
По мере того как системы ИИ развивают более широкие контекстные окна, способность обрабатывать больше текста одновременно становится менее критичной, чем обеспечение релевантности и курирования текста. Исследование под названием «Больше документов, та же длина» подчеркивает важность сосредоточения на наиболее подходящей информации для повышения точности и эффективности ИИ.
В заключение, это исследование бросает вызов нашим предположениям о вводе данных в системы ИИ. Тщательно выбирая меньше, но более качественных документов, мы можем создавать более умные и экономичные системы RAG, которые обеспечивают более точные и надежные ответы.
Связанная статья
 Правительство США инвестирует в Intel, чтобы увеличить производство полупроводников в стране
Администрация Трампа уделяет первостепенное внимание установлению лидерства США в области искусственного интеллекта, а краеугольным камнем стратегии является реорганизация производства полупроводников
Крейг Федериги из Apple признает, что у искусственного интеллекта Siri были серьезные недостатки на ранних стадиях
Руководители Apple объяснили задержку обновления SiriВо время WWDC 2024 Apple первоначально обещала значительные улучшения Siri, включая персонализированную контекстную осведомленность и возможности
Освойте техники AI Inpainting: Руководство по безупречному редактированию изображений
Откройте для себя преобразующие возможности технологии искусственного интеллекта Midjourney - революционной функции, позволяющей творцам с хирургической точностью дорабатывать и совершенствовать созда
Комментарии (47)
Правительство США инвестирует в Intel, чтобы увеличить производство полупроводников в стране
Администрация Трампа уделяет первостепенное внимание установлению лидерства США в области искусственного интеллекта, а краеугольным камнем стратегии является реорганизация производства полупроводников
Крейг Федериги из Apple признает, что у искусственного интеллекта Siri были серьезные недостатки на ранних стадиях
Руководители Apple объяснили задержку обновления SiriВо время WWDC 2024 Apple первоначально обещала значительные улучшения Siri, включая персонализированную контекстную осведомленность и возможности
Освойте техники AI Inpainting: Руководство по безупречному редактированию изображений
Откройте для себя преобразующие возможности технологии искусственного интеллекта Midjourney - революционной функции, позволяющей творцам с хирургической точностью дорабатывать и совершенствовать созда
Комментарии (47)
![LarryWilliams]() LarryWilliams
LarryWilliams
 10 сентября 2025 г., 3:30:32 GMT+03:00
10 сентября 2025 г., 3:30:32 GMT+03:00
La RAG est révolutionnaire, mais je me demande si limiter les documents récupérés pourrait parfois manquer des infos cruciales 🤔. Perso, j'opterais pour un juste milieu entre précision et exhaustivité !


 0
0
![BruceBrown]() BruceBrown
29 июля 2025 г., 15:25:16 GMT+03:00
BruceBrown
29 июля 2025 г., 15:25:16 GMT+03:00
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?
0
![JasonMartin]() JasonMartin
26 апреля 2025 г., 9:04:32 GMT+03:00
JasonMartin
26 апреля 2025 г., 9:04:32 GMT+03:00
Adoro como essa ferramenta torna as respostas do AI mais precisas usando menos documentos. É como mágica! Mas às vezes parece que está faltando alguma informação. Ainda assim, uma ótima ferramenta para respostas rápidas e confiáveis. 👍
0
![JuanMoore]() JuanMoore
24 апреля 2025 г., 1:29:07 GMT+03:00
JuanMoore
24 апреля 2025 г., 1:29:07 GMT+03:00
I love how this tool makes AI responses more accurate by using fewer documents. It's like magic! But sometimes it feels like it's missing out on some info. Still, a great tool for quick, reliable answers. 👍
0
![GregoryJones]() GregoryJones
22 апреля 2025 г., 19:50:26 GMT+03:00
GregoryJones
22 апреля 2025 г., 19:50:26 GMT+03:00
「少ない方が良い」というAIの応答方法はかなりクール!少ないドキュメントから正確な答えを得るなんて、登録したいですね!魔法のようですが、もっと早く動いてほしいです。でも、AI技術の前進の一歩としては素晴らしいですね!🚀
0
![BrianMartinez]() BrianMartinez
21 апреля 2025 г., 14:14:10 GMT+03:00
BrianMartinez
21 апреля 2025 г., 14:14:10 GMT+03:00
This app really simplifies things! By retrieving fewer but more relevant documents, the AI responses are much more accurate and to the point. It's like having a smart assistant that knows exactly what you need. Only wish it was a bit faster. Still, a great tool! 😊
0
Генерация с дополненным извлечением (RAG) — это инновационный подход к созданию систем ИИ, сочетающий языковую модель с внешним источником знаний для повышения точности и уменьшения фактических ошибок. По сути, ИИ ищет релевантные документы, связанные с запросом пользователя, и использует эту информацию для формирования более точного ответа. Этот метод получил признание благодаря своей способности удерживать большие языковые модели (LLMs) в рамках реальных данных, минимизируя риск галлюцинаций.
Можно предположить, что предоставление ИИ большего количества документов приведет к более информированным ответам. Однако недавнее исследование Еврейского университета в Иерусалиме показывает обратное: когда речь идет о предоставлении информации ИИ, меньше действительно может быть лучше.
Меньше документов, лучше ответы
Исследование изучило, как количество документов, предоставленных системе RAG, влияет на ее производительность. Исследователи сохраняли постоянную общую длину текста, варьируя количество документов от 20 до 2–4 релевантных и расширяя их, чтобы соответствовать исходному объему текста. Это позволило изолировать влияние количества документов на производительность.
Используя набор данных MuSiQue, который включает вопросы по тривии в сочетании с параграфами из Википедии, они обнаружили, что модели ИИ часто работали лучше с меньшим количеством документов. Точность улучшалась до 10% (по метрике F1) при использовании лишь нескольких ключевых документов вместо широкого набора. Эта тенденция сохранялась для различных языковых моделей с открытым исходным кодом, таких как Llama от Meta, за исключением Qwen-2, которая сохраняла свою производительность при использовании нескольких документов.
Источник: Леви и др.
Этот неожиданный результат опровергает распространенное мнение, что больше информации всегда лучше. Даже при одинаковом объеме текста наличие множества документов, похоже, усложняло задачу ИИ, внося больше шума, чем сигнала.
Почему меньше может быть лучше в RAG
Принцип «меньше — значит больше» имеет смысл, если учесть, как модели ИИ обрабатывают информацию. С меньшим количеством более релевантных документов ИИ может сосредоточиться на основном контексте без отвлечений, подобно студенту, изучающему наиболее подходящий материал.
В исследовании модели работали лучше, когда получали только документы, непосредственно связанные с ответом, поскольку этот более чистый и сфокусированный контекст облегчал извлечение правильной информации. Напротив, когда ИИ приходилось просеивать множество документов, он часто испытывал трудности с сочетанием релевантного и нерелевантного контента. Похожие, но не связанные документы могли ввести модель в заблуждение, увеличивая риск галлюцинаций.
Интересно, что исследование показало, что ИИ легче игнорировал явно нерелевантные документы, чем те, которые были слегка не по теме. Это говорит о том, что реалистичные отвлекающие факторы более запутывают, чем случайные. Ограничивая количество документов только необходимыми, мы снижаем вероятность создания таких ловушек.
Кроме того, использование меньшего количества документов снижает вычислительные затраты, делая систему более эффективной и экономичной. Этот подход не только повышает точность, но и улучшает общую производительность системы RAG.
Источник: Леви и др.
Переосмысление RAG: будущие направления
Эти выводы имеют значительные последствия для проектирования будущих систем ИИ, зависящих от внешних знаний. Они предполагают, что сосредоточение на качестве и релевантности извлеченных документов, а не на их количестве, может повысить производительность. Авторы исследования выступают за методы извлечения, которые балансируют релевантность и разнообразие, обеспечивая всестороннее покрытие без перегрузки модели лишним текстом.
Будущие исследования могут быть направлены на разработку лучших систем извлечения или алгоритмов переранжирования для определения действительно ценных документов и улучшения того, как языковые модели обрабатывают множественные источники. Усовершенствование самих моделей, как видно на примере Qwen-2, также может дать понимание того, как сделать их более устойчивыми к разнообразным входным данным.
По мере того как системы ИИ развивают более широкие контекстные окна, способность обрабатывать больше текста одновременно становится менее критичной, чем обеспечение релевантности и курирования текста. Исследование под названием «Больше документов, та же длина» подчеркивает важность сосредоточения на наиболее подходящей информации для повышения точности и эффективности ИИ.
В заключение, это исследование бросает вызов нашим предположениям о вводе данных в системы ИИ. Тщательно выбирая меньше, но более качественных документов, мы можем создавать более умные и экономичные системы RAG, которые обеспечивают более точные и надежные ответы.










 Правительство США инвестирует в Intel, чтобы увеличить производство полупроводников в стране
Администрация Трампа уделяет первостепенное внимание установлению лидерства США в области искусственного интеллекта, а краеугольным камнем стратегии является реорганизация производства полупроводников
Правительство США инвестирует в Intel, чтобы увеличить производство полупроводников в стране
Администрация Трампа уделяет первостепенное внимание установлению лидерства США в области искусственного интеллекта, а краеугольным камнем стратегии является реорганизация производства полупроводников
 Крейг Федериги из Apple признает, что у искусственного интеллекта Siri были серьезные недостатки на ранних стадиях
Руководители Apple объяснили задержку обновления SiriВо время WWDC 2024 Apple первоначально обещала значительные улучшения Siri, включая персонализированную контекстную осведомленность и возможности
Крейг Федериги из Apple признает, что у искусственного интеллекта Siri были серьезные недостатки на ранних стадиях
Руководители Apple объяснили задержку обновления SiriВо время WWDC 2024 Apple первоначально обещала значительные улучшения Siri, включая персонализированную контекстную осведомленность и возможности
 Освойте техники AI Inpainting: Руководство по безупречному редактированию изображений
Откройте для себя преобразующие возможности технологии искусственного интеллекта Midjourney - революционной функции, позволяющей творцам с хирургической точностью дорабатывать и совершенствовать созда
10 сентября 2025 г., 3:30:32 GMT+03:00
Освойте техники AI Inpainting: Руководство по безупречному редактированию изображений
Откройте для себя преобразующие возможности технологии искусственного интеллекта Midjourney - революционной функции, позволяющей творцам с хирургической точностью дорабатывать и совершенствовать созда
10 сентября 2025 г., 3:30:32 GMT+03:00
La RAG est révolutionnaire, mais je me demande si limiter les documents récupérés pourrait parfois manquer des infos cruciales 🤔. Perso, j'opterais pour un juste milieu entre précision et exhaustivité !
0
29 июля 2025 г., 15:25:16 GMT+03:00
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?
0
26 апреля 2025 г., 9:04:32 GMT+03:00
Adoro como essa ferramenta torna as respostas do AI mais precisas usando menos documentos. É como mágica! Mas às vezes parece que está faltando alguma informação. Ainda assim, uma ótima ferramenta para respostas rápidas e confiáveis. 👍
0
24 апреля 2025 г., 1:29:07 GMT+03:00
I love how this tool makes AI responses more accurate by using fewer documents. It's like magic! But sometimes it feels like it's missing out on some info. Still, a great tool for quick, reliable answers. 👍
0
22 апреля 2025 г., 19:50:26 GMT+03:00
「少ない方が良い」というAIの応答方法はかなりクール!少ないドキュメントから正確な答えを得るなんて、登録したいですね!魔法のようですが、もっと早く動いてほしいです。でも、AI技術の前進の一歩としては素晴らしいですね!🚀
0
21 апреля 2025 г., 14:14:10 GMT+03:00
This app really simplifies things! By retrieving fewer but more relevant documents, the AI responses are much more accurate and to the point. It's like having a smart assistant that knows exactly what you need. Only wish it was a bit faster. Still, a great tool! 😊
0













