




Menos é mais: como recuperar menos documentos aprimora as respostas da IA
A Geração Aumentada por Recuperação (RAG) é uma abordagem inovadora para construir sistemas de IA, combinando um modelo de linguagem com uma fonte de conhecimento externa para aumentar a precisão e reduzir erros factuais. Em essência, a IA busca documentos relevantes relacionados à consulta de um usuário e utiliza essas informações para gerar uma resposta mais precisa. Esse método ganhou reconhecimento por sua capacidade de manter grandes modelos de linguagem (LLMs) ancorados em dados reais, minimizando o risco de alucinações.
Você pode presumir que fornecer mais documentos à IA levaria a respostas mais bem informadas. No entanto, um estudo recente da Universidade Hebraica de Jerusalém sugere o contrário: quando se trata de fornecer informações à IA, menos pode, de fato, ser mais.
Menos Documentos, Melhores Respostas
O estudo analisou como o número de documentos fornecidos a um sistema RAG impacta seu desempenho. Os pesquisadores mantiveram um comprimento total de texto consistente, ajustando a contagem de documentos de 20 para 2-4 relevantes e expandindo esses para corresponder ao volume de texto original. Isso permitiu isolar o efeito da quantidade de documentos no desempenho.
Usando o conjunto de dados MuSiQue, que inclui perguntas de trivialidades combinadas com parágrafos da Wikipédia, eles descobriram que os modelos de IA frequentemente tinham melhor desempenho com menos documentos. A precisão melhorou em até 10% (medida pelo escore F1) quando o sistema se concentrava em apenas alguns documentos-chave, em vez de uma coleção ampla. Essa tendência se manteve em vários modelos de linguagem de código aberto, como o Llama da Meta, com o Qwen-2 sendo a notável exceção, mantendo seu desempenho com múltiplos documentos.
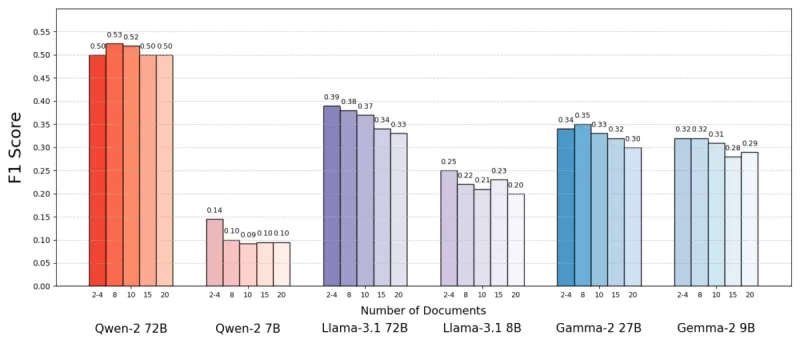 Fonte: Levy et al.
Fonte: Levy et al.
Esse resultado surpreendente desafia a crença comum de que mais informações sempre ajudam. Mesmo com a mesma quantidade de texto, a presença de múltiplos documentos pareceu complicar a tarefa da IA, introduzindo mais ruído do que sinal.
Por Que Menos Pode Ser Mais em RAG
O princípio de "menos é mais" faz sentido quando consideramos como os modelos de IA processam informações. Com menos documentos, mais relevantes, a IA pode se concentrar no contexto essencial sem distrações, assim como um estudante estudando o material mais pertinente.
No estudo, os modelos tiveram melhor desempenho quando recebiam apenas os documentos diretamente relevantes para a resposta, pois esse contexto mais limpo e focado facilitava a extração das informações corretas. Por outro lado, quando a IA precisava filtrar muitos documentos, frequentemente enfrentava dificuldades com a mistura de conteúdo relevante e irrelevante. Documentos semelhantes, mas não relacionados, podiam enganar o modelo, aumentando o risco de alucinações.
Curiosamente, o estudo descobriu que a IA conseguia ignorar mais facilmente documentos claramente irrelevantes do que aqueles sutilmente fora do tema. Isso sugere que distratores realistas são mais confusos do que os aleatórios. Ao limitar os documentos apenas aos necessários, reduzimos a probabilidade de criar tais armadilhas.
Além disso, usar menos documentos reduz a sobrecarga computacional, tornando o sistema mais eficiente e econômico. Essa abordagem não apenas melhora a precisão, mas também aprimora o desempenho geral do sistema RAG.
 Fonte: Levy et al.
Fonte: Levy et al.
Repensando o RAG: Direções Futuras
Essas descobertas têm implicações significativas para o design de futuros sistemas de IA que dependem de conhecimento externo. Elas sugerem que focar na qualidade e relevância dos documentos recuperados, em vez de sua quantidade, pode melhorar o desempenho. Os autores do estudo defendem métodos de recuperação que equilibrem relevância e diversidade, garantindo uma cobertura abrangente sem sobrecarregar o modelo com texto desnecessário.
Pesquisas futuras podem explorar sistemas de recuperação ou reclassificadores melhores para identificar documentos verdadeiramente valiosos e melhorar como os modelos de linguagem lidam com múltiplas fontes. Aprimorar os próprios modelos, como visto com o Qwen-2, também pode fornecer insights sobre como torná-los mais robustos a entradas diversas.
À medida que os sistemas de IA desenvolvem janelas de contexto maiores, a capacidade de processar mais texto de uma vez se torna menos crítica do que garantir que o texto seja relevante e curado. O estudo, intitulado "Mais Documentos, Mesmo Comprimento," destaca a importância de focar nas informações mais pertinentes para melhorar a precisão e a eficiência da IA.
Em conclusão, esta pesquisa desafia nossas suposições sobre a entrada de dados em sistemas de IA. Ao selecionar cuidadosamente menos documentos, mas melhores, podemos criar sistemas RAG mais inteligentes e enxutos que entregam respostas mais precisas e confiáveis.
Artigo relacionado
 Craig Federighi, da Apple, admite que a Siri com IA tinha falhas graves nos estágios iniciais
Executivos da Apple explicam o atraso na atualização da SiriDurante a WWDC 2024, a Apple originalmente prometeu melhorias significativas na Siri, incluindo reconhecimento de contexto personalizado e
Domine as técnicas de pintura com IA: Guia intermediário para edição de imagens sem falhas
Descubra os recursos transformadores da tecnologia AI inpainting do Midjourney, um recurso revolucionário que permite aos criadores refinar e aperfeiçoar obras de arte geradas por IA com precisão cirú
Manus lança a ferramenta de IA 'Wide Research' com mais de 100 agentes para raspagem da Web
A Manus, empresa chinesa inovadora em IA, que já chamou a atenção por sua plataforma pioneira de orquestração de multiagentes voltada para consumidores e usuários profissionais, revelou uma aplicação
Comentários (47)
0/200
Craig Federighi, da Apple, admite que a Siri com IA tinha falhas graves nos estágios iniciais
Executivos da Apple explicam o atraso na atualização da SiriDurante a WWDC 2024, a Apple originalmente prometeu melhorias significativas na Siri, incluindo reconhecimento de contexto personalizado e
Domine as técnicas de pintura com IA: Guia intermediário para edição de imagens sem falhas
Descubra os recursos transformadores da tecnologia AI inpainting do Midjourney, um recurso revolucionário que permite aos criadores refinar e aperfeiçoar obras de arte geradas por IA com precisão cirú
Manus lança a ferramenta de IA 'Wide Research' com mais de 100 agentes para raspagem da Web
A Manus, empresa chinesa inovadora em IA, que já chamou a atenção por sua plataforma pioneira de orquestração de multiagentes voltada para consumidores e usuários profissionais, revelou uma aplicação
Comentários (47)
0/200
![LarryWilliams]() LarryWilliams
LarryWilliams
 10 de Setembro de 2025 à32 01:30:32 WEST
10 de Setembro de 2025 à32 01:30:32 WEST
La RAG est révolutionnaire, mais je me demande si limiter les documents récupérés pourrait parfois manquer des infos cruciales 🤔. Perso, j'opterais pour un juste milieu entre précision et exhaustivité !


 0
0
![BruceBrown]() BruceBrown
29 de Julho de 2025 à16 13:25:16 WEST
BruceBrown
29 de Julho de 2025 à16 13:25:16 WEST
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?
0
![JasonMartin]() JasonMartin
26 de Abril de 2025 à32 07:04:32 WEST
JasonMartin
26 de Abril de 2025 à32 07:04:32 WEST
Adoro como essa ferramenta torna as respostas do AI mais precisas usando menos documentos. É como mágica! Mas às vezes parece que está faltando alguma informação. Ainda assim, uma ótima ferramenta para respostas rápidas e confiáveis. 👍
0
![JuanMoore]() JuanMoore
23 de Abril de 2025 à7 23:29:07 WEST
JuanMoore
23 de Abril de 2025 à7 23:29:07 WEST
I love how this tool makes AI responses more accurate by using fewer documents. It's like magic! But sometimes it feels like it's missing out on some info. Still, a great tool for quick, reliable answers. 👍
0
![GregoryJones]() GregoryJones
22 de Abril de 2025 à26 17:50:26 WEST
GregoryJones
22 de Abril de 2025 à26 17:50:26 WEST
「少ない方が良い」というAIの応答方法はかなりクール!少ないドキュメントから正確な答えを得るなんて、登録したいですね!魔法のようですが、もっと早く動いてほしいです。でも、AI技術の前進の一歩としては素晴らしいですね!🚀
0
![BrianMartinez]() BrianMartinez
21 de Abril de 2025 à10 12:14:10 WEST
BrianMartinez
21 de Abril de 2025 à10 12:14:10 WEST
This app really simplifies things! By retrieving fewer but more relevant documents, the AI responses are much more accurate and to the point. It's like having a smart assistant that knows exactly what you need. Only wish it was a bit faster. Still, a great tool! 😊
0
A Geração Aumentada por Recuperação (RAG) é uma abordagem inovadora para construir sistemas de IA, combinando um modelo de linguagem com uma fonte de conhecimento externa para aumentar a precisão e reduzir erros factuais. Em essência, a IA busca documentos relevantes relacionados à consulta de um usuário e utiliza essas informações para gerar uma resposta mais precisa. Esse método ganhou reconhecimento por sua capacidade de manter grandes modelos de linguagem (LLMs) ancorados em dados reais, minimizando o risco de alucinações.
Você pode presumir que fornecer mais documentos à IA levaria a respostas mais bem informadas. No entanto, um estudo recente da Universidade Hebraica de Jerusalém sugere o contrário: quando se trata de fornecer informações à IA, menos pode, de fato, ser mais.
Menos Documentos, Melhores Respostas
O estudo analisou como o número de documentos fornecidos a um sistema RAG impacta seu desempenho. Os pesquisadores mantiveram um comprimento total de texto consistente, ajustando a contagem de documentos de 20 para 2-4 relevantes e expandindo esses para corresponder ao volume de texto original. Isso permitiu isolar o efeito da quantidade de documentos no desempenho.
Usando o conjunto de dados MuSiQue, que inclui perguntas de trivialidades combinadas com parágrafos da Wikipédia, eles descobriram que os modelos de IA frequentemente tinham melhor desempenho com menos documentos. A precisão melhorou em até 10% (medida pelo escore F1) quando o sistema se concentrava em apenas alguns documentos-chave, em vez de uma coleção ampla. Essa tendência se manteve em vários modelos de linguagem de código aberto, como o Llama da Meta, com o Qwen-2 sendo a notável exceção, mantendo seu desempenho com múltiplos documentos.
Fonte: Levy et al.
Esse resultado surpreendente desafia a crença comum de que mais informações sempre ajudam. Mesmo com a mesma quantidade de texto, a presença de múltiplos documentos pareceu complicar a tarefa da IA, introduzindo mais ruído do que sinal.
Por Que Menos Pode Ser Mais em RAG
O princípio de "menos é mais" faz sentido quando consideramos como os modelos de IA processam informações. Com menos documentos, mais relevantes, a IA pode se concentrar no contexto essencial sem distrações, assim como um estudante estudando o material mais pertinente.
No estudo, os modelos tiveram melhor desempenho quando recebiam apenas os documentos diretamente relevantes para a resposta, pois esse contexto mais limpo e focado facilitava a extração das informações corretas. Por outro lado, quando a IA precisava filtrar muitos documentos, frequentemente enfrentava dificuldades com a mistura de conteúdo relevante e irrelevante. Documentos semelhantes, mas não relacionados, podiam enganar o modelo, aumentando o risco de alucinações.
Curiosamente, o estudo descobriu que a IA conseguia ignorar mais facilmente documentos claramente irrelevantes do que aqueles sutilmente fora do tema. Isso sugere que distratores realistas são mais confusos do que os aleatórios. Ao limitar os documentos apenas aos necessários, reduzimos a probabilidade de criar tais armadilhas.
Além disso, usar menos documentos reduz a sobrecarga computacional, tornando o sistema mais eficiente e econômico. Essa abordagem não apenas melhora a precisão, mas também aprimora o desempenho geral do sistema RAG.
Fonte: Levy et al.
Repensando o RAG: Direções Futuras
Essas descobertas têm implicações significativas para o design de futuros sistemas de IA que dependem de conhecimento externo. Elas sugerem que focar na qualidade e relevância dos documentos recuperados, em vez de sua quantidade, pode melhorar o desempenho. Os autores do estudo defendem métodos de recuperação que equilibrem relevância e diversidade, garantindo uma cobertura abrangente sem sobrecarregar o modelo com texto desnecessário.
Pesquisas futuras podem explorar sistemas de recuperação ou reclassificadores melhores para identificar documentos verdadeiramente valiosos e melhorar como os modelos de linguagem lidam com múltiplas fontes. Aprimorar os próprios modelos, como visto com o Qwen-2, também pode fornecer insights sobre como torná-los mais robustos a entradas diversas.
À medida que os sistemas de IA desenvolvem janelas de contexto maiores, a capacidade de processar mais texto de uma vez se torna menos crítica do que garantir que o texto seja relevante e curado. O estudo, intitulado "Mais Documentos, Mesmo Comprimento," destaca a importância de focar nas informações mais pertinentes para melhorar a precisão e a eficiência da IA.
Em conclusão, esta pesquisa desafia nossas suposições sobre a entrada de dados em sistemas de IA. Ao selecionar cuidadosamente menos documentos, mas melhores, podemos criar sistemas RAG mais inteligentes e enxutos que entregam respostas mais precisas e confiáveis.










 Craig Federighi, da Apple, admite que a Siri com IA tinha falhas graves nos estágios iniciais
Executivos da Apple explicam o atraso na atualização da SiriDurante a WWDC 2024, a Apple originalmente prometeu melhorias significativas na Siri, incluindo reconhecimento de contexto personalizado e
Craig Federighi, da Apple, admite que a Siri com IA tinha falhas graves nos estágios iniciais
Executivos da Apple explicam o atraso na atualização da SiriDurante a WWDC 2024, a Apple originalmente prometeu melhorias significativas na Siri, incluindo reconhecimento de contexto personalizado e
 Domine as técnicas de pintura com IA: Guia intermediário para edição de imagens sem falhas
Descubra os recursos transformadores da tecnologia AI inpainting do Midjourney, um recurso revolucionário que permite aos criadores refinar e aperfeiçoar obras de arte geradas por IA com precisão cirú
Domine as técnicas de pintura com IA: Guia intermediário para edição de imagens sem falhas
Descubra os recursos transformadores da tecnologia AI inpainting do Midjourney, um recurso revolucionário que permite aos criadores refinar e aperfeiçoar obras de arte geradas por IA com precisão cirú
 Manus lança a ferramenta de IA 'Wide Research' com mais de 100 agentes para raspagem da Web
A Manus, empresa chinesa inovadora em IA, que já chamou a atenção por sua plataforma pioneira de orquestração de multiagentes voltada para consumidores e usuários profissionais, revelou uma aplicação
10 de Setembro de 2025 à32 01:30:32 WEST
Manus lança a ferramenta de IA 'Wide Research' com mais de 100 agentes para raspagem da Web
A Manus, empresa chinesa inovadora em IA, que já chamou a atenção por sua plataforma pioneira de orquestração de multiagentes voltada para consumidores e usuários profissionais, revelou uma aplicação
10 de Setembro de 2025 à32 01:30:32 WEST
La RAG est révolutionnaire, mais je me demande si limiter les documents récupérés pourrait parfois manquer des infos cruciales 🤔. Perso, j'opterais pour un juste milieu entre précision et exhaustivité !
0
29 de Julho de 2025 à16 13:25:16 WEST
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?
0
26 de Abril de 2025 à32 07:04:32 WEST
Adoro como essa ferramenta torna as respostas do AI mais precisas usando menos documentos. É como mágica! Mas às vezes parece que está faltando alguma informação. Ainda assim, uma ótima ferramenta para respostas rápidas e confiáveis. 👍
0
23 de Abril de 2025 à7 23:29:07 WEST
I love how this tool makes AI responses more accurate by using fewer documents. It's like magic! But sometimes it feels like it's missing out on some info. Still, a great tool for quick, reliable answers. 👍
0
22 de Abril de 2025 à26 17:50:26 WEST
「少ない方が良い」というAIの応答方法はかなりクール!少ないドキュメントから正確な答えを得るなんて、登録したいですね!魔法のようですが、もっと早く動いてほしいです。でも、AI技術の前進の一歩としては素晴らしいですね!🚀
0
21 de Abril de 2025 à10 12:14:10 WEST
This app really simplifies things! By retrieving fewer but more relevant documents, the AI responses are much more accurate and to the point. It's like having a smart assistant that knows exactly what you need. Only wish it was a bit faster. Still, a great tool! 😊
0













