
















 집
집더 적은 점 : 문서를 적게 검색하는 방법 AI 응답을 향상시키는 방법
검색 증강 생성(RAG)은 언어 모델과 외부 지식 소스를 결합하여 정확성을 높이고 사실적 오류를 줄이는 혁신적인 AI 시스템 구축 접근법입니다. 본질적으로, AI는 사용자의 질의와 관련된 문서를 검색하고 이 정보를 활용하여 더 정확한 응답을 생성합니다. 이 방법은 대규모 언어 모델(LLMs)을 실제 데이터에 기반을 두게 하여 환각(hallucination) 위험을 최소화하는 능력으로 인정받고 있습니다.
AI에 더 많은 문서를 제공하면 더 정보에 기반한 답변을 얻을 것이라고 생각할 수 있습니다. 그러나 예루살렘 히브리 대학교의 최근 연구는 그 반대를 시사합니다: AI에 정보를 제공할 때 적은 것이 실제로 더 나을 수 있습니다.
문서 수 줄이기, 더 나은 답변
이 연구는 RAG 시스템에 제공된 문서의 수가 성능에 어떤 영향을 미치는지 탐구했습니다. 연구자들은 총 텍스트 길이를 일정하게 유지하면서 문서 수를 20개에서 2~4개의 관련 문서로 줄이고, 이를 원래 텍스트 양에 맞게 확장했습니다. 이를 통해 문서 수량이 성능에 미치는 영향을 분리할 수 있었습니다.
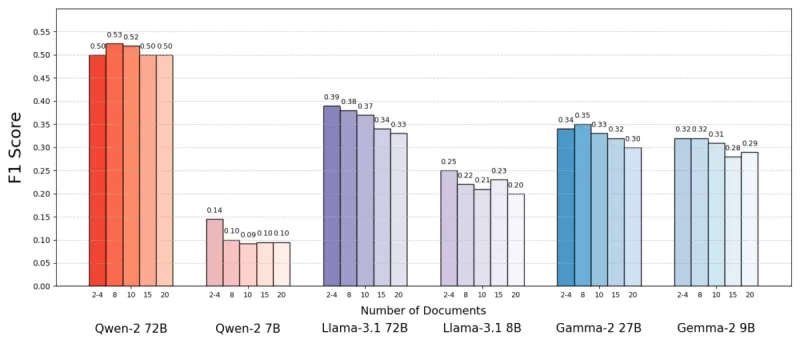
MuSiQue 데이터셋을 사용했으며, 이 데이터셋은 퀴즈 질문과 위키피디아 문단으로 구성되어 있습니다. 연구 결과, AI 모델은 문서 수가 적을 때 더 나은 성능을 보였습니다. 시스템이 광범위한 문서 컬렉션 대신 몇 개의 핵심 문서에 집중했을 때 정확도가 최대 10% 향상되었습니다(F1 점수로 측정). 이 추세는 Meta의 Llama와 같은 다양한 오픈소스 언어 모델에서 나타났으며, Qwen-2는 여러 문서에서도 성능을 유지한 주목할 만한 예외였습니다.
 출처: Levy et al.
출처: Levy et al.
이 놀라운 결과는 더 많은 정보가 항상 도움이 된다는 일반적인 믿음에 도전합니다. 같은 텍스트 양이라도 여러 문서가 존재하면 AI의 작업이 복잡해져 신호보다 잡음이 더 많이 유입되는 것으로 보입니다.
RAG에서 적은 것이 더 나은 이유
“적은 것이 더 많다”는 원리는 AI 모델이 정보를 처리하는 방식을 고려할 때 이해할 수 있습니다. 더 적고 관련성 높은 문서를 제공받으면 AI는 방해 없이 핵심 맥락에 집중할 수 있습니다. 마치 학생이 가장 관련 있는 자료만 공부하는 것과 비슷합니다.
연구에서 모델은 답변에 직접 관련된 문서만 제공받았을 때 더 나은 성능을 보였습니다. 이 깔끔하고 집중된 맥락은 올바른 정보를 추출하기 쉽게 만들었습니다. 반대로, AI가 많은 문서를 검토해야 할 때는 관련성과 무관한 내용이 섞여 어려움을 겪었습니다. 유사하지만 관련 없는 문서는 모델을 오도하여 환각의 위험을 높였습니다.
흥미롭게도, 연구는 AI가 명백히 무관한 문서보다 미묘하게 주제에서 벗어난 문서를 더 쉽게 무시할 수 있음을 발견했습니다. 이는 현실적인 방해 요소가 무작위적인 것보다 더 혼란스럽다는 것을 시사합니다. 필요한 문서만으로 제한함으로써 이러한 함정을 설정할 가능성을 줄일 수 있습니다.
또한, 문서 수를 줄이면 계산 부담이 낮아져 시스템이 더 효율적이고 비용 효율적으로 작동합니다. 이 접근법은 정확성을 높일 뿐만 아니라 RAG 시스템의 전반적인 성능을 향상시킵니다.
 출처: Levy et al.
출처: Levy et al.
RAG 재고: 미래 방향
이러한 발견은 외부 지식에 의존하는 미래 AI 시스템 설계에 중요한 시사점을 제공합니다. 검색된 문서의 양보다 품질과 관련성에 집중하는 것이 성능을 향상시킬 수 있음을 시사합니다. 연구 저자들은 관련성과 다양성의 균형을 맞춘 검색 방법을 옹호하며, 불필요한 텍스트로 모델을 압도하지 않으면서 포괄적인 커버리지를 보장할 것을 제안합니다.
미래 연구는 정말로 가치 있는 문서를 식별하고 언어 모델이 여러 소스를 처리하는 방식을 개선하기 위해 더 나은 검색 시스템이나 재순위 시스템을 탐구할 수 있습니다. Qwen-2에서 보듯이 모델 자체를 개선하면 다양한 입력에 더 강건한 모델을 만드는 데 통찰을 제공할 수 있습니다.
AI 시스템이 더 큰 맥락 창을 개발함에 따라, 한 번에 더 많은 텍스트를 처리하는 능력은 텍스트가 관련 있고 선별된 것인지 확인하는 것보다 덜 중요해집니다. "More Documents, Same Length"라는 제목의 이 연구는 AI 정확성과 효율성을 개선하기 위해 가장 관련 있는 정보에 집중하는 중요성을 강조합니다.
결론적으로, 이 연구는 AI 시스템의 데이터 입력에 대한 우리의 가정을 도전합니다. 더 적고 더 나은 문서를 신중히 선택함으로써, 더 정확하고 신뢰할 수 있는 답변을 제공하는 더 스마트하고 간결한 RAG 시스템을 만들 수 있습니다.
관련 기사
 하이얼, 무게가 단 1.75kg에 불과한 세계에서 가장 가벼운 AI 스포츠 외골격 로봇 출시
하이얼 그룹은 세계에서 가장 가벼운 AI 기반 스포츠용 외골격 로봇인 ‘하이얼 외골격 로봇 W3’를 선보였습니다. 이번 출시로 경량성 부문에서 업계 신기록을 세우며, 경량 설계 및 지능형 인간 동작 강화 분야에서 획기적인 진전을 이루었습니다.고급 소재가 구현한 초경량 디자인W3는 풀 카본 파이버와 티타늄 합금을 결합한 혁신적인 일체형 제조 공정을 적용했습니
야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
관련 특별 주제 추천
사업
하이얼, 무게가 단 1.75kg에 불과한 세계에서 가장 가벼운 AI 스포츠 외골격 로봇 출시
하이얼 그룹은 세계에서 가장 가벼운 AI 기반 스포츠용 외골격 로봇인 ‘하이얼 외골격 로봇 W3’를 선보였습니다. 이번 출시로 경량성 부문에서 업계 신기록을 세우며, 경량 설계 및 지능형 인간 동작 강화 분야에서 획기적인 진전을 이루었습니다.고급 소재가 구현한 초경량 디자인W3는 풀 카본 파이버와 티타늄 합금을 결합한 혁신적인 일체형 제조 공정을 적용했습니
야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
관련 특별 주제 추천
사업
 최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
 10 도구
10 도구
 xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai
교육 및 학습
최고의 AI 데이터 과학 멘토들: SQL, Pandas 및 머신 러닝 워크플로우 마스터하기
2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai
챗봇
최고의 AI 유혹 및 대화 트레이너: 실시간으로 사회적 매력과 자신감을 높여보세요
XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai

 의견 (51)
0/500
의견 (51)
0/500
![LarryMartin]()
이런 연구 결과는 RAG 시스템을 최적화하는 데 정말 중요한 인사이트를 주는 것 같아요. 가끔 검색된 문서가 너무 많으면 AI가 오히려 핵심 내용을 놓치고 산만해지는 걸 본 적 있는데, '적게 가져올수록 더 좋다'는 아이디어가 실제 적용에서 얼마나 효과적일지 궁금해지네요. 프로젝트에 한 번 적용해 봐야겠어요! 👍
![BillyEvans]()
Interesante enfoque. A veces menos es más, y en la IA parece no ser diferente. Me pregunto si esa reducción de documentos también podría acelerar las respuestas o si hay algún riesgo de perder contexto clave. 🤔
![BruceClark]()
これ、AIが情報を少なく検索した方が精度が上がるって話?逆説的で面白いな。むしろ情報が多いとAIが混乱しちゃうんだ。人間も情報多すぎると迷うし、AIも同じなのかも。ちょっとリラックスしたなこれ。🤔
![FrankSmith]()
이거 꽤 흥미롭네요. 문서를 적게 검색할수록 AI 답변이 더 좋아진다고? 🤔 우리 팀 RAG 시스템에 적용해볼까... 그런데 이러면 검색 정밀도가 더 중요해지겠는데, 실제로 구현하기 꽤 까다롭지 않을까?
![LarryWilliams]()
La RAG est révolutionnaire, mais je me demande si limiter les documents récupérés pourrait parfois manquer des infos cruciales 🤔. Perso, j'opterais pour un juste milieu entre précision et exhaustivité !
![BruceBrown]()
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?
검색 증강 생성(RAG)은 언어 모델과 외부 지식 소스를 결합하여 정확성을 높이고 사실적 오류를 줄이는 혁신적인 AI 시스템 구축 접근법입니다. 본질적으로, AI는 사용자의 질의와 관련된 문서를 검색하고 이 정보를 활용하여 더 정확한 응답을 생성합니다. 이 방법은 대규모 언어 모델(LLMs)을 실제 데이터에 기반을 두게 하여 환각(hallucination) 위험을 최소화하는 능력으로 인정받고 있습니다.
AI에 더 많은 문서를 제공하면 더 정보에 기반한 답변을 얻을 것이라고 생각할 수 있습니다. 그러나 예루살렘 히브리 대학교의 최근 연구는 그 반대를 시사합니다: AI에 정보를 제공할 때 적은 것이 실제로 더 나을 수 있습니다.
문서 수 줄이기, 더 나은 답변
이 연구는 RAG 시스템에 제공된 문서의 수가 성능에 어떤 영향을 미치는지 탐구했습니다. 연구자들은 총 텍스트 길이를 일정하게 유지하면서 문서 수를 20개에서 2~4개의 관련 문서로 줄이고, 이를 원래 텍스트 양에 맞게 확장했습니다. 이를 통해 문서 수량이 성능에 미치는 영향을 분리할 수 있었습니다.
MuSiQue 데이터셋을 사용했으며, 이 데이터셋은 퀴즈 질문과 위키피디아 문단으로 구성되어 있습니다. 연구 결과, AI 모델은 문서 수가 적을 때 더 나은 성능을 보였습니다. 시스템이 광범위한 문서 컬렉션 대신 몇 개의 핵심 문서에 집중했을 때 정확도가 최대 10% 향상되었습니다(F1 점수로 측정). 이 추세는 Meta의 Llama와 같은 다양한 오픈소스 언어 모델에서 나타났으며, Qwen-2는 여러 문서에서도 성능을 유지한 주목할 만한 예외였습니다.
출처: Levy et al.
이 놀라운 결과는 더 많은 정보가 항상 도움이 된다는 일반적인 믿음에 도전합니다. 같은 텍스트 양이라도 여러 문서가 존재하면 AI의 작업이 복잡해져 신호보다 잡음이 더 많이 유입되는 것으로 보입니다.
RAG에서 적은 것이 더 나은 이유
“적은 것이 더 많다”는 원리는 AI 모델이 정보를 처리하는 방식을 고려할 때 이해할 수 있습니다. 더 적고 관련성 높은 문서를 제공받으면 AI는 방해 없이 핵심 맥락에 집중할 수 있습니다. 마치 학생이 가장 관련 있는 자료만 공부하는 것과 비슷합니다.
연구에서 모델은 답변에 직접 관련된 문서만 제공받았을 때 더 나은 성능을 보였습니다. 이 깔끔하고 집중된 맥락은 올바른 정보를 추출하기 쉽게 만들었습니다. 반대로, AI가 많은 문서를 검토해야 할 때는 관련성과 무관한 내용이 섞여 어려움을 겪었습니다. 유사하지만 관련 없는 문서는 모델을 오도하여 환각의 위험을 높였습니다.
흥미롭게도, 연구는 AI가 명백히 무관한 문서보다 미묘하게 주제에서 벗어난 문서를 더 쉽게 무시할 수 있음을 발견했습니다. 이는 현실적인 방해 요소가 무작위적인 것보다 더 혼란스럽다는 것을 시사합니다. 필요한 문서만으로 제한함으로써 이러한 함정을 설정할 가능성을 줄일 수 있습니다.
또한, 문서 수를 줄이면 계산 부담이 낮아져 시스템이 더 효율적이고 비용 효율적으로 작동합니다. 이 접근법은 정확성을 높일 뿐만 아니라 RAG 시스템의 전반적인 성능을 향상시킵니다.
출처: Levy et al.
RAG 재고: 미래 방향
이러한 발견은 외부 지식에 의존하는 미래 AI 시스템 설계에 중요한 시사점을 제공합니다. 검색된 문서의 양보다 품질과 관련성에 집중하는 것이 성능을 향상시킬 수 있음을 시사합니다. 연구 저자들은 관련성과 다양성의 균형을 맞춘 검색 방법을 옹호하며, 불필요한 텍스트로 모델을 압도하지 않으면서 포괄적인 커버리지를 보장할 것을 제안합니다.
미래 연구는 정말로 가치 있는 문서를 식별하고 언어 모델이 여러 소스를 처리하는 방식을 개선하기 위해 더 나은 검색 시스템이나 재순위 시스템을 탐구할 수 있습니다. Qwen-2에서 보듯이 모델 자체를 개선하면 다양한 입력에 더 강건한 모델을 만드는 데 통찰을 제공할 수 있습니다.
AI 시스템이 더 큰 맥락 창을 개발함에 따라, 한 번에 더 많은 텍스트를 처리하는 능력은 텍스트가 관련 있고 선별된 것인지 확인하는 것보다 덜 중요해집니다. "More Documents, Same Length"라는 제목의 이 연구는 AI 정확성과 효율성을 개선하기 위해 가장 관련 있는 정보에 집중하는 중요성을 강조합니다.
결론적으로, 이 연구는 AI 시스템의 데이터 입력에 대한 우리의 가정을 도전합니다. 더 적고 더 나은 문서를 신중히 선택함으로써, 더 정확하고 신뢰할 수 있는 답변을 제공하는 더 스마트하고 간결한 RAG 시스템을 만들 수 있습니다.










 하이얼, 무게가 단 1.75kg에 불과한 세계에서 가장 가벼운 AI 스포츠 외골격 로봇 출시
하이얼 그룹은 세계에서 가장 가벼운 AI 기반 스포츠용 외골격 로봇인 ‘하이얼 외골격 로봇 W3’를 선보였습니다. 이번 출시로 경량성 부문에서 업계 신기록을 세우며, 경량 설계 및 지능형 인간 동작 강화 분야에서 획기적인 진전을 이루었습니다.고급 소재가 구현한 초경량 디자인W3는 풀 카본 파이버와 티타늄 합금을 결합한 혁신적인 일체형 제조 공정을 적용했습니
하이얼, 무게가 단 1.75kg에 불과한 세계에서 가장 가벼운 AI 스포츠 외골격 로봇 출시
하이얼 그룹은 세계에서 가장 가벼운 AI 기반 스포츠용 외골격 로봇인 ‘하이얼 외골격 로봇 W3’를 선보였습니다. 이번 출시로 경량성 부문에서 업계 신기록을 세우며, 경량 설계 및 지능형 인간 동작 강화 분야에서 획기적인 진전을 이루었습니다.고급 소재가 구현한 초경량 디자인W3는 풀 카본 파이버와 티타늄 합금을 결합한 혁신적인 일체형 제조 공정을 적용했습니
 야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
 사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai

이런 연구 결과는 RAG 시스템을 최적화하는 데 정말 중요한 인사이트를 주는 것 같아요. 가끔 검색된 문서가 너무 많으면 AI가 오히려 핵심 내용을 놓치고 산만해지는 걸 본 적 있는데, '적게 가져올수록 더 좋다'는 아이디어가 실제 적용에서 얼마나 효과적일지 궁금해지네요. 프로젝트에 한 번 적용해 봐야겠어요! 👍
Interesante enfoque. A veces menos es más, y en la IA parece no ser diferente. Me pregunto si esa reducción de documentos también podría acelerar las respuestas o si hay algún riesgo de perder contexto clave. 🤔
これ、AIが情報を少なく検索した方が精度が上がるって話?逆説的で面白いな。むしろ情報が多いとAIが混乱しちゃうんだ。人間も情報多すぎると迷うし、AIも同じなのかも。ちょっとリラックスしたなこれ。🤔
이거 꽤 흥미롭네요. 문서를 적게 검색할수록 AI 답변이 더 좋아진다고? 🤔 우리 팀 RAG 시스템에 적용해볼까... 그런데 이러면 검색 정밀도가 더 중요해지겠는데, 실제로 구현하기 꽤 까다롭지 않을까?
La RAG est révolutionnaire, mais je me demande si limiter les documents récupérés pourrait parfois manquer des infos cruciales 🤔. Perso, j'opterais pour un juste milieu entre précision et exhaustivité !
This article on RAG is super intriguing! Fewer documents leading to better AI responses? Mind blown 🤯. Makes me wonder how this could streamline chatbots for customer service. Anyone tried this yet?













