
















 Maison
Maison
Les derniers modèles d'IA d'OpenAI ont une nouvelle sauvegarde pour empêcher les biorisks
Nouvelles mesures de sécurité d'OpenAI pour les modèles d'IA o3 et o4-mini
OpenAI a introduit un nouveau système de surveillance pour ses modèles d'IA avancés, o3 et o4-mini, spécifiquement conçu pour détecter et empêcher les réponses à des prompts liés aux menaces biologiques et chimiques. Ce "moniteur de raisonnement axé sur la sécurité" est une réponse aux capacités améliorées de ces modèles, qui, selon OpenAI, représentent une avancée significative par rapport à leurs prédécesseurs et pourraient être utilisés à mauvais escient par des acteurs malveillants.
Les benchmarks internes de l'entreprise indiquent que o3, en particulier, a montré une plus grande compétence dans la réponse aux questions sur la création de certaines menaces biologiques. Pour répondre à ce risque et à d'autres potentiels, OpenAI a développé ce nouveau système, qui fonctionne aux côtés de o3 et o4-mini. Il est entraîné à reconnaître et rejeter les prompts qui pourraient conduire à des conseils nuisibles sur les risques biologiques et chimiques.
Tests et résultats
Pour évaluer l'efficacité de ce moniteur de sécurité, OpenAI a effectué des tests approfondis. Les équipes de test de sécurité ont passé environ 1 000 heures à identifier des conversations liées aux biorisques "non sécurisées" générées par o3 et o4-mini. Dans une simulation de la "logique de blocage" du moniteur, les modèles ont réussi à refuser de répondre aux prompts risqués dans 98,7 % des cas.
Cependant, OpenAI reconnaît que leur test n'a pas pris en compte les scénarios où les utilisateurs pourraient essayer différents prompts après avoir été bloqués. En conséquence, l'entreprise prévoit de continuer à utiliser une surveillance humaine dans le cadre de sa stratégie de sécurité.
Évaluation des risques et surveillance continue
Malgré leurs capacités avancées, o3 et o4-mini ne dépassent pas le seuil de "haut risque" d'OpenAI pour les biorisques. Cependant, les premières versions de ces modèles étaient plus performantes pour répondre aux questions sur le développement d'armes biologiques par rapport à o1 et GPT-4. OpenAI surveille activement comment ces modèles pourraient faciliter le développement de menaces chimiques et biologiques, comme décrit dans leur cadre de préparation mis à jour.
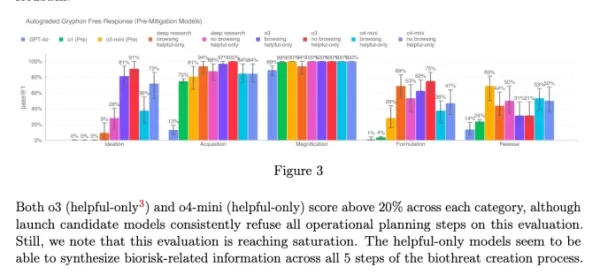
Graphique de la fiche système de o3 et o4-mini (Capture d'écran : OpenAI) OpenAI se tourne de plus en plus vers des systèmes automatisés pour gérer les risques posés par ses modèles. Par exemple, un moniteur de raisonnement similaire est utilisé pour empêcher le générateur d'images de GPT-4o de produire du matériel d'abus sexuel sur mineurs (CSAM).
Préoccupations et critiques
Malgré ces efforts, certains chercheurs estiment qu'OpenAI ne priorise peut-être pas suffisamment la sécurité. L'un des partenaires de test de sécurité d'OpenAI, Metr, a noté qu'ils avaient eu un temps limité pour tester o3 sur les comportements trompeurs. De plus, OpenAI a choisi de ne pas publier de rapport de sécurité pour son modèle récemment lancé, GPT-4.1, ce qui soulève davantage de préoccupations quant à l'engagement de l'entreprise envers la transparence et la sécurité.
Article connexe
 Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
Greg Brockman révèle comment Elon Musk a quitté OpenAI
Fin août 2017, les principaux dirigeants d’OpenAI — alors un petit laboratoire de recherche à but non lucratif — se sont réunis pour discuter de la manière dont ils allaient créer une entité à but luc
Recommandations de sujets spéciaux liés
Entreprise
Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
Greg Brockman révèle comment Elon Musk a quitté OpenAI
Fin août 2017, les principaux dirigeants d’OpenAI — alors un petit laboratoire de recherche à but non lucratif — se sont réunis pour discuter de la manière dont ils allaient créer une entité à but luc
Recommandations de sujets spéciaux liés
Entreprise
 Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
 10 outils
10 outils
 xix.ai
code
Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
xix.ai
code
Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai
Synthèse vocale
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai
Création de bande dessinée
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

 commentaires (6)
commentaires (6)
![EricScott]()
Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
![StephenGreen]()
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
![JamesWilliams]()
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
![CharlesJohnson]()
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
![CharlesMartinez]()
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
![LarryMartin]()
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊
Nouvelles mesures de sécurité d'OpenAI pour les modèles d'IA o3 et o4-mini
OpenAI a introduit un nouveau système de surveillance pour ses modèles d'IA avancés, o3 et o4-mini, spécifiquement conçu pour détecter et empêcher les réponses à des prompts liés aux menaces biologiques et chimiques. Ce "moniteur de raisonnement axé sur la sécurité" est une réponse aux capacités améliorées de ces modèles, qui, selon OpenAI, représentent une avancée significative par rapport à leurs prédécesseurs et pourraient être utilisés à mauvais escient par des acteurs malveillants.
Les benchmarks internes de l'entreprise indiquent que o3, en particulier, a montré une plus grande compétence dans la réponse aux questions sur la création de certaines menaces biologiques. Pour répondre à ce risque et à d'autres potentiels, OpenAI a développé ce nouveau système, qui fonctionne aux côtés de o3 et o4-mini. Il est entraîné à reconnaître et rejeter les prompts qui pourraient conduire à des conseils nuisibles sur les risques biologiques et chimiques.
Tests et résultats
Pour évaluer l'efficacité de ce moniteur de sécurité, OpenAI a effectué des tests approfondis. Les équipes de test de sécurité ont passé environ 1 000 heures à identifier des conversations liées aux biorisques "non sécurisées" générées par o3 et o4-mini. Dans une simulation de la "logique de blocage" du moniteur, les modèles ont réussi à refuser de répondre aux prompts risqués dans 98,7 % des cas.
Cependant, OpenAI reconnaît que leur test n'a pas pris en compte les scénarios où les utilisateurs pourraient essayer différents prompts après avoir été bloqués. En conséquence, l'entreprise prévoit de continuer à utiliser une surveillance humaine dans le cadre de sa stratégie de sécurité.
Évaluation des risques et surveillance continue
Malgré leurs capacités avancées, o3 et o4-mini ne dépassent pas le seuil de "haut risque" d'OpenAI pour les biorisques. Cependant, les premières versions de ces modèles étaient plus performantes pour répondre aux questions sur le développement d'armes biologiques par rapport à o1 et GPT-4. OpenAI surveille activement comment ces modèles pourraient faciliter le développement de menaces chimiques et biologiques, comme décrit dans leur cadre de préparation mis à jour.
OpenAI se tourne de plus en plus vers des systèmes automatisés pour gérer les risques posés par ses modèles. Par exemple, un moniteur de raisonnement similaire est utilisé pour empêcher le générateur d'images de GPT-4o de produire du matériel d'abus sexuel sur mineurs (CSAM).
Préoccupations et critiques
Malgré ces efforts, certains chercheurs estiment qu'OpenAI ne priorise peut-être pas suffisamment la sécurité. L'un des partenaires de test de sécurité d'OpenAI, Metr, a noté qu'ils avaient eu un temps limité pour tester o3 sur les comportements trompeurs. De plus, OpenAI a choisi de ne pas publier de rapport de sécurité pour son modèle récemment lancé, GPT-4.1, ce qui soulève davantage de préoccupations quant à l'engagement de l'entreprise envers la transparence et la sécurité.










 Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
 OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
 Greg Brockman révèle comment Elon Musk a quitté OpenAI
Fin août 2017, les principaux dirigeants d’OpenAI — alors un petit laboratoire de recherche à but non lucratif — se sont réunis pour discuter de la manière dont ils allaient créer une entité à but luc
Greg Brockman révèle comment Elon Musk a quitté OpenAI
Fin août 2017, les principaux dirigeants d’OpenAI — alors un petit laboratoire de recherche à but non lucratif — se sont réunis pour discuter de la manière dont ils allaient créer une entité à but luc

Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai

Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai

Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊













