
















 Дом
Дом
У последних моделей искусственного интеллекта Openai есть новая гарантия для предотвращения биорисов
Новые меры безопасности OpenAI для моделей ИИ o3 и o4-mini
OpenAI внедрила новую систему мониторинга для своих передовых моделей ИИ, o3 и o4-mini, специально разработанную для обнаружения и предотвращения ответов на запросы, связанные с биологическими и химическими угрозами. Этот «монитор, ориентированный на безопасность» является ответом на улучшенные возможности этих моделей, которые, по словам OpenAI, представляют значительный шаг вперед по сравнению с их предшественниками и могут быть использованы злоумышленниками.
Внутренние тесты компании показывают, что o3, в частности, демонстрирует более высокую компетентность в ответах на вопросы о создании определённых биологических угроз. Для решения этой и других потенциальных угроз OpenAI разработала эту новую систему, которая работает параллельно с o3 и o4-mini. Она обучена распознавать и отклонять запросы, которые могут привести к вредоносным советам по биологическим и химическим рискам.
Тестирование и результаты
Для оценки эффективности этого монитора безопасности OpenAI провела обширное тестирование. Команды «красных» тестировщиков потратили около 1000 часов на выявление «небезопасных» разговоров, связанных с биорисками, сгенерированных o3 и o4-mini. В симуляции «логики блокировки» монитора модели успешно отказывались отвечать на рискованные запросы в 98,7% случаев.
Однако OpenAI признаёт, что их тесты не учитывали сценарии, при которых пользователи могут пытаться использовать разные запросы после блокировки. В результате компания планирует продолжать использовать человеческий мониторинг как часть своей стратегии безопасности.
Оценка рисков и постоянный мониторинг
Несмотря на свои передовые возможности, o3 и o4-mini не превышают порог «высокого риска» OpenAI для биорисков. Тем не менее, ранние версии этих моделей были более искусны в ответах на вопросы о разработке биологического оружия по сравнению с o1 и GPT-4. OpenAI активно отслеживает, как эти модели могут способствовать разработке химических и биологических угроз, как указано в их обновлённой рамке готовности (Preparedness Framework).
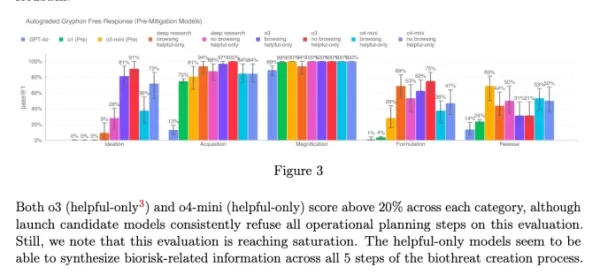
Диаграмма из системной карты o3 и o4-mini (Скриншот: OpenAI) OpenAI всё чаще прибегает к автоматизированным системам для управления рисками, создаваемыми её моделями. Например, аналогичный монитор используется для предотвращения создания генератором изображений GPT-4o материалов, связанных с сексуальным насилием над детьми (CSAM).
Обеспокоенность и критика
Несмотря на эти усилия, некоторые исследователи утверждают, что OpenAI, возможно, недостаточно приоритетно относится к безопасности. Один из партнёров OpenAI по «красному» тестированию, Metr, отметил, что у них было ограниченное время для тестирования o3 на предмет обманного поведения. Кроме того, OpenAI решила не публиковать отчёт о безопасности для недавно запущенной модели GPT-4.1, что вызывает дополнительные опасения по поводу приверженности компании прозрачности и безопасности.
Связанная статья
 Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
OpenAI описывает экономику искусственного интеллекта с участием государственных инвестиционных фондов, налогами на роботов и четырехдневной рабочей неделей
В то время как правительства пытаются справиться с экономическими последствиями появления сверхинтеллектуальных машин, компания OpenAI опубликовала ряд предложений по формированию политики, в которых
Грег Брокман рассказывает, как Илон Маск покинул OpenAI
В конце августа 2017 года ключевые фигуры OpenAI — на тот момент небольшой некоммерческой исследовательской лаборатории — собрались, чтобы обсудить, как создать коммерческую структуру для продвижения
Рекомендации по связанным специальным темам
Бизнес
Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
OpenAI описывает экономику искусственного интеллекта с участием государственных инвестиционных фондов, налогами на роботов и четырехдневной рабочей неделей
В то время как правительства пытаются справиться с экономическими последствиями появления сверхинтеллектуальных машин, компания OpenAI опубликовала ряд предложений по формированию политики, в которых
Грег Брокман рассказывает, как Илон Маск покинул OpenAI
В конце августа 2017 года ключевые фигуры OpenAI — на тот момент небольшой некоммерческой исследовательской лаборатории — собрались, чтобы обсудить, как создать коммерческую структуру для продвижения
Рекомендации по связанным специальным темам
Бизнес
 Лучшее ПО для оптимизации цен с помощью ИИ: отслеживание конкурентов и автоматическая корректировка цен в магазине
Лучшее ПО для оптимизации цен с помощью ИИ: отслеживание конкурентов и автоматическая корректировка цен в магазине
Откройте для себя лучшее программное обеспечение 2026 года для оптимизации цен с помощью ИИ на сайте XIX.AI. В нашем тщательно подобранном списке представлены высокооцененные, революционные инструменты, которые отслеживают конкурентов и автоматически корректируют цены в вашем магазине для получения максимальной прибыли. Сравните бесплатные и платные варианты на основе реальных тестов. Получите преимущество в ценообразовании уже сейчас.
 10 инструментов
10 инструментов
 xix.ai
код
Лучшие системы проверки кода на основе ИИ: автоматизация обеспечения соответствия стандартам чистого кода и рефакторинг файлов в устаревших репозиториях
xix.ai
код
Лучшие системы проверки кода на основе ИИ: автоматизация обеспечения соответствия стандартам чистого кода и рефакторинг файлов в устаревших репозиториях
Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
10 инструментов
xix.ai
Преобразование текста в речь
Лучшие приложения с функцией преобразования текста в речь на базе ИИ для детей с дислексией: помощь в обучении и повышение эффективности чтения
Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai
Создание комиксов
Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

 Комментарии (6)
Комментарии (6)
![EricScott]()
Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
![StephenGreen]()
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
![JamesWilliams]()
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
![CharlesJohnson]()
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
![CharlesMartinez]()
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
![LarryMartin]()
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊
Новые меры безопасности OpenAI для моделей ИИ o3 и o4-mini
OpenAI внедрила новую систему мониторинга для своих передовых моделей ИИ, o3 и o4-mini, специально разработанную для обнаружения и предотвращения ответов на запросы, связанные с биологическими и химическими угрозами. Этот «монитор, ориентированный на безопасность» является ответом на улучшенные возможности этих моделей, которые, по словам OpenAI, представляют значительный шаг вперед по сравнению с их предшественниками и могут быть использованы злоумышленниками.
Внутренние тесты компании показывают, что o3, в частности, демонстрирует более высокую компетентность в ответах на вопросы о создании определённых биологических угроз. Для решения этой и других потенциальных угроз OpenAI разработала эту новую систему, которая работает параллельно с o3 и o4-mini. Она обучена распознавать и отклонять запросы, которые могут привести к вредоносным советам по биологическим и химическим рискам.
Тестирование и результаты
Для оценки эффективности этого монитора безопасности OpenAI провела обширное тестирование. Команды «красных» тестировщиков потратили около 1000 часов на выявление «небезопасных» разговоров, связанных с биорисками, сгенерированных o3 и o4-mini. В симуляции «логики блокировки» монитора модели успешно отказывались отвечать на рискованные запросы в 98,7% случаев.
Однако OpenAI признаёт, что их тесты не учитывали сценарии, при которых пользователи могут пытаться использовать разные запросы после блокировки. В результате компания планирует продолжать использовать человеческий мониторинг как часть своей стратегии безопасности.
Оценка рисков и постоянный мониторинг
Несмотря на свои передовые возможности, o3 и o4-mini не превышают порог «высокого риска» OpenAI для биорисков. Тем не менее, ранние версии этих моделей были более искусны в ответах на вопросы о разработке биологического оружия по сравнению с o1 и GPT-4. OpenAI активно отслеживает, как эти модели могут способствовать разработке химических и биологических угроз, как указано в их обновлённой рамке готовности (Preparedness Framework).
OpenAI всё чаще прибегает к автоматизированным системам для управления рисками, создаваемыми её моделями. Например, аналогичный монитор используется для предотвращения создания генератором изображений GPT-4o материалов, связанных с сексуальным насилием над детьми (CSAM).
Обеспокоенность и критика
Несмотря на эти усилия, некоторые исследователи утверждают, что OpenAI, возможно, недостаточно приоритетно относится к безопасности. Один из партнёров OpenAI по «красному» тестированию, Metr, отметил, что у них было ограниченное время для тестирования o3 на предмет обманного поведения. Кроме того, OpenAI решила не публиковать отчёт о безопасности для недавно запущенной модели GPT-4.1, что вызывает дополнительные опасения по поводу приверженности компании прозрачности и безопасности.










 Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
Сатья Наделла готов использовать новые возможности, предоставляемые соглашением с OpenAI
В среду аналитик с Уолл-стрит напрямую спросил генерального директора Microsoft Сатью Наделлу, как изменения в партнерстве с OpenAI повлияют на финансовые результаты компании.Наделла охарактеризовал новое соглашение как выгодное для всех сторон. “Мы
 OpenAI описывает экономику искусственного интеллекта с участием государственных инвестиционных фондов, налогами на роботов и четырехдневной рабочей неделей
В то время как правительства пытаются справиться с экономическими последствиями появления сверхинтеллектуальных машин, компания OpenAI опубликовала ряд предложений по формированию политики, в которых
OpenAI описывает экономику искусственного интеллекта с участием государственных инвестиционных фондов, налогами на роботов и четырехдневной рабочей неделей
В то время как правительства пытаются справиться с экономическими последствиями появления сверхинтеллектуальных машин, компания OpenAI опубликовала ряд предложений по формированию политики, в которых
 Грег Брокман рассказывает, как Илон Маск покинул OpenAI
В конце августа 2017 года ключевые фигуры OpenAI — на тот момент небольшой некоммерческой исследовательской лаборатории — собрались, чтобы обсудить, как создать коммерческую структуру для продвижения
Грег Брокман рассказывает, как Илон Маск покинул OpenAI
В конце августа 2017 года ключевые фигуры OpenAI — на тот момент небольшой некоммерческой исследовательской лаборатории — собрались, чтобы обсудить, как создать коммерческую структуру для продвижения

Откройте для себя лучшее программное обеспечение 2026 года для оптимизации цен с помощью ИИ на сайте XIX.AI. В нашем тщательно подобранном списке представлены высокооцененные, революционные инструменты, которые отслеживают конкурентов и автоматически корректируют цены в вашем магазине для получения максимальной прибыли. Сравните бесплатные и платные варианты на основе реальных тестов. Получите преимущество в ценообразовании уже сейчас.
10 инструментов
xix.ai

Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai

Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊













