
















 집
집OpenAi의 최신 AI 모델에는 생물을 방지하기위한 새로운 보호 장치가 있습니다.
OpenAI의 AI 모델 o3 및 o4-mini를 위한 새로운 안전 조치
OpenAI는 고급 AI 모델인 o3 및 o4-mini를 위해 새로운 모니터링 시스템을 도입했으며, 이 시스템은 생물학적 및 화학적 위협과 관련된 프롬프트에 대한 응답을 탐지하고 방지하도록 특별히 설계되었습니다. 이 "안전 중심 추론 모니터"는 OpenAI에 따르면 이전 모델들보다 상당한 발전을 이룬 이러한 모델들의 향상된 능력에 대응하며, 악의적인 행위자들에 의해 오용될 가능성을 염두에 둔 것입니다.
회사 내부 벤치마크에 따르면 특히 o3는 특정 생물학적 위협 생성에 관한 질문에 답하는 데 더 높은 숙련도를 보여주었습니다. 이러한 잠재적 위험과 기타 위험을 해결하기 위해 OpenAI는 o3 및 o4-mini와 함께 작동하는 새로운 시스템을 개발했습니다. 이 시스템은 생물학적 및 화학적 위험에 대한 해로운 조언으로 이어질 수 있는 프롬프트를 인식하고 거부하도록 훈련되었습니다.
테스트 및 결과
이 안전 모니터의 효과를 평가하기 위해 OpenAI는 광범위한 테스트를 수행했습니다. 레드 팀은 약 1,000시간 동안 o3 및 o4-mini에서 생성된 "안전하지 않은" 바이오리스크 관련 대화를 식별했습니다. 모니터의 "차단 로직" 시뮬레이션에서 모델은 위험한 프롬프트에 98.7%의 비율로 응답을 거부했습니다.
그러나 OpenAI는 사용자가 차단된 후 다른 프롬프트를 시도할 수 있는 시나리오를 테스트에서 고려하지 않았다고 인정했습니다. 이에 따라 회사는 안전 전략의 일환으로 인간 모니터링을 계속 사용할 계획입니다.
위험 평가 및 지속적인 모니터링
고급 기능에도 불구하고 o3 및 o4-mini는 OpenAI의 "고위험" 바이오리스크 기준을 초과하지 않습니다. 그러나 이러한 모델의 초기 버전은 o1 및 GPT-4에 비해 생물학적 무기 개발에 관한 질문에 답하는 데 더 뛰어났습니다. OpenAI는 업데이트된 준비 프레임워크에 명시된 대로 이러한 모델이 화학 및 생물학적 위협 개발을 촉진할 가능성을 적극적으로 모니터링하고 있습니다.
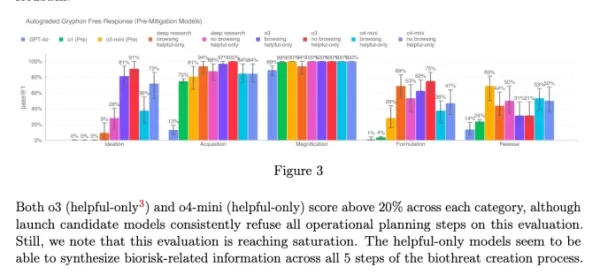
o3 및 o4-mini의 시스템 카드 차트 (스크린샷: OpenAI) OpenAI는 모델이 초래하는 위험을 관리하기 위해 점점 더 자동화된 시스템에 의존하고 있습니다. 예를 들어, 유사한 추론 모니터는 GPT-4o의 이미지 생성기가 아동 성 학대 자료(CSAM)를 생성하지 않도록 방지하는 데 사용됩니다.
우려와 비판
이러한 노력에도 불구하고 일부 연구자들은 OpenAI가 안전을 충분히 우선순위에 두지 않는다고 주장합니다. OpenAI의 레드 팀 파트너 중 하나인 Metr은 o3의 기만적 행동을 테스트할 시간이 제한적이었다고 언급했습니다. 또한 OpenAI는 최근 출시된 GPT-4.1 모델에 대한 안전 보고서를 공개하지 않기로 결정하여 회사의 투명성과 안전에 대한 헌신에 대한 추가적인 우려를 불러일으켰습니다.
관련 기사
 사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
그렉 브록맨이 일론 머스크가 오픈AI를 떠난 경위를 밝힌다
2017년 8월 말, 당시 소규모 비영리 연구소였던 OpenAI의 주요 인사들은 기술을 상용화하고 AGI 달성에 필요한 자금을 조달하기 위해 영리 법인을 설립하는 방안을 논의하기 위해 모였다.일론 머스크는 회사에 대한 전적인 통제권을 요구하고 있었으며, 막 공동 창업자 각자에게 테슬라 모델 3를 선물한 참이었다. 그렉 브록맨 최고기술책임자(CTO)는 머스크
관련 특별 주제 추천
암호
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
그렉 브록맨이 일론 머스크가 오픈AI를 떠난 경위를 밝힌다
2017년 8월 말, 당시 소규모 비영리 연구소였던 OpenAI의 주요 인사들은 기술을 상용화하고 AGI 달성에 필요한 자금을 조달하기 위해 영리 법인을 설립하는 방안을 논의하기 위해 모였다.일론 머스크는 회사에 대한 전적인 통제권을 요구하고 있었으며, 막 공동 창업자 각자에게 테슬라 모델 3를 선물한 참이었다. 그렉 브록맨 최고기술책임자(CTO)는 머스크
관련 특별 주제 추천
암호
 최고의 AI 코드 검토 도구: 깔끔한 코드 준수 자동화 및 레거시 리포지토리 파일 리팩토링
최고의 AI 코드 검토 도구: 깔끔한 코드 준수 자동화 및 레거시 리포지토리 파일 리팩토링
XIX.AI에서 2026년 최고의 AI 코드 검토 도구를 만나보세요. 엄선된 이 목록에는 깔끔한 코드 준수 여부를 자동으로 확인하고 레거시 리포지토리 파일을 리팩토링하는 데 있어 판도를 바꿀 만한 최고 등급의 도구들이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 지금 바로 AI의 경쟁력을 확보하세요.
 10 도구
10 도구
 xix.ai
텍스트 음성 변환
난독증 환자를 위한 최고의 AI 음성 합성 앱: 학생들의 학습 및 독서 효율성 향상
xix.ai
텍스트 음성 변환
난독증 환자를 위한 최고의 AI 음성 합성 앱: 학생들의 학습 및 독서 효율성 향상
난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
10 도구
xix.ai
만화 창작
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

 의견 (6)
0/500
의견 (6)
0/500
![EricScott]()
Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
![StephenGreen]()
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
![JamesWilliams]()
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
![CharlesJohnson]()
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
![CharlesMartinez]()
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
![LarryMartin]()
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊
OpenAI의 AI 모델 o3 및 o4-mini를 위한 새로운 안전 조치
OpenAI는 고급 AI 모델인 o3 및 o4-mini를 위해 새로운 모니터링 시스템을 도입했으며, 이 시스템은 생물학적 및 화학적 위협과 관련된 프롬프트에 대한 응답을 탐지하고 방지하도록 특별히 설계되었습니다. 이 "안전 중심 추론 모니터"는 OpenAI에 따르면 이전 모델들보다 상당한 발전을 이룬 이러한 모델들의 향상된 능력에 대응하며, 악의적인 행위자들에 의해 오용될 가능성을 염두에 둔 것입니다.
회사 내부 벤치마크에 따르면 특히 o3는 특정 생물학적 위협 생성에 관한 질문에 답하는 데 더 높은 숙련도를 보여주었습니다. 이러한 잠재적 위험과 기타 위험을 해결하기 위해 OpenAI는 o3 및 o4-mini와 함께 작동하는 새로운 시스템을 개발했습니다. 이 시스템은 생물학적 및 화학적 위험에 대한 해로운 조언으로 이어질 수 있는 프롬프트를 인식하고 거부하도록 훈련되었습니다.
테스트 및 결과
이 안전 모니터의 효과를 평가하기 위해 OpenAI는 광범위한 테스트를 수행했습니다. 레드 팀은 약 1,000시간 동안 o3 및 o4-mini에서 생성된 "안전하지 않은" 바이오리스크 관련 대화를 식별했습니다. 모니터의 "차단 로직" 시뮬레이션에서 모델은 위험한 프롬프트에 98.7%의 비율로 응답을 거부했습니다.
그러나 OpenAI는 사용자가 차단된 후 다른 프롬프트를 시도할 수 있는 시나리오를 테스트에서 고려하지 않았다고 인정했습니다. 이에 따라 회사는 안전 전략의 일환으로 인간 모니터링을 계속 사용할 계획입니다.
위험 평가 및 지속적인 모니터링
고급 기능에도 불구하고 o3 및 o4-mini는 OpenAI의 "고위험" 바이오리스크 기준을 초과하지 않습니다. 그러나 이러한 모델의 초기 버전은 o1 및 GPT-4에 비해 생물학적 무기 개발에 관한 질문에 답하는 데 더 뛰어났습니다. OpenAI는 업데이트된 준비 프레임워크에 명시된 대로 이러한 모델이 화학 및 생물학적 위협 개발을 촉진할 가능성을 적극적으로 모니터링하고 있습니다.
OpenAI는 모델이 초래하는 위험을 관리하기 위해 점점 더 자동화된 시스템에 의존하고 있습니다. 예를 들어, 유사한 추론 모니터는 GPT-4o의 이미지 생성기가 아동 성 학대 자료(CSAM)를 생성하지 않도록 방지하는 데 사용됩니다.
우려와 비판
이러한 노력에도 불구하고 일부 연구자들은 OpenAI가 안전을 충분히 우선순위에 두지 않는다고 주장합니다. OpenAI의 레드 팀 파트너 중 하나인 Metr은 o3의 기만적 행동을 테스트할 시간이 제한적이었다고 언급했습니다. 또한 OpenAI는 최근 출시된 GPT-4.1 모델에 대한 안전 보고서를 공개하지 않기로 결정하여 회사의 투명성과 안전에 대한 헌신에 대한 추가적인 우려를 불러일으켰습니다.










 사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
 오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
 그렉 브록맨이 일론 머스크가 오픈AI를 떠난 경위를 밝힌다
2017년 8월 말, 당시 소규모 비영리 연구소였던 OpenAI의 주요 인사들은 기술을 상용화하고 AGI 달성에 필요한 자금을 조달하기 위해 영리 법인을 설립하는 방안을 논의하기 위해 모였다.일론 머스크는 회사에 대한 전적인 통제권을 요구하고 있었으며, 막 공동 창업자 각자에게 테슬라 모델 3를 선물한 참이었다. 그렉 브록맨 최고기술책임자(CTO)는 머스크
그렉 브록맨이 일론 머스크가 오픈AI를 떠난 경위를 밝힌다
2017년 8월 말, 당시 소규모 비영리 연구소였던 OpenAI의 주요 인사들은 기술을 상용화하고 AGI 달성에 필요한 자금을 조달하기 위해 영리 법인을 설립하는 방안을 논의하기 위해 모였다.일론 머스크는 회사에 대한 전적인 통제권을 요구하고 있었으며, 막 공동 창업자 각자에게 테슬라 모델 3를 선물한 참이었다. 그렉 브록맨 최고기술책임자(CTO)는 머스크

XIX.AI에서 2026년 최고의 AI 코드 검토 도구를 만나보세요. 엄선된 이 목록에는 깔끔한 코드 준수 여부를 자동으로 확인하고 레거시 리포지토리 파일을 리팩토링하는 데 있어 판도를 바꿀 만한 최고 등급의 도구들이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 지금 바로 AI의 경쟁력을 확보하세요.
10 도구
xix.ai

난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊













