
















 首页
首页Openai的最新AI型号具有新的保障措施,以防止生物风格
OpenAI为AI模型o3和o4-mini推出的新安全措施
OpenAI为其先进AI模型o3和o4-mini引入了新的监控系统,专门设计用于检测和防止回应与生物和化学威胁相关的提示。这种“以安全为重点的推理监控器”是针对这些模型增强功能的回应,据OpenAI称,这些模型相较于其前代产品有了显著提升,可能被恶意行为者滥用。
公司内部基准测试表明,特别是o3在回答关于制造某些生物威胁的问题时表现出更高的熟练度。为了应对这一风险及其他潜在风险,OpenAI开发了这一新系统,该系统与o3和o4-mini一同运行。它被训练来识别并拒绝可能导致有害生物和化学风险建议的提示。
测试与结果
为了评估这一安全监控器的有效性,OpenAI进行了广泛的测试。红队成员花费大约1000小时识别由o3和o4-mini生成的“非安全”生物风险相关对话。在监控器的“阻止逻辑”模拟中,模型成功拒绝了98.7%的风险提示。
然而,OpenAI承认,他们的测试并未考虑用户在被阻止后可能尝试不同提示的场景。因此,公司计划继续将人工监控作为其安全策略的一部分。
风险评估与持续监控
尽管具备先进功能,o3和o4-mini并未超过OpenAI对生物风险的“高风险”阈值。然而,这些模型的早期版本在回答关于开发生物武器的问题时,相比o1和GPT-4表现出更强的能力。OpenAI正在积极监控这些模型可能如何促进化学和生物威胁的发展,正如其更新的准备框架中所概述。
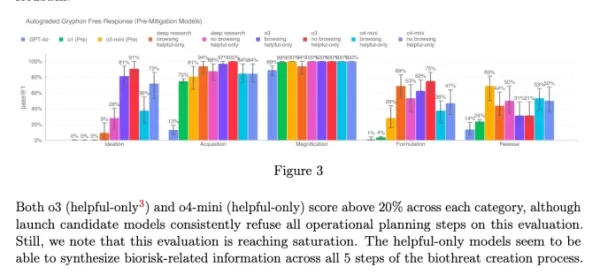
o3和o4-mini系统卡中的图表(截图:OpenAI) OpenAI越来越倾向于使用自动化系统来管理其模型带来的风险。例如,类似的推理监控器被用于防止GPT-4o的图像生成器产生儿童性虐待材料(CSAM)。
担忧与批评
尽管做出了这些努力,一些研究人员认为OpenAI可能未足够重视安全。OpenAI的红队合作伙伴之一Metr指出,他们测试o3的欺骗行为时间有限。此外,OpenAI选择不为其最近推出的GPT-4.1模型发布安全报告,这进一步引发了对其透明度和安全承诺的担忧。
相关文章
 萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
格雷格·布罗克曼揭秘埃隆·马斯克如何离开OpenAI
2017年8月下旬,OpenAI(当时还是一家小型非营利研究实验室)的核心成员召开会议,商讨如何成立一家营利性实体,以实现技术的商业化,并筹集实现通用人工智能(AGI)所需的资金。埃隆·马斯克要求全面掌控公司,并刚刚向每位联合创始人赠送了一辆特斯拉Model 3。首席技术官格雷格·布罗克曼表示,他认为这是马斯克试图收买人心,当时马斯克和萨姆·阿尔特曼正就各自对公司未来愿景的支持展开角逐。 Open
相关专题推荐
写作
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
格雷格·布罗克曼揭秘埃隆·马斯克如何离开OpenAI
2017年8月下旬,OpenAI(当时还是一家小型非营利研究实验室)的核心成员召开会议,商讨如何成立一家营利性实体,以实现技术的商业化,并筹集实现通用人工智能(AGI)所需的资金。埃隆·马斯克要求全面掌控公司,并刚刚向每位联合创始人赠送了一辆特斯拉Model 3。首席技术官格雷格·布罗克曼表示,他认为这是马斯克试图收买人心,当时马斯克和萨姆·阿尔特曼正就各自对公司未来愿景的支持展开角逐。 Open
相关专题推荐
写作
 顶尖 AI 角色设定生成器:生成一致的角色动机与致命缺陷
顶尖 AI 角色设定生成器:生成一致的角色动机与致命缺陷
探索2026年最优秀的AI人物设定生成工具,助您塑造鲜活立体的角色。XIX.AI精心筛选的这份清单汇集了广受好评、颠覆传统的工具,能够生成具有内在逻辑的动机和致命缺陷。通过实际测试对比免费与付费选项。立即释放您的叙事潜能。
 10 个工具
10 个工具
 xix.ai
商业
顶级 AI 定价优化软件:追踪竞争对手并自动调整店铺价格
xix.ai
商业
顶级 AI 定价优化软件:追踪竞争对手并自动调整店铺价格
在 XIX.AI 上探索 2026 年最佳 AI 定价优化软件。我们精心挑选的清单汇集了备受好评、具有颠覆性意义的工具,这些工具不仅能追踪竞争对手,还能自动调整您的店铺价格,从而实现利润最大化。通过实际测试对比免费与付费选项。立即掌握您的定价优势。
10 个工具
xix.ai
代码
最佳 AI 代码审查工具:自动确保代码符合规范,并重构遗留代码库文件
在 XIX.AI 上探索 2026 年最佳 AI 代码审查工具。我们的精选列表汇集了备受好评、具有颠覆性的工具,可自动确保代码规范并重构遗留代码库文件。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即开启您的 AI 优势。
10 个工具
xix.ai
文字转语音
专为阅读障碍设计的顶级AI语音合成应用:助力学生提升学习与阅读效率
探索2026年最新精选的高评分AI语音合成(TTS)应用,专为阅读障碍者提供支持。我们的专家评级对比了免费与付费工具,重点介绍了能够提升阅读效率和学习效果的强大功能。探索这些必试的、具有革命性意义的解决方案,释放学生的潜能。立即访问XIX.AI,开启您的探索之旅。
10 个工具
xix.ai
漫画创作
少年漫画顶级AI生成器:打造高能动作场面与特效
在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

 评论 (6)
0/500
评论 (6)
0/500
![EricScott]()
Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
![StephenGreen]()
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
![JamesWilliams]()
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
![CharlesJohnson]()
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
![CharlesMartinez]()
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
![LarryMartin]()
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊
OpenAI为AI模型o3和o4-mini推出的新安全措施
OpenAI为其先进AI模型o3和o4-mini引入了新的监控系统,专门设计用于检测和防止回应与生物和化学威胁相关的提示。这种“以安全为重点的推理监控器”是针对这些模型增强功能的回应,据OpenAI称,这些模型相较于其前代产品有了显著提升,可能被恶意行为者滥用。
公司内部基准测试表明,特别是o3在回答关于制造某些生物威胁的问题时表现出更高的熟练度。为了应对这一风险及其他潜在风险,OpenAI开发了这一新系统,该系统与o3和o4-mini一同运行。它被训练来识别并拒绝可能导致有害生物和化学风险建议的提示。
测试与结果
为了评估这一安全监控器的有效性,OpenAI进行了广泛的测试。红队成员花费大约1000小时识别由o3和o4-mini生成的“非安全”生物风险相关对话。在监控器的“阻止逻辑”模拟中,模型成功拒绝了98.7%的风险提示。
然而,OpenAI承认,他们的测试并未考虑用户在被阻止后可能尝试不同提示的场景。因此,公司计划继续将人工监控作为其安全策略的一部分。
风险评估与持续监控
尽管具备先进功能,o3和o4-mini并未超过OpenAI对生物风险的“高风险”阈值。然而,这些模型的早期版本在回答关于开发生物武器的问题时,相比o1和GPT-4表现出更强的能力。OpenAI正在积极监控这些模型可能如何促进化学和生物威胁的发展,正如其更新的准备框架中所概述。
OpenAI越来越倾向于使用自动化系统来管理其模型带来的风险。例如,类似的推理监控器被用于防止GPT-4o的图像生成器产生儿童性虐待材料(CSAM)。
担忧与批评
尽管做出了这些努力,一些研究人员认为OpenAI可能未足够重视安全。OpenAI的红队合作伙伴之一Metr指出,他们测试o3的欺骗行为时间有限。此外,OpenAI选择不为其最近推出的GPT-4.1模型发布安全报告,这进一步引发了对其透明度和安全承诺的担忧。










 萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
 OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
 格雷格·布罗克曼揭秘埃隆·马斯克如何离开OpenAI
2017年8月下旬,OpenAI(当时还是一家小型非营利研究实验室)的核心成员召开会议,商讨如何成立一家营利性实体,以实现技术的商业化,并筹集实现通用人工智能(AGI)所需的资金。埃隆·马斯克要求全面掌控公司,并刚刚向每位联合创始人赠送了一辆特斯拉Model 3。首席技术官格雷格·布罗克曼表示,他认为这是马斯克试图收买人心,当时马斯克和萨姆·阿尔特曼正就各自对公司未来愿景的支持展开角逐。 Open
格雷格·布罗克曼揭秘埃隆·马斯克如何离开OpenAI
2017年8月下旬,OpenAI(当时还是一家小型非营利研究实验室)的核心成员召开会议,商讨如何成立一家营利性实体,以实现技术的商业化,并筹集实现通用人工智能(AGI)所需的资金。埃隆·马斯克要求全面掌控公司,并刚刚向每位联合创始人赠送了一辆特斯拉Model 3。首席技术官格雷格·布罗克曼表示,他认为这是马斯克试图收买人心,当时马斯克和萨姆·阿尔特曼正就各自对公司未来愿景的支持展开角逐。 Open

探索2026年最优秀的AI人物设定生成工具,助您塑造鲜活立体的角色。XIX.AI精心筛选的这份清单汇集了广受好评、颠覆传统的工具,能够生成具有内在逻辑的动机和致命缺陷。通过实际测试对比免费与付费选项。立即释放您的叙事潜能。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最佳 AI 定价优化软件。我们精心挑选的清单汇集了备受好评、具有颠覆性意义的工具,这些工具不仅能追踪竞争对手,还能自动调整您的店铺价格,从而实现利润最大化。通过实际测试对比免费与付费选项。立即掌握您的定价优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最佳 AI 代码审查工具。我们的精选列表汇集了备受好评、具有颠覆性的工具,可自动确保代码规范并重构遗留代码库文件。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即开启您的 AI 优势。
10 个工具
xix.ai

探索2026年最新精选的高评分AI语音合成(TTS)应用,专为阅读障碍者提供支持。我们的专家评级对比了免费与付费工具,重点介绍了能够提升阅读效率和学习效果的强大功能。探索这些必试的、具有革命性意义的解决方案,释放学生的潜能。立即访问XIX.AI,开启您的探索之旅。
10 个工具
xix.ai

在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊













