
















 Lar
Lar
Os mais recentes modelos de IA do OpenAI têm uma nova salvaguarda para prevenir biorisks
Novas Medidas de Segurança da OpenAI para Modelos de IA o3 e o4-mini
A OpenAI introduziu um novo sistema de monitoramento para seus modelos de IA avançados, o3 e o4-mini, projetado especificamente para detectar e prevenir respostas a prompts relacionados a ameaças biológicas e químicas. Este "monitor de raciocínio focado em segurança" é uma resposta às capacidades aprimoradas desses modelos, que, segundo a OpenAI, representam um avanço significativo em relação aos seus antecessores e poderiam ser mal utilizados por agentes mal-intencionados.
Os benchmarks internos da empresa indicam que o o3, em particular, demonstrou maior proficiência em responder perguntas sobre a criação de certas ameaças biológicas. Para abordar isso e outros riscos potenciais, a OpenAI desenvolveu esse novo sistema, que opera ao lado do o3 e o4-mini. Ele é treinado para reconhecer e rejeitar prompts que poderiam levar a conselhos prejudiciais sobre riscos biológicos e químicos.
Testes e Resultados
Para avaliar a eficácia desse monitor de segurança, a OpenAI conduziu testes extensivos. Equipes de teste gastaram aproximadamente 1.000 horas identificando conversas relacionadas a "riscos biológicos inseguros" geradas pelo o3 e o4-mini. Em uma simulação da "lógica de bloqueio" do monitor, os modelos conseguiram recusar responder a prompts arriscados em 98,7% das vezes.
No entanto, a OpenAI admite que seu teste não considerou cenários em que os usuários poderiam tentar prompts diferentes após serem bloqueados. Como resultado, a empresa planeja continuar usando monitoramento humano como parte de sua estratégia de segurança.
Avaliação de Riscos e Monitoramento Contínuo
Apesar de suas capacidades avançadas, o o3 e o o4-mini não excedem o limiar de "alto risco" da OpenAI para riscos biológicos. No entanto, versões iniciais desses modelos foram mais adeptas em responder perguntas sobre o desenvolvimento de armas biológicas em comparação com o o1 e o GPT-4. A OpenAI está monitorando ativamente como esses modelos podem facilitar o desenvolvimento de ameaças químicas e biológicas, conforme delineado em seu Framework de Preparação atualizado.
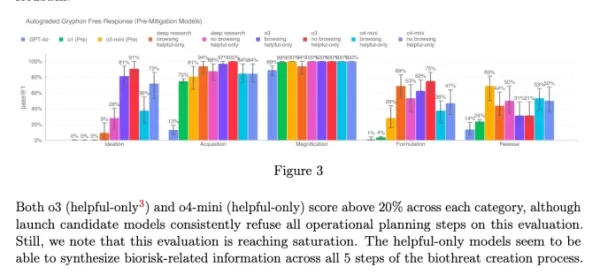
Gráfico do cartão de sistema do o3 e o4-mini (Captura de tela: OpenAI) A OpenAI está cada vez mais recorrendo a sistemas automatizados para gerenciar os riscos apresentados por seus modelos. Por exemplo, um monitor de raciocínio semelhante é usado para impedir que o gerador de imagens do GPT-4o produza material de abuso sexual infantil (CSAM).
Preocupações e Críticas
Apesar desses esforços, alguns pesquisadores argumentam que a OpenAI pode não estar priorizando a segurança o suficiente. Um dos parceiros de teste da OpenAI, Metr, observou que teve tempo limitado para testar o o3 quanto a comportamentos enganosos. Além disso, a OpenAI optou por não divulgar um relatório de segurança para seu modelo GPT-4.1 recentemente lançado, levantando mais preocupações sobre o compromisso da empresa com transparência e segurança.
Artigo relacionado
 Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
Greg Brockman revela como Elon Musk deixou a OpenAI
No final de agosto de 2017, figuras-chave da OpenAI — na época, um pequeno laboratório de pesquisa sem fins lucrativos — se reuniram para discutir como criariam uma entidade com fins lucrativos para c
Recomendações de tópicos especiais relacionados
código
Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
Greg Brockman revela como Elon Musk deixou a OpenAI
No final de agosto de 2017, figuras-chave da OpenAI — na época, um pequeno laboratório de pesquisa sem fins lucrativos — se reuniram para discutir como criariam uma entidade com fins lucrativos para c
Recomendações de tópicos especiais relacionados
código
 Os melhores revisores de código com IA: automatize a conformidade com o código limpo e refatore arquivos de repositórios legados
Os melhores revisores de código com IA: automatize a conformidade com o código limpo e refatore arquivos de repositórios legados
Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
 10 ferramentas
10 ferramentas
 xix.ai
Conversão de texto para fala
Os melhores aplicativos de TTS com IA para dislexia: apoio à aprendizagem e à eficiência na leitura para alunos
xix.ai
Conversão de texto para fala
Os melhores aplicativos de TTS com IA para dislexia: apoio à aprendizagem e à eficiência na leitura para alunos
Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai
Criação de quadrinhos
Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

 Comentários (6)
Comentários (6)
![EricScott]()
Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
![StephenGreen]()
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
![JamesWilliams]()
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
![CharlesJohnson]()
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
![CharlesMartinez]()
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
![LarryMartin]()
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊
Novas Medidas de Segurança da OpenAI para Modelos de IA o3 e o4-mini
A OpenAI introduziu um novo sistema de monitoramento para seus modelos de IA avançados, o3 e o4-mini, projetado especificamente para detectar e prevenir respostas a prompts relacionados a ameaças biológicas e químicas. Este "monitor de raciocínio focado em segurança" é uma resposta às capacidades aprimoradas desses modelos, que, segundo a OpenAI, representam um avanço significativo em relação aos seus antecessores e poderiam ser mal utilizados por agentes mal-intencionados.
Os benchmarks internos da empresa indicam que o o3, em particular, demonstrou maior proficiência em responder perguntas sobre a criação de certas ameaças biológicas. Para abordar isso e outros riscos potenciais, a OpenAI desenvolveu esse novo sistema, que opera ao lado do o3 e o4-mini. Ele é treinado para reconhecer e rejeitar prompts que poderiam levar a conselhos prejudiciais sobre riscos biológicos e químicos.
Testes e Resultados
Para avaliar a eficácia desse monitor de segurança, a OpenAI conduziu testes extensivos. Equipes de teste gastaram aproximadamente 1.000 horas identificando conversas relacionadas a "riscos biológicos inseguros" geradas pelo o3 e o4-mini. Em uma simulação da "lógica de bloqueio" do monitor, os modelos conseguiram recusar responder a prompts arriscados em 98,7% das vezes.
No entanto, a OpenAI admite que seu teste não considerou cenários em que os usuários poderiam tentar prompts diferentes após serem bloqueados. Como resultado, a empresa planeja continuar usando monitoramento humano como parte de sua estratégia de segurança.
Avaliação de Riscos e Monitoramento Contínuo
Apesar de suas capacidades avançadas, o o3 e o o4-mini não excedem o limiar de "alto risco" da OpenAI para riscos biológicos. No entanto, versões iniciais desses modelos foram mais adeptas em responder perguntas sobre o desenvolvimento de armas biológicas em comparação com o o1 e o GPT-4. A OpenAI está monitorando ativamente como esses modelos podem facilitar o desenvolvimento de ameaças químicas e biológicas, conforme delineado em seu Framework de Preparação atualizado.
A OpenAI está cada vez mais recorrendo a sistemas automatizados para gerenciar os riscos apresentados por seus modelos. Por exemplo, um monitor de raciocínio semelhante é usado para impedir que o gerador de imagens do GPT-4o produza material de abuso sexual infantil (CSAM).
Preocupações e Críticas
Apesar desses esforços, alguns pesquisadores argumentam que a OpenAI pode não estar priorizando a segurança o suficiente. Um dos parceiros de teste da OpenAI, Metr, observou que teve tempo limitado para testar o o3 quanto a comportamentos enganosos. Além disso, a OpenAI optou por não divulgar um relatório de segurança para seu modelo GPT-4.1 recentemente lançado, levantando mais preocupações sobre o compromisso da empresa com transparência e segurança.










 Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
 A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
 Greg Brockman revela como Elon Musk deixou a OpenAI
No final de agosto de 2017, figuras-chave da OpenAI — na época, um pequeno laboratório de pesquisa sem fins lucrativos — se reuniram para discutir como criariam uma entidade com fins lucrativos para c
Greg Brockman revela como Elon Musk deixou a OpenAI
No final de agosto de 2017, figuras-chave da OpenAI — na época, um pequeno laboratório de pesquisa sem fins lucrativos — se reuniram para discutir como criariam uma entidade com fins lucrativos para c

Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai

Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊













