
















 Hogar
Hogar
Los últimos modelos de IA de OpenAI tienen una nueva salvaguardia para evitar biorisks
Nuevas medidas de seguridad de OpenAI para los modelos de IA o3 y o4-mini
OpenAI ha introducido un nuevo sistema de monitoreo para sus modelos de IA avanzados, o3 y o4-mini, diseñado específicamente para detectar y prevenir respuestas a prompts relacionados con amenazas biológicas y químicas. Este "monitor de razonamiento enfocado en la seguridad" es una respuesta a las capacidades mejoradas de estos modelos, que, según OpenAI, representan un avance significativo respecto a sus predecesores y podrían ser utilizados de manera indebida por actores malintencionados.
Los puntos de referencia internos de la compañía indican que o3, en particular, ha mostrado una mayor competencia en responder preguntas sobre la creación de ciertas amenazas biológicas. Para abordar este y otros riesgos potenciales, OpenAI desarrolló este nuevo sistema, que opera junto con o3 y o4-mini. Está entrenado para reconocer y rechazar prompts que podrían conducir a consejos perjudiciales sobre riesgos biológicos y químicos.
Pruebas y resultados
Para evaluar la efectividad de este monitor de seguridad, OpenAI realizó pruebas exhaustivas. Los equipos de red teaming dedicaron aproximadamente 1,000 horas a identificar conversaciones relacionadas con "riesgos biល>biológicos no seguros generadas por o3 y o4-mini. En una simulación de la "lógica de bloqueo" del monitor, los modelos lograron rechazar responder a prompts arriesgados el 98.7% de las veces.
Sin embargo, OpenAI admite que su prueba no consideró escenarios en los que los usuarios podrían intentar diferentes prompts después de ser bloqueados. Como resultado, la compañía planea seguir utilizando el monitoreo humano como parte de su estrategia de seguridad.
Evaluación de riesgos y monitoreo continuo
A pesar de sus capacidades avanzadas, o3 y o4-mini no superan el umbral de "alto riesgo" de OpenAI para biorriesgos. Sin embargo, las versiones iniciales de estos modelos eran más hábiles para responder preguntas sobre el desarrollo de armas biológicas en comparación con o1 y GPT-4. OpenAI está monitoreando activamente cómo estos modelos podrían facilitar el desarrollo de amenazas químicas y biológicas, como se detalla en su Marco de Preparación actualizado.
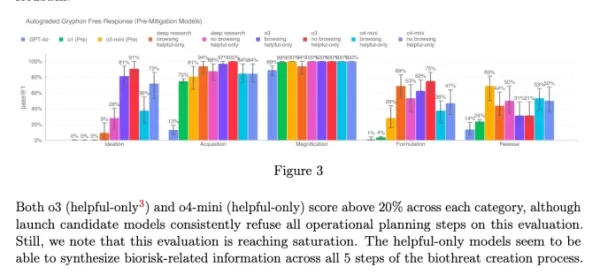
Gráfico de la tarjeta de sistema de o3 y o4-mini (Captura de pantalla: OpenAI) OpenAI está recurriendo cada vez más a sistemas automatizados para gestionar los riesgos que presentan sus modelos. Por ejemplo, un monitor de razonamiento similar se utiliza para evitar que el generador de imágenes de GPT-4o produzca material de abuso sexual infantil (CSAM).
Preocupaciones y críticas
A pesar de estos esfuerzos, algunos investigadores argumentan que OpenAI podría no estar priorizando suficientemente la seguridad. Uno de los socios de red teaming de OpenAI, Metr, señaló que tuvieron un tiempo limitado para probar o3 en busca de comportamientos engañosos. Además, OpenAI decidió no publicar un informe de seguridad para su modelo GPT-4.1 recientemente lanzado, lo que genera más preocupaciones sobre el compromiso de la compañía con la transparencia y la seguridad.
Artículo relacionado
 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati
Recomendaciones de temas especiales relacionados
Negocio
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati
Recomendaciones de temas especiales relacionados
Negocio
 El mejor software de optimización de precios con IA: realiza un seguimiento de la competencia y ajusta automáticamente los precios de la tienda
El mejor software de optimización de precios con IA: realiza un seguimiento de la competencia y ajusta automáticamente los precios de la tienda
Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
 10 herramientas
10 herramientas
 xix.ai
código
Los mejores revisores de código basados en IA: automatiza el cumplimiento de las normas de código limpio y refactoriza los archivos de repositorios heredados
xix.ai
código
Los mejores revisores de código basados en IA: automatiza el cumplimiento de las normas de código limpio y refactoriza los archivos de repositorios heredados
Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai
Texto a voz
Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai
Creación de cómics
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

 comentario (6)
0/500
comentario (6)
0/500
![EricScott]()
Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
![StephenGreen]()
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
![JamesWilliams]()
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
![CharlesJohnson]()
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
![CharlesMartinez]()
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
![LarryMartin]()
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊
Nuevas medidas de seguridad de OpenAI para los modelos de IA o3 y o4-mini
OpenAI ha introducido un nuevo sistema de monitoreo para sus modelos de IA avanzados, o3 y o4-mini, diseñado específicamente para detectar y prevenir respuestas a prompts relacionados con amenazas biológicas y químicas. Este "monitor de razonamiento enfocado en la seguridad" es una respuesta a las capacidades mejoradas de estos modelos, que, según OpenAI, representan un avance significativo respecto a sus predecesores y podrían ser utilizados de manera indebida por actores malintencionados.
Los puntos de referencia internos de la compañía indican que o3, en particular, ha mostrado una mayor competencia en responder preguntas sobre la creación de ciertas amenazas biológicas. Para abordar este y otros riesgos potenciales, OpenAI desarrolló este nuevo sistema, que opera junto con o3 y o4-mini. Está entrenado para reconocer y rechazar prompts que podrían conducir a consejos perjudiciales sobre riesgos biológicos y químicos.
Pruebas y resultados
Para evaluar la efectividad de este monitor de seguridad, OpenAI realizó pruebas exhaustivas. Los equipos de red teaming dedicaron aproximadamente 1,000 horas a identificar conversaciones relacionadas con "riesgos biល>biológicos no seguros generadas por o3 y o4-mini. En una simulación de la "lógica de bloqueo" del monitor, los modelos lograron rechazar responder a prompts arriesgados el 98.7% de las veces.
Sin embargo, OpenAI admite que su prueba no consideró escenarios en los que los usuarios podrían intentar diferentes prompts después de ser bloqueados. Como resultado, la compañía planea seguir utilizando el monitoreo humano como parte de su estrategia de seguridad.
Evaluación de riesgos y monitoreo continuo
A pesar de sus capacidades avanzadas, o3 y o4-mini no superan el umbral de "alto riesgo" de OpenAI para biorriesgos. Sin embargo, las versiones iniciales de estos modelos eran más hábiles para responder preguntas sobre el desarrollo de armas biológicas en comparación con o1 y GPT-4. OpenAI está monitoreando activamente cómo estos modelos podrían facilitar el desarrollo de amenazas químicas y biológicas, como se detalla en su Marco de Preparación actualizado.
OpenAI está recurriendo cada vez más a sistemas automatizados para gestionar los riesgos que presentan sus modelos. Por ejemplo, un monitor de razonamiento similar se utiliza para evitar que el generador de imágenes de GPT-4o produzca material de abuso sexual infantil (CSAM).
Preocupaciones y críticas
A pesar de estos esfuerzos, algunos investigadores argumentan que OpenAI podría no estar priorizando suficientemente la seguridad. Uno de los socios de red teaming de OpenAI, Metr, señaló que tuvieron un tiempo limitado para probar o3 en busca de comportamientos engañosos. Además, OpenAI decidió no publicar un informe de seguridad para su modelo GPT-4.1 recientemente lanzado, lo que genera más preocupaciones sobre el compromiso de la compañía con la transparencia y la seguridad.










 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
 OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
 Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati
Greg Brockman desvela cómo Elon Musk abandonó OpenAI
A finales de agosto de 2017, las figuras clave de OpenAI —por entonces un pequeño laboratorio de investigación sin ánimo de lucro— se reunieron para debatir cómo crearían una entidad con fines lucrati

Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai

Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai

Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊













