
















 Heim
Heim
Die neuesten KI -Modelle von Openai haben einen neuen Schutz, um Bioritäten zu verhindern
Neue Sicherheitsmaßnahmen von OpenAI für die KI-Modelle o3 und o4-mini
OpenAI hat ein neues Überwachungssystem für seine fortschrittlichen KI-Modelle o3 und o4-mini eingeführt, das speziell darauf ausgelegt ist, Antworten auf Eingaben zu erkennen und zu verhindern, die mit biologischen und chemischen Bedrohungen in Verbindung stehen. Dieser „sicherheitsorientierte Reasoning-Monitor“ ist eine Reaktion auf die erweiterten Fähigkeiten dieser Modelle, die laut OpenAI einen bedeutenden Fortschritt gegenüber ihren Vorgängern darstellen und von böswilligen Akteuren missbraucht werden könnten.
Die internen Benchmarks des Unternehmens zeigen, dass insbesondere o3 eine höhere Kompetenz bei der Beantwortung von Fragen zur Herstellung bestimmter biologischer Bedrohungen aufweist. Um dieses und andere potenzielle Risiken anzugehen, hat OpenAI dieses neue System entwickelt, das parallel zu o3 und o4-mini arbeitet. Es ist darauf trainiert, Eingaben zu erkennen und abzulehnen, die zu schädlichen Ratschlägen in Bezug auf biologische und chemische Risiken führen könnten.
Testen und Ergebnisse
Um die Wirksamkeit dieses Sicherheitsmonitors zu bewerten, führte OpenAI umfangreiche Tests durch. Red-Teamer verbrachten etwa 1.000 Stunden damit, „unsichere“ Gespräche zu Biorisiken zu identifizieren, die von o3 und o4-mini generiert wurden. In einer Simulation der „Blockierlogik“ des Monitors lehnten die Modelle in 98,7 % der Fälle riskante Eingaben erfolgreich ab.
OpenAI gibt jedoch zu, dass der Test Szenarien, in denen Nutzer nach einer Blockierung andere Eingaben versuchen könnten, nicht berücksichtigt hat. Daher plant das Unternehmen, weiterhin menschliche Überwachung als Teil seiner Sicherheitsstrategie einzusetzen.
Risikobewertung und fortlaufende Überwachung
Trotz ihrer fortschrittlichen Fähigkeiten überschreiten o3 und o4-mini nicht die „hohe Risiko“-Schwelle von OpenAI für Biorisiken. Dennoch waren frühe Versionen dieser Modelle im Vergleich zu o1 und GPT-4 besser in der Lage, Fragen zur Entwicklung biologischer Waffen zu beantworten. OpenAI überwacht aktiv, wie diese Modelle die Entwicklung chemischer und biologischer Bedrohungen erleichtern könnten, wie im aktualisierten Preparedness Framework beschrieben.
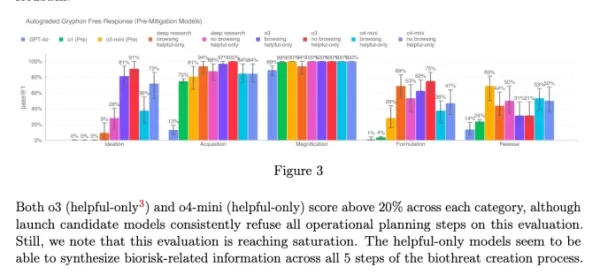
Diagramm aus der Systemkarte von o3 und o4-mini (Screenshot: OpenAI) OpenAI setzt zunehmend auf automatisierte Systeme, um die Risiken zu managen, die von seinen Modellen ausgehen. Zum Beispiel wird ein ähnlicher Reasoning-Monitor verwendet, um zu verhindern, dass der Bildgenerator von GPT-4o Material zu sexuellem Kindesmissbrauch (CSAM) erstellt.
Bedenken und Kritik
Trotz dieser Bemühungen argumentieren einige Forscher, dass OpenAI der Sicherheit möglicherweise nicht genügend Priorität einräumt. Einer der Red-Teaming-Partner von OpenAI, Metr, stellte fest, dass sie nur begrenzte Zeit hatten, um o3 auf täuschendes Verhalten zu testen. Zudem entschied sich OpenAI, keinen Sicherheitsbericht für das kürzlich eingeführte GPT-4.1-Modell zu veröffentlichen, was weitere Bedenken hinsichtlich des Engagements des Unternehmens für Transparenz und Sicherheit aufwirft.
Verwandter Artikel
 Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Empfehlungen zu verwandten Spezialthemen
Text-zu-Sprache
Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Empfehlungen zu verwandten Spezialthemen
Text-zu-Sprache
 Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
 10 Tools
10 Tools
 xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai
Geschäft
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

 Kommentare (6)
Kommentare (6)
![EricScott]()
Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
![StephenGreen]()
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
![JamesWilliams]()
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
![CharlesJohnson]()
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
![CharlesMartinez]()
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
![LarryMartin]()
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊
Neue Sicherheitsmaßnahmen von OpenAI für die KI-Modelle o3 und o4-mini
OpenAI hat ein neues Überwachungssystem für seine fortschrittlichen KI-Modelle o3 und o4-mini eingeführt, das speziell darauf ausgelegt ist, Antworten auf Eingaben zu erkennen und zu verhindern, die mit biologischen und chemischen Bedrohungen in Verbindung stehen. Dieser „sicherheitsorientierte Reasoning-Monitor“ ist eine Reaktion auf die erweiterten Fähigkeiten dieser Modelle, die laut OpenAI einen bedeutenden Fortschritt gegenüber ihren Vorgängern darstellen und von böswilligen Akteuren missbraucht werden könnten.
Die internen Benchmarks des Unternehmens zeigen, dass insbesondere o3 eine höhere Kompetenz bei der Beantwortung von Fragen zur Herstellung bestimmter biologischer Bedrohungen aufweist. Um dieses und andere potenzielle Risiken anzugehen, hat OpenAI dieses neue System entwickelt, das parallel zu o3 und o4-mini arbeitet. Es ist darauf trainiert, Eingaben zu erkennen und abzulehnen, die zu schädlichen Ratschlägen in Bezug auf biologische und chemische Risiken führen könnten.
Testen und Ergebnisse
Um die Wirksamkeit dieses Sicherheitsmonitors zu bewerten, führte OpenAI umfangreiche Tests durch. Red-Teamer verbrachten etwa 1.000 Stunden damit, „unsichere“ Gespräche zu Biorisiken zu identifizieren, die von o3 und o4-mini generiert wurden. In einer Simulation der „Blockierlogik“ des Monitors lehnten die Modelle in 98,7 % der Fälle riskante Eingaben erfolgreich ab.
OpenAI gibt jedoch zu, dass der Test Szenarien, in denen Nutzer nach einer Blockierung andere Eingaben versuchen könnten, nicht berücksichtigt hat. Daher plant das Unternehmen, weiterhin menschliche Überwachung als Teil seiner Sicherheitsstrategie einzusetzen.
Risikobewertung und fortlaufende Überwachung
Trotz ihrer fortschrittlichen Fähigkeiten überschreiten o3 und o4-mini nicht die „hohe Risiko“-Schwelle von OpenAI für Biorisiken. Dennoch waren frühe Versionen dieser Modelle im Vergleich zu o1 und GPT-4 besser in der Lage, Fragen zur Entwicklung biologischer Waffen zu beantworten. OpenAI überwacht aktiv, wie diese Modelle die Entwicklung chemischer und biologischer Bedrohungen erleichtern könnten, wie im aktualisierten Preparedness Framework beschrieben.
OpenAI setzt zunehmend auf automatisierte Systeme, um die Risiken zu managen, die von seinen Modellen ausgehen. Zum Beispiel wird ein ähnlicher Reasoning-Monitor verwendet, um zu verhindern, dass der Bildgenerator von GPT-4o Material zu sexuellem Kindesmissbrauch (CSAM) erstellt.
Bedenken und Kritik
Trotz dieser Bemühungen argumentieren einige Forscher, dass OpenAI der Sicherheit möglicherweise nicht genügend Priorität einräumt. Einer der Red-Teaming-Partner von OpenAI, Metr, stellte fest, dass sie nur begrenzte Zeit hatten, um o3 auf täuschendes Verhalten zu testen. Zudem entschied sich OpenAI, keinen Sicherheitsbericht für das kürzlich eingeführte GPT-4.1-Modell zu veröffentlichen, was weitere Bedenken hinsichtlich des Engagements des Unternehmens für Transparenz und Sicherheit aufwirft.










 Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
 OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
 Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um
Greg Brockman enthüllt, wie Elon Musk OpenAI verlassen hat
Ende August 2017 trafen sich führende Persönlichkeiten von OpenAI – damals ein kleines gemeinnütziges Forschungslabor –, um zu erörtern, wie sie ein gewinnorientiertes Unternehmen gründen könnten, um

Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊













