
















 Home
HomeOpenAI’s latest AI models have a new safeguard to prevent biorisks
OpenAI's New Safety Measures for AI Models o3 and o4-mini
OpenAI has introduced a new monitoring system for its advanced AI models, o3 and o4-mini, specifically designed to detect and prevent responses to prompts related to biological and chemical threats. This "safety-focused reasoning monitor" is a response to the enhanced capabilities of these models, which, according to OpenAI, represent a significant step up from their predecessors and could be misused by malicious actors.
The company's internal benchmarks indicate that o3, in particular, has shown a higher proficiency in answering questions about creating certain biological threats. To address this and other potential risks, OpenAI developed this new system, which operates alongside o3 and o4-mini. It's trained to recognize and reject prompts that could lead to harmful advice on biological and chemical risks.
Testing and Results
To gauge the effectiveness of this safety monitor, OpenAI conducted extensive testing. Red teamers spent approximately 1,000 hours identifying "unsafe" biorisk-related conversations generated by o3 and o4-mini. In a simulation of the monitor's "blocking logic," the models successfully declined to respond to risky prompts 98.7% of the time.
However, OpenAI admits that their test did not consider scenarios where users might attempt different prompts after being blocked. As a result, the company plans to continue using human monitoring as part of its safety strategy.
Risk Assessment and Ongoing Monitoring
Despite their advanced capabilities, o3 and o4-mini do not exceed OpenAI's "high risk" threshold for biorisks. Yet, early versions of these models were more adept at answering questions about developing biological weapons compared to o1 and GPT-4. OpenAI is actively monitoring how these models might facilitate the development of chemical and biological threats, as outlined in their updated Preparedness Framework.
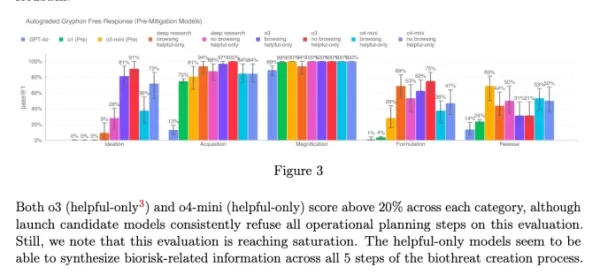
Chart from o3 and o4-mini’s system card (Screenshot: OpenAI)
OpenAI is increasingly turning to automated systems to manage the risks posed by its models. For instance, a similar reasoning monitor is used to prevent GPT-4o's image generator from producing child sexual abuse material (CSAM).
Concerns and Criticisms
Despite these efforts, some researchers argue that OpenAI may not be prioritizing safety enough. One of OpenAI's red-teaming partners, Metr, noted they had limited time to test o3 for deceptive behavior. Additionally, OpenAI chose not to release a safety report for its recently launched GPT-4.1 model, raising further concerns about the company's commitment to transparency and safety.
Related article
 Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Greg Brockman reveals how Elon Musk departed OpenAI
In late August 2017, key figures at OpenAI—then a small nonprofit research lab—met to discuss how they would establish a for-profit entity to commercialize their technology and raise the capital needed to achieve AGI.Elon Musk was demanding full cont
Related Special Topic Recommendations
Text-to-speech
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Greg Brockman reveals how Elon Musk departed OpenAI
In late August 2017, key figures at OpenAI—then a small nonprofit research lab—met to discuss how they would establish a for-profit entity to commercialize their technology and raise the capital needed to achieve AGI.Elon Musk was demanding full cont
Related Special Topic Recommendations
Text-to-speech
 Top AI TTS Apps for Dyslexia: Support Learning and Reading Efficiency for Students
Top AI TTS Apps for Dyslexia: Support Learning and Reading Efficiency for Students
Discover the 2026 latest top-rated AI TTS apps curated for dyslexia support. Our expert rankings compare free vs paid tools, highlighting powerful features for enhanced reading efficiency and learning. Explore must-try, game-changing solutions to unlock student potential. Start your journey at XIX.AI.
 10 tools
10 tools
 xix.ai
Comic Creation
Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
xix.ai
Comic Creation
Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai
Business
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

 Comments (6)
0/500
Comments (6)
0/500
![EricScott]()
Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
![StephenGreen]()
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
![JamesWilliams]()
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
![CharlesJohnson]()
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
![CharlesMartinez]()
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
![LarryMartin]()
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊
OpenAI's New Safety Measures for AI Models o3 and o4-mini
OpenAI has introduced a new monitoring system for its advanced AI models, o3 and o4-mini, specifically designed to detect and prevent responses to prompts related to biological and chemical threats. This "safety-focused reasoning monitor" is a response to the enhanced capabilities of these models, which, according to OpenAI, represent a significant step up from their predecessors and could be misused by malicious actors.
The company's internal benchmarks indicate that o3, in particular, has shown a higher proficiency in answering questions about creating certain biological threats. To address this and other potential risks, OpenAI developed this new system, which operates alongside o3 and o4-mini. It's trained to recognize and reject prompts that could lead to harmful advice on biological and chemical risks.
Testing and Results
To gauge the effectiveness of this safety monitor, OpenAI conducted extensive testing. Red teamers spent approximately 1,000 hours identifying "unsafe" biorisk-related conversations generated by o3 and o4-mini. In a simulation of the monitor's "blocking logic," the models successfully declined to respond to risky prompts 98.7% of the time.
However, OpenAI admits that their test did not consider scenarios where users might attempt different prompts after being blocked. As a result, the company plans to continue using human monitoring as part of its safety strategy.
Risk Assessment and Ongoing Monitoring
Despite their advanced capabilities, o3 and o4-mini do not exceed OpenAI's "high risk" threshold for biorisks. Yet, early versions of these models were more adept at answering questions about developing biological weapons compared to o1 and GPT-4. OpenAI is actively monitoring how these models might facilitate the development of chemical and biological threats, as outlined in their updated Preparedness Framework.
OpenAI is increasingly turning to automated systems to manage the risks posed by its models. For instance, a similar reasoning monitor is used to prevent GPT-4o's image generator from producing child sexual abuse material (CSAM).
Concerns and Criticisms
Despite these efforts, some researchers argue that OpenAI may not be prioritizing safety enough. One of OpenAI's red-teaming partners, Metr, noted they had limited time to test o3 for deceptive behavior. Additionally, OpenAI chose not to release a safety report for its recently launched GPT-4.1 model, raising further concerns about the company's commitment to transparency and safety.










 Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
 OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
 Greg Brockman reveals how Elon Musk departed OpenAI
In late August 2017, key figures at OpenAI—then a small nonprofit research lab—met to discuss how they would establish a for-profit entity to commercialize their technology and raise the capital needed to achieve AGI.Elon Musk was demanding full cont
Greg Brockman reveals how Elon Musk departed OpenAI
In late August 2017, key figures at OpenAI—then a small nonprofit research lab—met to discuss how they would establish a for-profit entity to commercialize their technology and raise the capital needed to achieve AGI.Elon Musk was demanding full cont

Discover the 2026 latest top-rated AI TTS apps curated for dyslexia support. Our expert rankings compare free vs paid tools, highlighting powerful features for enhanced reading efficiency and learning. Explore must-try, game-changing solutions to unlock student potential. Start your journey at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊













