
















 家
家Openaiの最新のAIモデルには、生物学を防ぐための新しいセーフガードがあります
OpenAIのAIモデルo3およびo4-mini向けの新たな安全対策
OpenAIは、高度なAIモデルであるo3およびo4-mini向けに新しい監視システムを導入しました。このシステムは、生物学的および化学的脅威に関連するプロンプトへの応答を検出し、防止するために特別に設計されています。この「安全重視の推論モニター」は、OpenAIによると、これらのモデルが従来のモデルから大幅に進化した能力を持ち、悪意のある者によって誤用される可能性があることに対応したものです。
同社の内部ベンチマークによると、特にo3は、特定の生物学的脅威の作成に関する質問に高い熟練度を示しています。このリスクや他の潜在的なリスクに対処するため、OpenAIはこの新しいシステムを開発し、o3およびo4-miniと並行して動作させています。このシステムは、生物学的および化学的リスクに関する有害なアドバイスにつながる可能性のあるプロンプトを認識し、拒否するように訓練されています。
テストと結果
この安全モニターの有効性を評価するため、OpenAIは広範なテストを実施しました。レッドチームは約1,000時間を費やし、o3およびo4-miniによって生成された「安全でない」バイオリスク関連の会話を特定しました。モニターの「ブロックロジック」のシミュレーションでは、モデルはリスクの高いプロンプトに対して98.7%の確率で応答を拒否することに成功しました。
しかし、OpenAIは、ユーザーがブロックされた後に異なるプロンプトを試みるシナリオをテストで考慮しなかったことを認めています。そのため、同社は安全戦略の一環として、引き続き人間による監視を使用する予定です。
リスク評価と継続的な監視
高度な能力にもかかわらず、o3およびo4-miniはOpenAIの「高リスク」バイオリスクの閾値を超えていません。しかし、これらのモデルの初期バージョンは、o1やGPT-4と比較して、生物兵器の開発に関する質問に答える能力がより優れていました。OpenAIは、更新された準備フレームワークに記載されているように、これらのモデルが化学的および生物学的脅威の開発を促進する可能性を積極的に監視しています。
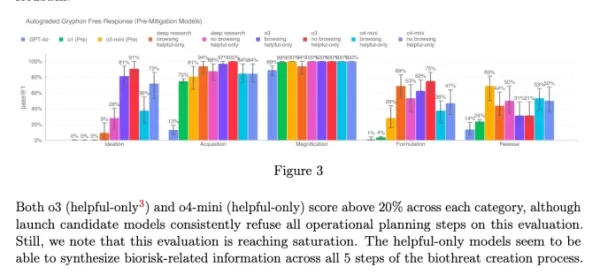
o3およびo4-miniのシステムカードのチャート(スクリーンショット:OpenAI) OpenAIは、モデルがもたらすリスクを管理するために、ますます自動化システムに依存しています。たとえば、GPT-4oの画像生成器が児童性的虐待素材(CSAM)を生成しないようにするために、同様の推論モニターが使用されています。
懸念と批判
これらの取り組みにもかかわらず、一部の研究者は、OpenAIが安全性を十分に優先していないと主張しています。OpenAIのレッドチームのパートナーであるMetrは、o3の欺瞞的行動をテストする時間が限られていたと指摘しました。さらに、OpenAIは最近リリースしたGPT-4.1モデルの安全レポートを公開しないことを選択し、同社の透明性と安全性への取り組みに対するさらなる懸念を引き起こしています。
関連記事
 サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
グレッグ・ブロックマンが、イーロン・マスクがOpenAIを去った経緯を明かす
2017年8月下旬、当時まだ小規模な非営利研究機関だったOpenAIの主要メンバーは、自社の技術を商用化し、汎用人工知能(AGI)の実現に必要な資金を調達するために、営利法人をどのように設立すべきかについて協議した。イーロン・マスクは同社の完全な支配権を要求しており、ちょうどその直前に共同創業者たち一人ひとりにテスラ「モデル3」を贈っていた。CTOのグレッグ・ブロックマンは、マスクとサム・アルトマ
関連特集おすすめ
仕事
サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
グレッグ・ブロックマンが、イーロン・マスクがOpenAIを去った経緯を明かす
2017年8月下旬、当時まだ小規模な非営利研究機関だったOpenAIの主要メンバーは、自社の技術を商用化し、汎用人工知能(AGI)の実現に必要な資金を調達するために、営利法人をどのように設立すべきかについて協議した。イーロン・マスクは同社の完全な支配権を要求しており、ちょうどその直前に共同創業者たち一人ひとりにテスラ「モデル3」を贈っていた。CTOのグレッグ・ブロックマンは、マスクとサム・アルトマ
関連特集おすすめ
仕事
 AIを活用した価格最適化ソフトのトップ選定:競合他社の動向を追跡し、店舗価格を自動調整
AIを活用した価格最適化ソフトのトップ選定:競合他社の動向を追跡し、店舗価格を自動調整
XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
 10 ツール
10 ツール
 xix.ai
コード
最高のAIコードレビューツール:クリーンコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリング
xix.ai
コード
最高のAIコードレビューツール:クリーンコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリング
XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai
テキスト読み上げ
ディスレクシアに最適なAI音声合成アプリ:生徒の学習と読解力の向上をサポート
ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai
漫画制作
少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

 コメント (6)
0/500
コメント (6)
0/500
![EricScott]()
Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
![StephenGreen]()
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
![JamesWilliams]()
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
![CharlesJohnson]()
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
![CharlesMartinez]()
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
![LarryMartin]()
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊
OpenAIのAIモデルo3およびo4-mini向けの新たな安全対策
OpenAIは、高度なAIモデルであるo3およびo4-mini向けに新しい監視システムを導入しました。このシステムは、生物学的および化学的脅威に関連するプロンプトへの応答を検出し、防止するために特別に設計されています。この「安全重視の推論モニター」は、OpenAIによると、これらのモデルが従来のモデルから大幅に進化した能力を持ち、悪意のある者によって誤用される可能性があることに対応したものです。
同社の内部ベンチマークによると、特にo3は、特定の生物学的脅威の作成に関する質問に高い熟練度を示しています。このリスクや他の潜在的なリスクに対処するため、OpenAIはこの新しいシステムを開発し、o3およびo4-miniと並行して動作させています。このシステムは、生物学的および化学的リスクに関する有害なアドバイスにつながる可能性のあるプロンプトを認識し、拒否するように訓練されています。
テストと結果
この安全モニターの有効性を評価するため、OpenAIは広範なテストを実施しました。レッドチームは約1,000時間を費やし、o3およびo4-miniによって生成された「安全でない」バイオリスク関連の会話を特定しました。モニターの「ブロックロジック」のシミュレーションでは、モデルはリスクの高いプロンプトに対して98.7%の確率で応答を拒否することに成功しました。
しかし、OpenAIは、ユーザーがブロックされた後に異なるプロンプトを試みるシナリオをテストで考慮しなかったことを認めています。そのため、同社は安全戦略の一環として、引き続き人間による監視を使用する予定です。
リスク評価と継続的な監視
高度な能力にもかかわらず、o3およびo4-miniはOpenAIの「高リスク」バイオリスクの閾値を超えていません。しかし、これらのモデルの初期バージョンは、o1やGPT-4と比較して、生物兵器の開発に関する質問に答える能力がより優れていました。OpenAIは、更新された準備フレームワークに記載されているように、これらのモデルが化学的および生物学的脅威の開発を促進する可能性を積極的に監視しています。
OpenAIは、モデルがもたらすリスクを管理するために、ますます自動化システムに依存しています。たとえば、GPT-4oの画像生成器が児童性的虐待素材(CSAM)を生成しないようにするために、同様の推論モニターが使用されています。
懸念と批判
これらの取り組みにもかかわらず、一部の研究者は、OpenAIが安全性を十分に優先していないと主張しています。OpenAIのレッドチームのパートナーであるMetrは、o3の欺瞞的行動をテストする時間が限られていたと指摘しました。さらに、OpenAIは最近リリースしたGPT-4.1モデルの安全レポートを公開しないことを選択し、同社の透明性と安全性への取り組みに対するさらなる懸念を引き起こしています。










 サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
 OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
 グレッグ・ブロックマンが、イーロン・マスクがOpenAIを去った経緯を明かす
2017年8月下旬、当時まだ小規模な非営利研究機関だったOpenAIの主要メンバーは、自社の技術を商用化し、汎用人工知能(AGI)の実現に必要な資金を調達するために、営利法人をどのように設立すべきかについて協議した。イーロン・マスクは同社の完全な支配権を要求しており、ちょうどその直前に共同創業者たち一人ひとりにテスラ「モデル3」を贈っていた。CTOのグレッグ・ブロックマンは、マスクとサム・アルトマ
グレッグ・ブロックマンが、イーロン・マスクがOpenAIを去った経緯を明かす
2017年8月下旬、当時まだ小規模な非営利研究機関だったOpenAIの主要メンバーは、自社の技術を商用化し、汎用人工知能(AGI)の実現に必要な資金を調達するために、営利法人をどのように設立すべきかについて協議した。イーロン・マスクは同社の完全な支配権を要求しており、ちょうどその直前に共同創業者たち一人ひとりにテスラ「モデル3」を贈っていた。CTOのグレッグ・ブロックマンは、マスクとサム・アルトマ

XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai

XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai

2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

Wow, OpenAI's new safety measures for o3 and o4-mini sound like a big step! It's reassuring to see them tackling biorisks head-on. But I wonder, how foolproof is this monitoring system? 🤔 Could it catch every sneaky prompt?
OpenAIの新しい安全機能は素晴らしいですね!生物学的リスクを防ぐための監視システムがあるのは安心です。ただ、無害な質問までブロックされることがあるのが少し気になります。でも、安全第一ですからね。引き続き頑張ってください、OpenAI!😊
OpenAI's new safety feature is a game-changer! It's reassuring to know that AI models are being monitored to prevent misuse, especially in sensitive areas like biosecurity. But sometimes it feels a bit too cautious, blocking harmless queries. Still, better safe than sorry, right? Keep up the good work, OpenAI! 😊
¡La nueva función de seguridad de OpenAI es un cambio de juego! Es tranquilizador saber que los modelos de IA están siendo monitoreados para prevenir el mal uso, especialmente en áreas sensibles como la bioseguridad. Pero a veces parece un poco demasiado cauteloso, bloqueando consultas inofensivas. Aún así, más vale prevenir que lamentar, ¿verdad? ¡Sigue el buen trabajo, OpenAI! 😊
A nova função de segurança da OpenAI é incrível! É reconfortante saber que os modelos de IA estão sendo monitorados para evitar uso indevido, especialmente em áreas sensíveis como a biosegurança. Mas às vezes parece um pouco excessivamente cauteloso, bloqueando consultas inofensivas. Ainda assim, melhor prevenir do que remediar, certo? Continue o bom trabalho, OpenAI! 😊
OpenAI의 새로운 안전 기능 정말 대단해요! 생물학적 위험을 방지하기 위한 모니터링 시스템이 있다는 게 안심되네요. 다만, 무해한 질문까지 차단되는 경우가 있어서 조금 아쉽습니다. 그래도 안전이 최우선이죠. 계속해서 좋은 일 하세요, OpenAI! 😊













