
















 Home
HomeEnhancing AI's Ability to Render Realistic Mirror Reflections
Since generative AI captured widespread attention, computer vision researchers have intensified efforts to develop models that grasp and replicate physical laws, with a particular focus on challenges like simulating gravity and fluid dynamics over the past five years.
With latent diffusion models (LDMs) leading generative AI since 2022, attention has shifted to their struggles with accurately depicting physical phenomena. This issue has gained traction following OpenAI's Sora video model and the recent open-source releases of Hunyuan Video and Wan 2.1.
Struggles with Reflections
Research to improve LDMs’ grasp of physics has largely centered on areas like gait simulation and Newtonian motion, as inaccuracies here undermine the realism of AI-generated videos.
Yet, a growing body of work targets a key LDM weakness: its limited ability to generate accurate reflections.

From the January 2025 paper ‘Reflecting Reality: Enabling Diffusion Models to Produce Faithful Mirror Reflections’, examples of ‘reflection failure’ versus the researchers’ approach. Source: https://arxiv.org/pdf/2409.14677
This challenge, also prevalent in CGI and video gaming, relies on ray-tracing algorithms to simulate light’s interaction with surfaces, producing realistic reflections, refractions, and shadows.
However, each additional light-ray bounce significantly increases computational demands, forcing real-time applications to balance latency and accuracy by capping bounce counts.
![A representation of a virtually-calculated light-beam in a traditional 3D-based (i.e., CGI) scenario, using technologies and principles first developed in the 1960s, and which came to fruition between 1982-93 (the span between Tron [1982] and Jurassic Park [1993]). Source: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing](https://img.xix.ai/uploads/55/680fa78ce2769.webp)
A virtual light-beam in a 3D-based (CGI) scenario, using techniques from the 1960s, refined between ‘Tron’ (1982) and ‘Jurassic Park’ (1993). Source: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
For example, rendering a chrome teapot before a mirror involves light rays bouncing repeatedly, creating near-infinite loops with minimal visual benefit. Typically, two to three bounces suffice for perceptible reflections, as a single bounce yields a dark mirror.
Each extra bounce doubles rendering time, making efficient reflection handling critical for improving ray-traced visuals.
Reflections are vital for photorealism in subtler cases, like wet city streets, shop window reflections, or characters’ glasses, where objects and environments must appear accurately.

A twin-reflection created through traditional compositing for a scene in ‘The Matrix’ (1999).
Challenges in Visuals
Before diffusion models, frameworks like Neural Radiance Fields (NeRF) and newer approaches like Gaussian Splatting struggled to naturally depict reflections.
The REF2-NeRF project proposed a NeRF-based method for scenes with glass cases, modeling refraction and reflection based on viewer perspective. This allowed estimation of glass surfaces and separation of direct and reflected light.

Examples from the Ref2Nerf paper. Source: https://arxiv.org/pdf/2311.17116
Other reflection-focused NeRF solutions include NeRFReN, Reflecting Reality, and Meta’s 2024 Planar Reflection-Aware Neural Radiance Fields project.
For Gaussian Splatting, efforts like Mirror-3DGS, Reflective Gaussian Splatting, and RefGaussian tackled reflection issues, while the 2023 Nero project introduced a unique method for neural representations.
MirrorVerse Breakthrough
Teaching diffusion models to handle reflection logic is tougher than with structural methods like Gaussian Splatting or NeRF. Reliable reflection in diffusion models hinges on diverse, high-quality training data across varied scenarios.
Traditionally, adding such behaviors involves LoRA or fine-tuning, but these skew outputs or create model-specific tools incompatible with the original model.
Improving diffusion models demands training data that emphasizes reflection physics. However, curating hyperscale datasets for every weakness is costly and impractical.
Still, solutions emerge, like India’s MirrorVerse project, which offers an enhanced dataset and training method to advance reflection accuracy in diffusion models.

Rightmost, MirrorVerse results compared to two prior approaches (central columns). Source: https://arxiv.org/pdf/2504.15397
As shown above, MirrorVerse improves on recent efforts but isn’t flawless.
In the top right image, ceramic jars are slightly misaligned, and in the lower image, an erroneous cup reflection appears against natural reflective angles.
We’ll explore this method not as a definitive solution but to highlight the persistent challenges diffusion models face in static and video formats, where reflection data is often tied to specific scenarios.
Thus, LDMs may lag behind NeRF, Gaussian Splatting, and traditional CGI in reflection accuracy.
The paper, MirrorVerse: Pushing Diffusion Models to Realistically Reflect the World, comes from researchers at Vision and AI Lab, IISc Bangalore, and Samsung R&D Institute, Bangalore, with a project page, Hugging Face dataset, and GitHub code.
Methodology
The researchers highlight the difficulty models like Stable Diffusion and Flux face with reflection-based prompts, as shown below:

From the paper: Top text-to-image models, SD3.5 and Flux, struggle with consistent, geometrically accurate reflections.
The team developed MirrorFusion 2.0, a diffusion-based model to enhance photorealism and geometric accuracy of mirror reflections. It was trained on their MirrorGen2 dataset, designed to address generalization issues.
MirrorGen2 introduces random object positioning, randomized rotations, and explicit object grounding to ensure plausible reflections across diverse object placements.
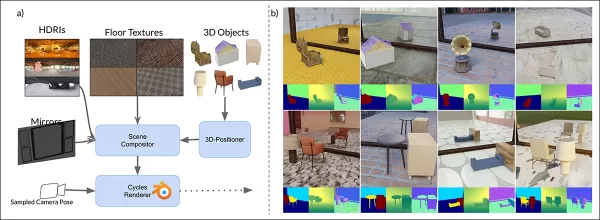
MirrorVerse’s synthetic data schema: random positioning, rotation, and grounding via 3D-Positioner, with paired objects for realistic spatial interactions.
MirrorGen2 includes paired object scenes to better handle occlusions and complex spatial arrangements in reflective settings.
The paper notes:
‘Categories are paired for semantic coherence, like a chair with a table. After positioning the primary object, a secondary one is added without overlap, ensuring distinct spatial regions.’
For object grounding, the authors ensured objects were anchored to the ground, avoiding unnatural ‘floating’ in synthetic data.
Since dataset innovation drives the paper’s novelty, we’ll cover this next.
Data and Tests
SynMirrorV2
The SynMirrorV2 dataset enhances reflection training data diversity, using 3D objects from Objaverse and Amazon Berkeley Objects (ABO), refined via OBJECT 3DIT and V1 MirrorFusion filtering, yielding 66,062 high-quality objects.

Objaverse dataset examples used for the curated dataset. Source: https://arxiv.org/pdf/2212.08051
Scenes were built with textured floors from CC-Textures and HDRI backgrounds from PolyHaven, using full-wall or rectangular mirrors. Lighting used an area-light at a 45-degree angle. Objects were scaled, positioned via mirror-camera frustum intersection, and randomly rotated on the y-axis, with grounding to avoid floating artifacts.
Multi-object scenes used 3,140 semantically coherent pairings from ABO, avoiding overlap to capture varied occlusions and depth.

Rendered views from the dataset with multiple objects, showing segmentation and depth maps.
Training Process
A three-stage curriculum learning process trained MirrorFusion 2.0 for robust real-world generalization.
Stage 1 initialized weights from Stable Diffusion v1.5, fine-tuning on SynMirrorV2’s single-object split for 40,000 iterations, keeping both conditioning and generation branches active.
Stage 2 fine-tuned for 10,000 iterations on SynMirrorV2’s multi-object split to handle occlusions and complex scenes.
Stage 3 added 10,000 iterations with real-world MSD dataset data, using Matterport3D depth maps.

MSD dataset examples with depth and segmentation maps. Source: https://arxiv.org/pdf/1908.09101
Text prompts were omitted 20% of the time to prioritize depth information. Training used four NVIDIA A100 GPUs, a 1e-5 learning rate, batch size of 4 per GPU, and AdamW optimizer.
This progressive training moved from simple synthetic to complex real-world scenes for better transferability.
Testing
MirrorFusion 2.0 was tested against the baseline MirrorFusion on MirrorBenchV2, covering single and multi-object scenes, with qualitative tests on MSD and Google Scanned Objects (GSO) datasets.
Evaluation used 2,991 single-object and 300 two-object scenes, measuring PSNR, SSIM, and LPIPS for reflection quality, and CLIP for prompt alignment. Images were generated with four seeds, selecting the best SSIM score.

Left: Single-object reflection quality on MirrorBenchV2, with MirrorFusion 2.0 outperforming the baseline. Right: Multi-object reflection quality, with multi-object training improving results.
The authors note:
‘Our method outperforms the baseline, and multi-object fine-tuning enhances complex scene results.’
Qualitative tests emphasized MirrorFusion 2.0’s improvements:

MirrorBenchV2 comparison: Baseline shows incorrect chair orientation and distorted reflections; MirrorFusion 2.0 renders accurately.
The baseline struggled with object orientation and spatial artifacts, while MirrorFusion 2.0, trained on SynMirrorV2, maintained accurate positioning and realistic reflections.
GSO dataset results:

GSO comparison: Baseline distorts object structure; MirrorFusion 2.0 preserves geometry, color, and detail.
The authors comment:
‘MirrorFusion 2.0 accurately reflects details like drawer handles, while the baseline produces implausible results.’
Real-world MSD dataset results:

MSD results: MirrorFusion 2.0, fine-tuned on MSD, captures complex scenes with cluttered objects and multiple mirrors accurately.
Fine-tuning on MSD improved MirrorFusion 2.0’s handling of complex real-world scenes, enhancing reflection coherence.
A user study found 84% preferred MirrorFusion 2.0’s outputs.
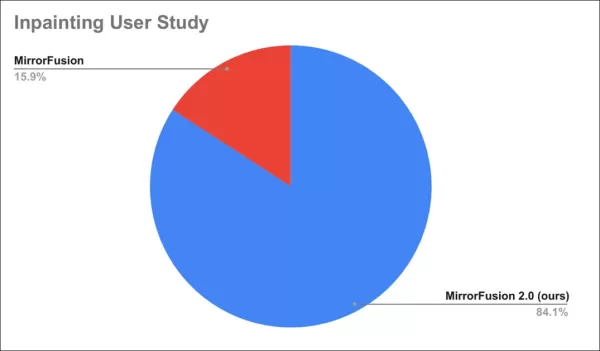
User study results.
Conclusion
While MirrorFusion 2.0 marks progress, the baseline for reflection accuracy in diffusion models remains low, making even modest improvements notable. Diffusion models’ architecture struggles with consistent physics, and adding data, as done here, is a standard but limited fix.
Future datasets with better reflection data distribution could improve results, but this applies to many LDM weaknesses. Prioritizing which issues to address remains a challenge.
First published Monday, April 28, 2025
Related article
 Google Unveils Gemini Notebooks, Merging NotebookLM with Personal Knowledge Base
Google recently launched a "Notebooks" feature for Gemini, designed to help users manage complex projects by creating a personalized knowledge base. This update bridges the data gap between Gemini and the AI research assistant NotebookLM, marking a k
Luma AI unveils Uni-1 autoregressive model that generates text and pixels simultaneously
Luma Labs launched its image generation model Uni-1 on March 23, marking the company's first publicly available model built on the Unified Intelligence architecture. Free trial access is now open on the official website, with API pricing announced an
NVIDIA's Xinzhou Wu: autonomous driving's ChatGPT moment has arrived, L4 mass production no longer a dream
In the rapidly evolving field of physical AI, autonomous driving is often viewed as the first major challenge to overcome. Recently, Wu Xinzhou, Vice President of NVIDIA, outlined the company's ambitious vision for intelligent driving at a Beijing co
Related Special Topic Recommendations
chatbot
Google Unveils Gemini Notebooks, Merging NotebookLM with Personal Knowledge Base
Google recently launched a "Notebooks" feature for Gemini, designed to help users manage complex projects by creating a personalized knowledge base. This update bridges the data gap between Gemini and the AI research assistant NotebookLM, marking a k
Luma AI unveils Uni-1 autoregressive model that generates text and pixels simultaneously
Luma Labs launched its image generation model Uni-1 on March 23, marking the company's first publicly available model built on the Unified Intelligence architecture. Free trial access is now open on the official website, with API pricing announced an
NVIDIA's Xinzhou Wu: autonomous driving's ChatGPT moment has arrived, L4 mass production no longer a dream
In the rapidly evolving field of physical AI, autonomous driving is often viewed as the first major challenge to overcome. Recently, Wu Xinzhou, Vice President of NVIDIA, outlined the company's ambitious vision for intelligent driving at a Beijing co
Related Special Topic Recommendations
chatbot
 Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
 10 tools
10 tools
 xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai
code
Best AI Tools for Automated Unit Testing: Generate Jest, PyTest & JUnit Test Cases in One Click
Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai
Data Analysis
Best AI Data Visualization Tools: Auto-Generate Interactive BI Dashboards from Raw Files
Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
10 tools
xix.ai
Social Media
AI Branding Kits for Social Media: Maintain Consistent Brand Visuals Across All Channels
Discover the 2026 best AI branding kits for social media. XIX.AI's curated list features top-rated, game-changing tools to maintain perfectly consistent brand visuals across all channels. Compare free vs paid options with real-world tests. Unlock your brand's visual edge today.
10 tools
xix.ai

 Comments (4)
0/500
Comments (4)
0/500
![GaryWalker]()
鏡の反射をリアルに描画するAIの進歩ってすごいですね!でも、これが深フェイクに悪用されたらどうなるんだろう…ちょっと怖いかも😅 反射の物理法則を理解するって、AIが現実世界を「見る」能力が向上している証拠でしょうか?
![JimmyWilson]()
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
![FredGreen]()
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
![RogerNelson]()
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯
Since generative AI captured widespread attention, computer vision researchers have intensified efforts to develop models that grasp and replicate physical laws, with a particular focus on challenges like simulating gravity and fluid dynamics over the past five years.
With latent diffusion models (LDMs) leading generative AI since 2022, attention has shifted to their struggles with accurately depicting physical phenomena. This issue has gained traction following OpenAI's Sora video model and the recent open-source releases of Hunyuan Video and Wan 2.1.
Struggles with Reflections
Research to improve LDMs’ grasp of physics has largely centered on areas like gait simulation and Newtonian motion, as inaccuracies here undermine the realism of AI-generated videos.
Yet, a growing body of work targets a key LDM weakness: its limited ability to generate accurate reflections.
From the January 2025 paper ‘Reflecting Reality: Enabling Diffusion Models to Produce Faithful Mirror Reflections’, examples of ‘reflection failure’ versus the researchers’ approach. Source: https://arxiv.org/pdf/2409.14677
This challenge, also prevalent in CGI and video gaming, relies on ray-tracing algorithms to simulate light’s interaction with surfaces, producing realistic reflections, refractions, and shadows.
However, each additional light-ray bounce significantly increases computational demands, forcing real-time applications to balance latency and accuracy by capping bounce counts.
A virtual light-beam in a 3D-based (CGI) scenario, using techniques from the 1960s, refined between ‘Tron’ (1982) and ‘Jurassic Park’ (1993). Source: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
For example, rendering a chrome teapot before a mirror involves light rays bouncing repeatedly, creating near-infinite loops with minimal visual benefit. Typically, two to three bounces suffice for perceptible reflections, as a single bounce yields a dark mirror.
Each extra bounce doubles rendering time, making efficient reflection handling critical for improving ray-traced visuals.
Reflections are vital for photorealism in subtler cases, like wet city streets, shop window reflections, or characters’ glasses, where objects and environments must appear accurately.
A twin-reflection created through traditional compositing for a scene in ‘The Matrix’ (1999).
Challenges in Visuals
Before diffusion models, frameworks like Neural Radiance Fields (NeRF) and newer approaches like Gaussian Splatting struggled to naturally depict reflections.
The REF2-NeRF project proposed a NeRF-based method for scenes with glass cases, modeling refraction and reflection based on viewer perspective. This allowed estimation of glass surfaces and separation of direct and reflected light.
Examples from the Ref2Nerf paper. Source: https://arxiv.org/pdf/2311.17116
Other reflection-focused NeRF solutions include NeRFReN, Reflecting Reality, and Meta’s 2024 Planar Reflection-Aware Neural Radiance Fields project.
For Gaussian Splatting, efforts like Mirror-3DGS, Reflective Gaussian Splatting, and RefGaussian tackled reflection issues, while the 2023 Nero project introduced a unique method for neural representations.
MirrorVerse Breakthrough
Teaching diffusion models to handle reflection logic is tougher than with structural methods like Gaussian Splatting or NeRF. Reliable reflection in diffusion models hinges on diverse, high-quality training data across varied scenarios.
Traditionally, adding such behaviors involves LoRA or fine-tuning, but these skew outputs or create model-specific tools incompatible with the original model.
Improving diffusion models demands training data that emphasizes reflection physics. However, curating hyperscale datasets for every weakness is costly and impractical.
Still, solutions emerge, like India’s MirrorVerse project, which offers an enhanced dataset and training method to advance reflection accuracy in diffusion models.
Rightmost, MirrorVerse results compared to two prior approaches (central columns). Source: https://arxiv.org/pdf/2504.15397
As shown above, MirrorVerse improves on recent efforts but isn’t flawless.
In the top right image, ceramic jars are slightly misaligned, and in the lower image, an erroneous cup reflection appears against natural reflective angles.
We’ll explore this method not as a definitive solution but to highlight the persistent challenges diffusion models face in static and video formats, where reflection data is often tied to specific scenarios.
Thus, LDMs may lag behind NeRF, Gaussian Splatting, and traditional CGI in reflection accuracy.
The paper, MirrorVerse: Pushing Diffusion Models to Realistically Reflect the World, comes from researchers at Vision and AI Lab, IISc Bangalore, and Samsung R&D Institute, Bangalore, with a project page, Hugging Face dataset, and GitHub code.
Methodology
The researchers highlight the difficulty models like Stable Diffusion and Flux face with reflection-based prompts, as shown below:
From the paper: Top text-to-image models, SD3.5 and Flux, struggle with consistent, geometrically accurate reflections.
The team developed MirrorFusion 2.0, a diffusion-based model to enhance photorealism and geometric accuracy of mirror reflections. It was trained on their MirrorGen2 dataset, designed to address generalization issues.
MirrorGen2 introduces random object positioning, randomized rotations, and explicit object grounding to ensure plausible reflections across diverse object placements.
MirrorVerse’s synthetic data schema: random positioning, rotation, and grounding via 3D-Positioner, with paired objects for realistic spatial interactions.
MirrorGen2 includes paired object scenes to better handle occlusions and complex spatial arrangements in reflective settings.
The paper notes:
‘Categories are paired for semantic coherence, like a chair with a table. After positioning the primary object, a secondary one is added without overlap, ensuring distinct spatial regions.’
For object grounding, the authors ensured objects were anchored to the ground, avoiding unnatural ‘floating’ in synthetic data.
Since dataset innovation drives the paper’s novelty, we’ll cover this next.
Data and Tests
SynMirrorV2
The SynMirrorV2 dataset enhances reflection training data diversity, using 3D objects from Objaverse and Amazon Berkeley Objects (ABO), refined via OBJECT 3DIT and V1 MirrorFusion filtering, yielding 66,062 high-quality objects.
Objaverse dataset examples used for the curated dataset. Source: https://arxiv.org/pdf/2212.08051
Scenes were built with textured floors from CC-Textures and HDRI backgrounds from PolyHaven, using full-wall or rectangular mirrors. Lighting used an area-light at a 45-degree angle. Objects were scaled, positioned via mirror-camera frustum intersection, and randomly rotated on the y-axis, with grounding to avoid floating artifacts.
Multi-object scenes used 3,140 semantically coherent pairings from ABO, avoiding overlap to capture varied occlusions and depth.
Rendered views from the dataset with multiple objects, showing segmentation and depth maps.
Training Process
A three-stage curriculum learning process trained MirrorFusion 2.0 for robust real-world generalization.
Stage 1 initialized weights from Stable Diffusion v1.5, fine-tuning on SynMirrorV2’s single-object split for 40,000 iterations, keeping both conditioning and generation branches active.
Stage 2 fine-tuned for 10,000 iterations on SynMirrorV2’s multi-object split to handle occlusions and complex scenes.
Stage 3 added 10,000 iterations with real-world MSD dataset data, using Matterport3D depth maps.
MSD dataset examples with depth and segmentation maps. Source: https://arxiv.org/pdf/1908.09101
Text prompts were omitted 20% of the time to prioritize depth information. Training used four NVIDIA A100 GPUs, a 1e-5 learning rate, batch size of 4 per GPU, and AdamW optimizer.
This progressive training moved from simple synthetic to complex real-world scenes for better transferability.
Testing
MirrorFusion 2.0 was tested against the baseline MirrorFusion on MirrorBenchV2, covering single and multi-object scenes, with qualitative tests on MSD and Google Scanned Objects (GSO) datasets.
Evaluation used 2,991 single-object and 300 two-object scenes, measuring PSNR, SSIM, and LPIPS for reflection quality, and CLIP for prompt alignment. Images were generated with four seeds, selecting the best SSIM score.
Left: Single-object reflection quality on MirrorBenchV2, with MirrorFusion 2.0 outperforming the baseline. Right: Multi-object reflection quality, with multi-object training improving results.
The authors note:
‘Our method outperforms the baseline, and multi-object fine-tuning enhances complex scene results.’
Qualitative tests emphasized MirrorFusion 2.0’s improvements:
MirrorBenchV2 comparison: Baseline shows incorrect chair orientation and distorted reflections; MirrorFusion 2.0 renders accurately.
The baseline struggled with object orientation and spatial artifacts, while MirrorFusion 2.0, trained on SynMirrorV2, maintained accurate positioning and realistic reflections.
GSO dataset results:
GSO comparison: Baseline distorts object structure; MirrorFusion 2.0 preserves geometry, color, and detail.
The authors comment:
‘MirrorFusion 2.0 accurately reflects details like drawer handles, while the baseline produces implausible results.’
Real-world MSD dataset results:
MSD results: MirrorFusion 2.0, fine-tuned on MSD, captures complex scenes with cluttered objects and multiple mirrors accurately.
Fine-tuning on MSD improved MirrorFusion 2.0’s handling of complex real-world scenes, enhancing reflection coherence.
A user study found 84% preferred MirrorFusion 2.0’s outputs.
User study results.
Conclusion
While MirrorFusion 2.0 marks progress, the baseline for reflection accuracy in diffusion models remains low, making even modest improvements notable. Diffusion models’ architecture struggles with consistent physics, and adding data, as done here, is a standard but limited fix.
Future datasets with better reflection data distribution could improve results, but this applies to many LDM weaknesses. Prioritizing which issues to address remains a challenge.
First published Monday, April 28, 2025










 Google Unveils Gemini Notebooks, Merging NotebookLM with Personal Knowledge Base
Google recently launched a "Notebooks" feature for Gemini, designed to help users manage complex projects by creating a personalized knowledge base. This update bridges the data gap between Gemini and the AI research assistant NotebookLM, marking a k
Google Unveils Gemini Notebooks, Merging NotebookLM with Personal Knowledge Base
Google recently launched a "Notebooks" feature for Gemini, designed to help users manage complex projects by creating a personalized knowledge base. This update bridges the data gap between Gemini and the AI research assistant NotebookLM, marking a k
 Luma AI unveils Uni-1 autoregressive model that generates text and pixels simultaneously
Luma Labs launched its image generation model Uni-1 on March 23, marking the company's first publicly available model built on the Unified Intelligence architecture. Free trial access is now open on the official website, with API pricing announced an
Luma AI unveils Uni-1 autoregressive model that generates text and pixels simultaneously
Luma Labs launched its image generation model Uni-1 on March 23, marking the company's first publicly available model built on the Unified Intelligence architecture. Free trial access is now open on the official website, with API pricing announced an
 NVIDIA's Xinzhou Wu: autonomous driving's ChatGPT moment has arrived, L4 mass production no longer a dream
In the rapidly evolving field of physical AI, autonomous driving is often viewed as the first major challenge to overcome. Recently, Wu Xinzhou, Vice President of NVIDIA, outlined the company's ambitious vision for intelligent driving at a Beijing co
NVIDIA's Xinzhou Wu: autonomous driving's ChatGPT moment has arrived, L4 mass production no longer a dream
In the rapidly evolving field of physical AI, autonomous driving is often viewed as the first major challenge to overcome. Recently, Wu Xinzhou, Vice President of NVIDIA, outlined the company's ambitious vision for intelligent driving at a Beijing co

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

Discover the 2026 best AI data visualization tools at XIX.AI. Our curated, top-rated selection helps you auto-generate powerful, interactive BI dashboards from raw files instantly. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your data's potential today.
10 tools
xix.ai

Discover the 2026 best AI branding kits for social media. XIX.AI's curated list features top-rated, game-changing tools to maintain perfectly consistent brand visuals across all channels. Compare free vs paid options with real-world tests. Unlock your brand's visual edge today.
10 tools
xix.ai

鏡の反射をリアルに描画するAIの進歩ってすごいですね!でも、これが深フェイクに悪用されたらどうなるんだろう…ちょっと怖いかも😅 反射の物理法則を理解するって、AIが現実世界を「見る」能力が向上している証拠でしょうか?
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯













