
















 首頁
首頁增強AI渲染真實鏡面反射的能力
自從生成式AI引起廣泛關注以來,計算機視覺研究人員已加緊努力開發能夠理解並複製物理定律的模型,特別是在過去五年中專注於模擬重力和流體動力學等挑戰。
自2022年以來,潛在擴散模型(LDMs)引領生成式AI,焦點轉向其在準確描繪物理現象方面的困難。此問題在OpenAI的Sora視頻模型以及最近的開源項目Hunyuan Video和Wan 2.1發布後引起更多關注。
反射的挑戰
改善LDMs對物理定律掌握的研究主要集中在步態模擬和牛頓運動等領域,因為這些方面的不準確會削弱AI生成視頻的真實感。
然而,越來越多的研究針對LDM的一個關鍵弱點:其生成準確反射的能力有限。

來自2025年1月論文《反映現實:使擴散模型生成忠實的鏡面反射》的示例,展示了“反射失敗”與研究人員自身方法的對比。 來源:https://arxiv.org/pdf/2409.14677
這一挑戰在CGI和視頻遊戲中也普遍存在,依賴光線追蹤算法來模擬光線與表面的交互,生成真實的反射、折射和陰影。
然而,每次額外的光線反射顯著增加計算需求,迫使即時應用在延遲與準確性之間平衡,通過限制反射次數來應對。
在3D(CGI)場景中的虛擬光束,使用1960年代的技術,於《創:戰記》(1982)與《侏羅紀公園》(1993)間完善。 來源:https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
例如,在鏡子前渲染一個鉻製茶壺涉及光線多次反射,形成幾乎無限的循環,但視覺收益甚微。通常兩到三次反射足以產生可感知的反射,因為單次反射會導致黑暗的鏡面。
每次額外反射使渲染時間翻倍,使得高效處理反射對於改善光線追蹤視覺效果至關重要。
反射對於照片級真實感至關重要,特別是在濕潤的城市街道、商店櫥窗反射或角色眼鏡等微妙場景中,物體和環境必須準確呈現。

通過傳統合成技術為《黑客帝國》(1999)中的場景創建的雙重反射。
視覺挑戰
在擴散模型之前,神經輻射場(NeRF)等框架以及較新的高斯濺射方法難以自然描繪反射。
REF2-NeRF項目提出了一種基於NeRF的方法,適用於包含玻璃櫃的場景,根據觀看者視角建模折射和反射。這允許估計玻璃表面並分離直接光與反射光。

來自Ref2Nerf論文的示例。 來源:https://arxiv.org/pdf/2311.17116
其他專注於反射的NeRF解決方案包括NeRFReN、反映現實,以及Meta於2024年推出的平面反射感知神經輻射場項目。
對於高斯濺射,Mirror-3DGS、反射高斯濺射和RefGaussian等努力解決了反射問題,而2023年的Nero項目引入了一種獨特的神經表示方法。
MirrorVerse突破
教導擴散模型處理反射邏輯比結構化方法如高斯濺射或NeRF更困難。擴散模型中的可靠反射依賴於多樣化、高質量的訓練數據,涵蓋各種場景。
傳統上,添加此類行為涉及LoRA或微調,但這些會導致輸出偏差或創建與原始模型不兼容的特定工具。
改進擴散模型需要強調反射物理的訓練數據。然而,為每個弱點策劃超大規模數據集成本高昂且不切實際。
儘管如此,解決方案正在湧現,例如印度的MirrorVerse項目,提供增強的數據集和訓練方法,以提升擴散模型中的反射準確性。

最右側,MirrorVerse的結果與之前兩種方法(中間兩列)對比。 來源:https://arxiv.org/pdf/2504.15397
如上所示,MirrorVerse改進了近期努力,但並非完美無缺。
在右上圖中,陶瓷罐略有錯位,在下圖中,出現了違反自然反射角度的錯誤杯子反射。
我們將探討此方法,並非作為最終解決方案,而是為了凸顯擴散模型在靜態和視頻格式中面臨的持續挑戰,其中反射數據通常與特定場景相關聯。
因此,LDMs在反射準確性上可能落後於NeRF、高斯濺射和傳統CGI。
論文《MirrorVerse:推動擴散模型真實反映世界》來自班加羅爾IISc視覺與AI實驗室以及三星研發研究所的研究人員,提供項目頁面、Hugging Face數據集和GitHub代碼。
方法
研究人員強調,像穩定擴散和Flux這樣的模型在處理基於反射的提示時面臨困難,如下所示:

來自論文:頂尖文本到圖像模型,SD3.5和Flux,在生成一致、幾何準確的反射方面面臨挑戰。
團隊開發了MirrorFusion 2.0,一種基於擴散的模型,以增強鏡面反射的照片真實感和幾何準確性。它在他們的MirrorGen2數據集上進行訓練,該數據集旨在解決泛化問題。
MirrorGen2引入了隨機物體定位、隨機旋轉和明確物體接地,以確保在多樣化物體放置中生成合理的反射。
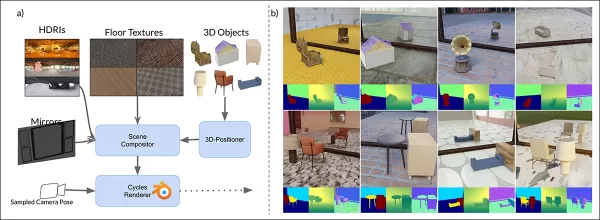
MirrorVerse的合成數據架構:通過3D-Positioner隨機定位、旋轉和接地,配對物體以實現真實的空間交互。
MirrorGen2包括配對物體場景,以更好地處理反射環境中的遮擋和複雜空間排列。
論文指出:
「類別以語義一致性配對,如椅子與桌子。在定位主要物體後,添加次要物體而不重疊,確保不同的空間區域。」
對於物體接地,作者確保物體錨定在地面上,避免合成數據中不自然的「漂浮」現象。
由於數據集創新是論文新穎性的驅動力,我們接下來將討論這一點。
數據與測試
SynMirrorV2
SynMirrorV2數據集增強了反射訓練數據的多樣性,使用來自Objaverse和Amazon Berkeley Objects(ABO)的3D物體,通過OBJECT 3DIT和V1 MirrorFusion過濾進行精煉,產生66,062個高質量物體。

用於精選數據集的Objaverse數據集示例。 來源:https://arxiv.org/pdf/2212.08051
場景使用來自CC-Textures的紋理地板和PolyHaven的HDRI背景構建,採用全牆或矩形鏡子。照明使用45度角的區域光。物體被縮放,通過鏡面-相機視錐相交定位,並在y軸上隨機旋轉,接地以避免漂浮偽影。
多物體場景使用來自ABO的3,140個語義一致配對,避免重疊以捕捉多樣的遮擋和深度。

數據集中的渲染視圖,包含多個物體,展示分割和深度圖。
訓練過程
三階段課程學習過程訓練MirrorFusion 2.0,以實現穩健的現實世界泛化。
第一階段從穩定擴散v1.5初始化權重,在SynMirrorV2的單物體分割上進行40,000次迭代微調,保持條件和生成分支均活躍。
第二階段在SynMirrorV2的多物體分割上進行10,000次迭代微調,以處理遮擋和複雜場景。
第三階段添加10,000次迭代,使用現實世界的MSD數據集數據,結合Matterport3D深度圖。

MSD數據集示例,包含深度和分割圖。 來源:https://arxiv.org/pdf/1908.09101
文本提示有20%的時間被省略,以優先考慮深度信息。訓練使用四個NVIDIA A100 GPU,學習率為1e-5,每GPU批量大小為4,使用AdamW優化器。
這種漸進式訓練從簡單的合成場景轉向複雜的現實世界場景,以實現更好的轉移性。
測試
MirrorFusion 2.0在MirrorBenchV2上與基線MirrorFusion進行測試,涵蓋單物體和多物體場景,並在MSD和Google Scanned Objects(GSO)數據集上進行定性測試。
評估使用2,991個單物體和300個雙物體場景,測量PSNR、SSIM和LPIPS以評估反射質量,以及CLIP以評估提示對齊。圖像使用四個種子生成,選擇最佳SSIM分數。

左側:MirrorBenchV2單物體反射質量,MirrorFusion 2.0優於基線。右側:多物體反射質量,多物體訓練改善結果。
作者指出:
「我們的方法優於基線,多物體微調增強了複雜場景的結果。」
定性測試強調了MirrorFusion 2.0的改進:

MirrorBenchV2比較:基線顯示錯誤的椅子方向和扭曲反射;MirrorFusion 2.0渲染準確。
基線在物體方向和空間偽影方面表現不佳,而在SynMirrorV2上訓練的MirrorFusion 2.0保持了準確的定位和真實的反射。
GSO數據集結果:

GSO比較:基線扭曲物體結構;MirrorFusion 2.0保持幾何、顏色和細節。
作者評論:
「MirrorFusion 2.0準確反映細節,如抽屜把手,而基線生成不合理的結果。」
現實世界MSD數據集結果:

MSD結果:在MSD上微調的MirrorFusion 2.0準確捕捉複雜場景,包括雜亂物體和多個鏡子。
在MSD上微調改進了MirrorFusion 2.0對複雜現實世界場景的處理,增強了反射一致性。
一項用戶研究發現84%的人偏好MirrorFusion 2.0的輸出。
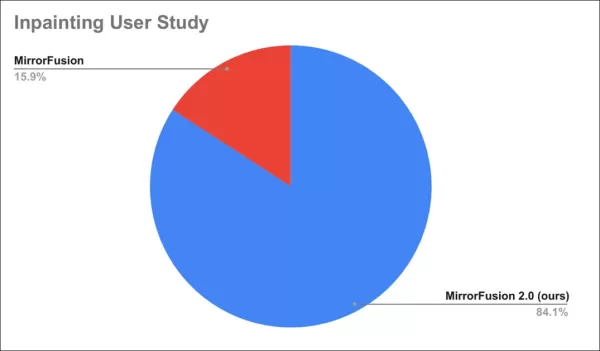
用戶研究結果。
結論
雖然MirrorFusion 2.0標誌著進展,但擴散模型在反射準確性方面的基線仍然較低,即使是適度的改進也顯著。擴散模型的架構在保持一致物理性方面存在困難,添加數據(如本文所述)是一種標準但有限的解決方案。
未來具有更好反射數據分佈的數據集可能會改善結果,但這適用於許多LDM弱點。優先解決哪些問題仍是一個挑戰。
首次發布於2025年4月28日星期一
相關文章
 WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理
Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
相關專題推薦
商業
WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理
Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
相關專題推薦
商業
 最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
 10 個工具
10 個工具
 xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai
教育與學習
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai
聊天機器人
最佳 AI 調情與對話訓練工具:即時提升社交魅力與自信
在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

 評論 (4)
0/500
評論 (4)
0/500
![GaryWalker]()
鏡の反射をリアルに描画するAIの進歩ってすごいですね!でも、これが深フェイクに悪用されたらどうなるんだろう…ちょっと怖いかも😅 反射の物理法則を理解するって、AIが現実世界を「見る」能力が向上している証拠でしょうか?
![JimmyWilson]()
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
![FredGreen]()
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
![RogerNelson]()
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯
自從生成式AI引起廣泛關注以來,計算機視覺研究人員已加緊努力開發能夠理解並複製物理定律的模型,特別是在過去五年中專注於模擬重力和流體動力學等挑戰。
自2022年以來,潛在擴散模型(LDMs)引領生成式AI,焦點轉向其在準確描繪物理現象方面的困難。此問題在OpenAI的Sora視頻模型以及最近的開源項目Hunyuan Video和Wan 2.1發布後引起更多關注。
反射的挑戰
改善LDMs對物理定律掌握的研究主要集中在步態模擬和牛頓運動等領域,因為這些方面的不準確會削弱AI生成視頻的真實感。
然而,越來越多的研究針對LDM的一個關鍵弱點:其生成準確反射的能力有限。
來自2025年1月論文《反映現實:使擴散模型生成忠實的鏡面反射》的示例,展示了“反射失敗”與研究人員自身方法的對比。 來源:https://arxiv.org/pdf/2409.14677
這一挑戰在CGI和視頻遊戲中也普遍存在,依賴光線追蹤算法來模擬光線與表面的交互,生成真實的反射、折射和陰影。
然而,每次額外的光線反射顯著增加計算需求,迫使即時應用在延遲與準確性之間平衡,通過限制反射次數來應對。
在3D(CGI)場景中的虛擬光束,使用1960年代的技術,於《創:戰記》(1982)與《侏羅紀公園》(1993)間完善。 來源:https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
例如,在鏡子前渲染一個鉻製茶壺涉及光線多次反射,形成幾乎無限的循環,但視覺收益甚微。通常兩到三次反射足以產生可感知的反射,因為單次反射會導致黑暗的鏡面。
每次額外反射使渲染時間翻倍,使得高效處理反射對於改善光線追蹤視覺效果至關重要。
反射對於照片級真實感至關重要,特別是在濕潤的城市街道、商店櫥窗反射或角色眼鏡等微妙場景中,物體和環境必須準確呈現。
通過傳統合成技術為《黑客帝國》(1999)中的場景創建的雙重反射。
視覺挑戰
在擴散模型之前,神經輻射場(NeRF)等框架以及較新的高斯濺射方法難以自然描繪反射。
REF2-NeRF項目提出了一種基於NeRF的方法,適用於包含玻璃櫃的場景,根據觀看者視角建模折射和反射。這允許估計玻璃表面並分離直接光與反射光。
來自Ref2Nerf論文的示例。 來源:https://arxiv.org/pdf/2311.17116
其他專注於反射的NeRF解決方案包括NeRFReN、反映現實,以及Meta於2024年推出的平面反射感知神經輻射場項目。
對於高斯濺射,Mirror-3DGS、反射高斯濺射和RefGaussian等努力解決了反射問題,而2023年的Nero項目引入了一種獨特的神經表示方法。
MirrorVerse突破
教導擴散模型處理反射邏輯比結構化方法如高斯濺射或NeRF更困難。擴散模型中的可靠反射依賴於多樣化、高質量的訓練數據,涵蓋各種場景。
傳統上,添加此類行為涉及LoRA或微調,但這些會導致輸出偏差或創建與原始模型不兼容的特定工具。
改進擴散模型需要強調反射物理的訓練數據。然而,為每個弱點策劃超大規模數據集成本高昂且不切實際。
儘管如此,解決方案正在湧現,例如印度的MirrorVerse項目,提供增強的數據集和訓練方法,以提升擴散模型中的反射準確性。
最右側,MirrorVerse的結果與之前兩種方法(中間兩列)對比。 來源:https://arxiv.org/pdf/2504.15397
如上所示,MirrorVerse改進了近期努力,但並非完美無缺。
在右上圖中,陶瓷罐略有錯位,在下圖中,出現了違反自然反射角度的錯誤杯子反射。
我們將探討此方法,並非作為最終解決方案,而是為了凸顯擴散模型在靜態和視頻格式中面臨的持續挑戰,其中反射數據通常與特定場景相關聯。
因此,LDMs在反射準確性上可能落後於NeRF、高斯濺射和傳統CGI。
論文《MirrorVerse:推動擴散模型真實反映世界》來自班加羅爾IISc視覺與AI實驗室以及三星研發研究所的研究人員,提供項目頁面、Hugging Face數據集和GitHub代碼。
方法
研究人員強調,像穩定擴散和Flux這樣的模型在處理基於反射的提示時面臨困難,如下所示:
來自論文:頂尖文本到圖像模型,SD3.5和Flux,在生成一致、幾何準確的反射方面面臨挑戰。
團隊開發了MirrorFusion 2.0,一種基於擴散的模型,以增強鏡面反射的照片真實感和幾何準確性。它在他們的MirrorGen2數據集上進行訓練,該數據集旨在解決泛化問題。
MirrorGen2引入了隨機物體定位、隨機旋轉和明確物體接地,以確保在多樣化物體放置中生成合理的反射。
MirrorVerse的合成數據架構:通過3D-Positioner隨機定位、旋轉和接地,配對物體以實現真實的空間交互。
MirrorGen2包括配對物體場景,以更好地處理反射環境中的遮擋和複雜空間排列。
論文指出:
「類別以語義一致性配對,如椅子與桌子。在定位主要物體後,添加次要物體而不重疊,確保不同的空間區域。」
對於物體接地,作者確保物體錨定在地面上,避免合成數據中不自然的「漂浮」現象。
由於數據集創新是論文新穎性的驅動力,我們接下來將討論這一點。
數據與測試
SynMirrorV2
SynMirrorV2數據集增強了反射訓練數據的多樣性,使用來自Objaverse和Amazon Berkeley Objects(ABO)的3D物體,通過OBJECT 3DIT和V1 MirrorFusion過濾進行精煉,產生66,062個高質量物體。
用於精選數據集的Objaverse數據集示例。 來源:https://arxiv.org/pdf/2212.08051
場景使用來自CC-Textures的紋理地板和PolyHaven的HDRI背景構建,採用全牆或矩形鏡子。照明使用45度角的區域光。物體被縮放,通過鏡面-相機視錐相交定位,並在y軸上隨機旋轉,接地以避免漂浮偽影。
多物體場景使用來自ABO的3,140個語義一致配對,避免重疊以捕捉多樣的遮擋和深度。
數據集中的渲染視圖,包含多個物體,展示分割和深度圖。
訓練過程
三階段課程學習過程訓練MirrorFusion 2.0,以實現穩健的現實世界泛化。
第一階段從穩定擴散v1.5初始化權重,在SynMirrorV2的單物體分割上進行40,000次迭代微調,保持條件和生成分支均活躍。
第二階段在SynMirrorV2的多物體分割上進行10,000次迭代微調,以處理遮擋和複雜場景。
第三階段添加10,000次迭代,使用現實世界的MSD數據集數據,結合Matterport3D深度圖。
MSD數據集示例,包含深度和分割圖。 來源:https://arxiv.org/pdf/1908.09101
文本提示有20%的時間被省略,以優先考慮深度信息。訓練使用四個NVIDIA A100 GPU,學習率為1e-5,每GPU批量大小為4,使用AdamW優化器。
這種漸進式訓練從簡單的合成場景轉向複雜的現實世界場景,以實現更好的轉移性。
測試
MirrorFusion 2.0在MirrorBenchV2上與基線MirrorFusion進行測試,涵蓋單物體和多物體場景,並在MSD和Google Scanned Objects(GSO)數據集上進行定性測試。
評估使用2,991個單物體和300個雙物體場景,測量PSNR、SSIM和LPIPS以評估反射質量,以及CLIP以評估提示對齊。圖像使用四個種子生成,選擇最佳SSIM分數。
左側:MirrorBenchV2單物體反射質量,MirrorFusion 2.0優於基線。右側:多物體反射質量,多物體訓練改善結果。
作者指出:
「我們的方法優於基線,多物體微調增強了複雜場景的結果。」
定性測試強調了MirrorFusion 2.0的改進:
MirrorBenchV2比較:基線顯示錯誤的椅子方向和扭曲反射;MirrorFusion 2.0渲染準確。
基線在物體方向和空間偽影方面表現不佳,而在SynMirrorV2上訓練的MirrorFusion 2.0保持了準確的定位和真實的反射。
GSO數據集結果:
GSO比較:基線扭曲物體結構;MirrorFusion 2.0保持幾何、顏色和細節。
作者評論:
「MirrorFusion 2.0準確反映細節,如抽屜把手,而基線生成不合理的結果。」
現實世界MSD數據集結果:
MSD結果:在MSD上微調的MirrorFusion 2.0準確捕捉複雜場景,包括雜亂物體和多個鏡子。
在MSD上微調改進了MirrorFusion 2.0對複雜現實世界場景的處理,增強了反射一致性。
一項用戶研究發現84%的人偏好MirrorFusion 2.0的輸出。
用戶研究結果。
結論
雖然MirrorFusion 2.0標誌著進展,但擴散模型在反射準確性方面的基線仍然較低,即使是適度的改進也顯著。擴散模型的架構在保持一致物理性方面存在困難,添加數據(如本文所述)是一種標準但有限的解決方案。
未來具有更好反射數據分佈的數據集可能會改善結果,但這適用於許多LDM弱點。優先解決哪些問題仍是一個挑戰。
首次發布於2025年4月28日星期一










 WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理
WordPress.com 現已允許 AI 代理程式撰寫並發布文章,還有更多功能
廣受歡迎的網站託管與發佈平台 WordPress.com 現正積極導入 AI 代理程式——此舉可能重塑網路的樣貌與使用體驗。該公司於週五宣布,將允許 AI 代理程式在客戶網站上起草、編輯及發佈內容,同時也能管理留言、更新與修正元資料,並透過標籤和分類來整理內容。所有這些操作皆透過一個介面進行控制,網站擁有者只需使用自然語言指令說明其需求即可。憑藉這些新功能,網站幾乎可以完全由人工指導的 AI 代理
 Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
Anthropic 的實驗性 AI「Claude」在電子商務測試中完成了談判與交易
隨著人工智慧的快速發展,Anthropic 上週五悄悄推出了一項名為「Project Deal」的內部實驗,展現了人工智慧在電子商務領域的潛力。該實驗讓其人工智慧模型 Claude 在封閉的市場環境中自主處理買賣及價格協商,並涉及真實的金融交易。實驗的核心是一個建構於 Slack 平台上的內部市場,Claude 在其中同時擔任買方與賣方的談判代表。它首先訪談了 69 名員工,以收集他們的買賣意圖及
 DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen
DeepSeek Code 即將推出
隨著人工智慧技術的加速發展,DeepSeek 正處於一個令人振奮的轉捩點。這家人工智慧公司最近透露,已獲得超過 700 億元的資金。管理層強調,公司致力於突破性的人工智慧研究,而非追求眼前的商業利益。這一戰略轉向表明 DeepSeek 將全力投入新產品的開發,尤其是眾人矚目的 DeepSeek Code。DeepSeek Code 的規劃已逐漸成形,該公司職缺頁面已發布數個相關職位,例如「Agen

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

鏡の反射をリアルに描画するAIの進歩ってすごいですね!でも、これが深フェイクに悪用されたらどうなるんだろう…ちょっと怖いかも😅 反射の物理法則を理解するって、AIが現実世界を「見る」能力が向上している証拠でしょうか?
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯













