




Nâng cao Khả năng của AI trong Việc Tạo Hình Phản chiếu Gương Thực tế
Kể từ khi AI tạo sinh thu hút sự chú ý rộng rãi, các nhà nghiên cứu về thị giác máy tính đã tăng cường nỗ lực phát triển các mô hình nắm bắt và tái tạo các quy luật vật lý, đặc biệt tập trung vào các thách thức như mô phỏng trọng lực và động lực học chất lỏng trong suốt năm năm qua.
Với các mô hình khuếch tán tiềm ẩn (LDMs) dẫn đầu trong lĩnh vực AI tạo sinh từ năm 2022, sự chú ý đã chuyển sang những khó khăn của chúng trong việc mô tả chính xác các hiện tượng vật lý. Vấn đề này đã thu hút sự quan tâm sau mô hình video Sora của OpenAI và các bản phát hành mã nguồn mở gần đây của Hunyuan Video và Wan 2.1.
Những khó khăn với Phản chiếu
Nghiên cứu để cải thiện khả năng nắm bắt vật lý của LDMs chủ yếu tập trung vào các lĩnh vực như mô phỏng dáng đi và chuyển động Newton, vì những sai sót ở đây làm giảm tính chân thực của các video do AI tạo ra.
Tuy nhiên, một lượng lớn nghiên cứu đang nhắm đến một điểm yếu quan trọng của LDM: khả năng hạn chế trong việc tạo ra các phản chiếu chính xác.

Từ bài báo tháng 1 năm 2025 ‘Phản chiếu Thực tế: Kích hoạt Mô hình Khuếch tán để Tạo Phản chiếu Gương Trung thực’, ví dụ về ‘thất bại trong phản chiếu’ so với phương pháp của các nhà nghiên cứu. Nguồn: https://arxiv.org/pdf/2409.14677
Thách thức này, cũng phổ biến trong CGI và trò chơi điện tử, dựa vào các thuật toán truy vết tia để mô phỏng sự tương tác của ánh sáng với bề mặt, tạo ra các phản chiếu, khúc xạ và bóng đổ chân thực.
Tuy nhiên, mỗi lần tia sáng bật thêm một lần sẽ làm tăng đáng kể nhu cầu tính toán, buộc các ứng dụng thời gian thực phải cân bằng giữa độ trễ và độ chính xác bằng cách giới hạn số lần bật.
![Hình ảnh đại diện của một tia sáng được tính toán ảo trong kịch bản dựa trên 3D truyền thống (tức là CGI), sử dụng các công nghệ và nguyên lý được phát triển lần đầu vào những năm 1960, và đạt được thành tựu từ năm 1982-93 (khoảng thời gian giữa Tron [198oltura và Jurassic Park [1993]). Nguồn: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing](https://img.xix.ai/uploads/55/680fa78ce2769.webp)
Một tia sáng ảo trong kịch bản dựa trên 3D (CGI), sử dụng các kỹ thuật từ những năm 1960, được tinh chỉnh giữa ‘Tron’ (1982) và ‘Jurassic Park’ (1993). Nguồn: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
Ví dụ, việc dựng hình một ấm trà bằng chrome trước gương liên quan đến việc tia sáng bật đi bật lại nhiều lần, tạo ra các vòng lặp gần như vô hạn với lợi ích thị giác tối thiểu. Thông thường, hai đến ba lần bật là đủ để tạo ra phản chiếu có thể nhận thấy, vì một lần bật duy nhất sẽ cho ra một chiếc gương tối.
Mỗi lần bật thêm sẽ làm tăng gấp đôi thời gian dựng hình, khiến việc xử lý phản chiếu hiệu quả trở nên quan trọng để cải thiện hình ảnh truy vết tia.
Phản chiếu rất quan trọng cho tính chân thực trong các trường hợp tinh tế hơn, như đường phố ẩm ướt, phản chiếu cửa sổ cửa hàng, hoặc kính của nhân vật, nơi các vật thể và môi trường phải xuất hiện chính xác.

Một phản chiếu đôi được tạo ra thông qua kỹ thuật compositing truyền thống cho một cảnh trong ‘The Matrix’ (1999).
Thách thức trong Hình ảnh
Trước các mô hình khuếch tán, các khung như Neural Radiance Fields (NeRF) và các phương pháp mới hơn như Gaussian Splatting đã gặp khó khăn trong việc mô tả phản chiếu một cách tự nhiên.
Dự án REF2-NeRF đã đề xuất một phương pháp dựa trên NeRF cho các cảnh có hộp kính, mô hình hóa khúc xạ và phản chiếu dựa trên góc nhìn của người xem. Điều này cho phép ước lượng bề mặt kính và tách biệt ánh sáng trực tiếp và ánh sáng phản chiếu.

Ví dụ từ bài báo Ref2Nerf. Nguồn: https://arxiv.org/pdf/2311.17116
Các giải pháp NeRF tập trung vào phản chiếu khác bao gồm NeRFReN, Reflecting Reality, và dự án Planar Reflection-Aware Neural Radiance Fields của Meta năm 2024.
Đối với Gaussian Splatting, các nỗ lực như Mirror-3DGS, Reflective Gaussian Splatting, và RefGaussian đã giải quyết các vấn đề phản chiếu, trong khi dự án Nero năm 2023 đã giới thiệu một phương pháp độc đáo cho các biểu diễn thần kinh.
Đột phá MirrorVerse
Việc dạy các mô hình khuếch tán xử lý logic phản chiếu khó khăn hơn so với các phương pháp cấu trúc như Gaussian Splatting hoặc NeRF. Phản chiếu đáng tin cậy trong các mô hình khuếch tán phụ thuộc vào dữ liệu huấn luyện đa dạng, chất lượng cao trong các kịch bản khác nhau.
Thông thường, việc thêm các hành vi như vậy liên quan đến LoRA hoặc tinh chỉnh, nhưng những phương pháp này làm sai lệch đầu ra hoặc tạo ra các công cụ dành riêng cho mô hình không tương thích với mô hình gốc.
Việc cải thiện các mô hình khuếch tán đòi hỏi dữ liệu huấn luyện nhấn mạnh vào vật lý phản chiếu. Tuy nhiên, việc xây dựng các tập dữ liệu quy mô lớn cho mọi điểm yếu là tốn kém và không thực tế.
Dù vậy, các giải pháp vẫn xuất hiện, như dự án MirrorVerse của Ấn Độ, cung cấp một tập dữ liệu cải tiến và phương pháp huấn luyện để nâng cao độ chính xác phản chiếu trong các mô hình khuếch tán.

Bên phải nhất, kết quả MirrorVerse so sánh với hai phương pháp trước đó (cột giữa). Nguồn: https://arxiv.org/pdf/2504.15397
Như đã thể hiện ở trên, MirrorVerse cải thiện so với các nỗ lực gần đây nhưng không hoàn hảo.
Trong hình ảnh trên cùng bên phải, các lọ gốm hơi lệch, và ở hình ảnh phía dưới, một phản chiếu cốc sai xuất hiện trái với các góc phản chiếu tự nhiên.
Chúng tôi sẽ khám phá phương pháp này không phải như một giải pháp cuối cùng mà để làm nổi bật những thách thức liên tục mà các mô hình khuếch tán đối mặt trong các định dạng tĩnh và video, nơi dữ liệu phản chiếu thường gắn liền với các kịch bản cụ thể.
Do đó, LDMs có thể tụt hậu so với NeRF, Gaussian Splatting và CGI truyền thống về độ chính xác phản chiếu.
Bài báo, MirrorVerse: Đẩy Mô hình Khuếch tán để Phản chiếu Thế giới một cách Thực tế, đến từ các nhà nghiên cứu tại Vision and AI Lab, IISc Bangalore, và Samsung R&D Institute, Bangalore, với một trang dự án, tập dữ liệu Hugging Face, và mã GitHub.
Phương pháp
Các nhà nghiên cứu nhấn mạnh khó khăn mà các mô hình như Stable Diffusion và Flux gặp phải với các gợi ý dựa trên phản chiếu, như thể hiện dưới đây:

Từ bài báo: Các mô hình chuyển văn bản thành hình ảnh hàng đầu, SD3.5 và Flux, gặp khó khăn trong việc tạo ra các phản chiếu nhất quán, chính xác về mặt hình học.
Nhóm nghiên cứu đã phát triển MirrorFusion 2.0, một mô hình dựa trên khuếch tán để nâng cao tính chân thực và độ chính xác hình học của các phản chiếu gương. Nó được huấn luyện trên tập dữ liệu MirrorGen2, được thiết kế để giải quyết các vấn đề khái quát hóa.
MirrorGen2 giới thiệu định vị đối tượng ngẫu nhiên, xoay ngẫu nhiên, và nền tảng đối tượng rõ ràng để đảm bảo các phản chiếu hợp lý trên các vị trí đối tượng đa dạng.
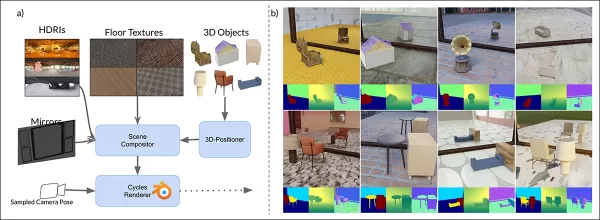
Sơ đồ dữ liệu tổng hợp của MirrorVerse: định vị ngẫu nhiên, xoay và nền tảng thông qua 3D-Positioner, với các đối tượng ghép đôi để tạo tương tác không gian thực tế.
MirrorGen2 bao gồm các cảnh đối tượng ghép đôi để xử lý tốt hơn các sự che khuất và các sắp xếp không gian phức tạp trong các cài đặt phản chiếu.
Bài báo ghi chú:
‘Các danh mục được ghép đôi để đảm bảo tính nhất quán ngữ nghĩa, như ghế với bàn. Sau khi định vị đối tượng chính, một đối tượng phụ được thêm vào mà không chồng lấn, đảm bảo các vùng không gian riêng biệt.’
Đối với nền tảng đối tượng, các tác giả đảm bảo các đối tượng được neo vào mặt đất, tránh tình trạng ‘trôi nổi’ không tự nhiên trong dữ liệu tổng hợp.
Vì sự đổi mới tập dữ liệu là yếu tố tạo nên tính mới mẻ của bài báo, chúng tôi sẽ đề cập đến điều này tiếp theo.
Dữ liệu và Thử nghiệm
SynMirrorV2
Tập dữ liệu SynMirrorV2 tăng cường sự đa dạng của dữ liệu huấn luyện phản chiếu, sử dụng các đối tượng 3D từ Objaverse và Amazon Berkeley Objects (ABO), được tinh chỉnh thông qua lọc OBJECT 3DIT và V1 MirrorFusion, tạo ra 66.062 đối tượng chất lượng cao.

Ví dụ tập dữ liệu Objaverse được sử dụng cho tập dữ liệu được tinh chỉnh. Nguồn: https://arxiv.org/pdf/2212.08051
Các cảnh được xây dựng với sàn có kết cấu từ CC-Textures và nền HDRI từ PolyHaven, sử dụng gương toàn tường hoặc hình chữ nhật. Ánh sáng sử dụng một đèn khu vực ở góc 45 độ. Các đối tượng được thu nhỏ, định vị thông qua giao điểm frustum gương-máy ảnh, và xoay ngẫu nhiên trên trục y, với nền tảng để tránh hiện tượng trôi nổi.
Các cảnh nhiều đối tượng sử dụng 3.140 cặp ghép đôi nhất quán ngữ nghĩa từ ABO, tránh chồng lấn để ghi lại các sự che khuất và độ sâu đa dạng.

Các góc nhìn được dựng từ tập dữ liệu với nhiều đối tượng, hiển thị phân đoạn và bản đồ độ sâu.
Quy trình Huấn luyện
Một quy trình học tập theo giáo trình ba giai đoạn đã huấn luyện MirrorFusion 2.0 để đạt được khả năng khái quát hóa mạnh mẽ trong thế giới thực.
Giai đoạn 1 khởi tạo trọng số từ Stable Diffusion v1.5, tinh chỉnh trên phân tách đối tượng đơn của SynMirrorV2 trong 40.000 lần lặp, giữ cả nhánh điều kiện và tạo sinh hoạt động.
Giai đoạn 2 tinh chỉnh trong 10.000 lần lặp trên phân tách nhiều đối tượng của SynMirrorV2 để xử lý các sự che khuất và cảnh phức tạp.
Giai đoạn 3 thêm 10.000 lần lặp với dữ liệu tập dữ liệu MSD thế giới thực, sử dụng bản đồ độ sâu Matterport3D.

Ví dụ tập dữ liệu MSD với bản đồ độ sâu và phân đoạn. Nguồn: https://arxiv.org/pdf/1908.09101
Các gợi ý văn bản được bỏ qua 20% thời gian để ưu tiên thông tin độ sâu. Huấn luyện sử dụng bốn GPU NVIDIA A100, tốc độ học 1e-5, kích thước lô 4 mỗi GPU, và bộ tối ưu hóa AdamW.
Quy trình huấn luyện tiến bộ này chuyển từ các cảnh tổng hợp đơn giản sang các cảnh thế giới thực phức tạp để có khả năng chuyển giao tốt hơn.
Thử nghiệm
MirrorFusion 2.0 được thử nghiệm so với chuẩn MirrorFusion trên MirrorBenchV2, bao gồm các cảnh đối tượng đơn và nhiều đối tượng, với các thử nghiệm định tính trên tập dữ liệu MSD và Google Scanned Objects (GSO).
Đánh giá sử dụng 2.991 cảnh đối tượng đơn và 300 cảnh hai đối tượng, đo lường PSNR, SSIM, và LPIPS cho chất lượng phản chiếu, và CLIP cho sự căn chỉnh gợi ý. Hình ảnh được tạo với bốn hạt giống, chọn điểm SSIM tốt nhất.

Bên trái: Chất lượng phản chiếu đối tượng đơn trên MirrorBenchV2, với MirrorFusion 2.0 vượt trội so với chuẩn. Bên phải: Chất lượng phản chiếu nhiều đối tượng, với huấn luyện nhiều đối tượng cải thiện kết quả.
Các tác giả ghi chú:
‘Phương pháp của chúng tôi vượt trội so với chuẩn, và tinh chỉnh nhiều đối tượng cải thiện kết quả cảnh phức tạp.’
Các thử nghiệm định tính nhấn mạnh cải tiến của MirrorFusion 2.0:

So sánh MirrorBenchV2: Chuẩn hiển thị hướng ghế sai và phản chiếu méo mó; MirrorFusion 2.0 dựng chính xác.
Kết quả tập dữ liệu GSO:

So sánh GSO: Chuẩn méo mó cấu trúc đối tượng; MirrorFusion 2.0 bảo toàn hình học, màu sắc và chi tiết.
Các tác giả nhận xét:
‘MirrorFusion 2.0 phản chiếu chính xác các chi tiết như tay cầm ngăn kéo, trong khi chuẩn tạo ra kết quả không hợp lý.’
Kết quả tập dữ liệu MSD thế giới thực:

Kết quả MSD: MirrorFusion 2.0, được tinh chỉnh trên MSD, ghi lại các cảnh phức tạp với các đối tượng lộn xộn và nhiều gương chính xác.
Tinh chỉnh trên MSD đã cải thiện khả năng xử lý các cảnh thế giới thực phức tạp của MirrorFusion 2.0, nâng cao tính nhất quán phản chiếu.
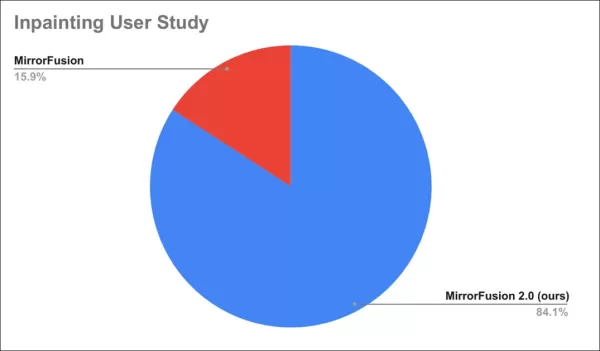
Một nghiên cứu người dùng cho thấy 84% thích đầu ra của MirrorFusion 2.0.
Kết quả nghiên cứu người dùng.
Kết luận
Dù MirrorFusion 2.0 đánh dấu sự tiến bộ, chuẩn mực cho độ chính xác phản chiếu trong các mô hình khuếch tán vẫn còn thấp, khiến ngay cả những cải tiến nhỏ cũng đáng chú ý. Kiến trúc của các mô hình khuếch tán gặp khó khăn với vật lý nhất quán, và việc thêm dữ liệu, như được thực hiện ở đây, là một cách sửa chữa tiêu chuẩn nhưng có giới hạn.
Các tập dữ liệu tương lai với phân phối dữ liệu phản chiếu tốt hơn có thể cải thiện kết quả, nhưng điều này áp dụng cho nhiều điểm yếu của LDM. Việc ưu tiên giải quyết vấn đề nào vẫn là một thách thức.
Được xuất bản lần đầu vào Thứ Hai, ngày 28 tháng 4 năm 2025
Bài viết liên quan
 Chiến lược TradingView được hỗ trợ bởi AI để nâng cao độ chính xác
Trong bối cảnh giao dịch nhịp độ nhanh, các công cụ hiệu quả là rất quan trọng. Bài viết này giới thiệu một chiến lược TradingView được tối ưu hóa sử dụng các chỉ báo AI để tăng cường độ chính xác và
Tạo Logo Độc Đáo với AI: Hướng Dẫn Từng Bước
Thiết kế một logo chuyên nghiệp có thể là một thách thức đối với các doanh nghiệp, công ty khởi nghiệp và thương hiệu cá nhân. Các phương pháp truyền thống thường yêu cầu các nhà thiết kế tốn kém hoặc
Sự phụ thuộc vào AI có thể làm suy yếu tư duy phản biện: Nghiên cứu MIT tiết lộ rủi ro nhận thức
Trong thời đại mà các công cụ AI như ChatGPT phổ biến như kiểm tra chính tả, một nghiên cứu MIT cảnh báo rằng sự phụ thuộc ngày càng tăng vào các mô hình ngôn ngữ lớn (LLMs) có thể âm thầm làm suy yếu
Nhận xét (0)
0/200
Chiến lược TradingView được hỗ trợ bởi AI để nâng cao độ chính xác
Trong bối cảnh giao dịch nhịp độ nhanh, các công cụ hiệu quả là rất quan trọng. Bài viết này giới thiệu một chiến lược TradingView được tối ưu hóa sử dụng các chỉ báo AI để tăng cường độ chính xác và
Tạo Logo Độc Đáo với AI: Hướng Dẫn Từng Bước
Thiết kế một logo chuyên nghiệp có thể là một thách thức đối với các doanh nghiệp, công ty khởi nghiệp và thương hiệu cá nhân. Các phương pháp truyền thống thường yêu cầu các nhà thiết kế tốn kém hoặc
Sự phụ thuộc vào AI có thể làm suy yếu tư duy phản biện: Nghiên cứu MIT tiết lộ rủi ro nhận thức
Trong thời đại mà các công cụ AI như ChatGPT phổ biến như kiểm tra chính tả, một nghiên cứu MIT cảnh báo rằng sự phụ thuộc ngày càng tăng vào các mô hình ngôn ngữ lớn (LLMs) có thể âm thầm làm suy yếu
Nhận xét (0)
0/200
Kể từ khi AI tạo sinh thu hút sự chú ý rộng rãi, các nhà nghiên cứu về thị giác máy tính đã tăng cường nỗ lực phát triển các mô hình nắm bắt và tái tạo các quy luật vật lý, đặc biệt tập trung vào các thách thức như mô phỏng trọng lực và động lực học chất lỏng trong suốt năm năm qua.
Với các mô hình khuếch tán tiềm ẩn (LDMs) dẫn đầu trong lĩnh vực AI tạo sinh từ năm 2022, sự chú ý đã chuyển sang những khó khăn của chúng trong việc mô tả chính xác các hiện tượng vật lý. Vấn đề này đã thu hút sự quan tâm sau mô hình video Sora của OpenAI và các bản phát hành mã nguồn mở gần đây của Hunyuan Video và Wan 2.1.
Những khó khăn với Phản chiếu
Nghiên cứu để cải thiện khả năng nắm bắt vật lý của LDMs chủ yếu tập trung vào các lĩnh vực như mô phỏng dáng đi và chuyển động Newton, vì những sai sót ở đây làm giảm tính chân thực của các video do AI tạo ra.
Tuy nhiên, một lượng lớn nghiên cứu đang nhắm đến một điểm yếu quan trọng của LDM: khả năng hạn chế trong việc tạo ra các phản chiếu chính xác.
Từ bài báo tháng 1 năm 2025 ‘Phản chiếu Thực tế: Kích hoạt Mô hình Khuếch tán để Tạo Phản chiếu Gương Trung thực’, ví dụ về ‘thất bại trong phản chiếu’ so với phương pháp của các nhà nghiên cứu. Nguồn: https://arxiv.org/pdf/2409.14677
Thách thức này, cũng phổ biến trong CGI và trò chơi điện tử, dựa vào các thuật toán truy vết tia để mô phỏng sự tương tác của ánh sáng với bề mặt, tạo ra các phản chiếu, khúc xạ và bóng đổ chân thực.
Tuy nhiên, mỗi lần tia sáng bật thêm một lần sẽ làm tăng đáng kể nhu cầu tính toán, buộc các ứng dụng thời gian thực phải cân bằng giữa độ trễ và độ chính xác bằng cách giới hạn số lần bật.
Một tia sáng ảo trong kịch bản dựa trên 3D (CGI), sử dụng các kỹ thuật từ những năm 1960, được tinh chỉnh giữa ‘Tron’ (1982) và ‘Jurassic Park’ (1993). Nguồn: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
Ví dụ, việc dựng hình một ấm trà bằng chrome trước gương liên quan đến việc tia sáng bật đi bật lại nhiều lần, tạo ra các vòng lặp gần như vô hạn với lợi ích thị giác tối thiểu. Thông thường, hai đến ba lần bật là đủ để tạo ra phản chiếu có thể nhận thấy, vì một lần bật duy nhất sẽ cho ra một chiếc gương tối.
Mỗi lần bật thêm sẽ làm tăng gấp đôi thời gian dựng hình, khiến việc xử lý phản chiếu hiệu quả trở nên quan trọng để cải thiện hình ảnh truy vết tia.
Phản chiếu rất quan trọng cho tính chân thực trong các trường hợp tinh tế hơn, như đường phố ẩm ướt, phản chiếu cửa sổ cửa hàng, hoặc kính của nhân vật, nơi các vật thể và môi trường phải xuất hiện chính xác.
Một phản chiếu đôi được tạo ra thông qua kỹ thuật compositing truyền thống cho một cảnh trong ‘The Matrix’ (1999).
Thách thức trong Hình ảnh
Trước các mô hình khuếch tán, các khung như Neural Radiance Fields (NeRF) và các phương pháp mới hơn như Gaussian Splatting đã gặp khó khăn trong việc mô tả phản chiếu một cách tự nhiên.
Dự án REF2-NeRF đã đề xuất một phương pháp dựa trên NeRF cho các cảnh có hộp kính, mô hình hóa khúc xạ và phản chiếu dựa trên góc nhìn của người xem. Điều này cho phép ước lượng bề mặt kính và tách biệt ánh sáng trực tiếp và ánh sáng phản chiếu.
Ví dụ từ bài báo Ref2Nerf. Nguồn: https://arxiv.org/pdf/2311.17116
Các giải pháp NeRF tập trung vào phản chiếu khác bao gồm NeRFReN, Reflecting Reality, và dự án Planar Reflection-Aware Neural Radiance Fields của Meta năm 2024.
Đối với Gaussian Splatting, các nỗ lực như Mirror-3DGS, Reflective Gaussian Splatting, và RefGaussian đã giải quyết các vấn đề phản chiếu, trong khi dự án Nero năm 2023 đã giới thiệu một phương pháp độc đáo cho các biểu diễn thần kinh.
Đột phá MirrorVerse
Việc dạy các mô hình khuếch tán xử lý logic phản chiếu khó khăn hơn so với các phương pháp cấu trúc như Gaussian Splatting hoặc NeRF. Phản chiếu đáng tin cậy trong các mô hình khuếch tán phụ thuộc vào dữ liệu huấn luyện đa dạng, chất lượng cao trong các kịch bản khác nhau.
Thông thường, việc thêm các hành vi như vậy liên quan đến LoRA hoặc tinh chỉnh, nhưng những phương pháp này làm sai lệch đầu ra hoặc tạo ra các công cụ dành riêng cho mô hình không tương thích với mô hình gốc.
Việc cải thiện các mô hình khuếch tán đòi hỏi dữ liệu huấn luyện nhấn mạnh vào vật lý phản chiếu. Tuy nhiên, việc xây dựng các tập dữ liệu quy mô lớn cho mọi điểm yếu là tốn kém và không thực tế.
Dù vậy, các giải pháp vẫn xuất hiện, như dự án MirrorVerse của Ấn Độ, cung cấp một tập dữ liệu cải tiến và phương pháp huấn luyện để nâng cao độ chính xác phản chiếu trong các mô hình khuếch tán.
Bên phải nhất, kết quả MirrorVerse so sánh với hai phương pháp trước đó (cột giữa). Nguồn: https://arxiv.org/pdf/2504.15397
Như đã thể hiện ở trên, MirrorVerse cải thiện so với các nỗ lực gần đây nhưng không hoàn hảo.
Trong hình ảnh trên cùng bên phải, các lọ gốm hơi lệch, và ở hình ảnh phía dưới, một phản chiếu cốc sai xuất hiện trái với các góc phản chiếu tự nhiên.
Chúng tôi sẽ khám phá phương pháp này không phải như một giải pháp cuối cùng mà để làm nổi bật những thách thức liên tục mà các mô hình khuếch tán đối mặt trong các định dạng tĩnh và video, nơi dữ liệu phản chiếu thường gắn liền với các kịch bản cụ thể.
Do đó, LDMs có thể tụt hậu so với NeRF, Gaussian Splatting và CGI truyền thống về độ chính xác phản chiếu.
Bài báo, MirrorVerse: Đẩy Mô hình Khuếch tán để Phản chiếu Thế giới một cách Thực tế, đến từ các nhà nghiên cứu tại Vision and AI Lab, IISc Bangalore, và Samsung R&D Institute, Bangalore, với một trang dự án, tập dữ liệu Hugging Face, và mã GitHub.
Phương pháp
Các nhà nghiên cứu nhấn mạnh khó khăn mà các mô hình như Stable Diffusion và Flux gặp phải với các gợi ý dựa trên phản chiếu, như thể hiện dưới đây:
Từ bài báo: Các mô hình chuyển văn bản thành hình ảnh hàng đầu, SD3.5 và Flux, gặp khó khăn trong việc tạo ra các phản chiếu nhất quán, chính xác về mặt hình học.
Nhóm nghiên cứu đã phát triển MirrorFusion 2.0, một mô hình dựa trên khuếch tán để nâng cao tính chân thực và độ chính xác hình học của các phản chiếu gương. Nó được huấn luyện trên tập dữ liệu MirrorGen2, được thiết kế để giải quyết các vấn đề khái quát hóa.
MirrorGen2 giới thiệu định vị đối tượng ngẫu nhiên, xoay ngẫu nhiên, và nền tảng đối tượng rõ ràng để đảm bảo các phản chiếu hợp lý trên các vị trí đối tượng đa dạng.
Sơ đồ dữ liệu tổng hợp của MirrorVerse: định vị ngẫu nhiên, xoay và nền tảng thông qua 3D-Positioner, với các đối tượng ghép đôi để tạo tương tác không gian thực tế.
MirrorGen2 bao gồm các cảnh đối tượng ghép đôi để xử lý tốt hơn các sự che khuất và các sắp xếp không gian phức tạp trong các cài đặt phản chiếu.
Bài báo ghi chú:
‘Các danh mục được ghép đôi để đảm bảo tính nhất quán ngữ nghĩa, như ghế với bàn. Sau khi định vị đối tượng chính, một đối tượng phụ được thêm vào mà không chồng lấn, đảm bảo các vùng không gian riêng biệt.’
Đối với nền tảng đối tượng, các tác giả đảm bảo các đối tượng được neo vào mặt đất, tránh tình trạng ‘trôi nổi’ không tự nhiên trong dữ liệu tổng hợp.
Vì sự đổi mới tập dữ liệu là yếu tố tạo nên tính mới mẻ của bài báo, chúng tôi sẽ đề cập đến điều này tiếp theo.
Dữ liệu và Thử nghiệm
SynMirrorV2
Tập dữ liệu SynMirrorV2 tăng cường sự đa dạng của dữ liệu huấn luyện phản chiếu, sử dụng các đối tượng 3D từ Objaverse và Amazon Berkeley Objects (ABO), được tinh chỉnh thông qua lọc OBJECT 3DIT và V1 MirrorFusion, tạo ra 66.062 đối tượng chất lượng cao.
Ví dụ tập dữ liệu Objaverse được sử dụng cho tập dữ liệu được tinh chỉnh. Nguồn: https://arxiv.org/pdf/2212.08051
Các cảnh được xây dựng với sàn có kết cấu từ CC-Textures và nền HDRI từ PolyHaven, sử dụng gương toàn tường hoặc hình chữ nhật. Ánh sáng sử dụng một đèn khu vực ở góc 45 độ. Các đối tượng được thu nhỏ, định vị thông qua giao điểm frustum gương-máy ảnh, và xoay ngẫu nhiên trên trục y, với nền tảng để tránh hiện tượng trôi nổi.
Các cảnh nhiều đối tượng sử dụng 3.140 cặp ghép đôi nhất quán ngữ nghĩa từ ABO, tránh chồng lấn để ghi lại các sự che khuất và độ sâu đa dạng.
Các góc nhìn được dựng từ tập dữ liệu với nhiều đối tượng, hiển thị phân đoạn và bản đồ độ sâu.
Quy trình Huấn luyện
Một quy trình học tập theo giáo trình ba giai đoạn đã huấn luyện MirrorFusion 2.0 để đạt được khả năng khái quát hóa mạnh mẽ trong thế giới thực.
Giai đoạn 1 khởi tạo trọng số từ Stable Diffusion v1.5, tinh chỉnh trên phân tách đối tượng đơn của SynMirrorV2 trong 40.000 lần lặp, giữ cả nhánh điều kiện và tạo sinh hoạt động.
Giai đoạn 2 tinh chỉnh trong 10.000 lần lặp trên phân tách nhiều đối tượng của SynMirrorV2 để xử lý các sự che khuất và cảnh phức tạp.
Giai đoạn 3 thêm 10.000 lần lặp với dữ liệu tập dữ liệu MSD thế giới thực, sử dụng bản đồ độ sâu Matterport3D.
Ví dụ tập dữ liệu MSD với bản đồ độ sâu và phân đoạn. Nguồn: https://arxiv.org/pdf/1908.09101
Các gợi ý văn bản được bỏ qua 20% thời gian để ưu tiên thông tin độ sâu. Huấn luyện sử dụng bốn GPU NVIDIA A100, tốc độ học 1e-5, kích thước lô 4 mỗi GPU, và bộ tối ưu hóa AdamW.
Quy trình huấn luyện tiến bộ này chuyển từ các cảnh tổng hợp đơn giản sang các cảnh thế giới thực phức tạp để có khả năng chuyển giao tốt hơn.
Thử nghiệm
MirrorFusion 2.0 được thử nghiệm so với chuẩn MirrorFusion trên MirrorBenchV2, bao gồm các cảnh đối tượng đơn và nhiều đối tượng, với các thử nghiệm định tính trên tập dữ liệu MSD và Google Scanned Objects (GSO).
Đánh giá sử dụng 2.991 cảnh đối tượng đơn và 300 cảnh hai đối tượng, đo lường PSNR, SSIM, và LPIPS cho chất lượng phản chiếu, và CLIP cho sự căn chỉnh gợi ý. Hình ảnh được tạo với bốn hạt giống, chọn điểm SSIM tốt nhất.
Bên trái: Chất lượng phản chiếu đối tượng đơn trên MirrorBenchV2, với MirrorFusion 2.0 vượt trội so với chuẩn. Bên phải: Chất lượng phản chiếu nhiều đối tượng, với huấn luyện nhiều đối tượng cải thiện kết quả.
Các tác giả ghi chú:
‘Phương pháp của chúng tôi vượt trội so với chuẩn, và tinh chỉnh nhiều đối tượng cải thiện kết quả cảnh phức tạp.’
Các thử nghiệm định tính nhấn mạnh cải tiến của MirrorFusion 2.0:
So sánh MirrorBenchV2: Chuẩn hiển thị hướng ghế sai và phản chiếu méo mó; MirrorFusion 2.0 dựng chính xác.
Kết quả tập dữ liệu GSO:
So sánh GSO: Chuẩn méo mó cấu trúc đối tượng; MirrorFusion 2.0 bảo toàn hình học, màu sắc và chi tiết.
Các tác giả nhận xét:
‘MirrorFusion 2.0 phản chiếu chính xác các chi tiết như tay cầm ngăn kéo, trong khi chuẩn tạo ra kết quả không hợp lý.’
Kết quả tập dữ liệu MSD thế giới thực:
Kết quả MSD: MirrorFusion 2.0, được tinh chỉnh trên MSD, ghi lại các cảnh phức tạp với các đối tượng lộn xộn và nhiều gương chính xác.
Tinh chỉnh trên MSD đã cải thiện khả năng xử lý các cảnh thế giới thực phức tạp của MirrorFusion 2.0, nâng cao tính nhất quán phản chiếu.
Một nghiên cứu người dùng cho thấy 84% thích đầu ra của MirrorFusion 2.0.
Kết quả nghiên cứu người dùng.
Kết luận
Dù MirrorFusion 2.0 đánh dấu sự tiến bộ, chuẩn mực cho độ chính xác phản chiếu trong các mô hình khuếch tán vẫn còn thấp, khiến ngay cả những cải tiến nhỏ cũng đáng chú ý. Kiến trúc của các mô hình khuếch tán gặp khó khăn với vật lý nhất quán, và việc thêm dữ liệu, như được thực hiện ở đây, là một cách sửa chữa tiêu chuẩn nhưng có giới hạn.
Các tập dữ liệu tương lai với phân phối dữ liệu phản chiếu tốt hơn có thể cải thiện kết quả, nhưng điều này áp dụng cho nhiều điểm yếu của LDM. Việc ưu tiên giải quyết vấn đề nào vẫn là một thách thức.
Được xuất bản lần đầu vào Thứ Hai, ngày 28 tháng 4 năm 2025










 Chiến lược TradingView được hỗ trợ bởi AI để nâng cao độ chính xác
Trong bối cảnh giao dịch nhịp độ nhanh, các công cụ hiệu quả là rất quan trọng. Bài viết này giới thiệu một chiến lược TradingView được tối ưu hóa sử dụng các chỉ báo AI để tăng cường độ chính xác và
Chiến lược TradingView được hỗ trợ bởi AI để nâng cao độ chính xác
Trong bối cảnh giao dịch nhịp độ nhanh, các công cụ hiệu quả là rất quan trọng. Bài viết này giới thiệu một chiến lược TradingView được tối ưu hóa sử dụng các chỉ báo AI để tăng cường độ chính xác và
 Tạo Logo Độc Đáo với AI: Hướng Dẫn Từng Bước
Thiết kế một logo chuyên nghiệp có thể là một thách thức đối với các doanh nghiệp, công ty khởi nghiệp và thương hiệu cá nhân. Các phương pháp truyền thống thường yêu cầu các nhà thiết kế tốn kém hoặc
Tạo Logo Độc Đáo với AI: Hướng Dẫn Từng Bước
Thiết kế một logo chuyên nghiệp có thể là một thách thức đối với các doanh nghiệp, công ty khởi nghiệp và thương hiệu cá nhân. Các phương pháp truyền thống thường yêu cầu các nhà thiết kế tốn kém hoặc
 Sự phụ thuộc vào AI có thể làm suy yếu tư duy phản biện: Nghiên cứu MIT tiết lộ rủi ro nhận thức
Trong thời đại mà các công cụ AI như ChatGPT phổ biến như kiểm tra chính tả, một nghiên cứu MIT cảnh báo rằng sự phụ thuộc ngày càng tăng vào các mô hình ngôn ngữ lớn (LLMs) có thể âm thầm làm suy yếu
Sự phụ thuộc vào AI có thể làm suy yếu tư duy phản biện: Nghiên cứu MIT tiết lộ rủi ro nhận thức
Trong thời đại mà các công cụ AI như ChatGPT phổ biến như kiểm tra chính tả, một nghiên cứu MIT cảnh báo rằng sự phụ thuộc ngày càng tăng vào các mô hình ngôn ngữ lớn (LLMs) có thể âm thầm làm suy yếu













