
















 Heim
HeimVerbesserung der Fähigkeit von KI, realistische Spiegelreflexionen darzustellen
Seit generative KI breite Aufmerksamkeit erregt hat, haben Forscher im Bereich der Computervision ihre Bemühungen verstärkt, Modelle zu entwickeln, die physikalische Gesetze verstehen und nachbilden können, mit einem besonderen Fokus auf Herausforderungen wie der Simulation von Schwerkraft und Flüssigkeitsdynamik in den letzten fünf Jahren.
Mit latenten Diffusionsmodellen (LDMs), die seit 2022 die generative KI anführen, hat sich die Aufmerksamkeit auf ihre Schwierigkeiten bei der genauen Darstellung physikalischer Phänomene verlagert. Dieses Problem hat nach der Einführung des Sora-Videomodells von OpenAI und den kürzlich erfolgten Open-Source-Veröffentlichungen von Hunyuan Video und Wan 2.1 an Bedeutung gewonnen.
Herausforderungen bei Reflexionen
Die Forschung zur Verbesserung der Physikverständnisse von LDMs hat sich größtenteils auf Bereiche wie Gangsimulation und Newtonsche Bewegung konzentriert, da Ungenauigkeiten hier die Realität von KI-generierten Videos untergraben.
Dennoch zielt eine wachsende Anzahl von Arbeiten auf eine zentrale Schwäche von LDMs ab: ihre begrenzte Fähigkeit, genaue Reflexionen zu erzeugen.

Aus dem Januar 2025 Papier 'Realität widerspiegeln: Ermöglichung von Diffusionsmodellen, getreue Spiegelreflexionen zu erzeugen', Beispiele für 'Reflexionsfehler' im Vergleich zum Ansatz der Forscher. Quelle: https://arxiv.org/pdf/2409.14677
Diese Herausforderung, die auch in CGI und Videospielen weit verbreitet ist, stützt sich auf Ray-Tracing-Algorithmen, um die Interaktion von Licht mit Oberflächen zu simulieren und realistische Reflexionen, Brechungen und Schatten zu erzeugen.
Jedoch erhöht jeder zusätzliche Lichtstrahl-Sprung den Rechenaufwand erheblich, was Echtzeitanwendungen dazu zwingt, Latenz und Genauigkeit auszugleichen, indem die Anzahl der Sprünge begrenzt wird.
![Eine Darstellung eines virtuell berechneten Lichtstrahls in einem traditionellen 3D-basierten (d.h. CGI) Szenario, unter Verwendung von Technologien und Prinzipien, die erstmals in den 1960er Jahren entwickelt wurden und zwischen 1982-93 (der Zeitspanne zwischen Tron [1982] und Jurassic Park [1993]) zur Reife gelangten. Quelle: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing](https://img.xix.ai/uploads/55/680fa78ce2769.webp)
Ein virtueller Lichtstrahl in einem 3D-basierten (CGI) Szenario, unter Verwendung von Techniken aus den 1960er Jahren, verfeinert zwischen 'Tron' (1982) und 'Jurassic Park' (1993). Quelle: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
Zum Beispiel erfordert das Rendern einer Chrom-Teekanne vor einem Spiegel wiederholtes Springen von Lichtstrahlen, was nahezu unendliche Schleifen mit minimalem visuellem Nutzen erzeugt. Typischerweise reichen zwei bis drei Sprünge für wahrnehmbare Reflexionen, da ein einzelner Sprung einen dunklen Spiegel ergibt.
Jeder zusätzliche Sprung verdoppelt die Renderzeit, was ein effizientes Handling von Reflexionen entscheidend macht, um Ray-Tracing-Visuals zu verbessern.
Reflexionen sind entscheidend für Fotorealismus in subtileren Fällen, wie nassen Stadtstraßen, Schaufensterreflexionen oder Brillen von Charakteren, wo Objekte und Umgebungen genau dargestellt werden müssen.

Eine Zwillingsreflexion, erstellt durch traditionelles Compositing für eine Szene in 'The Matrix' (1999).
Herausforderungen in der Visualisierung
Vor Diffusionsmodellen hatten Frameworks wie Neural Radiance Fields (NeRF) und neuere Ansätze wie Gaussian Splatting Schwierigkeiten, Reflexionen natürlich darzustellen.
Das REF2-NeRF-Projekt schlug eine NeRF-basierte Methode für Szenen mit Glasvitrinen vor, die Brechung und Reflexion basierend auf der Perspektive des Betrachters modelliert. Dies ermöglichte die Schätzung von Glasoberflächen und die Trennung von direktem und reflektiertem Licht.

Beispiele aus dem Ref2Nerf-Papier. Quelle: https://arxiv.org/pdf/2311.17116
Weitere reflexionsfokussierte NeRF-Lösungen umfassen NeRFReN, Reflecting Reality und Metas 2024 Planar Reflection-Aware Neural Radiance Fields-Projekt.
Für Gaussian Splatting haben Projekte wie Mirror-3DGS, Reflective Gaussian Splatting und RefGaussian Reflexionsprobleme angegangen, während das 2023 Nero-Projekt eine einzigartige Methode für neuronale Repräsentationen einführte.
MirrorVerse-Durchbruch
Das Lehren von Diffusionsmodellen, Reflexionslogik zu handhaben, ist schwieriger als bei strukturellen Methoden wie Gaussian Splatting oder NeRF. Zuverlässige Reflexionen in Diffusionsmodellen hängen von vielfältigen, hochwertigen Trainingsdaten in unterschiedlichen Szenarien ab.
Traditionell beinhaltet das Hinzufügen solcher Verhaltensweisen LoRA oder Fine-Tuning, aber diese verzerren die Ausgaben oder erstellen modellspezifische Werkzeuge, die mit dem Originalmodell inkompatibel sind.
Die Verbesserung von Diffusionsmodellen erfordert Trainingsdaten, die die Physik von Reflexionen betonen. Das Kuratieren von hyperskaligen Datensätzen für jede Schwäche ist jedoch kostspielig und unpraktisch.
Dennoch entstehen Lösungen, wie Indiens MirrorVerse-Projekt, das einen erweiterten Datensatz und eine Trainingsmethode bietet, um die Reflexionsgenauigkeit in Diffusionsmodellen zu verbessern.

Ganz rechts die Ergebnisse von MirrorVerse im Vergleich zu zwei früheren Ansätzen (mittlere Spalten). Quelle: https://arxiv.org/pdf/2504.15397
Wie oben gezeigt, verbessert MirrorVerse die jüngsten Bemühungen, ist aber nicht fehlerfrei.
Im oberen rechten Bild sind Keramikkrüge leicht falsch ausgerichtet, und im unteren Bild erscheint eine fehlerhafte Tassenreflexion entgegen natürlicher Reflexionswinkel.
Wir werden diese Methode nicht als definitive Lösung untersuchen, sondern um die anhaltenden Herausforderungen zu beleuchten, denen Diffusionsmodelle in statischen und Videoformaten begegnen, wo Reflexionsdaten oft an spezifische Szenarien gebunden sind.
Daher könnten LDMs in der Reflexionsgenauigkeit hinter NeRF, Gaussian Splatting und traditionellem CGI zurückbleiben.
Das Papier, MirrorVerse: Diffusionsmodelle dazu bringen, die Welt realistisch widerzuspiegeln, stammt von Forschern des Vision and AI Lab, IISc Bangalore, und Samsung R&D Institute, Bangalore, mit einer Projektseite, einem Hugging Face-Datensatz und GitHub-Code.
Methodik
Die Forscher betonen die Schwierigkeiten, die Modelle wie Stable Diffusion und Flux mit reflexionsbasierten Eingaben haben, wie unten geಸ
System: gezeigt:

Aus dem Papier: Top-Text-zu-Bild-Modelle, SD3.5 und Flux, haben Schwierigkeiten mit konsistenten, geometrisch genauen Reflexionen.
Das Team entwickelte MirrorFusion 2.0, ein diffusionsbasiertes Modell, um den Fotorealismus und die geometrische Genauigkeit von Spiegelreflexionen zu verbessern. Es wurde auf ihrem MirrorGen2-Datensatz trainiert, der entwickelt wurde, um Verallgemeinerungsprobleme zu lösen.
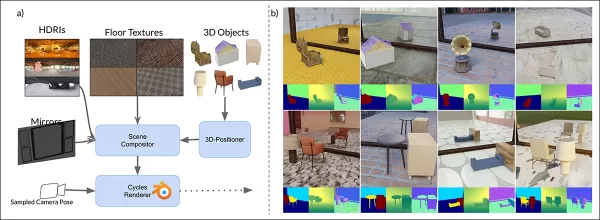
MirrorVerse’s Schema für synthetische Daten: zufällige Positionierung, Rotation und Verankerung durch den 3D-Positioner, mit gepaarten Objekten für realistische räumliche Interaktionen.
MirrorGen2 umfasst Szenen mit gepaarten Objekten, um Verdeckungen und komplexe räumliche Anordnungen in reflektierenden Umgebungen besser zu handhaben.
Das Papier stellt fest:
„Kategorien werden für semantische Kohärenz gepaart, wie ein Stuhl mit einem Tisch. Nach der Positionierung des primären Objekts wird ein sekundäres ohne Überlappung hinzugefügt, um unterschiedliche räumliche Bereiche zu gewährleisten.“
Für die Objektverankerung sorgten die Autoren dafür, dass Objekte am Boden verankert waren, um unnatürliches „Schweben“ in synthetischen Daten zu vermeiden.
Da die Innovation des Datensatzes die Neuheit des Papiers antreibt, werden wir dies als Nächstes behandeln.
Daten und Tests
SynMirrorV2
Der SynMirrorV2-Datensatz verbessert die Vielfalt der Trainingsdaten für Reflexionen, unter Verwendung von 3D-Objekten aus Objaverse und Amazon Berkeley Objects (ABO), verfeinert durch OBJECT 3DIT und V1 MirrorFusion-Filterung, was 66.062 hochwertige Objekte ergab.

Beispiele aus dem Objaverse-Datensatz, verwendet für den kuratierten Datensatz. Quelle: https://arxiv.org/pdf/2212.08051
Szenen wurden mit texturierten Böden von CC-Textures und HDRI-Hintergründen von PolyHaven erstellt, unter Verwendung von Wandspiegeln oder rechteckigen Spiegeln. Die Beleuchtung verwendete eine Flächenleuchte im 45-Grad-Winkel. Objekte wurden skaliert, über die Schnittmenge von Spiegel und Kamerasichtfeld positioniert und zufällig um die y-Achse rotiert, mit Verankerung, um schwebende Artefakte zu vermeiden.
Mehr-Objekt-Szenen verwendeten 3.140 semantisch kohärente Paarungen von ABO, wobei Überlappungen vermieden wurden, um verschiedene Verdeckungen und Tiefen zu erfassen.

Gerenderte Ansichten aus dem Datensatz mit mehreren Objekten, die Segmentierung und Tiefenkarten zeigen.
Trainingsprozess
Ein dreistufiger Lernprozess trainierte MirrorFusion 2.0 für robuste Verallgemeinerung in der realen Welt.
Stufe 1 initialisierte Gewichte von Stable Diffusion v1.5, mit Feinabstimmung auf der Einzelobjekt-Teilmenge von SynMirrorV2 für 40.000 Iterationen, wobei beide Konditionierungs- und Generierungsstränge aktiv blieben.
Stufe 2 feinabgestimmt für 10.000 Iterationen auf der Mehr-Objekt-Teilmenge von SynMirrorV2, um Verdeckungen und komplexe Szenen zu handhaben.
Stufe 3 fügte 10.000 Iterationen mit realen MSD-Datensatzdaten hinzu, unter Verwendung von Matterport3D-Tiefenkarten.

Beispiele aus dem MSD-Datensatz mit Tiefen- und Segmentierungskarten. Quelle: https://arxiv.org/pdf/1908.09101
Textprompts wurden in 20 % der Fälle weggelassen, um Tiefeninformationen zu priorisieren. Das Training verwendete vier NVIDIA A100 GPUs, eine Lernrate von 1e-5, eine Batchgröße von 4 pro GPU und den AdamW-Optimierer.
Dieses progressive Training verlief von einfachen synthetischen zu komplexen realen Szenen für bessere Übertragbarkeit.
Testen
MirrorFusion 2.0 wurde gegen die Basisversion MirrorFusion auf MirrorBenchV2 getestet, das Einzel- und Mehr-Objekt-Szenen abdeckte, mit qualitativen Tests auf MSD- und Google Scanned Objects (GSO)-Datensätzen.
Die Bewertung verwendete 2.991 Einzelobjekt- und 300 Zwei-Objekt-Szenen, wobei PSNR, SSIM und LPIPS für Reflexionsqualität und CLIP für die Prompt-Ausrichtung gemessen wurden. Bilder wurden mit vier Seeds generiert, wobei die beste SSIM-Bewertung ausgewählt wurde.

Links: Einzelobjekt-Reflexionsqualität auf MirrorBenchV2, mit MirrorFusion 2.0, das die Basisversion übertrifft. Rechts: Mehr-Objekt-Reflexionsqualität, mit Mehr-Objekt-Training verbessert die Ergebnisse.
Die Autoren stellen fest:
„Unsere Methode übertrifft die Basisversion, und Mehr-Objekt-Feinabstimmung verbessert die Ergebnisse komplexer Szenen.“
Qualitative Tests betonten die Verbesserungen von MirrorFusion 2.0:

Vergleich auf MirrorBenchV2: Basisversion zeigt falsche Stuhlausrichtung und verzerrte Reflexionen; MirrorFusion 2.0 rendert korrekt.
Die Basisversion hatte Probleme mit Objektausrichtung und räumlichen Artefakten, während MirrorFusion 2.0, trainiert auf SynMirrorV2, genaue Positionierung und realistische Reflexionen beibehielt.
Ergebnisse des GSO-Datensatzes:

GSO-Vergleich: Basisversion verzerrt Objektstruktur; MirrorFusion 2.0 bewahrt Geometrie, Farbe und Details.
Die Autoren kommentieren:
„MirrorFusion 2.0 spiegelt Details wie Schubladengriffe genau wider, während die Basisversion unplausible Ergebnisse liefert.“
Ergebnisse des realen MSD-Datensatzes:

MSD-Ergebnisse: MirrorFusion 2.0, feinabgestimmt auf MSD, erfasst komplexe Szenen mit überladenen Objekten und mehreren Spiegeln genau.
Die Feinabstimmung auf MSD verbesserte die Handhabung komplexer realer Szenen durch MirrorFusion 2.0 und erhöhte die Reflexionskohärenz.
Eine Nutzerstudie ergab, dass 84 % die Ausgaben von MirrorFusion 2.0 bevorzugten.
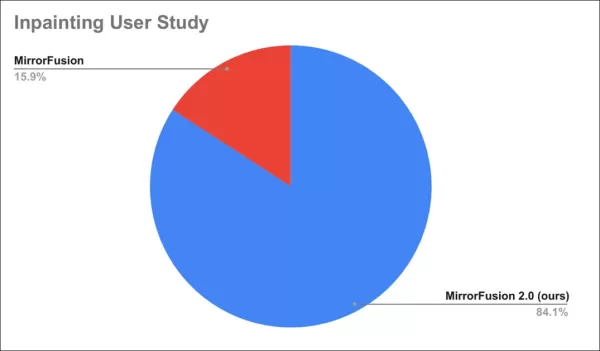
Ergebnisse der Nutzerstudie.
Fazit
Während MirrorFusion 2.0 Fortschritte markiert, bleibt die Basis für Reflexionsgenauigkeit in Diffusionsmodellen niedrig, was selbst bescheidene Verbesserungen bemerkenswert macht. Die Architektur von Diffusionsmodellen hat Schwierigkeiten mit konsistenter Physik, und das Hinzufügen von Daten, wie hier geschehen, ist eine Standard-, aber begrenzte Lösung.
Zukünftige Datensätze mit besserer Verteilung von Reflexionsdaten könnten die Ergebnisse verbessern, aber dies gilt für viele Schwächen von LDMs. Die Priorisierung der zu behandelnden Probleme bleibt eine Herausforderung.
Erstmals veröffentlicht am Montag, 28. April 2025
Verwandter Artikel
 OpenAI ändert heimlich seine Satzung, um die Entlassung von Altman zu erschweren
Nach dem putschähnlichen Vorfall im Jahr 2023 hat OpenAI den Schutz für CEO Sam Altman durch eine Aktualisierung der Unternehmenssatzung weiter gefestigt. Kürzlich veröffentlichte Gerichtsdokumente ze
Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Empfehlungen zu verwandten Spezialthemen
Produktivität
OpenAI ändert heimlich seine Satzung, um die Entlassung von Altman zu erschweren
Nach dem putschähnlichen Vorfall im Jahr 2023 hat OpenAI den Schutz für CEO Sam Altman durch eine Aktualisierung der Unternehmenssatzung weiter gefestigt. Kürzlich veröffentlichte Gerichtsdokumente ze
Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Empfehlungen zu verwandten Spezialthemen
Produktivität
 KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
 10 Tools
10 Tools
 xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai
Code
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai
Datenanalyse
Die besten KI-Tools zur Datenvisualisierung: Interaktive BI-Dashboards automatisch aus Rohdaten generieren
Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai

 Kommentare (4)
Kommentare (4)
![GaryWalker]()
鏡の反射をリアルに描画するAIの進歩ってすごいですね!でも、これが深フェイクに悪用されたらどうなるんだろう…ちょっと怖いかも😅 反射の物理法則を理解するって、AIが現実世界を「見る」能力が向上している証拠でしょうか?
![JimmyWilson]()
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
![FredGreen]()
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
![RogerNelson]()
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯
Seit generative KI breite Aufmerksamkeit erregt hat, haben Forscher im Bereich der Computervision ihre Bemühungen verstärkt, Modelle zu entwickeln, die physikalische Gesetze verstehen und nachbilden können, mit einem besonderen Fokus auf Herausforderungen wie der Simulation von Schwerkraft und Flüssigkeitsdynamik in den letzten fünf Jahren.
Mit latenten Diffusionsmodellen (LDMs), die seit 2022 die generative KI anführen, hat sich die Aufmerksamkeit auf ihre Schwierigkeiten bei der genauen Darstellung physikalischer Phänomene verlagert. Dieses Problem hat nach der Einführung des Sora-Videomodells von OpenAI und den kürzlich erfolgten Open-Source-Veröffentlichungen von Hunyuan Video und Wan 2.1 an Bedeutung gewonnen.
Herausforderungen bei Reflexionen
Die Forschung zur Verbesserung der Physikverständnisse von LDMs hat sich größtenteils auf Bereiche wie Gangsimulation und Newtonsche Bewegung konzentriert, da Ungenauigkeiten hier die Realität von KI-generierten Videos untergraben.
Dennoch zielt eine wachsende Anzahl von Arbeiten auf eine zentrale Schwäche von LDMs ab: ihre begrenzte Fähigkeit, genaue Reflexionen zu erzeugen.
Aus dem Januar 2025 Papier 'Realität widerspiegeln: Ermöglichung von Diffusionsmodellen, getreue Spiegelreflexionen zu erzeugen', Beispiele für 'Reflexionsfehler' im Vergleich zum Ansatz der Forscher. Quelle: https://arxiv.org/pdf/2409.14677
Diese Herausforderung, die auch in CGI und Videospielen weit verbreitet ist, stützt sich auf Ray-Tracing-Algorithmen, um die Interaktion von Licht mit Oberflächen zu simulieren und realistische Reflexionen, Brechungen und Schatten zu erzeugen.
Jedoch erhöht jeder zusätzliche Lichtstrahl-Sprung den Rechenaufwand erheblich, was Echtzeitanwendungen dazu zwingt, Latenz und Genauigkeit auszugleichen, indem die Anzahl der Sprünge begrenzt wird.
Ein virtueller Lichtstrahl in einem 3D-basierten (CGI) Szenario, unter Verwendung von Techniken aus den 1960er Jahren, verfeinert zwischen 'Tron' (1982) und 'Jurassic Park' (1993). Quelle: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
Zum Beispiel erfordert das Rendern einer Chrom-Teekanne vor einem Spiegel wiederholtes Springen von Lichtstrahlen, was nahezu unendliche Schleifen mit minimalem visuellem Nutzen erzeugt. Typischerweise reichen zwei bis drei Sprünge für wahrnehmbare Reflexionen, da ein einzelner Sprung einen dunklen Spiegel ergibt.
Jeder zusätzliche Sprung verdoppelt die Renderzeit, was ein effizientes Handling von Reflexionen entscheidend macht, um Ray-Tracing-Visuals zu verbessern.
Reflexionen sind entscheidend für Fotorealismus in subtileren Fällen, wie nassen Stadtstraßen, Schaufensterreflexionen oder Brillen von Charakteren, wo Objekte und Umgebungen genau dargestellt werden müssen.
Eine Zwillingsreflexion, erstellt durch traditionelles Compositing für eine Szene in 'The Matrix' (1999).
Herausforderungen in der Visualisierung
Vor Diffusionsmodellen hatten Frameworks wie Neural Radiance Fields (NeRF) und neuere Ansätze wie Gaussian Splatting Schwierigkeiten, Reflexionen natürlich darzustellen.
Das REF2-NeRF-Projekt schlug eine NeRF-basierte Methode für Szenen mit Glasvitrinen vor, die Brechung und Reflexion basierend auf der Perspektive des Betrachters modelliert. Dies ermöglichte die Schätzung von Glasoberflächen und die Trennung von direktem und reflektiertem Licht.
Beispiele aus dem Ref2Nerf-Papier. Quelle: https://arxiv.org/pdf/2311.17116
Weitere reflexionsfokussierte NeRF-Lösungen umfassen NeRFReN, Reflecting Reality und Metas 2024 Planar Reflection-Aware Neural Radiance Fields-Projekt.
Für Gaussian Splatting haben Projekte wie Mirror-3DGS, Reflective Gaussian Splatting und RefGaussian Reflexionsprobleme angegangen, während das 2023 Nero-Projekt eine einzigartige Methode für neuronale Repräsentationen einführte.
MirrorVerse-Durchbruch
Das Lehren von Diffusionsmodellen, Reflexionslogik zu handhaben, ist schwieriger als bei strukturellen Methoden wie Gaussian Splatting oder NeRF. Zuverlässige Reflexionen in Diffusionsmodellen hängen von vielfältigen, hochwertigen Trainingsdaten in unterschiedlichen Szenarien ab.
Traditionell beinhaltet das Hinzufügen solcher Verhaltensweisen LoRA oder Fine-Tuning, aber diese verzerren die Ausgaben oder erstellen modellspezifische Werkzeuge, die mit dem Originalmodell inkompatibel sind.
Die Verbesserung von Diffusionsmodellen erfordert Trainingsdaten, die die Physik von Reflexionen betonen. Das Kuratieren von hyperskaligen Datensätzen für jede Schwäche ist jedoch kostspielig und unpraktisch.
Dennoch entstehen Lösungen, wie Indiens MirrorVerse-Projekt, das einen erweiterten Datensatz und eine Trainingsmethode bietet, um die Reflexionsgenauigkeit in Diffusionsmodellen zu verbessern.
Ganz rechts die Ergebnisse von MirrorVerse im Vergleich zu zwei früheren Ansätzen (mittlere Spalten). Quelle: https://arxiv.org/pdf/2504.15397
Wie oben gezeigt, verbessert MirrorVerse die jüngsten Bemühungen, ist aber nicht fehlerfrei.
Im oberen rechten Bild sind Keramikkrüge leicht falsch ausgerichtet, und im unteren Bild erscheint eine fehlerhafte Tassenreflexion entgegen natürlicher Reflexionswinkel.
Wir werden diese Methode nicht als definitive Lösung untersuchen, sondern um die anhaltenden Herausforderungen zu beleuchten, denen Diffusionsmodelle in statischen und Videoformaten begegnen, wo Reflexionsdaten oft an spezifische Szenarien gebunden sind.
Daher könnten LDMs in der Reflexionsgenauigkeit hinter NeRF, Gaussian Splatting und traditionellem CGI zurückbleiben.
Das Papier, MirrorVerse: Diffusionsmodelle dazu bringen, die Welt realistisch widerzuspiegeln, stammt von Forschern des Vision and AI Lab, IISc Bangalore, und Samsung R&D Institute, Bangalore, mit einer Projektseite, einem Hugging Face-Datensatz und GitHub-Code.
Methodik
Die Forscher betonen die Schwierigkeiten, die Modelle wie Stable Diffusion und Flux mit reflexionsbasierten Eingaben haben, wie unten geಸ
System: gezeigt:
Aus dem Papier: Top-Text-zu-Bild-Modelle, SD3.5 und Flux, haben Schwierigkeiten mit konsistenten, geometrisch genauen Reflexionen.
Das Team entwickelte MirrorFusion 2.0, ein diffusionsbasiertes Modell, um den Fotorealismus und die geometrische Genauigkeit von Spiegelreflexionen zu verbessern. Es wurde auf ihrem MirrorGen2-Datensatz trainiert, der entwickelt wurde, um Verallgemeinerungsprobleme zu lösen.
MirrorVerse’s Schema für synthetische Daten: zufällige Positionierung, Rotation und Verankerung durch den 3D-Positioner, mit gepaarten Objekten für realistische räumliche Interaktionen.
MirrorGen2 umfasst Szenen mit gepaarten Objekten, um Verdeckungen und komplexe räumliche Anordnungen in reflektierenden Umgebungen besser zu handhaben.
Das Papier stellt fest:
„Kategorien werden für semantische Kohärenz gepaart, wie ein Stuhl mit einem Tisch. Nach der Positionierung des primären Objekts wird ein sekundäres ohne Überlappung hinzugefügt, um unterschiedliche räumliche Bereiche zu gewährleisten.“
Für die Objektverankerung sorgten die Autoren dafür, dass Objekte am Boden verankert waren, um unnatürliches „Schweben“ in synthetischen Daten zu vermeiden.
Da die Innovation des Datensatzes die Neuheit des Papiers antreibt, werden wir dies als Nächstes behandeln.
Daten und Tests
SynMirrorV2
Der SynMirrorV2-Datensatz verbessert die Vielfalt der Trainingsdaten für Reflexionen, unter Verwendung von 3D-Objekten aus Objaverse und Amazon Berkeley Objects (ABO), verfeinert durch OBJECT 3DIT und V1 MirrorFusion-Filterung, was 66.062 hochwertige Objekte ergab.
Beispiele aus dem Objaverse-Datensatz, verwendet für den kuratierten Datensatz. Quelle: https://arxiv.org/pdf/2212.08051
Szenen wurden mit texturierten Böden von CC-Textures und HDRI-Hintergründen von PolyHaven erstellt, unter Verwendung von Wandspiegeln oder rechteckigen Spiegeln. Die Beleuchtung verwendete eine Flächenleuchte im 45-Grad-Winkel. Objekte wurden skaliert, über die Schnittmenge von Spiegel und Kamerasichtfeld positioniert und zufällig um die y-Achse rotiert, mit Verankerung, um schwebende Artefakte zu vermeiden.
Mehr-Objekt-Szenen verwendeten 3.140 semantisch kohärente Paarungen von ABO, wobei Überlappungen vermieden wurden, um verschiedene Verdeckungen und Tiefen zu erfassen.
Gerenderte Ansichten aus dem Datensatz mit mehreren Objekten, die Segmentierung und Tiefenkarten zeigen.
Trainingsprozess
Ein dreistufiger Lernprozess trainierte MirrorFusion 2.0 für robuste Verallgemeinerung in der realen Welt.
Stufe 1 initialisierte Gewichte von Stable Diffusion v1.5, mit Feinabstimmung auf der Einzelobjekt-Teilmenge von SynMirrorV2 für 40.000 Iterationen, wobei beide Konditionierungs- und Generierungsstränge aktiv blieben.
Stufe 2 feinabgestimmt für 10.000 Iterationen auf der Mehr-Objekt-Teilmenge von SynMirrorV2, um Verdeckungen und komplexe Szenen zu handhaben.
Stufe 3 fügte 10.000 Iterationen mit realen MSD-Datensatzdaten hinzu, unter Verwendung von Matterport3D-Tiefenkarten.
Beispiele aus dem MSD-Datensatz mit Tiefen- und Segmentierungskarten. Quelle: https://arxiv.org/pdf/1908.09101
Textprompts wurden in 20 % der Fälle weggelassen, um Tiefeninformationen zu priorisieren. Das Training verwendete vier NVIDIA A100 GPUs, eine Lernrate von 1e-5, eine Batchgröße von 4 pro GPU und den AdamW-Optimierer.
Dieses progressive Training verlief von einfachen synthetischen zu komplexen realen Szenen für bessere Übertragbarkeit.
Testen
MirrorFusion 2.0 wurde gegen die Basisversion MirrorFusion auf MirrorBenchV2 getestet, das Einzel- und Mehr-Objekt-Szenen abdeckte, mit qualitativen Tests auf MSD- und Google Scanned Objects (GSO)-Datensätzen.
Die Bewertung verwendete 2.991 Einzelobjekt- und 300 Zwei-Objekt-Szenen, wobei PSNR, SSIM und LPIPS für Reflexionsqualität und CLIP für die Prompt-Ausrichtung gemessen wurden. Bilder wurden mit vier Seeds generiert, wobei die beste SSIM-Bewertung ausgewählt wurde.
Links: Einzelobjekt-Reflexionsqualität auf MirrorBenchV2, mit MirrorFusion 2.0, das die Basisversion übertrifft. Rechts: Mehr-Objekt-Reflexionsqualität, mit Mehr-Objekt-Training verbessert die Ergebnisse.
Die Autoren stellen fest:
„Unsere Methode übertrifft die Basisversion, und Mehr-Objekt-Feinabstimmung verbessert die Ergebnisse komplexer Szenen.“
Qualitative Tests betonten die Verbesserungen von MirrorFusion 2.0:
Vergleich auf MirrorBenchV2: Basisversion zeigt falsche Stuhlausrichtung und verzerrte Reflexionen; MirrorFusion 2.0 rendert korrekt.
Die Basisversion hatte Probleme mit Objektausrichtung und räumlichen Artefakten, während MirrorFusion 2.0, trainiert auf SynMirrorV2, genaue Positionierung und realistische Reflexionen beibehielt.
Ergebnisse des GSO-Datensatzes:
GSO-Vergleich: Basisversion verzerrt Objektstruktur; MirrorFusion 2.0 bewahrt Geometrie, Farbe und Details.
Die Autoren kommentieren:
„MirrorFusion 2.0 spiegelt Details wie Schubladengriffe genau wider, während die Basisversion unplausible Ergebnisse liefert.“
Ergebnisse des realen MSD-Datensatzes:
MSD-Ergebnisse: MirrorFusion 2.0, feinabgestimmt auf MSD, erfasst komplexe Szenen mit überladenen Objekten und mehreren Spiegeln genau.
Die Feinabstimmung auf MSD verbesserte die Handhabung komplexer realer Szenen durch MirrorFusion 2.0 und erhöhte die Reflexionskohärenz.
Eine Nutzerstudie ergab, dass 84 % die Ausgaben von MirrorFusion 2.0 bevorzugten.
Ergebnisse der Nutzerstudie.
Fazit
Während MirrorFusion 2.0 Fortschritte markiert, bleibt die Basis für Reflexionsgenauigkeit in Diffusionsmodellen niedrig, was selbst bescheidene Verbesserungen bemerkenswert macht. Die Architektur von Diffusionsmodellen hat Schwierigkeiten mit konsistenter Physik, und das Hinzufügen von Daten, wie hier geschehen, ist eine Standard-, aber begrenzte Lösung.
Zukünftige Datensätze mit besserer Verteilung von Reflexionsdaten könnten die Ergebnisse verbessern, aber dies gilt für viele Schwächen von LDMs. Die Priorisierung der zu behandelnden Probleme bleibt eine Herausforderung.
Erstmals veröffentlicht am Montag, 28. April 2025










 OpenAI ändert heimlich seine Satzung, um die Entlassung von Altman zu erschweren
Nach dem putschähnlichen Vorfall im Jahr 2023 hat OpenAI den Schutz für CEO Sam Altman durch eine Aktualisierung der Unternehmenssatzung weiter gefestigt. Kürzlich veröffentlichte Gerichtsdokumente ze
OpenAI ändert heimlich seine Satzung, um die Entlassung von Altman zu erschweren
Nach dem putschähnlichen Vorfall im Jahr 2023 hat OpenAI den Schutz für CEO Sam Altman durch eine Aktualisierung der Unternehmenssatzung weiter gefestigt. Kürzlich veröffentlichte Gerichtsdokumente ze
 Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
Meta AI beantwortet nun Nachrichten von Käufern auf dem Facebook Marketplace
Facebook Marketplace führt neue Meta-KI-Funktionen ein, darunter automatische Antworten auf Käuferanfragen, wie das Unternehmen am Donnerstag bekannt gab. Die Plattform nutzt KI außerdem, um die Erste
 OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai

鏡の反射をリアルに描画するAIの進歩ってすごいですね!でも、これが深フェイクに悪用されたらどうなるんだろう…ちょっと怖いかも😅 反射の物理法則を理解するって、AIが現実世界を「見る」能力が向上している証拠でしょうか?
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯













