
















 Дом
ДомУлучшение способности ИИ создавать реалистичные отражения в зеркале
С тех пор как генеративный ИИ привлек широкое внимание, исследователи в области компьютерного зрения усилили работу над разработкой моделей, способных понимать и воспроизводить физические законы, уделяя особое внимание таким задачам, как моделирование гравитации и динамики жидкостей за последние пять лет.
С появлением моделей латентной диффузии (LDM) в 2022 году внимание сместилось на их трудности с точным изображением физических явлений. Эта проблема стала особенно актуальной после выпуска видеомодели Sora от OpenAI и недавних open-source релизов Hunyuan Video и Wan 2.1.
Проблемы с отражениями
Исследования по улучшению понимания физики LDM в основном сосредоточены на таких областях, как симуляция походки и ньютоновское движение, поскольку неточности здесь подрывают реалистичность видео, созданных ИИ.
Тем не менее, всё больше работ направлено на ключевую слабость LDM: ограниченную способность создавать точные отражения.

Из статьи января 2025 года 'Отражение реальности: Обеспечение диффузионных моделей для создания точных зеркальных отражений', примеры 'ошибок отражения' в сравнении с подходом авторов. Источник: https://arxiv.org/pdf/2409.14677
Эта проблема, также распространённая в CGI и видеоиграх, решается с помощью алгоритмов трассировки лучей, которые моделируют взаимодействие света с поверхностями, создавая реалистичные отражения, преломления и тени.
Однако каждый дополнительный отскок луча света значительно увеличивает вычислительные затраты, вынуждая приложения реального времени балансировать между задержкой и точностью, ограничивая количество отскоков.
![Представление виртуально рассчитанного светового луча в традиционном 3D-сценарии (т.е. CGI), использующем технологии и принципы, впервые разработанные в 1960-х годах и реализованные в период между 1982–1993 годами (от 'Трон' [1982] до 'Парка Юрского периода' [1993]). Источник: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing](https://img.xix.ai/uploads/55/680fa78ce2769.webp)
Виртуальный световой луч в 3D-сценарии (CGI), использующий технологии 1960-х годов, усовершенствованные в период между 'Трон' (1982) и 'Парк Юрского периода' (1993). Источник: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
Например, рендеринг хромированного чайника перед зеркалом включает многократные отскоки лучей света, создавая почти бесконечные циклы с минимальной визуальной пользой. Обычно двух–трёх отскоков достаточно для заметных отражений, так как один отскок даёт тёмное зеркало.
Каждый дополнительный отскок удваивает время рендеринга, делая эффективную обработку отражений критически важной для улучшения визуальных эффектов с трассировкой лучей.
Отражения жизненно важны для фотореализма в более тонких случаях, таких как мокрые городские улицы, отражения в витринах магазинов или очках персонажей, где объекты и окружающая среда должны отображаться точно.

Двойное отражение, созданное с помощью традиционного композинга для сцены в 'Матрице' (1999).
Проблемы в визуализации
До появления диффузионных моделей такие фреймворки, как Neural Radiance Fields (NeRF) и более новые подходы, такие как Gaussian Splatting, испытывали трудности с естественным изображением отражений.
Проект REF2-NeRF предложил метод на основе NeRF для сцен с стеклянными витринами, моделирующий преломление и отражение с учётом перспективы зрителя. Это позволило оценить стеклянные поверхности и разделить прямой и отражённый свет.

Примеры из статьи Ref2Nerf. Источник: https://arxiv.org/pdf/2311.17116
Другие решения для NeRF, ориентированные на отражения, включают NeRFReN, Reflecting Reality и проект Meta 2024 года Planar Reflection-Aware Neural Radiance Fields.
Для Gaussian Splatting такие проекты, как Mirror-3DGS, Reflective Gaussian Splatting и RefGaussian, решали проблемы с отражениями, тогда как проект Nero 2023 года представил уникальный метод для нейронных представлений.
Прорыв MirrorVerse
Обучение диффузионных моделей логике отражений сложнее, чем в структурных методах, таких как Gaussian Splatting или NeRF. Надёжное отражение в диффузионных моделях зависит от разнообразных высококачественных данных для обучения в различных сценариях.
Традиционно добавление таких поведений включает LoRA или тонкую настройку, но они искажают результаты или создают инструменты, специфичные для модели, несовместимые с исходной моделью.
Улучшение диффузионных моделей требует данных для обучения, акцентирующих физику отражений. Однако создание гипермасштабных наборов данных для каждой слабости дорого и непрактично.
Тем не менее, появляются решения, такие как проект MirrorVerse из Индии, который предлагает улучшенный набор данных и метод обучения для повышения точности отражений в диффузионных моделях.

Справа результаты MirrorVerse в сравнении с двумя предыдущими подходами (средние столбцы). Источник: https://arxiv.org/pdf/2504.15397
Как показано выше, MirrorVerse улучшает недавние достижения, но не является безупречным.
На верхнем правом изображении керамические кувшины слегка смещены, а на нижнем изображении появляется ошибочное отражение чашки, противоречащее естественным углам отражения.
Мы рассмотрим этот метод не как окончательное решение, а чтобы подчеркнуть сохраняющиеся проблемы, с которыми сталкиваются диффузионные модели в статических и видеоформатах, где данные об отражениях часто привязаны к конкретным сценариям.
Таким образом, LDM могут отставать от NeRF, Gaussian Splatting и традиционного CGI по точности отражений.
Статья, MirrorVerse: Доведение диффузионных моделей до реалистичного отражения мира, подготовлена исследователями из Vision and AI Lab, IISc Bangalore, и Samsung R&D Institute, Bangalore, с проектной страницей, набором данных на Hugging Face и кодом на GitHub.
Методология
Исследователи подчёркивают трудности, с которыми сталкиваются модели, такие как Stable Diffusion и Flux, при работе с запросами, связанными с отражениями, как показано ниже:

Из статьи: Ведущие модели преобразования текста в изображение, SD3.5 и Flux, испытывают трудности с согласованными и геометрически точными отражениями.
Команда разработала MirrorFusion 2.0, модель на основе диффузии для повышения фотореализма и геометрической точности зеркальных отражений. Она обучалась на наборе данных MirrorGen2, разработанном для решения проблем обобщения.
MirrorGen2 включает случайное позиционирование объектов, случайные вращения и явное закрепление объектов для обеспечения правдоподобных отражений при различных размещениях объектов.
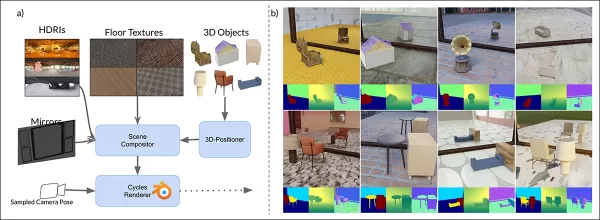
Схема синтетических данных MirrorVerse: случайное позиционирование, вращение и закрепление через 3D-Positioner, с парным подбором объектов для реалистичных пространственных взаимодействий.
MirrorGen2 включает сцены с парным расположением объектов для лучшей обработки окклюзий и сложных пространственных конфигураций в отражающих настройках.
В статье отмечается:
‘Категории подбираются для семантической согласованности, например, стул с столом. После размещения основного объекта добавляется второстепенный без пересечения, обеспечивая чёткие пространственные области.’
Для закрепления объектов авторы обеспечили их привязку к земле, избегая неестественного 'плавания' в синтетических данных.
Поскольку новизна статьи обусловлена инновациями в наборе данных, мы рассмотрим это далее.
Данные и тесты
SynMirrorV2
Набор данных SynMirrorV2 повышает разнообразие данных для обучения отражений, используя 3D-объекты из Objaverse и Amazon Berkeley Objects (ABO), отфильтрованные через OBJECT 3DIT и V1 MirrorFusion, что дало 66,062 высококачественных объекта.

Примеры из набора данных Objaverse, использованные для курированного набора данных. Источник: https://arxiv.org/pdf/2212.08051
Сцены создавались с текстурированными полами из CC-Textures и HDRI-фонами из PolyHaven, используя полноразмерные или прямоугольные зеркала. Освещение обеспечивала лампа с углом 45 градусов. Объекты масштабировались, позиционировались через пересечение зеркала и камеры и случайным образом вращались по оси y, с закреплением для избежания артефактов плавания.
Сцены с несколькими объектами использовали 3,140 семантически согласованных пар из ABO, избегая пересечений для захвата различных окклюзий и глубины.

Рендеринг сцен из набора данных с несколькими объектами, с демонстрацией сегментации и карт глубины.
Процесс обучения
Трёхэтапный процесс обучения по программе curriculum learning обучал MirrorFusion 2.0 для устойчивого обобщения в реальных условиях.
Этап 1 инициализировал веса из Stable Diffusion v1.5, с тонкой настройкой на однообъектной части SynMirrorV2 в течение 40,000 итераций, сохраняя активными ветви обусловливания и генерации.
Этап 2 проводил тонкую настройку в течение 10,000 итераций на многообъектной части SynMirrorV2 для обработки окклюзий и сложных сцен.
Этап 3 добавил 10,000 итераций с реальными данными набора MSD, используя карты глубины Matterport3D.

Примеры из набора данных MSD с картами глубины и сегментации. Источник: https://arxiv.org/pdf/1908.09101
Текстовые подсказки опускались в 20% случаев для приоритета информации о глубине. Обучение проводилось на четырёх GPU NVIDIA A100, с шагом обучения 1e-5, размером пакета 4 на GPU и оптимизатором AdamW.
Этот прогрессивный процесс обучения переходил от простых синтетических сцен к сложным реальным для лучшей переносимости.
Тестирование
MirrorFusion 2.0 тестировалась против базовой модели MirrorFusion на MirrorBenchV2, охватывая одно- и многообъектные сцены, с качественными тестами на наборах данных MSD и Google Scanned Objects (GSO).
Оценка проводилась на 2,991 однообъектной и 300 двухобъектных сценах, измеряя PSNR, SSIM и LPIPS для качества отражений и CLIP для соответствия подсказкам. Изображения генерировались с четырьмя сидами, выбирая лучший результат по SSIM.

Слева: Качество отражений одного объекта на MirrorBenchV2, MirrorFusion 2.0 превзошла базовую модель. Справа: Качество отражений нескольких объектов, обучение на нескольких объектах улучшило результаты.
Авторы отмечают:
‘Наш метод превосходит базовую модель, а тонкая настройка на нескольких объектах улучшает результаты в сложных сценах.’
Качественные тесты подчеркнули улучшения MirrorFusion 2.0:

Сравнение на MirrorBenchV2: Базовая модель показывает неверную ориентацию стула и искажённые отражения; MirrorFusion 2.0 рендерит точно.
Результаты на наборе данных GSO:

Сравнение на GSO: Базовая модель искажает структуру объектов; MirrorFusion 2.0 сохраняет геометрию, цвет и детали.
Авторы комментируют:
‘MirrorFusion 2.0 точно отражает детали, такие как ручки ящиков, тогда как базовая модель выдаёт неправдоподобные результаты.’
Результаты на реальном наборе данных MSD:

Результаты MSD: MirrorFusion 2.0, тонко настроенная на MSD, точно фиксирует сложные сцены с нагромождёнными объектами и несколькими зеркалами.
Тонкая настройка на MSD улучшила способность MirrorFusion 2.0 обрабатывать сложные реальные сцены, повышая согласованность отражений.
Исследование пользователей показало, что 84% предпочли результаты MirrorFusion 2.0.
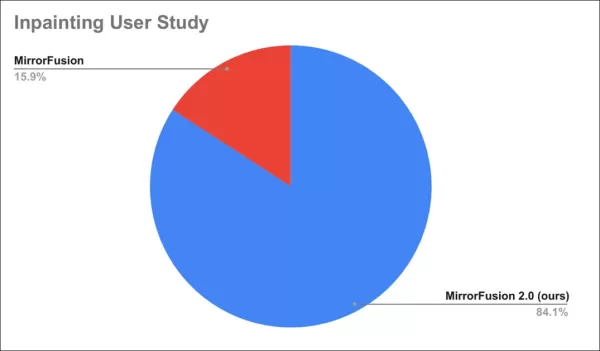
Результаты исследования пользователей.
Заключение
Хотя MirrorFusion 2.0 знаменует прогресс, базовый уровень точности отражений в диффузионных моделях остаётся низким, что делает даже скромные улучшения заметными. Архитектура диффузионных моделей испытывает трудности с согласованной физикой, и добавление данных, как здесь, является стандартным, но ограниченным решением.
Будущие наборы данных с лучшим распределением данных об отражениях могут улучшить результаты, но это относится ко многим слабостям LDM. Приоритизация проблем для решения остаётся вызовом.
Впервые опубликовано в понедельник, 28 апреля 2025 года
Связанная статья
 Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
DeepSeek Code готовится к запуску
На фоне стремительного развития технологий искусственного интеллекта компания DeepSeek находится на захватывающем этапе своего развития. Недавно эта компания, специализирующаяся на ИИ, объявила о прив
Grok от Маска: 1,5 триллиона параметров и поглощение кода курсора — прорыв или блеф?
Илон Маск наконец-то делает ход.В гонке по программированию ИИ компании OpenAI и Anthropic набирают обороты, в то время как xAI, похоже, отстает. Маск не раз заявлял о своем намерении составить конкур
Рекомендации по связанным специальным темам
Бизнес
Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
DeepSeek Code готовится к запуску
На фоне стремительного развития технологий искусственного интеллекта компания DeepSeek находится на захватывающем этапе своего развития. Недавно эта компания, специализирующаяся на ИИ, объявила о прив
Grok от Маска: 1,5 триллиона параметров и поглощение кода курсора — прорыв или блеф?
Илон Маск наконец-то делает ход.В гонке по программированию ИИ компании OpenAI и Anthropic набирают обороты, в то время как xAI, похоже, отстает. Маск не раз заявлял о своем намерении составить конкур
Рекомендации по связанным специальным темам
Бизнес
 Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
 10 инструментов
10 инструментов
 xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие романтические чат-боты на базе ИИ: постройте долгосрочные отношения с помощью чат-ботов с устойчивой индивидуальностью
Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai
Образование и обучение
Лучшие наставники в области искусственного интеллекта и науки о данных: мастерство работы с SQL, библиотекой Pandas и рабочими процессами машинного обучения
Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие тренажеры по флирту и общению на базе ИИ: повышайте свою харизму и уверенность в себе в режиме реального времени
Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
10 инструментов
xix.ai
код
Лучшие инструменты ИИ для автоматизированного тестирования модулей: создание случаев тестирования Jest, PyTest и JUnit одним кликом
Откройте для себя самые новые и высоко оцененные инструменты ИИ 2026 года для автоматизированного тестирования модулей. Наша тщательно подобранная коллекция включает мощные решения, способные радикально изменить процесс разработки, позволяющие мгновенно генерировать тестовые случаи для Jest, PyTest и JUnit. Сравните бесплатные и платные варианты с результатами реальных тестов, а также еженедельно обновляемыми рейтингами на сайте XIX.AI. Раскройте потенциал ИИ и повысьте эффективность своей работы в области разработки сегодня же.
10 инструментов
xix.ai

 Комментарии (4)
Комментарии (4)
![GaryWalker]()
鏡の反射をリアルに描画するAIの進歩ってすごいですね!でも、これが深フェイクに悪用されたらどうなるんだろう…ちょっと怖いかも😅 反射の物理法則を理解するって、AIが現実世界を「見る」能力が向上している証拠でしょうか?
![JimmyWilson]()
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
![FredGreen]()
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
![RogerNelson]()
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯
С тех пор как генеративный ИИ привлек широкое внимание, исследователи в области компьютерного зрения усилили работу над разработкой моделей, способных понимать и воспроизводить физические законы, уделяя особое внимание таким задачам, как моделирование гравитации и динамики жидкостей за последние пять лет.
С появлением моделей латентной диффузии (LDM) в 2022 году внимание сместилось на их трудности с точным изображением физических явлений. Эта проблема стала особенно актуальной после выпуска видеомодели Sora от OpenAI и недавних open-source релизов Hunyuan Video и Wan 2.1.
Проблемы с отражениями
Исследования по улучшению понимания физики LDM в основном сосредоточены на таких областях, как симуляция походки и ньютоновское движение, поскольку неточности здесь подрывают реалистичность видео, созданных ИИ.
Тем не менее, всё больше работ направлено на ключевую слабость LDM: ограниченную способность создавать точные отражения.
Из статьи января 2025 года 'Отражение реальности: Обеспечение диффузионных моделей для создания точных зеркальных отражений', примеры 'ошибок отражения' в сравнении с подходом авторов. Источник: https://arxiv.org/pdf/2409.14677
Эта проблема, также распространённая в CGI и видеоиграх, решается с помощью алгоритмов трассировки лучей, которые моделируют взаимодействие света с поверхностями, создавая реалистичные отражения, преломления и тени.
Однако каждый дополнительный отскок луча света значительно увеличивает вычислительные затраты, вынуждая приложения реального времени балансировать между задержкой и точностью, ограничивая количество отскоков.
Виртуальный световой луч в 3D-сценарии (CGI), использующий технологии 1960-х годов, усовершенствованные в период между 'Трон' (1982) и 'Парк Юрского периода' (1993). Источник: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
Например, рендеринг хромированного чайника перед зеркалом включает многократные отскоки лучей света, создавая почти бесконечные циклы с минимальной визуальной пользой. Обычно двух–трёх отскоков достаточно для заметных отражений, так как один отскок даёт тёмное зеркало.
Каждый дополнительный отскок удваивает время рендеринга, делая эффективную обработку отражений критически важной для улучшения визуальных эффектов с трассировкой лучей.
Отражения жизненно важны для фотореализма в более тонких случаях, таких как мокрые городские улицы, отражения в витринах магазинов или очках персонажей, где объекты и окружающая среда должны отображаться точно.
Двойное отражение, созданное с помощью традиционного композинга для сцены в 'Матрице' (1999).
Проблемы в визуализации
До появления диффузионных моделей такие фреймворки, как Neural Radiance Fields (NeRF) и более новые подходы, такие как Gaussian Splatting, испытывали трудности с естественным изображением отражений.
Проект REF2-NeRF предложил метод на основе NeRF для сцен с стеклянными витринами, моделирующий преломление и отражение с учётом перспективы зрителя. Это позволило оценить стеклянные поверхности и разделить прямой и отражённый свет.
Примеры из статьи Ref2Nerf. Источник: https://arxiv.org/pdf/2311.17116
Другие решения для NeRF, ориентированные на отражения, включают NeRFReN, Reflecting Reality и проект Meta 2024 года Planar Reflection-Aware Neural Radiance Fields.
Для Gaussian Splatting такие проекты, как Mirror-3DGS, Reflective Gaussian Splatting и RefGaussian, решали проблемы с отражениями, тогда как проект Nero 2023 года представил уникальный метод для нейронных представлений.
Прорыв MirrorVerse
Обучение диффузионных моделей логике отражений сложнее, чем в структурных методах, таких как Gaussian Splatting или NeRF. Надёжное отражение в диффузионных моделях зависит от разнообразных высококачественных данных для обучения в различных сценариях.
Традиционно добавление таких поведений включает LoRA или тонкую настройку, но они искажают результаты или создают инструменты, специфичные для модели, несовместимые с исходной моделью.
Улучшение диффузионных моделей требует данных для обучения, акцентирующих физику отражений. Однако создание гипермасштабных наборов данных для каждой слабости дорого и непрактично.
Тем не менее, появляются решения, такие как проект MirrorVerse из Индии, который предлагает улучшенный набор данных и метод обучения для повышения точности отражений в диффузионных моделях.
Справа результаты MirrorVerse в сравнении с двумя предыдущими подходами (средние столбцы). Источник: https://arxiv.org/pdf/2504.15397
Как показано выше, MirrorVerse улучшает недавние достижения, но не является безупречным.
На верхнем правом изображении керамические кувшины слегка смещены, а на нижнем изображении появляется ошибочное отражение чашки, противоречащее естественным углам отражения.
Мы рассмотрим этот метод не как окончательное решение, а чтобы подчеркнуть сохраняющиеся проблемы, с которыми сталкиваются диффузионные модели в статических и видеоформатах, где данные об отражениях часто привязаны к конкретным сценариям.
Таким образом, LDM могут отставать от NeRF, Gaussian Splatting и традиционного CGI по точности отражений.
Статья, MirrorVerse: Доведение диффузионных моделей до реалистичного отражения мира, подготовлена исследователями из Vision and AI Lab, IISc Bangalore, и Samsung R&D Institute, Bangalore, с проектной страницей, набором данных на Hugging Face и кодом на GitHub.
Методология
Исследователи подчёркивают трудности, с которыми сталкиваются модели, такие как Stable Diffusion и Flux, при работе с запросами, связанными с отражениями, как показано ниже:
Из статьи: Ведущие модели преобразования текста в изображение, SD3.5 и Flux, испытывают трудности с согласованными и геометрически точными отражениями.
Команда разработала MirrorFusion 2.0, модель на основе диффузии для повышения фотореализма и геометрической точности зеркальных отражений. Она обучалась на наборе данных MirrorGen2, разработанном для решения проблем обобщения.
MirrorGen2 включает случайное позиционирование объектов, случайные вращения и явное закрепление объектов для обеспечения правдоподобных отражений при различных размещениях объектов.
Схема синтетических данных MirrorVerse: случайное позиционирование, вращение и закрепление через 3D-Positioner, с парным подбором объектов для реалистичных пространственных взаимодействий.
MirrorGen2 включает сцены с парным расположением объектов для лучшей обработки окклюзий и сложных пространственных конфигураций в отражающих настройках.
В статье отмечается:
‘Категории подбираются для семантической согласованности, например, стул с столом. После размещения основного объекта добавляется второстепенный без пересечения, обеспечивая чёткие пространственные области.’
Для закрепления объектов авторы обеспечили их привязку к земле, избегая неестественного 'плавания' в синтетических данных.
Поскольку новизна статьи обусловлена инновациями в наборе данных, мы рассмотрим это далее.
Данные и тесты
SynMirrorV2
Набор данных SynMirrorV2 повышает разнообразие данных для обучения отражений, используя 3D-объекты из Objaverse и Amazon Berkeley Objects (ABO), отфильтрованные через OBJECT 3DIT и V1 MirrorFusion, что дало 66,062 высококачественных объекта.
Примеры из набора данных Objaverse, использованные для курированного набора данных. Источник: https://arxiv.org/pdf/2212.08051
Сцены создавались с текстурированными полами из CC-Textures и HDRI-фонами из PolyHaven, используя полноразмерные или прямоугольные зеркала. Освещение обеспечивала лампа с углом 45 градусов. Объекты масштабировались, позиционировались через пересечение зеркала и камеры и случайным образом вращались по оси y, с закреплением для избежания артефактов плавания.
Сцены с несколькими объектами использовали 3,140 семантически согласованных пар из ABO, избегая пересечений для захвата различных окклюзий и глубины.
Рендеринг сцен из набора данных с несколькими объектами, с демонстрацией сегментации и карт глубины.
Процесс обучения
Трёхэтапный процесс обучения по программе curriculum learning обучал MirrorFusion 2.0 для устойчивого обобщения в реальных условиях.
Этап 1 инициализировал веса из Stable Diffusion v1.5, с тонкой настройкой на однообъектной части SynMirrorV2 в течение 40,000 итераций, сохраняя активными ветви обусловливания и генерации.
Этап 2 проводил тонкую настройку в течение 10,000 итераций на многообъектной части SynMirrorV2 для обработки окклюзий и сложных сцен.
Этап 3 добавил 10,000 итераций с реальными данными набора MSD, используя карты глубины Matterport3D.
Примеры из набора данных MSD с картами глубины и сегментации. Источник: https://arxiv.org/pdf/1908.09101
Текстовые подсказки опускались в 20% случаев для приоритета информации о глубине. Обучение проводилось на четырёх GPU NVIDIA A100, с шагом обучения 1e-5, размером пакета 4 на GPU и оптимизатором AdamW.
Этот прогрессивный процесс обучения переходил от простых синтетических сцен к сложным реальным для лучшей переносимости.
Тестирование
MirrorFusion 2.0 тестировалась против базовой модели MirrorFusion на MirrorBenchV2, охватывая одно- и многообъектные сцены, с качественными тестами на наборах данных MSD и Google Scanned Objects (GSO).
Оценка проводилась на 2,991 однообъектной и 300 двухобъектных сценах, измеряя PSNR, SSIM и LPIPS для качества отражений и CLIP для соответствия подсказкам. Изображения генерировались с четырьмя сидами, выбирая лучший результат по SSIM.
Слева: Качество отражений одного объекта на MirrorBenchV2, MirrorFusion 2.0 превзошла базовую модель. Справа: Качество отражений нескольких объектов, обучение на нескольких объектах улучшило результаты.
Авторы отмечают:
‘Наш метод превосходит базовую модель, а тонкая настройка на нескольких объектах улучшает результаты в сложных сценах.’
Качественные тесты подчеркнули улучшения MirrorFusion 2.0:
Сравнение на MirrorBenchV2: Базовая модель показывает неверную ориентацию стула и искажённые отражения; MirrorFusion 2.0 рендерит точно.
Результаты на наборе данных GSO:
Сравнение на GSO: Базовая модель искажает структуру объектов; MirrorFusion 2.0 сохраняет геометрию, цвет и детали.
Авторы комментируют:
‘MirrorFusion 2.0 точно отражает детали, такие как ручки ящиков, тогда как базовая модель выдаёт неправдоподобные результаты.’
Результаты на реальном наборе данных MSD:
Результаты MSD: MirrorFusion 2.0, тонко настроенная на MSD, точно фиксирует сложные сцены с нагромождёнными объектами и несколькими зеркалами.
Тонкая настройка на MSD улучшила способность MirrorFusion 2.0 обрабатывать сложные реальные сцены, повышая согласованность отражений.
Исследование пользователей показало, что 84% предпочли результаты MirrorFusion 2.0.
Результаты исследования пользователей.
Заключение
Хотя MirrorFusion 2.0 знаменует прогресс, базовый уровень точности отражений в диффузионных моделях остаётся низким, что делает даже скромные улучшения заметными. Архитектура диффузионных моделей испытывает трудности с согласованной физикой, и добавление данных, как здесь, является стандартным, но ограниченным решением.
Будущие наборы данных с лучшим распределением данных об отражениях могут улучшить результаты, но это относится ко многим слабостям LDM. Приоритизация проблем для решения остаётся вызовом.
Впервые опубликовано в понедельник, 28 апреля 2025 года










 Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
Экспериментальный ИИ Claude от компании Anthropic успешно завершил переговоры и сделки в ходе тестирования в сфере электронной коммерции
На фоне стремительного развития искусственного интеллекта компания Anthropic в минувшую пятницу незаметно запустила внутренний эксперимент под названием «Project Deal», продемонстрировав потенциал ИИ
 DeepSeek Code готовится к запуску
На фоне стремительного развития технологий искусственного интеллекта компания DeepSeek находится на захватывающем этапе своего развития. Недавно эта компания, специализирующаяся на ИИ, объявила о прив
DeepSeek Code готовится к запуску
На фоне стремительного развития технологий искусственного интеллекта компания DeepSeek находится на захватывающем этапе своего развития. Недавно эта компания, специализирующаяся на ИИ, объявила о прив
 Grok от Маска: 1,5 триллиона параметров и поглощение кода курсора — прорыв или блеф?
Илон Маск наконец-то делает ход.В гонке по программированию ИИ компании OpenAI и Anthropic набирают обороты, в то время как xAI, похоже, отстает. Маск не раз заявлял о своем намерении составить конкур
Grok от Маска: 1,5 триллиона параметров и поглощение кода курсора — прорыв или блеф?
Илон Маск наконец-то делает ход.В гонке по программированию ИИ компании OpenAI и Anthropic набирают обороты, в то время как xAI, похоже, отстает. Маск не раз заявлял о своем намерении составить конкур

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

Откройте для себя 20 лучших тренажеров по флирту и общению с ИИ на сайте XIX.AI. Наша тщательно подобранная подборка самых популярных инструментов поможет вам развить коммуникабельность и уверенность в себе в режиме реального времени. Ознакомьтесь с незаменимыми инструментами, которые кардинально изменят вашу жизнь, — с сравнением бесплатных и платных версий и еженедельно обновляемым рейтингом. Раскройте свой коммуникативный потенциал уже сегодня.
10 инструментов
xix.ai

Откройте для себя самые новые и высоко оцененные инструменты ИИ 2026 года для автоматизированного тестирования модулей. Наша тщательно подобранная коллекция включает мощные решения, способные радикально изменить процесс разработки, позволяющие мгновенно генерировать тестовые случаи для Jest, PyTest и JUnit. Сравните бесплатные и платные варианты с результатами реальных тестов, а также еженедельно обновляемыми рейтингами на сайте XIX.AI. Раскройте потенциал ИИ и повысьте эффективность своей работы в области разработки сегодня же.
10 инструментов
xix.ai

鏡の反射をリアルに描画するAIの進歩ってすごいですね!でも、これが深フェイクに悪用されたらどうなるんだろう…ちょっと怖いかも😅 反射の物理法則を理解するって、AIが現実世界を「見る」能力が向上している証拠でしょうか?
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯













