
















 Lar
LarMelhorando a Capacidade da IA de Renderizar Reflexos Realistas no Espelho
Desde que a IA generativa conquistou ampla atenção, pesquisadores de visão computacional intensificaram esforços para desenvolver modelos que compreendam e repliquem leis físicas, com foco particular em desafios como simular gravidade e dinâmica de fluidos nos últimos cinco anos.
Com os modelos de difusão latente (LDMs) liderando a IA generativa desde 2022, a atenção se voltou para suas dificuldades em retratar com precisão fenômenos físicos. Essa questão ganhou destaque após o modelo de vídeo Sora da OpenAI e os recentes lançamentos de código aberto de Hunyuan Video e Wan 2.1.
Desafios com Reflexos
A pesquisa para melhorar a compreensão dos LDMs sobre física concentrou-se amplamente em áreas como simulação de marcha e movimento newtoniano, pois imprecisões aqui comprometem o realismo dos vídeos gerados por IA.
No entanto, um número crescente de trabalhos aborda uma fraqueza importante dos LDMs: sua capacidade limitada de gerar reflexos precisos.

Do artigo de janeiro de 2025 'Refletindo a Realidade: Capacitando Modelos de Difusão a Produzir Reflexos Fidedignos no Espelho', exemplos de 'falha de reflexo' versus a abordagem dos pesquisadores. Fonte: https://arxiv.org/pdf/2409.14677
Esse desafio, também prevalente em CGI e jogos de vídeo, depende de algoritmos de rastreamento de raios para simular a interação da luz com superfícies, produzindo reflexos, refrações e sombras realistas.
Entretanto, cada salto adicional de raio de luz aumenta significativamente as demandas computacionais, forçando aplicações em tempo real a equilibrar latência e precisão ao limitar o número de saltos.
![Uma representação de um feixe de luz calculado virtualmente em um cenário 3D tradicional (ou seja, CGI), usando tecnologias e princípios desenvolvidos pela primeira vez na década de 1960, e que se concretizaram entre 1982-93 (o período entre Tron [1982] e Jurassic Park [1993]). Fonte: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing](https://img.xix.ai/uploads/55/680fa78ce2769.webp)
Um feixe de luz virtual em um cenário 3D (CGI), usando técnicas da década de 1960, refinadas entre 'Tron' (1982) e 'Jurassic Park' (1993). Fonte: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
Por exemplo, renderizar uma chaleira de cromo diante de um espelho envolve raios de luz saltando repetidamente, criando loops quase infinitos com benefício visual mínimo. Geralmente, dois a três saltos são suficientes para reflexos perceptíveis, pois um único salto resulta em um espelho escuro.
Cada salto extra dobra o tempo de renderização, tornando o manejo eficiente de reflexos crítico para melhorar visuais rastreados por raios.
Os reflexos são vitais para o fotorrealismo em casos mais sutis, como ruas molhadas de cidades, reflexos em vitrines de lojas ou óculos de personagens, onde objetos e ambientes devem aparecer com precisão.

Um reflexo duplo criado por meio de composição tradicional para uma cena em 'The Matrix' (1999).
Desafios em Visuais
Antes dos modelos de difusão, estruturas como Neural Radiance Fields (NeRF) e abordagens mais recentes como Gaussian Splatting lutaram para retratar reflexos de forma natural.
O projeto REF2-NeRF propôs um método baseado em NeRF para cenas com caixas de vidro, modelando refração e reflexo com base na perspectiva do espectador. Isso permitiu a estimativa de superfícies de vidro e a separação de luz direta e refletida.

Exemplos do artigo Ref2Nerf. Fonte: https://arxiv.org/pdf/2311.17116
Outras soluções focadas em reflexos para NeRF incluem NeRFReN, Reflecting Reality e o projeto de 2024 da Meta, Planar Reflection-Aware Neural Radiance Fields.
Para Gaussian Splatting, esforços como Mirror-3DGS, Reflective Gaussian Splatting e RefGaussian abordaram problemas de reflexo, enquanto o projeto Nero de 2023 introduziu um método único para representações neurais.
Avanço do MirrorVerse
Ensinar modelos de difusão a lidar com a lógica de reflexo é mais difícil do que com métodos estruturais como Gaussian Splatting ou NeRF. Reflexos confiáveis em modelos de difusão dependem de dados de treinamento diversos e de alta qualidade em cenários variados.
Tradicionalmente, adicionar tais comportamentos envolve LoRA ou ajustes finos, mas esses distorcem as saídas ou criam ferramentas específicas para o modelo, incompatíveis com o modelo original.
Melhorar os modelos de difusão exige dados de treinamento que enfatizem a física dos reflexos. No entanto, curar conjuntos de dados em hiperescala para cada fraqueza é caro e impraticável.
Ainda assim, surgem soluções, como o projeto MirrorVerse da Índia, que oferece um conjunto de dados aprimorado e um método de treinamento para avançar a precisão dos reflexos em modelos de difusão.

À direita, resultados do MirrorVerse comparados a duas abordagens anteriores (colunas centrais). Fonte: https://arxiv.org/pdf/2504.15397
Como mostrado acima, o MirrorVerse melhora os esforços recentes, mas não é perfeito.
Na imagem superior à direita, jarros de cerâmica estão ligeiramente desalinhados, e na imagem inferior, um reflexo de copo errôneo aparece contra ângulos reflexivos naturais.
Exploraremos esse método não como uma solução definitiva, mas para destacar os desafios persistentes que os modelos de difusão enfrentam em formatos estáticos e de vídeo, onde os dados de reflexo estão frequentemente vinculados a cenários específicos.
Assim, os LDMs podem ficar atrás de NeRF, Gaussian Splatting e CGI tradicional em precisão de reflexos.
O artigo, MirrorVerse: Impulsionando Modelos de Difusão a Refletir Realisticamente o Mundo, vem de pesquisadores do Vision and AI Lab, IISc Bangalore, e do Samsung R&D Institute, Bangalore, com uma página de projeto, conjunto de dados no Hugging Face e código no GitHub.
Metodologia
Os pesquisadores destacam a dificuldade que modelos como Stable Diffusion e Flux enfrentam com prompts baseados em reflexos, conforme mostrado abaixo:

Do artigo: Modelos de texto para imagem de ponta, SD3.5 e Flux, enfrentam dificuldades com reflexos consistentes e geometricamente precisos.
A equipe desenvolveu o MirrorFusion 2.0, um modelo baseado em difusão para melhorar o fotorrealismo e a precisão geométrica dos reflexos no espelho. Ele foi treinado no conjunto de dados MirrorGen2, projetado para abordar questões de generalização.
O MirrorGen2 introduz posicionamento aleatório de objetos, rotações randomizadas e ancoragem explícita de objetos para garantir reflexos plausíveis em diferentes posicionamentos de objetos.
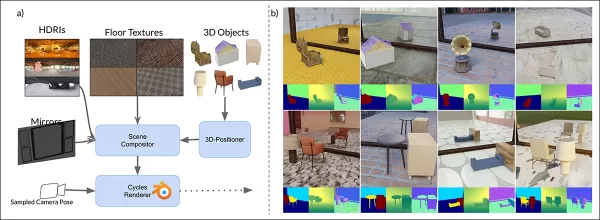
Esquema de dados sintéticos do MirrorVerse: posicionamento aleatório, rotação e ancoragem via 3D-Positioner, com objetos pareados para interações espaciais realistas.
O MirrorGen2 inclui cenas com objetos pareados para melhor lidar com oclusões e arranjos espaciais complexos em configurações reflexivas.
O artigo observa:
‘As categorias são pareadas para coerência semântica, como uma cadeira com uma mesa. Após posicionar o objeto primário, um secundário é adicionado sem sobreposição, garantindo regiões espaciais distintas.’
Para a ancoragem de objetos, os autores garantiram que os objetos fossem fixados ao chão, evitando ‘flutuação’ não natural em dados sintéticos.
Como a inovação do conjunto de dados impulsiona a novidade do artigo, abordaremos isso em seguida.
Dados e Testes
SynMirrorV2
O conjunto de dados SynMirrorV2 aprimora a diversidade dos dados de treinamento de reflexos, usando objetos 3D do Objaverse e Amazon Berkeley Objects (ABO), refinados via OBJECT 3DIT e filtragem do V1 MirrorFusion, resultando em 66.062 objetos de alta qualidade.

Exemplos do conjunto de dados Objaverse usados para o conjunto de dados curado. Fonte: https://arxiv.org/pdf/2212.08051
As cenas foram construídas com pisos texturizados do CC-Textures e fundos HDRI do PolyHaven, usando espelhos de parede inteiras ou retangulares. A iluminação usou uma luz de área em um ângulo de 45 graus. Os objetos foram escalonados, posicionados via interseção do frustum câmera-espelho e rotacionados aleatoriamente no eixo y, com ancoragem para evitar artefatos de flutuação.
Cenas com múltiplos objetos usaram 3.140 pareamentos semanticamente coerentes do ABO, evitando sobreposições para capturar oclusões e profundidade variadas.

Vistas renderizadas do conjunto de dados com múltiplos objetos, mostrando segmentação e mapas de profundidade.
Processo de Treinamento
Um processo de aprendizado em três estágios treinou o MirrorFusion 2.0 para generalização robusta no mundo real.
O Estágio 1 inicializou pesos do Stable Diffusion v1.5, ajustando finamente no split de objeto único do SynMirrorV2 por 40.000 iterações, mantendo ativos os ramos de condicionamento e geração.
O Estágio 2 ajustou finamente por 10.000 iterações no split de múltiplos objetos do SynMirrorV2 para lidar com oclusões e cenas complexas.
O Estágio 3 adicionou 10.000 iterações com dados do conjunto de dados MSD do mundo real, usando mapas de profundidade do Matterport3D.

Exemplos do conjunto de dados MSD com mapas de profundidade e segmentação. Fonte: https://arxiv.org/pdf/1908.09101
Os prompts de texto foram omitidos 20% do tempo para priorizar informações de profundidade. O treinamento usou quatro GPUs NVIDIA A100, uma taxa de aprendizado de 1e-5, tamanho de lote de 4 por GPU e otimizador AdamW.
Esse treinamento progressivo passou de cenas sintéticas simples para cenas complexas do mundo real para melhor transferibilidade.
Testes
O MirrorFusion 2.0 foi testado contra o baseline MirrorFusion no MirrorBenchV2, cobrindo cenas de objeto único e múltiplos objetos, com testes qualitativos nos conjuntos de dados MSD e Google Scanned Objects (GSO).
A avaliação usou 2.991 cenas de objeto único e 300 cenas de dois objetos, medindo PSNR, SSIM e LPIPS para qualidade de reflexo, e CLIP para alinhamento com prompts. As imagens foram geradas com quatro sementes, selecionando a melhor pontuação SSIM.

Esquerda: Qualidade de reflexo de objeto único no MirrorBenchV2, com o MirrorFusion 2.0 superando o baseline. Direita: Qualidade de reflexo de múltiplos objetos, com treinamento de múltiplos objetos melhorando os resultados.
Os autores observam:
‘Nosso método supera o baseline, e o ajuste fino de múltiplos objetos melhora os resultados de cenas complexas.’
Os testes qualitativos enfatizaram as melhorias do MirrorFusion 2.0:

Comparação no MirrorBenchV2: O baseline mostra orientação incorreta da cadeira e reflexos distorcidos; o MirrorFusion 2.0 renderiza com precisão.
Resultados do conjunto de dados GSO:

Comparação no GSO: O baseline distorce a estrutura do objeto; o MirrorFusion 2.0 preserva geometria, cor e detalhes.
Os autores comentam:
‘O MirrorFusion 2.0 reflete com precisão detalhes como alças de gaveta, enquanto o baseline produz resultados implausíveis.’
Resultados do conjunto de dados MSD do mundo real:

Resultados do MSD: O MirrorFusion 2.0, ajustado no MSD, captura cenas complexas com objetos aglomerados e múltiplos espelhos com precisão.
O ajuste fino no MSD melhorou o manejo do MirrorFusion 2.0 de cenas complexas do mundo real, aumentando a coerência dos reflexos.
Um estudo com usuários encontrou que 84% preferiram as saídas do MirrorFusion 2.0.
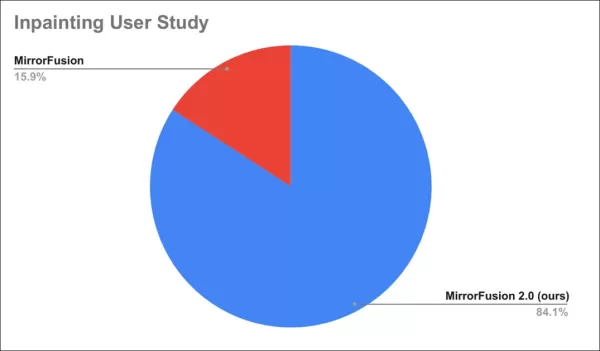
Resultados do estudo com usuários.
Conclusão
Embora o MirrorFusion 2.0 marque progresso, o baseline para precisão de reflexos em modelos de difusão permanece baixo, tornando até melhorias modestas notáveis. A arquitetura dos modelos de difusão enfrenta dificuldades com física consistente, e adicionar dados, como feito aqui, é uma correção padrão, mas limitada.
Conjuntos de dados futuros com melhor distribuição de dados de reflexo poderiam melhorar os resultados, mas isso se aplica a muitas fraquezas dos LDMs. Priorizar quais problemas abordar continua sendo um desafio.
Publicado pela primeira vez na segunda-feira, 28 de abril de 2025
Artigo relacionado
 A OpenAI altera secretamente seus estatutos para dificultar a demissão de Altman
Após o incidente semelhante a um golpe ocorrido em 2023, a OpenAI reforçou ainda mais as proteções ao CEO Sam Altman por meio da atualização de seu estatuto social. Documentos judiciais divulgados rec
A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
Recomendações de tópicos especiais relacionados
Produtividade
A OpenAI altera secretamente seus estatutos para dificultar a demissão de Altman
Após o incidente semelhante a um golpe ocorrido em 2023, a OpenAI reforçou ainda mais as proteções ao CEO Sam Altman por meio da atualização de seu estatuto social. Documentos judiciais divulgados rec
A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
Recomendações de tópicos especiais relacionados
Produtividade
 Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
 10 ferramentas
10 ferramentas
 xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai
chatbot
Os melhores treinadores de paquera e conversação com IA: melhore seu carisma social e sua autoconfiança em tempo real
Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai
código
Os melhores ferramentas de IA para testes unitários automatizados: geração de casos de teste Jest, PyTest e JUnit com apenas um clique
Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai
Análise de dados
As melhores ferramentas de visualização de dados com IA: gere automaticamente painéis interativos de BI a partir de arquivos brutos
Descubra as melhores ferramentas de visualização de dados com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a gerar automaticamente painéis de BI poderosos e interativos a partir de arquivos brutos, de forma instantânea. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Liberte o potencial dos seus dados hoje mesmo.
10 ferramentas
xix.ai

 Comentários (4)
Comentários (4)
![GaryWalker]()
鏡の反射をリアルに描画するAIの進歩ってすごいですね!でも、これが深フェイクに悪用されたらどうなるんだろう…ちょっと怖いかも😅 反射の物理法則を理解するって、AIが現実世界を「見る」能力が向上している証拠でしょうか?
![JimmyWilson]()
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
![FredGreen]()
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
![RogerNelson]()
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯
Desde que a IA generativa conquistou ampla atenção, pesquisadores de visão computacional intensificaram esforços para desenvolver modelos que compreendam e repliquem leis físicas, com foco particular em desafios como simular gravidade e dinâmica de fluidos nos últimos cinco anos.
Com os modelos de difusão latente (LDMs) liderando a IA generativa desde 2022, a atenção se voltou para suas dificuldades em retratar com precisão fenômenos físicos. Essa questão ganhou destaque após o modelo de vídeo Sora da OpenAI e os recentes lançamentos de código aberto de Hunyuan Video e Wan 2.1.
Desafios com Reflexos
A pesquisa para melhorar a compreensão dos LDMs sobre física concentrou-se amplamente em áreas como simulação de marcha e movimento newtoniano, pois imprecisões aqui comprometem o realismo dos vídeos gerados por IA.
No entanto, um número crescente de trabalhos aborda uma fraqueza importante dos LDMs: sua capacidade limitada de gerar reflexos precisos.
Do artigo de janeiro de 2025 'Refletindo a Realidade: Capacitando Modelos de Difusão a Produzir Reflexos Fidedignos no Espelho', exemplos de 'falha de reflexo' versus a abordagem dos pesquisadores. Fonte: https://arxiv.org/pdf/2409.14677
Esse desafio, também prevalente em CGI e jogos de vídeo, depende de algoritmos de rastreamento de raios para simular a interação da luz com superfícies, produzindo reflexos, refrações e sombras realistas.
Entretanto, cada salto adicional de raio de luz aumenta significativamente as demandas computacionais, forçando aplicações em tempo real a equilibrar latência e precisão ao limitar o número de saltos.
Um feixe de luz virtual em um cenário 3D (CGI), usando técnicas da década de 1960, refinadas entre 'Tron' (1982) e 'Jurassic Park' (1993). Fonte: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
Por exemplo, renderizar uma chaleira de cromo diante de um espelho envolve raios de luz saltando repetidamente, criando loops quase infinitos com benefício visual mínimo. Geralmente, dois a três saltos são suficientes para reflexos perceptíveis, pois um único salto resulta em um espelho escuro.
Cada salto extra dobra o tempo de renderização, tornando o manejo eficiente de reflexos crítico para melhorar visuais rastreados por raios.
Os reflexos são vitais para o fotorrealismo em casos mais sutis, como ruas molhadas de cidades, reflexos em vitrines de lojas ou óculos de personagens, onde objetos e ambientes devem aparecer com precisão.
Um reflexo duplo criado por meio de composição tradicional para uma cena em 'The Matrix' (1999).
Desafios em Visuais
Antes dos modelos de difusão, estruturas como Neural Radiance Fields (NeRF) e abordagens mais recentes como Gaussian Splatting lutaram para retratar reflexos de forma natural.
O projeto REF2-NeRF propôs um método baseado em NeRF para cenas com caixas de vidro, modelando refração e reflexo com base na perspectiva do espectador. Isso permitiu a estimativa de superfícies de vidro e a separação de luz direta e refletida.
Exemplos do artigo Ref2Nerf. Fonte: https://arxiv.org/pdf/2311.17116
Outras soluções focadas em reflexos para NeRF incluem NeRFReN, Reflecting Reality e o projeto de 2024 da Meta, Planar Reflection-Aware Neural Radiance Fields.
Para Gaussian Splatting, esforços como Mirror-3DGS, Reflective Gaussian Splatting e RefGaussian abordaram problemas de reflexo, enquanto o projeto Nero de 2023 introduziu um método único para representações neurais.
Avanço do MirrorVerse
Ensinar modelos de difusão a lidar com a lógica de reflexo é mais difícil do que com métodos estruturais como Gaussian Splatting ou NeRF. Reflexos confiáveis em modelos de difusão dependem de dados de treinamento diversos e de alta qualidade em cenários variados.
Tradicionalmente, adicionar tais comportamentos envolve LoRA ou ajustes finos, mas esses distorcem as saídas ou criam ferramentas específicas para o modelo, incompatíveis com o modelo original.
Melhorar os modelos de difusão exige dados de treinamento que enfatizem a física dos reflexos. No entanto, curar conjuntos de dados em hiperescala para cada fraqueza é caro e impraticável.
Ainda assim, surgem soluções, como o projeto MirrorVerse da Índia, que oferece um conjunto de dados aprimorado e um método de treinamento para avançar a precisão dos reflexos em modelos de difusão.
À direita, resultados do MirrorVerse comparados a duas abordagens anteriores (colunas centrais). Fonte: https://arxiv.org/pdf/2504.15397
Como mostrado acima, o MirrorVerse melhora os esforços recentes, mas não é perfeito.
Na imagem superior à direita, jarros de cerâmica estão ligeiramente desalinhados, e na imagem inferior, um reflexo de copo errôneo aparece contra ângulos reflexivos naturais.
Exploraremos esse método não como uma solução definitiva, mas para destacar os desafios persistentes que os modelos de difusão enfrentam em formatos estáticos e de vídeo, onde os dados de reflexo estão frequentemente vinculados a cenários específicos.
Assim, os LDMs podem ficar atrás de NeRF, Gaussian Splatting e CGI tradicional em precisão de reflexos.
O artigo, MirrorVerse: Impulsionando Modelos de Difusão a Refletir Realisticamente o Mundo, vem de pesquisadores do Vision and AI Lab, IISc Bangalore, e do Samsung R&D Institute, Bangalore, com uma página de projeto, conjunto de dados no Hugging Face e código no GitHub.
Metodologia
Os pesquisadores destacam a dificuldade que modelos como Stable Diffusion e Flux enfrentam com prompts baseados em reflexos, conforme mostrado abaixo:
Do artigo: Modelos de texto para imagem de ponta, SD3.5 e Flux, enfrentam dificuldades com reflexos consistentes e geometricamente precisos.
A equipe desenvolveu o MirrorFusion 2.0, um modelo baseado em difusão para melhorar o fotorrealismo e a precisão geométrica dos reflexos no espelho. Ele foi treinado no conjunto de dados MirrorGen2, projetado para abordar questões de generalização.
O MirrorGen2 introduz posicionamento aleatório de objetos, rotações randomizadas e ancoragem explícita de objetos para garantir reflexos plausíveis em diferentes posicionamentos de objetos.
Esquema de dados sintéticos do MirrorVerse: posicionamento aleatório, rotação e ancoragem via 3D-Positioner, com objetos pareados para interações espaciais realistas.
O MirrorGen2 inclui cenas com objetos pareados para melhor lidar com oclusões e arranjos espaciais complexos em configurações reflexivas.
O artigo observa:
‘As categorias são pareadas para coerência semântica, como uma cadeira com uma mesa. Após posicionar o objeto primário, um secundário é adicionado sem sobreposição, garantindo regiões espaciais distintas.’
Para a ancoragem de objetos, os autores garantiram que os objetos fossem fixados ao chão, evitando ‘flutuação’ não natural em dados sintéticos.
Como a inovação do conjunto de dados impulsiona a novidade do artigo, abordaremos isso em seguida.
Dados e Testes
SynMirrorV2
O conjunto de dados SynMirrorV2 aprimora a diversidade dos dados de treinamento de reflexos, usando objetos 3D do Objaverse e Amazon Berkeley Objects (ABO), refinados via OBJECT 3DIT e filtragem do V1 MirrorFusion, resultando em 66.062 objetos de alta qualidade.
Exemplos do conjunto de dados Objaverse usados para o conjunto de dados curado. Fonte: https://arxiv.org/pdf/2212.08051
As cenas foram construídas com pisos texturizados do CC-Textures e fundos HDRI do PolyHaven, usando espelhos de parede inteiras ou retangulares. A iluminação usou uma luz de área em um ângulo de 45 graus. Os objetos foram escalonados, posicionados via interseção do frustum câmera-espelho e rotacionados aleatoriamente no eixo y, com ancoragem para evitar artefatos de flutuação.
Cenas com múltiplos objetos usaram 3.140 pareamentos semanticamente coerentes do ABO, evitando sobreposições para capturar oclusões e profundidade variadas.
Vistas renderizadas do conjunto de dados com múltiplos objetos, mostrando segmentação e mapas de profundidade.
Processo de Treinamento
Um processo de aprendizado em três estágios treinou o MirrorFusion 2.0 para generalização robusta no mundo real.
O Estágio 1 inicializou pesos do Stable Diffusion v1.5, ajustando finamente no split de objeto único do SynMirrorV2 por 40.000 iterações, mantendo ativos os ramos de condicionamento e geração.
O Estágio 2 ajustou finamente por 10.000 iterações no split de múltiplos objetos do SynMirrorV2 para lidar com oclusões e cenas complexas.
O Estágio 3 adicionou 10.000 iterações com dados do conjunto de dados MSD do mundo real, usando mapas de profundidade do Matterport3D.
Exemplos do conjunto de dados MSD com mapas de profundidade e segmentação. Fonte: https://arxiv.org/pdf/1908.09101
Os prompts de texto foram omitidos 20% do tempo para priorizar informações de profundidade. O treinamento usou quatro GPUs NVIDIA A100, uma taxa de aprendizado de 1e-5, tamanho de lote de 4 por GPU e otimizador AdamW.
Esse treinamento progressivo passou de cenas sintéticas simples para cenas complexas do mundo real para melhor transferibilidade.
Testes
O MirrorFusion 2.0 foi testado contra o baseline MirrorFusion no MirrorBenchV2, cobrindo cenas de objeto único e múltiplos objetos, com testes qualitativos nos conjuntos de dados MSD e Google Scanned Objects (GSO).
A avaliação usou 2.991 cenas de objeto único e 300 cenas de dois objetos, medindo PSNR, SSIM e LPIPS para qualidade de reflexo, e CLIP para alinhamento com prompts. As imagens foram geradas com quatro sementes, selecionando a melhor pontuação SSIM.
Esquerda: Qualidade de reflexo de objeto único no MirrorBenchV2, com o MirrorFusion 2.0 superando o baseline. Direita: Qualidade de reflexo de múltiplos objetos, com treinamento de múltiplos objetos melhorando os resultados.
Os autores observam:
‘Nosso método supera o baseline, e o ajuste fino de múltiplos objetos melhora os resultados de cenas complexas.’
Os testes qualitativos enfatizaram as melhorias do MirrorFusion 2.0:
Comparação no MirrorBenchV2: O baseline mostra orientação incorreta da cadeira e reflexos distorcidos; o MirrorFusion 2.0 renderiza com precisão.
Resultados do conjunto de dados GSO:
Comparação no GSO: O baseline distorce a estrutura do objeto; o MirrorFusion 2.0 preserva geometria, cor e detalhes.
Os autores comentam:
‘O MirrorFusion 2.0 reflete com precisão detalhes como alças de gaveta, enquanto o baseline produz resultados implausíveis.’
Resultados do conjunto de dados MSD do mundo real:
Resultados do MSD: O MirrorFusion 2.0, ajustado no MSD, captura cenas complexas com objetos aglomerados e múltiplos espelhos com precisão.
O ajuste fino no MSD melhorou o manejo do MirrorFusion 2.0 de cenas complexas do mundo real, aumentando a coerência dos reflexos.
Um estudo com usuários encontrou que 84% preferiram as saídas do MirrorFusion 2.0.
Resultados do estudo com usuários.
Conclusão
Embora o MirrorFusion 2.0 marque progresso, o baseline para precisão de reflexos em modelos de difusão permanece baixo, tornando até melhorias modestas notáveis. A arquitetura dos modelos de difusão enfrenta dificuldades com física consistente, e adicionar dados, como feito aqui, é uma correção padrão, mas limitada.
Conjuntos de dados futuros com melhor distribuição de dados de reflexo poderiam melhorar os resultados, mas isso se aplica a muitas fraquezas dos LDMs. Priorizar quais problemas abordar continua sendo um desafio.
Publicado pela primeira vez na segunda-feira, 28 de abril de 2025










 A OpenAI altera secretamente seus estatutos para dificultar a demissão de Altman
Após o incidente semelhante a um golpe ocorrido em 2023, a OpenAI reforçou ainda mais as proteções ao CEO Sam Altman por meio da atualização de seu estatuto social. Documentos judiciais divulgados rec
A OpenAI altera secretamente seus estatutos para dificultar a demissão de Altman
Após o incidente semelhante a um golpe ocorrido em 2023, a OpenAI reforçou ainda mais as proteções ao CEO Sam Altman por meio da atualização de seu estatuto social. Documentos judiciais divulgados rec
 A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
A Meta AI agora responde às mensagens dos compradores no Facebook Marketplace
O Facebook Marketplace lança novos recursos de IA da Meta, incluindo respostas automáticas às consultas dos compradores, anunciou a empresa nesta quinta-feira. A plataforma também utiliza IA para agil
 A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam
A OpenAI traça os contornos da economia da IA com fundos de riqueza pública, impostos sobre robôs e a semana de quatro dias
Enquanto os governos lutam para lidar com o impacto econômico das máquinas superinteligentes, a OpenAI divulgou um conjunto de propostas de políticas que delineiam como a riqueza e o trabalho poderiam

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

Descubra as mais recentes e bem avaliadas ferramentas de IA de 2026 para testes unitários automatizados. Nossa seleção cuidadosa inclui soluções poderosas que podem transformar o seu processo, permitindo gerar casos de teste para Jest, PyTest e JUnit de forma instantânea. Compare opções gratuitas e pagas com testes reais e classificações atualizadas semanalmente no XIX.AI. Desfrute das vantagens da IA e aumente a produtividade do seu desenvolvimento hoje mesmo.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de visualização de dados com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a gerar automaticamente painéis de BI poderosos e interativos a partir de arquivos brutos, de forma instantânea. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Liberte o potencial dos seus dados hoje mesmo.
10 ferramentas
xix.ai

鏡の反射をリアルに描画するAIの進歩ってすごいですね!でも、これが深フェイクに悪用されたらどうなるんだろう…ちょっと怖いかも😅 反射の物理法則を理解するって、AIが現実世界を「見る」能力が向上している証拠でしょうか?
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯













