




Amélioration de la capacité de l'IA à rendre des réflexions réalistes dans les miroirs
Depuis que l'IA générative a capté une attention généralisée, les chercheurs en vision par ordinateur ont intensifié leurs efforts pour développer des modèles capables de comprendre et de reproduire les lois physiques, avec un accent particulier sur des défis comme la simulation de la gravité et de la dynamique des fluides au cours des cinq dernières années.
Avec les modèles de diffusion latente (LDMs) à la tête de l'IA générative depuis 2022, l'attention s'est portée sur leurs difficultés à dépeindre précisément les phénomènes physiques. Ce problème a gagné en importance suite au modèle vidéo Sora d'OpenAI et aux récentes publications open-source de Hunyuan Video et Wan 2.1.
Difficultés avec les réflexions
La recherche pour améliorer la compréhension des LDMs des lois physiques s'est largement concentrée sur des domaines comme la simulation de la démarche et le mouvement newtonien, car les inexactitudes ici compromettent le réalisme des vidéos générées par l'IA.
Cependant, un ensemble croissant de travaux cible une faiblesse clé des LDMs : leur capacité limitée à générer des réflexions précises.

Extrait de l'article de janvier 2025 ‘Reflecting Reality: Enabling Diffusion Models to Produce Faithful Mirror Reflections’, exemples d’échec de réflexion par rapport à l’approche des chercheurs. Source : https://arxiv.org/pdf/2409.14677
Ce défi, également présent dans le CGI et les jeux vidéo, repose sur des algorithmes de traçage de rayons pour simuler l’interaction de la lumière avec les surfaces, produisant des réflexions, réfractions et ombres réalistes.
Cependant, chaque rebond supplémentaire de rayons lumineux augmente considérablement les exigences computationnelles, obligeant les applications en temps réel à équilibrer la latence et la précision en limitant le nombre de rebonds.
![Une représentation d’un faisceau lumineux calculé virtuellement dans un scénario 3D traditionnel (c.-à-d., CGI), utilisant des technologies et principes développés dans les années 1960, et qui ont porté leurs fruits entre 1982-93 (la période entre Tron [1982] et Jurassic Park [1993]). Source : https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing](https://img.xix.ai/uploads/55/680fa78ce2769.webp)
Un faisceau lumineux virtuel dans un scénario 3D (CGI), utilisant des techniques des années 1960, affinées entre ‘Tron’ (1982) et ‘Jurassic Park’ (1993). Source : https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
Par exemple, rendre une théière chromée devant un miroir implique des rayons lumineux rebondissant de manière répétée, créant des boucles quasi infinies avec un bénéfice visuel minimal. Généralement, deux à trois rebonds suffisent pour des réflexions perceptibles, car un seul rebond produit un miroir sombre.
Chaque rebond supplémentaire double le temps de rendu, rendant la gestion efficace des réflexions cruciale pour améliorer les visuels traçés par rayons.
Les réflexions sont vitales pour le photoréalisme dans des cas plus subtils, comme les rues urbaines mouillées, les reflets des vitrines ou les lunettes des personnages, où les objets et environnements doivent apparaître précisément.

Une réflexion jumelle créée par composition traditionnelle pour une scène de ‘The Matrix’ (1999).
Défis visuels
Avant les modèles de diffusion, des cadres comme les Neural Radiance Fields (NeRF) et les approches plus récentes comme le Gaussian Splatting ont eu du mal à représenter naturellement les réflexions.
Le projet REF2-NeRF a proposé une méthode basée sur NeRF pour les scènes avec des vitrines, modélisant la réfraction et la réflexion en fonction de la perspective du spectateur. Cela a permis d’estimer les surfaces vitrées et de séparer la lumière directe et réfléchie.

Exemples de l'article Ref2Nerf. Source : https://arxiv.org/pdf/2311.17116
D’autres solutions axées sur les réflexions pour NeRF incluent NeRFReN, Reflecting Reality, et le projet de Meta 2024 Planar Reflection-Aware Neural Radiance Fields.
Pour le Gaussian Splatting, des efforts comme Mirror-3DGS, Reflective Gaussian Splatting, et RefGaussian ont abordé les problèmes de réflexion, tandis que le projet Nero 2023 a introduit une méthode unique pour les représentations neuronales.
Percée de MirrorVerse
Enseigner aux modèles de diffusion à gérer la logique des réflexions est plus difficile qu’avec des méthodes structurelles comme le Gaussian Splatting ou NeRF. Des réflexions fiables dans les modèles de diffusion dépendent de données d’entraînement diversifiées et de haute qualité dans des scénarios variés.
Traditionnellement, ajouter de tels comportements implique LoRA ou un réglage fin, mais ceux-ci biaisent les sorties ou créent des outils spécifiques au modèle, incompatibles avec le modèle original.
Améliorer les modèles de diffusion nécessite des données d’entraînement qui mettent l’accent sur la physique des réflexions. Cependant, constituer des ensembles de données à grande échelle pour chaque faiblesse est coûteux et peu pratique.
Néanmoins, des solutions émergent, comme le projet indien MirrorVerse, qui propose un ensemble de données amélioré et une méthode d’entraînement pour avancer la précision des réflexions dans les modèles de diffusion.

À droite, les résultats de MirrorVerse comparés à deux approches précédentes (colonnes centrales). Source : https://arxiv.org/pdf/2504.15397
Comme montré ci-dessus, MirrorVerse améliore les efforts récents mais n’est pas parfait.
Dans l’image en haut à droite, les jarres en céramique sont légèrement mal alignées, et dans l’image inférieure, une réflexion erronée d’une tasse apparaît contre les angles réfléchissants naturels.
Nous explorerons cette méthode non comme une solution définitive, mais pour souligner les défis persistants des modèles de diffusion dans les formats statiques et vidéo, où les données de réflexion sont souvent liées à des scénarios spécifiques.
Ainsi, les LDMs peuvent rester en retard par rapport à NeRF, Gaussian Splatting, et le CGI traditionnel en termes de précision des réflexions.
L’article, MirrorVerse : Faire en sorte que les modèles de diffusion reflètent le monde de manière réaliste, provient de chercheurs du Vision and AI Lab, IISc Bangalore, et du Samsung R&D Institute, Bangalore, avec une page de projet, un ensemble de données Hugging Face, et un code GitHub.
Méthodologie
Les chercheurs soulignent la difficulté des modèles comme Stable Diffusion et Flux à gérer les invites basées sur les réflexions, comme montré ci-dessous :

Extrait de l'article : Les meilleurs modèles texte-à-image, SD3.5 et Flux, peinent à produire des réflexions cohérentes et géométriquement précises.
L’équipe a développé MirrorFusion 2.0, un modèle basé sur la diffusion pour améliorer le photoréalisme et la précision géométrique des réflexions dans les miroirs. Il a été entraîné sur leur ensemble de données MirrorGen2, conçu pour résoudre les problèmes de généralisation.
MirrorGen2 introduit un positionnement aléatoire des objets, des rotations randomisées, et un ancrage explicite des objets pour garantir des réflexions plausibles dans diverses dispositions d’objets.
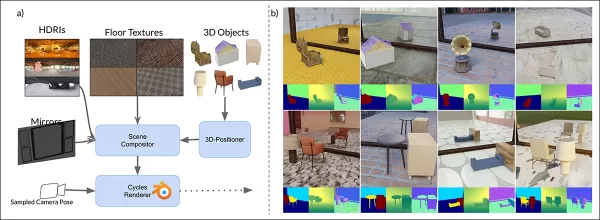
Schéma des données synthétiques de MirrorVerse : positionnement aléatoire, rotation et ancrage via 3D-Positioner, avec des objets appariés pour des interactions spatiales réalistes.
MirrorGen2 inclut des scènes d’objets appariés pour mieux gérer les occlusions et les arrangements spatiaux complexes dans des contextes réfléchissants.
L’article note :
‘Les catégories sont appariées pour une cohérence sémantique, comme une chaise avec une table. Après avoir positionné l’objet principal, un objet secondaire est ajouté sans chevauchement, assurant des régions spatiales distinctes.’
Pour l’ancrage des objets, les auteurs se sont assurés que les objets étaient ancrés au sol, évitant les artefacts de ‘flottement’ non naturels dans les données synthétiques.
Puisque l’innovation des données est au cœur de la nouveauté de l’article, nous aborderons cela ensuite.
Données et tests
SynMirrorV2
L’ensemble de données SynMirrorV2 améliore la diversité des données d’entraînement pour les réflexions, utilisant des objets 3D d’Objaverse et d’Amazon Berkeley Objects (ABO), affinés via OBJECT 3DIT et le filtrage V1 MirrorFusion, produisant 66 062 objets de haute qualité.

Exemples de l’ensemble de données Objaverse utilisé pour l’ensemble de données curated. Source : https://arxiv.org/pdf/2212.08051
Les scènes ont été construites avec des sols texturés de CC-Textures et des arrière-plans HDRI de PolyHaven, utilisant des miroirs pleine paroi ou rectangulaires. L’éclairage utilisait une lumière d’aire à un angle de 45 degrés. Les objets étaient redimensionnés, positionnés via l’intersection du frustum miroir-caméra, et tournés aléatoirement sur l’axe y, avec ancrage pour éviter les artefacts de flottement.
Les scènes multi-objets utilisaient 3 140 appariements sémantiquement cohérents d’ABO, évitant les chevauchements pour capturer diverses occlusions et profondeurs.

Vues rendues à partir de l’ensemble de données avec plusieurs objets, montrant la segmentation et les cartes de profondeur.
Processus d’entraînement
Un processus d’apprentissage par curriculum en trois étapes a entraîné MirrorFusion 2.0 pour une généralisation robuste dans le monde réel.
L’étape 1 a initialisé les poids à partir de Stable Diffusion v1.5, avec un réglage fin sur la division à objet unique de SynMirrorV2 pour 40 000 itérations, maintenant actives les branches de conditionnement et de génération.
L’étape 2 a affiné pendant 10 000 itérations sur la division multi-objets de SynMirrorV2 pour gérer les occlusions et les scènes complexes.
L’étape 3 a ajouté 10 000 itérations avec des données réelles de l’ensemble MSD, utilisant des cartes de profondeur Matterport3D.

Exemples de l’ensemble de données MSD avec des cartes de profondeur et de segmentation. Source : https://arxiv.org/pdf/1908.09101
Les invites textuelles ont été omises 20 % du temps pour prioriser les informations de profondeur. L’entraînement a utilisé quatre GPU NVIDIA A100, un taux d’apprentissage de 1e-5, une taille de lot de 4 par GPU, et l’optimiseur AdamW.
Cet entraînement progressif est passé de scènes synthétiques simples à des scènes réelles complexes pour une meilleure transférabilité.
Tests
MirrorFusion 2.0 a été testé contre la base de référence MirrorFusion sur MirrorBenchV2, couvrant les scènes à objet unique et multi-objets, avec des tests qualitatifs sur les ensembles de données MSD et Google Scanned Objects (GSO).
L’évaluation a utilisé 2 991 scènes à objet unique et 300 scènes à deux objets, mesurant PSNR, SSIM, et LPIPS pour la qualité des réflexions, et CLIP pour l’alignement des invites. Les images ont été générées avec quatre graines, sélectionnant le meilleur score SSIM.

À gauche : Qualité de réflexion d’objet unique sur MirrorBenchV2, avec MirrorFusion 2.0 surpassant la base de référence. À droite : Qualité de réflexion multi-objets, avec l’entraînement multi-objets améliorant les résultats.
Les auteurs notent :
‘Notre méthode surpasse la base de référence, et le réglage fin multi-objets améliore les résultats des scènes complexes.’
Les tests qualitatifs ont souligné les améliorations de MirrorFusion 2.0 :

Comparaison MirrorBenchV2 : La base de référence montre une orientation incorrecte de la chaise et des réflexions déformées ; MirrorFusion 2.0 rend précisément.
Les résultats de l’ensemble de données GSO :

Comparaison GSO : La base de référence déforme la structure des objets ; MirrorFusion 2.0 préserve la géométrie, la couleur et les détails.
Les auteurs commentent :
‘MirrorFusion 2.0 reflète précisément des détails comme les poignées de tiroirs, tandis que la base de référence produit des résultats invraisemblables.’
Résultats de l’ensemble de données MSD réel :

Résultats MSD : MirrorFusion 2.0, affiné sur MSD, capture précisément les scènes complexes avec des objets encombrés et plusieurs miroirs.
Le réglage fin sur MSD a amélioré la gestion par MirrorFusion 2.0 des scènes réelles complexes, renforçant la cohérence des réflexions.
Une étude auprès des utilisateurs a révélé que 84 % préféraient les sorties de MirrorFusion 2.0.
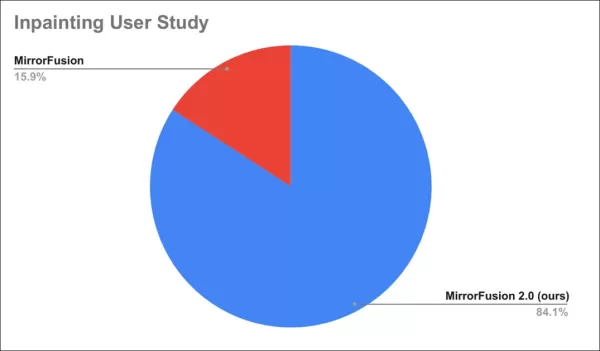
Résultats de l’étude auprès des utilisateurs.
Conclusion
Bien que MirrorFusion 2.0 marque des progrès, la base de référence pour la précision des réflexions dans les modèles de diffusion reste faible, rendant même des améliorations modestes notables. L’architecture des modèles de diffusion a du mal avec une physique cohérente, et ajouter des données, comme ici, est une solution standard mais limitée.
De futurs ensembles de données avec une meilleure distribution des données de réflexion pourraient améliorer les résultats, mais cela s’applique à de nombreuses faiblesses des LDMs. Prioriser les problèmes à résoudre reste un défi.
Publié pour la première fois le lundi 28 avril 2025
Article connexe
 Controverse sur l'art de l'IA : Aborder le droit d'auteur et l'éthique dans les créations numériques
Le paysage artistique, en particulier au sein de communautés spécialisées telles que les amateurs d'art furry, continue de se transformer de manière spectaculaire. L'avènement des outils de création a
Le projet de loi sur l'IA de l'UE propose des règles plus souples pour les modèles d'IA des grandes entreprises technologiques
À l'approche de l'échéance de mai pour la finalisation des lignes directrices prévues par la loi européenne sur l'IA, les autorités ont publié une troisième et probablement dernière version du code de
ChatGPT transforme les utilisateurs de LinkedIn en clones d'IA monotones
La dernière itération des capacités de génération d'images de ChatGPT a fait des vagues avec ses œuvres d'art inspirées du Studio Ghibli. Aujourd'hui, les utilisateurs de LinkedIn sont à l'origine d'u
commentaires (3)
0/200
Controverse sur l'art de l'IA : Aborder le droit d'auteur et l'éthique dans les créations numériques
Le paysage artistique, en particulier au sein de communautés spécialisées telles que les amateurs d'art furry, continue de se transformer de manière spectaculaire. L'avènement des outils de création a
Le projet de loi sur l'IA de l'UE propose des règles plus souples pour les modèles d'IA des grandes entreprises technologiques
À l'approche de l'échéance de mai pour la finalisation des lignes directrices prévues par la loi européenne sur l'IA, les autorités ont publié une troisième et probablement dernière version du code de
ChatGPT transforme les utilisateurs de LinkedIn en clones d'IA monotones
La dernière itération des capacités de génération d'images de ChatGPT a fait des vagues avec ses œuvres d'art inspirées du Studio Ghibli. Aujourd'hui, les utilisateurs de LinkedIn sont à l'origine d'u
commentaires (3)
0/200
![JimmyWilson]() JimmyWilson
JimmyWilson
 21 août 2025 21:01:25 UTC+02:00
21 août 2025 21:01:25 UTC+02:00
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎


 0
0
![FredGreen]() FredGreen
2 août 2025 17:07:14 UTC+02:00
FredGreen
2 août 2025 17:07:14 UTC+02:00
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
0
![RogerNelson]() RogerNelson
28 juillet 2025 03:20:21 UTC+02:00
RogerNelson
28 juillet 2025 03:20:21 UTC+02:00
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯
0
Depuis que l'IA générative a capté une attention généralisée, les chercheurs en vision par ordinateur ont intensifié leurs efforts pour développer des modèles capables de comprendre et de reproduire les lois physiques, avec un accent particulier sur des défis comme la simulation de la gravité et de la dynamique des fluides au cours des cinq dernières années.
Avec les modèles de diffusion latente (LDMs) à la tête de l'IA générative depuis 2022, l'attention s'est portée sur leurs difficultés à dépeindre précisément les phénomènes physiques. Ce problème a gagné en importance suite au modèle vidéo Sora d'OpenAI et aux récentes publications open-source de Hunyuan Video et Wan 2.1.
Difficultés avec les réflexions
La recherche pour améliorer la compréhension des LDMs des lois physiques s'est largement concentrée sur des domaines comme la simulation de la démarche et le mouvement newtonien, car les inexactitudes ici compromettent le réalisme des vidéos générées par l'IA.
Cependant, un ensemble croissant de travaux cible une faiblesse clé des LDMs : leur capacité limitée à générer des réflexions précises.
Extrait de l'article de janvier 2025 ‘Reflecting Reality: Enabling Diffusion Models to Produce Faithful Mirror Reflections’, exemples d’échec de réflexion par rapport à l’approche des chercheurs. Source : https://arxiv.org/pdf/2409.14677
Ce défi, également présent dans le CGI et les jeux vidéo, repose sur des algorithmes de traçage de rayons pour simuler l’interaction de la lumière avec les surfaces, produisant des réflexions, réfractions et ombres réalistes.
Cependant, chaque rebond supplémentaire de rayons lumineux augmente considérablement les exigences computationnelles, obligeant les applications en temps réel à équilibrer la latence et la précision en limitant le nombre de rebonds.
Un faisceau lumineux virtuel dans un scénario 3D (CGI), utilisant des techniques des années 1960, affinées entre ‘Tron’ (1982) et ‘Jurassic Park’ (1993). Source : https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
Par exemple, rendre une théière chromée devant un miroir implique des rayons lumineux rebondissant de manière répétée, créant des boucles quasi infinies avec un bénéfice visuel minimal. Généralement, deux à trois rebonds suffisent pour des réflexions perceptibles, car un seul rebond produit un miroir sombre.
Chaque rebond supplémentaire double le temps de rendu, rendant la gestion efficace des réflexions cruciale pour améliorer les visuels traçés par rayons.
Les réflexions sont vitales pour le photoréalisme dans des cas plus subtils, comme les rues urbaines mouillées, les reflets des vitrines ou les lunettes des personnages, où les objets et environnements doivent apparaître précisément.
Une réflexion jumelle créée par composition traditionnelle pour une scène de ‘The Matrix’ (1999).
Défis visuels
Avant les modèles de diffusion, des cadres comme les Neural Radiance Fields (NeRF) et les approches plus récentes comme le Gaussian Splatting ont eu du mal à représenter naturellement les réflexions.
Le projet REF2-NeRF a proposé une méthode basée sur NeRF pour les scènes avec des vitrines, modélisant la réfraction et la réflexion en fonction de la perspective du spectateur. Cela a permis d’estimer les surfaces vitrées et de séparer la lumière directe et réfléchie.
Exemples de l'article Ref2Nerf. Source : https://arxiv.org/pdf/2311.17116
D’autres solutions axées sur les réflexions pour NeRF incluent NeRFReN, Reflecting Reality, et le projet de Meta 2024 Planar Reflection-Aware Neural Radiance Fields.
Pour le Gaussian Splatting, des efforts comme Mirror-3DGS, Reflective Gaussian Splatting, et RefGaussian ont abordé les problèmes de réflexion, tandis que le projet Nero 2023 a introduit une méthode unique pour les représentations neuronales.
Percée de MirrorVerse
Enseigner aux modèles de diffusion à gérer la logique des réflexions est plus difficile qu’avec des méthodes structurelles comme le Gaussian Splatting ou NeRF. Des réflexions fiables dans les modèles de diffusion dépendent de données d’entraînement diversifiées et de haute qualité dans des scénarios variés.
Traditionnellement, ajouter de tels comportements implique LoRA ou un réglage fin, mais ceux-ci biaisent les sorties ou créent des outils spécifiques au modèle, incompatibles avec le modèle original.
Améliorer les modèles de diffusion nécessite des données d’entraînement qui mettent l’accent sur la physique des réflexions. Cependant, constituer des ensembles de données à grande échelle pour chaque faiblesse est coûteux et peu pratique.
Néanmoins, des solutions émergent, comme le projet indien MirrorVerse, qui propose un ensemble de données amélioré et une méthode d’entraînement pour avancer la précision des réflexions dans les modèles de diffusion.
À droite, les résultats de MirrorVerse comparés à deux approches précédentes (colonnes centrales). Source : https://arxiv.org/pdf/2504.15397
Comme montré ci-dessus, MirrorVerse améliore les efforts récents mais n’est pas parfait.
Dans l’image en haut à droite, les jarres en céramique sont légèrement mal alignées, et dans l’image inférieure, une réflexion erronée d’une tasse apparaît contre les angles réfléchissants naturels.
Nous explorerons cette méthode non comme une solution définitive, mais pour souligner les défis persistants des modèles de diffusion dans les formats statiques et vidéo, où les données de réflexion sont souvent liées à des scénarios spécifiques.
Ainsi, les LDMs peuvent rester en retard par rapport à NeRF, Gaussian Splatting, et le CGI traditionnel en termes de précision des réflexions.
L’article, MirrorVerse : Faire en sorte que les modèles de diffusion reflètent le monde de manière réaliste, provient de chercheurs du Vision and AI Lab, IISc Bangalore, et du Samsung R&D Institute, Bangalore, avec une page de projet, un ensemble de données Hugging Face, et un code GitHub.
Méthodologie
Les chercheurs soulignent la difficulté des modèles comme Stable Diffusion et Flux à gérer les invites basées sur les réflexions, comme montré ci-dessous :
Extrait de l'article : Les meilleurs modèles texte-à-image, SD3.5 et Flux, peinent à produire des réflexions cohérentes et géométriquement précises.
L’équipe a développé MirrorFusion 2.0, un modèle basé sur la diffusion pour améliorer le photoréalisme et la précision géométrique des réflexions dans les miroirs. Il a été entraîné sur leur ensemble de données MirrorGen2, conçu pour résoudre les problèmes de généralisation.
MirrorGen2 introduit un positionnement aléatoire des objets, des rotations randomisées, et un ancrage explicite des objets pour garantir des réflexions plausibles dans diverses dispositions d’objets.
Schéma des données synthétiques de MirrorVerse : positionnement aléatoire, rotation et ancrage via 3D-Positioner, avec des objets appariés pour des interactions spatiales réalistes.
MirrorGen2 inclut des scènes d’objets appariés pour mieux gérer les occlusions et les arrangements spatiaux complexes dans des contextes réfléchissants.
L’article note :
‘Les catégories sont appariées pour une cohérence sémantique, comme une chaise avec une table. Après avoir positionné l’objet principal, un objet secondaire est ajouté sans chevauchement, assurant des régions spatiales distinctes.’
Pour l’ancrage des objets, les auteurs se sont assurés que les objets étaient ancrés au sol, évitant les artefacts de ‘flottement’ non naturels dans les données synthétiques.
Puisque l’innovation des données est au cœur de la nouveauté de l’article, nous aborderons cela ensuite.
Données et tests
SynMirrorV2
L’ensemble de données SynMirrorV2 améliore la diversité des données d’entraînement pour les réflexions, utilisant des objets 3D d’Objaverse et d’Amazon Berkeley Objects (ABO), affinés via OBJECT 3DIT et le filtrage V1 MirrorFusion, produisant 66 062 objets de haute qualité.
Exemples de l’ensemble de données Objaverse utilisé pour l’ensemble de données curated. Source : https://arxiv.org/pdf/2212.08051
Les scènes ont été construites avec des sols texturés de CC-Textures et des arrière-plans HDRI de PolyHaven, utilisant des miroirs pleine paroi ou rectangulaires. L’éclairage utilisait une lumière d’aire à un angle de 45 degrés. Les objets étaient redimensionnés, positionnés via l’intersection du frustum miroir-caméra, et tournés aléatoirement sur l’axe y, avec ancrage pour éviter les artefacts de flottement.
Les scènes multi-objets utilisaient 3 140 appariements sémantiquement cohérents d’ABO, évitant les chevauchements pour capturer diverses occlusions et profondeurs.
Vues rendues à partir de l’ensemble de données avec plusieurs objets, montrant la segmentation et les cartes de profondeur.
Processus d’entraînement
Un processus d’apprentissage par curriculum en trois étapes a entraîné MirrorFusion 2.0 pour une généralisation robuste dans le monde réel.
L’étape 1 a initialisé les poids à partir de Stable Diffusion v1.5, avec un réglage fin sur la division à objet unique de SynMirrorV2 pour 40 000 itérations, maintenant actives les branches de conditionnement et de génération.
L’étape 2 a affiné pendant 10 000 itérations sur la division multi-objets de SynMirrorV2 pour gérer les occlusions et les scènes complexes.
L’étape 3 a ajouté 10 000 itérations avec des données réelles de l’ensemble MSD, utilisant des cartes de profondeur Matterport3D.
Exemples de l’ensemble de données MSD avec des cartes de profondeur et de segmentation. Source : https://arxiv.org/pdf/1908.09101
Les invites textuelles ont été omises 20 % du temps pour prioriser les informations de profondeur. L’entraînement a utilisé quatre GPU NVIDIA A100, un taux d’apprentissage de 1e-5, une taille de lot de 4 par GPU, et l’optimiseur AdamW.
Cet entraînement progressif est passé de scènes synthétiques simples à des scènes réelles complexes pour une meilleure transférabilité.
Tests
MirrorFusion 2.0 a été testé contre la base de référence MirrorFusion sur MirrorBenchV2, couvrant les scènes à objet unique et multi-objets, avec des tests qualitatifs sur les ensembles de données MSD et Google Scanned Objects (GSO).
L’évaluation a utilisé 2 991 scènes à objet unique et 300 scènes à deux objets, mesurant PSNR, SSIM, et LPIPS pour la qualité des réflexions, et CLIP pour l’alignement des invites. Les images ont été générées avec quatre graines, sélectionnant le meilleur score SSIM.
À gauche : Qualité de réflexion d’objet unique sur MirrorBenchV2, avec MirrorFusion 2.0 surpassant la base de référence. À droite : Qualité de réflexion multi-objets, avec l’entraînement multi-objets améliorant les résultats.
Les auteurs notent :
‘Notre méthode surpasse la base de référence, et le réglage fin multi-objets améliore les résultats des scènes complexes.’
Les tests qualitatifs ont souligné les améliorations de MirrorFusion 2.0 :
Comparaison MirrorBenchV2 : La base de référence montre une orientation incorrecte de la chaise et des réflexions déformées ; MirrorFusion 2.0 rend précisément.
Les résultats de l’ensemble de données GSO :
Comparaison GSO : La base de référence déforme la structure des objets ; MirrorFusion 2.0 préserve la géométrie, la couleur et les détails.
Les auteurs commentent :
‘MirrorFusion 2.0 reflète précisément des détails comme les poignées de tiroirs, tandis que la base de référence produit des résultats invraisemblables.’
Résultats de l’ensemble de données MSD réel :
Résultats MSD : MirrorFusion 2.0, affiné sur MSD, capture précisément les scènes complexes avec des objets encombrés et plusieurs miroirs.
Le réglage fin sur MSD a amélioré la gestion par MirrorFusion 2.0 des scènes réelles complexes, renforçant la cohérence des réflexions.
Une étude auprès des utilisateurs a révélé que 84 % préféraient les sorties de MirrorFusion 2.0.
Résultats de l’étude auprès des utilisateurs.
Conclusion
Bien que MirrorFusion 2.0 marque des progrès, la base de référence pour la précision des réflexions dans les modèles de diffusion reste faible, rendant même des améliorations modestes notables. L’architecture des modèles de diffusion a du mal avec une physique cohérente, et ajouter des données, comme ici, est une solution standard mais limitée.
De futurs ensembles de données avec une meilleure distribution des données de réflexion pourraient améliorer les résultats, mais cela s’applique à de nombreuses faiblesses des LDMs. Prioriser les problèmes à résoudre reste un défi.
Publié pour la première fois le lundi 28 avril 2025










 Controverse sur l'art de l'IA : Aborder le droit d'auteur et l'éthique dans les créations numériques
Le paysage artistique, en particulier au sein de communautés spécialisées telles que les amateurs d'art furry, continue de se transformer de manière spectaculaire. L'avènement des outils de création a
Le projet de loi sur l'IA de l'UE propose des règles plus souples pour les modèles d'IA des grandes entreprises technologiques
À l'approche de l'échéance de mai pour la finalisation des lignes directrices prévues par la loi européenne sur l'IA, les autorités ont publié une troisième et probablement dernière version du code de
Controverse sur l'art de l'IA : Aborder le droit d'auteur et l'éthique dans les créations numériques
Le paysage artistique, en particulier au sein de communautés spécialisées telles que les amateurs d'art furry, continue de se transformer de manière spectaculaire. L'avènement des outils de création a
Le projet de loi sur l'IA de l'UE propose des règles plus souples pour les modèles d'IA des grandes entreprises technologiques
À l'approche de l'échéance de mai pour la finalisation des lignes directrices prévues par la loi européenne sur l'IA, les autorités ont publié une troisième et probablement dernière version du code de
 ChatGPT transforme les utilisateurs de LinkedIn en clones d'IA monotones
La dernière itération des capacités de génération d'images de ChatGPT a fait des vagues avec ses œuvres d'art inspirées du Studio Ghibli. Aujourd'hui, les utilisateurs de LinkedIn sont à l'origine d'u
21 août 2025 21:01:25 UTC+02:00
ChatGPT transforme les utilisateurs de LinkedIn en clones d'IA monotones
La dernière itération des capacités de génération d'images de ChatGPT a fait des vagues avec ses œuvres d'art inspirées du Studio Ghibli. Aujourd'hui, les utilisateurs de LinkedIn sont à l'origine d'u
21 août 2025 21:01:25 UTC+02:00
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
0
2 août 2025 17:07:14 UTC+02:00
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
0
28 juillet 2025 03:20:21 UTC+02:00
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯
0













