
















 家
家AIの現実的な鏡面反射レンダリング能力の強化
生成AIが広く注目を集めて以来、コンピュータビジョンの研究者たちは、物理法則を理解し再現するモデルの開発に力を入れており、特に過去5年間は重力や流体力学のシミュレーションといった課題に焦点を当ててきました。
2022年以降、潜在拡散モデル(LDMs)が生成AIをリードする中、物理現象を正確に描写する難しさが注目されています。この問題は、OpenAIのSoraビデオモデルや最近のオープンソースであるHunyuan VideoやWan 2.1のリリースを受けて、さらに注目を集めています。
反射の課題
LDMsの物理法則の理解を改善するための研究は、主に歩行シミュレーションやニュートン運動などの分野に集中しており、これらの不正確さがAI生成ビデオのリアリズムを損なっています。
しかし、LDMの重要な弱点である正確な反射の生成能力の限界を対象とした研究が増えています。

2025年1月の論文『Reflecting Reality: Enabling Diffusion Models to Produce Faithful Mirror Reflections』より、『反射の失敗』の例と研究者自身の手法の比較。 出典: https://arxiv.org/pdf/2409.14677
この課題は、CGIやビデオゲームでも一般的で、レイトレーシングアルゴリズムを使用して光と表面の相互作用をシミュレートし、リアルな反射、屈折、影を生成します。
しかし、光線の一回の追加バウンスごとに計算負荷が大幅に増加し、リアルタイムアプリケーションではレイテンシーと精度のバランスを取るためにバウンス数を制限する必要があります。
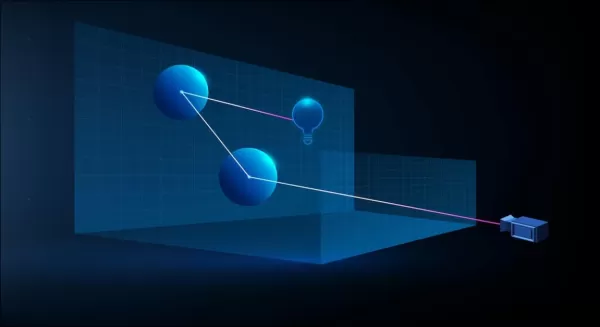
3Dベース(CGI)のシナリオでの仮想光線ビーム。1960年代の技術を使用し、『Tron』(1982年)と『Jurassic Park』(1993年)の間で改良されました。 出典: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
たとえば、鏡の前のクロムティーポットをレンダリングする場合、光線が繰り返しバウンスし、視覚的メリットがほとんどないほぼ無限のループが生じます。通常、2~3回のバウンスで知覚可能な反射が得られ、1回だけのバウンスでは暗い鏡になります。
追加のバウンスごとにレンダリング時間が2倍になるため、効率的な反射処理はレイトレーシングビジュアルの改善に不可欠です。
反射は、濡れた都市の通り、店舗の窓の反射、キャラクターのメガネなど、より微妙なケースでのフォトリアリズムに不可欠であり、オブジェクトや環境が正確に映る必要があります。

『The Matrix』(1999年)のシーンで従来のコンポジティングによって作成された双子反射。
ビジュアルの課題
拡散モデルの前には、Neural Radiance Fields(NeRF)やGaussian Splattingのような新しいアプローチが反射を自然に描写するのに苦労していました。
REF2-NeRFプロジェクトは、ガラスケースのあるシーン向けにNeRFベースの手法を提案し、視聴者の視点に基づいて屈折と反射をモデル化しました。これにより、ガラス表面の推定と直接光および反射光の分離が可能になりました。

Ref2Nerf論文の例。 出典: https://arxiv.org/pdf/2311.17116
他の反射に焦点を当てたNeRFソリューションには、NeRFReN、Reflecting Reality、Metaの2024年のPlanar Reflection-Aware Neural Radiance Fieldsプロジェクトが含まれます。
Gaussian Splattingでは、Mirror-3DGS、Reflective Gaussian Splatting、RefGaussianが反射の問題に取り組み、2023年のNeroプロジェクトはニューラル表現のための独自の手法を導入しました。
MirrorVerseのブレークスルー
拡散モデルに反射ロジックを教えることは、Gaussian SplattingやNeRFのような構造的手法よりも難しいです。拡散モデルでの信頼性の高い反射は、多様なシナリオにわたる高品質なトレーニングデータに依存します。
従来、このような動作の追加にはLoRAやファインチューニングが含まれますが、これらは出力を歪めたり、元のモデルと互換性のないモデル固有のツールを作成したりします。
拡散モデルの改善には、反射物理を強調したトレーニングデータが必要です。しかし、あらゆる弱点に対してハイパースケールのデータセットをキュレーションすることは高コストで非現実的です。
それでも、インドのMirrorVerseプロジェクトのようなソリューションが登場し、拡散モデルでの反射精度を向上させるための強化されたデータセットとトレーニング方法を提供します。

右端は、MirrorVerseの結果と2つの以前のアプローチ(中央列)との比較。 出典: https://arxiv.org/pdf/2504.15397
上記のように、MirrorVerseは最近の取り組みを改善していますが、完全ではありません。
右上の画像では、セラミックジャーがわずかに位置ずれし、下の画像では、自然な反射角度に反して誤ったカップの反射が現れます。
この手法を決定的な解決策としてではなく、拡散モデルが静的およびビデオ形式で直面する持続的な課題を強調するために検討します。反射データはしばしば特定のシナリオに結びついています。
したがって、LDMは反射精度においてNeRF、Gaussian Splatting、従来のCGIに遅れをとる可能性があります。
論文MirrorVerse: Pushing Diffusion Models to Realistically Reflect the Worldは、Vision and AI Lab(IISc Bangalore)およびSamsung R&D Institute(Bangalore)の研究者によるもので、プロジェクトページ、Hugging Faceデータセット、GitHubコードが含まれます。
方法論
研究者は、Stable DiffusionやFluxのようなモデルが反射ベースのプロンプトで困難を抱えていることを強調しています。以下に示します:

論文より:トップテキストから画像へのモデル、SD3.5とFluxは、一貫性のある幾何学的に正確な反射の生成に苦労しています。
チームは、鏡面反射のフォトリアリズムと幾何学的精度を向上させるための拡散ベースのモデル、MirrorFusion 2.0を開発しました。これは、一般化の問題に対処するために設計されたMirrorGen2データセットでトレーニングされました。
MirrorGen2は、ランダムなオブジェクト配置、ランダム化された回転、および明示的なオブジェクト接地を導入し、多様なオブジェクト配置での妥当な反射を保証します。
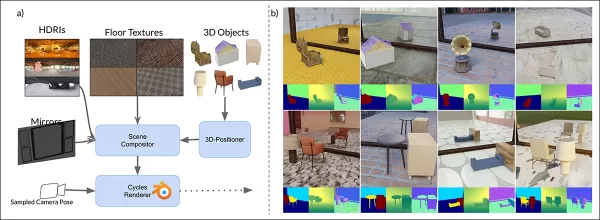
MirrorVerseの合成データスキーマ:3D-Positionerを使用したランダムな配置、回転、接地、ペアリングされたオブジェクトによる現実的な空間相互作用。
MirrorGen2は、反射設定でのオクルージョンや複雑な空間配置をより良く処理するために、ペアリングされたオブジェクトシーンを含みます。
論文は次のように述べています:
「カテゴリは、椅子とテーブルなどの意味的整合性のためにペアリングされます。主要なオブジェクトを配置した後、重なり合わないように二次オブジェクトを追加し、明確な空間領域を確保します。」
オブジェクト接地については、著者らは合成データで不自然な「浮遊」を避けるためにオブジェクトが地面に固定されていることを確認しました。
データセットの革新が論文の新規性を牽引しているため、次にこれを詳しく説明します。
データとテスト
SynMirrorV2
SynMirrorV2データセットは、反射トレーニングデータの多様性を強化し、ObjaverseおよびAmazon Berkeley Objects(ABO)の3Dオブジェクトを使用し、OBJECT 3DITおよびV1 MirrorFusionフィルタリングを通じて改良され、66,062の高品質オブジェクトを生成しました。

キュレーションされたデータセットに使用されたObjaverseデータセットの例。 出典: https://arxiv.org/pdf/2212.08051
シーンは、CC-Texturesのテクスチャ付き床とPolyHavenのHDRI背景を使用して構築され、フルウォールまたは長方形の鏡を使用しました。照明は45度の角度でエリアライトを使用しました。オブジェクトはスケーリングされ、ミラーカメラの視錐台交差によって配置され、y軸上でランダムに回転し、浮遊アーティファクトを避けるために接地されました。
複数オブジェクトのシーンは、ABOから3,140の意味的に一貫したペアリングを使用し、重なりを避けて多様なオクルージョンと奥行きを捉えました。

複数のオブジェクトを含むデータセットからのレンダリングビュー、セグメンテーションと深度マップを示す。
トレーニングプロセス
3段階のカリキュラム学習プロセスでMirrorFusion 2.0をトレーニングし、現実世界での堅牢な一般化を実現しました。
ステージ1では、Stable Diffusion v1.5から重みを初期化し、SynMirrorV2の単一オブジェクト分割で40,000イテレーションのファインチューニングを行い、条件付けと生成ブランチの両方をアクティブに保ちました。
ステージ2では、SynMirrorV2の複数オブジェクト分割で10,000イテレーションのファインチューニングを行い、オクルージョンや複雑なシーンを処理しました。
ステージ3では、Matterport3D深度マップを使用した実世界のMSDデータセットデータで10,000イテレーションを追加しました。

MSDデータセットの例、深度およびセグメンテーションマップ付き。 出典: https://arxiv.org/pdf/1908.09101
テキストプロンプトは20%の確率で省略され、深度情報が優先されました。トレーニングは、4つのNVIDIA A100 GPU、1e-5の学習率、GPUごとのバッチサイズ4、AdamWオプティマイザを使用しました。
この段階的なトレーニングは、単純な合成シーンから複雑な実世界のシーンに移行し、転送可能性を向上させました。
テスト
MirrorFusion 2.0は、MirrorBenchV2でベースラインMirrorFusionに対してテストされ、単一および複数オブジェクトのシーンをカバーし、MSDおよびGoogle Scanned Objects(GSO)データセットで定性的テストを行いました。
評価は、2,991の単一オブジェクトシーンと300の2オブジェクトシーンを使用し、反射品質のためにPSNR、SSIM、LPIPSを測定し、プロンプト整合性のためにCLIPを使用しました。画像は4つのシードで生成され、最も高いSSIMスコアを選択しました。

左:MirrorBenchV2での単一オブジェクト反射品質、MirrorFusion 2.0がベースラインを上回る。右:複数オブジェクト反射品質、複数オブジェクトトレーニングが結果を改善。
著者は次のように述べています:
「我々の手法はベースラインを上回り、複数オブジェクトのファインチューニングは複雑なシーンの結果を向上させます。」
定性的テストはMirrorFusion 2.0の改善を強調しました:

MirrorBenchV2比較:ベースラインは椅子の向きの誤りと歪んだ反射を示す;MirrorFusion 2.0は正確にレンダリング。
GSOデータセットの結果:

GSO比較:ベースラインはオブジェクト構造を歪め;MirrorFusion 2.0は幾何学、色、詳細を保持。
著者はコメントします:
「MirrorFusion 2.0は引き出しのハンドルなどの詳細を正確に反映し、ベースラインは非現実的な結果を生成します。」
実世界のMSDデータセットの結果:

MSD結果:MSDでファインチューニングされたMirrorFusion 2.0は、雑然としたオブジェクトや複数の鏡を正確に捉える。
MSDでのファインチューニングは、MirrorFusion 2.0の複雑な実世界のシーンの処理を改善し、反射の一貫性を向上させました。
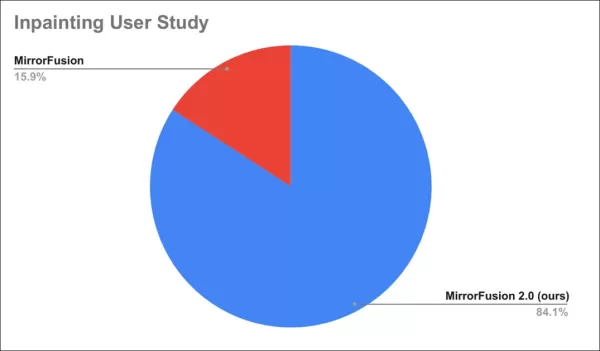
ユーザー調査では、84%がMirrorFusion 2.0の出力を好みました。
ユーザー調査の結果。
結論
MirrorFusion 2.0は進歩を遂げていますが、拡散モデルでの反射精度のベースラインは依然として低く、わずかな改善でも注目に値します。拡散モデルのアーキテクチャは一貫した物理法則に苦労しており、ここで行われたようにデータを追加することは標準的だが限定的な修正です。
より優れた反射データ分布を持つ将来のデータセットは結果を改善する可能性がありますが、これは多くのLDMの弱点に適用されます。どの問題を優先的に対処するかは引き続き課題です。
2025年4月28日(月)に初公開
関連記事
 Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
Googleが「Gemini Notebooks」を発表、NotebookLMとパーソナルナレッジベースを統合
Googleは先日、Gemini向けに「Notebooks」機能をリリースしました。これは、ユーザーがパーソナライズされたナレッジベースを作成することで、複雑なプロジェクトを管理しやすくすることを目的としています。このアップデートは、GeminiとAIリサーチアシスタント「NotebookLM」との間のデータギャップを埋めるものであり、Googleが閉ループAIワークフローの構築を目指す取り組みに
関連特集おすすめ
生産性
Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
Googleが「Gemini Notebooks」を発表、NotebookLMとパーソナルナレッジベースを統合
Googleは先日、Gemini向けに「Notebooks」機能をリリースしました。これは、ユーザーがパーソナライズされたナレッジベースを作成することで、複雑なプロジェクトを管理しやすくすることを目的としています。このアップデートは、GeminiとAIリサーチアシスタント「NotebookLM」との間のデータギャップを埋めるものであり、Googleが閉ループAIワークフローの構築を目指す取り組みに
関連特集おすすめ
生産性
 AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
 10 ツール
10 ツール
 xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai
コード
自動化ユニットテストに最適なAIツール:ワンクリックでJest、PyTest、JUnitのテストケースを生成する
2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai
データ分析
最高のAIデータ可視化ツール:生データからインタラクティブなBIダッシュボードを自動生成
XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai

 コメント (4)
0/500
コメント (4)
0/500
![GaryWalker]()
鏡の反射をリアルに描画するAIの進歩ってすごいですね!でも、これが深フェイクに悪用されたらどうなるんだろう…ちょっと怖いかも😅 反射の物理法則を理解するって、AIが現実世界を「見る」能力が向上している証拠でしょうか?
![JimmyWilson]()
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
![FredGreen]()
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
![RogerNelson]()
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯
生成AIが広く注目を集めて以来、コンピュータビジョンの研究者たちは、物理法則を理解し再現するモデルの開発に力を入れており、特に過去5年間は重力や流体力学のシミュレーションといった課題に焦点を当ててきました。
2022年以降、潜在拡散モデル(LDMs)が生成AIをリードする中、物理現象を正確に描写する難しさが注目されています。この問題は、OpenAIのSoraビデオモデルや最近のオープンソースであるHunyuan VideoやWan 2.1のリリースを受けて、さらに注目を集めています。
反射の課題
LDMsの物理法則の理解を改善するための研究は、主に歩行シミュレーションやニュートン運動などの分野に集中しており、これらの不正確さがAI生成ビデオのリアリズムを損なっています。
しかし、LDMの重要な弱点である正確な反射の生成能力の限界を対象とした研究が増えています。
2025年1月の論文『Reflecting Reality: Enabling Diffusion Models to Produce Faithful Mirror Reflections』より、『反射の失敗』の例と研究者自身の手法の比較。 出典: https://arxiv.org/pdf/2409.14677
この課題は、CGIやビデオゲームでも一般的で、レイトレーシングアルゴリズムを使用して光と表面の相互作用をシミュレートし、リアルな反射、屈折、影を生成します。
しかし、光線の一回の追加バウンスごとに計算負荷が大幅に増加し、リアルタイムアプリケーションではレイテンシーと精度のバランスを取るためにバウンス数を制限する必要があります。
3Dベース(CGI)のシナリオでの仮想光線ビーム。1960年代の技術を使用し、『Tron』(1982年)と『Jurassic Park』(1993年)の間で改良されました。 出典: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
たとえば、鏡の前のクロムティーポットをレンダリングする場合、光線が繰り返しバウンスし、視覚的メリットがほとんどないほぼ無限のループが生じます。通常、2~3回のバウンスで知覚可能な反射が得られ、1回だけのバウンスでは暗い鏡になります。
追加のバウンスごとにレンダリング時間が2倍になるため、効率的な反射処理はレイトレーシングビジュアルの改善に不可欠です。
反射は、濡れた都市の通り、店舗の窓の反射、キャラクターのメガネなど、より微妙なケースでのフォトリアリズムに不可欠であり、オブジェクトや環境が正確に映る必要があります。
『The Matrix』(1999年)のシーンで従来のコンポジティングによって作成された双子反射。
ビジュアルの課題
拡散モデルの前には、Neural Radiance Fields(NeRF)やGaussian Splattingのような新しいアプローチが反射を自然に描写するのに苦労していました。
REF2-NeRFプロジェクトは、ガラスケースのあるシーン向けにNeRFベースの手法を提案し、視聴者の視点に基づいて屈折と反射をモデル化しました。これにより、ガラス表面の推定と直接光および反射光の分離が可能になりました。
Ref2Nerf論文の例。 出典: https://arxiv.org/pdf/2311.17116
他の反射に焦点を当てたNeRFソリューションには、NeRFReN、Reflecting Reality、Metaの2024年のPlanar Reflection-Aware Neural Radiance Fieldsプロジェクトが含まれます。
Gaussian Splattingでは、Mirror-3DGS、Reflective Gaussian Splatting、RefGaussianが反射の問題に取り組み、2023年のNeroプロジェクトはニューラル表現のための独自の手法を導入しました。
MirrorVerseのブレークスルー
拡散モデルに反射ロジックを教えることは、Gaussian SplattingやNeRFのような構造的手法よりも難しいです。拡散モデルでの信頼性の高い反射は、多様なシナリオにわたる高品質なトレーニングデータに依存します。
従来、このような動作の追加にはLoRAやファインチューニングが含まれますが、これらは出力を歪めたり、元のモデルと互換性のないモデル固有のツールを作成したりします。
拡散モデルの改善には、反射物理を強調したトレーニングデータが必要です。しかし、あらゆる弱点に対してハイパースケールのデータセットをキュレーションすることは高コストで非現実的です。
それでも、インドのMirrorVerseプロジェクトのようなソリューションが登場し、拡散モデルでの反射精度を向上させるための強化されたデータセットとトレーニング方法を提供します。
右端は、MirrorVerseの結果と2つの以前のアプローチ(中央列)との比較。 出典: https://arxiv.org/pdf/2504.15397
上記のように、MirrorVerseは最近の取り組みを改善していますが、完全ではありません。
右上の画像では、セラミックジャーがわずかに位置ずれし、下の画像では、自然な反射角度に反して誤ったカップの反射が現れます。
この手法を決定的な解決策としてではなく、拡散モデルが静的およびビデオ形式で直面する持続的な課題を強調するために検討します。反射データはしばしば特定のシナリオに結びついています。
したがって、LDMは反射精度においてNeRF、Gaussian Splatting、従来のCGIに遅れをとる可能性があります。
論文MirrorVerse: Pushing Diffusion Models to Realistically Reflect the Worldは、Vision and AI Lab(IISc Bangalore)およびSamsung R&D Institute(Bangalore)の研究者によるもので、プロジェクトページ、Hugging Faceデータセット、GitHubコードが含まれます。
方法論
研究者は、Stable DiffusionやFluxのようなモデルが反射ベースのプロンプトで困難を抱えていることを強調しています。以下に示します:
論文より:トップテキストから画像へのモデル、SD3.5とFluxは、一貫性のある幾何学的に正確な反射の生成に苦労しています。
チームは、鏡面反射のフォトリアリズムと幾何学的精度を向上させるための拡散ベースのモデル、MirrorFusion 2.0を開発しました。これは、一般化の問題に対処するために設計されたMirrorGen2データセットでトレーニングされました。
MirrorGen2は、ランダムなオブジェクト配置、ランダム化された回転、および明示的なオブジェクト接地を導入し、多様なオブジェクト配置での妥当な反射を保証します。
MirrorVerseの合成データスキーマ:3D-Positionerを使用したランダムな配置、回転、接地、ペアリングされたオブジェクトによる現実的な空間相互作用。
MirrorGen2は、反射設定でのオクルージョンや複雑な空間配置をより良く処理するために、ペアリングされたオブジェクトシーンを含みます。
論文は次のように述べています:
「カテゴリは、椅子とテーブルなどの意味的整合性のためにペアリングされます。主要なオブジェクトを配置した後、重なり合わないように二次オブジェクトを追加し、明確な空間領域を確保します。」
オブジェクト接地については、著者らは合成データで不自然な「浮遊」を避けるためにオブジェクトが地面に固定されていることを確認しました。
データセットの革新が論文の新規性を牽引しているため、次にこれを詳しく説明します。
データとテスト
SynMirrorV2
SynMirrorV2データセットは、反射トレーニングデータの多様性を強化し、ObjaverseおよびAmazon Berkeley Objects(ABO)の3Dオブジェクトを使用し、OBJECT 3DITおよびV1 MirrorFusionフィルタリングを通じて改良され、66,062の高品質オブジェクトを生成しました。
キュレーションされたデータセットに使用されたObjaverseデータセットの例。 出典: https://arxiv.org/pdf/2212.08051
シーンは、CC-Texturesのテクスチャ付き床とPolyHavenのHDRI背景を使用して構築され、フルウォールまたは長方形の鏡を使用しました。照明は45度の角度でエリアライトを使用しました。オブジェクトはスケーリングされ、ミラーカメラの視錐台交差によって配置され、y軸上でランダムに回転し、浮遊アーティファクトを避けるために接地されました。
複数オブジェクトのシーンは、ABOから3,140の意味的に一貫したペアリングを使用し、重なりを避けて多様なオクルージョンと奥行きを捉えました。
複数のオブジェクトを含むデータセットからのレンダリングビュー、セグメンテーションと深度マップを示す。
トレーニングプロセス
3段階のカリキュラム学習プロセスでMirrorFusion 2.0をトレーニングし、現実世界での堅牢な一般化を実現しました。
ステージ1では、Stable Diffusion v1.5から重みを初期化し、SynMirrorV2の単一オブジェクト分割で40,000イテレーションのファインチューニングを行い、条件付けと生成ブランチの両方をアクティブに保ちました。
ステージ2では、SynMirrorV2の複数オブジェクト分割で10,000イテレーションのファインチューニングを行い、オクルージョンや複雑なシーンを処理しました。
ステージ3では、Matterport3D深度マップを使用した実世界のMSDデータセットデータで10,000イテレーションを追加しました。
MSDデータセットの例、深度およびセグメンテーションマップ付き。 出典: https://arxiv.org/pdf/1908.09101
テキストプロンプトは20%の確率で省略され、深度情報が優先されました。トレーニングは、4つのNVIDIA A100 GPU、1e-5の学習率、GPUごとのバッチサイズ4、AdamWオプティマイザを使用しました。
この段階的なトレーニングは、単純な合成シーンから複雑な実世界のシーンに移行し、転送可能性を向上させました。
テスト
MirrorFusion 2.0は、MirrorBenchV2でベースラインMirrorFusionに対してテストされ、単一および複数オブジェクトのシーンをカバーし、MSDおよびGoogle Scanned Objects(GSO)データセットで定性的テストを行いました。
評価は、2,991の単一オブジェクトシーンと300の2オブジェクトシーンを使用し、反射品質のためにPSNR、SSIM、LPIPSを測定し、プロンプト整合性のためにCLIPを使用しました。画像は4つのシードで生成され、最も高いSSIMスコアを選択しました。
左:MirrorBenchV2での単一オブジェクト反射品質、MirrorFusion 2.0がベースラインを上回る。右:複数オブジェクト反射品質、複数オブジェクトトレーニングが結果を改善。
著者は次のように述べています:
「我々の手法はベースラインを上回り、複数オブジェクトのファインチューニングは複雑なシーンの結果を向上させます。」
定性的テストはMirrorFusion 2.0の改善を強調しました:
MirrorBenchV2比較:ベースラインは椅子の向きの誤りと歪んだ反射を示す;MirrorFusion 2.0は正確にレンダリング。
GSOデータセットの結果:
GSO比較:ベースラインはオブジェクト構造を歪め;MirrorFusion 2.0は幾何学、色、詳細を保持。
著者はコメントします:
「MirrorFusion 2.0は引き出しのハンドルなどの詳細を正確に反映し、ベースラインは非現実的な結果を生成します。」
実世界のMSDデータセットの結果:
MSD結果:MSDでファインチューニングされたMirrorFusion 2.0は、雑然としたオブジェクトや複数の鏡を正確に捉える。
MSDでのファインチューニングは、MirrorFusion 2.0の複雑な実世界のシーンの処理を改善し、反射の一貫性を向上させました。
ユーザー調査では、84%がMirrorFusion 2.0の出力を好みました。
ユーザー調査の結果。
結論
MirrorFusion 2.0は進歩を遂げていますが、拡散モデルでの反射精度のベースラインは依然として低く、わずかな改善でも注目に値します。拡散モデルのアーキテクチャは一貫した物理法則に苦労しており、ここで行われたようにデータを追加することは標準的だが限定的な修正です。
より優れた反射データ分布を持つ将来のデータセットは結果を改善する可能性がありますが、これは多くのLDMの弱点に適用されます。どの問題を優先的に対処するかは引き続き課題です。
2025年4月28日(月)に初公開










 Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
Meta AIがFacebookマーケットプレイスでの購入者からのメッセージに対応するようになりました
Facebookは木曜日、Facebook Marketplaceに、購入者からの問い合わせへの自動返信を含む新たなMeta AI機能を導入すると発表した。同プラットフォームでは、AIを活用して出品手続きの迅速化や出品者プロフィールの要約を行うほか、出品者が商品ページで配送オプションを提供できるようになった。出品者は購入者からの問い合わせを頻繁に受けるため、FacebookはMeta AIを活用し
 OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
 Googleが「Gemini Notebooks」を発表、NotebookLMとパーソナルナレッジベースを統合
Googleは先日、Gemini向けに「Notebooks」機能をリリースしました。これは、ユーザーがパーソナライズされたナレッジベースを作成することで、複雑なプロジェクトを管理しやすくすることを目的としています。このアップデートは、GeminiとAIリサーチアシスタント「NotebookLM」との間のデータギャップを埋めるものであり、Googleが閉ループAIワークフローの構築を目指す取り組みに
Googleが「Gemini Notebooks」を発表、NotebookLMとパーソナルナレッジベースを統合
Googleは先日、Gemini向けに「Notebooks」機能をリリースしました。これは、ユーザーがパーソナライズされたナレッジベースを作成することで、複雑なプロジェクトを管理しやすくすることを目的としています。このアップデートは、GeminiとAIリサーチアシスタント「NotebookLM」との間のデータギャップを埋めるものであり、Googleが閉ループAIワークフローの構築を目指す取り組みに

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai

鏡の反射をリアルに描画するAIの進歩ってすごいですね!でも、これが深フェイクに悪用されたらどうなるんだろう…ちょっと怖いかも😅 反射の物理法則を理解するって、AIが現実世界を「見る」能力が向上している証拠でしょうか?
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯













