




AI की यथार्थवादी दर्पण प्रतिबिंब रेंडर करने की क्षमता को बढ़ाना
जब से जनरेटिव AI ने व्यापक ध्यान आकर्षित किया, कंप्यूटर विजन शोधकर्ताओं ने भौतिक नियमों को समझने और दोहराने वाले मॉडल विकसित करने के प्रयास तेज किए, विशेष रूप से पिछले पांच वर्षों में गुरुत्वाकर्षण और द्रव गतिकी जैसी चुनौतियों पर ध्यान केंद्रित किया।
2022 से जनरेटिव AI में लेटेंट डिफ्यूजन मॉडल्स (LDMs) के नेतृत्व के साथ, भौतिक घटनाओं को सटीक रूप से चित्रित करने में उनकी कठिनाइयों पर ध्यान केंद्रित हुआ। यह मुद्दा OpenAI के Sora वीडियो मॉडल और हाल के ओपन-सोर्स रिलीज़ जैसे Hunyuan Video और Wan 2.1 के बाद चर्चा में आया।
प्रतिबिंबों के साथ संघर्ष
LDMs की भौतिकी समझ को बेहतर करने के लिए शोध मुख्य रूप से गति सिमुलेशन और न्यूटोनियन गति जैसे क्षेत्रों पर केंद्रित रहा, क्योंकि यहां गलतियां AI-जनरेटेड वीडियो की यथार्थवादिता को कम करती हैं।
फिर भी, एक बढ़ता हुआ शोध क्षेत्र LDM की एक प्रमुख कमजोरी को लक्षित करता है: सटीक प्रतिबिंब उत्पन्न करने की उनकी सीमित क्षमता।

जनवरी 2025 के पेपर ‘Reflecting Reality: Enabling Diffusion Models to Produce Faithful Mirror Reflections’ से, ‘प्रतिबिंब विफलता’ बनाम शोधकर्ताओं का दृष्टिकोण। स्रोत: https://arxiv.org/pdf/2409.14677
यह चुनौती, जो CGI और वीडियो गेमिंग में भी प्रचलित है, रे-ट्रेसिंग एल्गोरिदम पर निर्भर करती है जो प्रकाश की सतहों के साथ अंतःक्रिया को सिमुलेट करता है, यथार्थवादी प्रतिबिंब, अपवर्तन और छायाएं उत्पन्न करता है।
हालांकि, प्रत्येक अतिरिक्त प्रकाश-रे उछाल काफी हद तक कम्प्यूटेशनल मांगों को बढ़ाता है, जिससे रीयल-टाइम अनुप्रयोगों को विलंबता और सटीकता के बीच संतुलन बनाने के लिए उछालों की संख्या को सीमित करना पड़ता है।
![पारंपरिक 3D-आधारित (अर्थात्, CGI) परिदृश्य में वस्तुतः गणना की गई प्रकाश-किरण का प्रतिनिधित्व, जो 1960 के दशक में विकसित तकनीकों और सिद्धांतों का उपयोग करता है, और जो 1982-93 (Tron [1982] और Jurassic Park [1993] के बीच का समय) के बीच फलीभूत हुआ। स्रोत: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing](https://img.xix.ai/uploads/55/680fa78ce2769.webp)
3D-आधारित (CGI) परिदृश्य में एक आभासी प्रकाश-किरण, 1960 के दशक की तकनीकों का उपयोग, जो ‘Tron’ (1982) और ‘Jurassic Park’ (1993) के बीच परिष्कृत हुई। स्रोत: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
उदाहरण के लिए, दर्पण के सामने क्रोम चायदान को रेंडर करने में प्रकाश किरणों का बार-बार उछाल शामिल होता है, जो न्यूनतम दृश्य लाभ के साथ लगभग अनंत लूप बनाता है। आमतौर पर, दो से तीन उछाल पर्याप्त प्रतिबिंब के लिए पर्याप्त होते हैं, क्योंकि एकल उछाल एक गहरा दर्पण देता है।
प्रत्येक अतिरिक्त उछाल रेंडरिंग समय को दोगुना करता है, जिससे रे-ट्रेस्ड दृश्यों को बेहतर बनाने के लिए कुशल प्रतिबिंब प्रबंधन महत्वपूर्ण हो जाता है।
प्रतिबिंब फोटोरियलिज्म के लिए महत्वपूर्ण हैं, जैसे गीली शहर की सड़कों, दुकान की खिड़कियों के प्रतिबिंब, या पात्रों के चश्मे में, जहां वस्तुओं और वातावरण को सटीक रूप से दिखना चाहिए।

‘The Matrix’ (1999) में एक दृश्य के लिए पारंपरिक कम्पोजिटिंग के माध्यम से बनाया गया दोहरा प्रतिबिंब।
दृश्यों में चुनौतियां
डिफ्यूजन मॉडल्स से पहले, Neural Radiance Fields (NeRF) और Gaussian Splatting जैसे नए दृष्टिकोणों को स्वाभाविक रूप से प्रतिबिंब चित्रित करने में कठिनाई हुई।
REF2-NeRF परियोजना ने कांच के मामलों वाले दृश्यों के लिए एक NeRF-आधारित विधि प्रस्तावित की, जो दर्शक के दृष्टिकोण के आधार पर अपवर्तन और प्रतिबिंब को मॉडल करती है। इससे कांच की सतहों का अनुमान और प्रत्यक्ष और परावर्तित प्रकाश का पृथक्करण संभव हुआ।

Ref2Nerf पेपर से उदाहरण। स्रोत: https://arxiv.org/pdf/2311.17116
अन्य प्रतिबिंब-केंद्रित NeRF समाधानों में NeRFReN, Reflecting Reality, और Meta का 2024 Planar Reflection-Aware Neural Radiance Fields परियोजना शामिल हैं।
Gaussian Splatting के लिए, Mirror-3DGS, Reflective Gaussian Splatting, और RefGaussian जैसे प्रयासों ने प्रतिबिंब मुद्दों को संबोधित किया, जबकि 2023 Nero परियोजना ने न्यूरल प्रतिनिधित्व के लिए एक अनूठी विधि प्रस्तुत की।
MirrorVerse Breakthrough
डिफ्यूजन मॉडल्स को प्रतिबिंब तर्क संभालना सिखाना Gaussian Splatting या NeRF जैसे संरचनात्मक तरीकों की तुलना में कठिन है। डिफ्यूजन मॉडल्स में विश्वसनीय प्रतिबिंब विविध, उच्च-गुणवत्ता वाले प्रशिक्षण डेटा पर निर्भर करता है।
परंपरागत रूप से, ऐसे व्यवहारों को जोड़ने में LoRA या फाइन-ट्यूनिंग शामिल होती है, लेकिन ये आउटपुट को तिरछा करते हैं या मूल मॉडल के साथ असंगत मॉडल-विशिष्ट उपकरण बनाते हैं।
डिफ्यूजन मॉडल्स को बेहतर बनाने के लिए प्रतिबिंब भौतिकी पर जोर देने वाले प्रशिक्षण डेटा की मांग होती है। हालांकि, प्रत्येक कमजोरी के लिए हाइपरस्केल डेटासेट तैयार करना महंगा और अव्यवहारिक है।
फिर भी, समाधान उभरते हैं, जैसे भारत की MirrorVerse परियोजना, जो डिफ्यूजन मॉडल्स में प्रतिबिंब सटीकता को आगे बढ़ाने के लिए एक उन्नत डेटासेट और प्रशिक्षण विधि प्रदान करती है।

सबसे दाएं, MirrorVerse के परिणाम दो पिछले दृष्टिकोणों (मध्य कॉलम) की तुलना में। स्रोत: https://arxiv.org/pdf/2504.15397
जैसा कि ऊपर दिखाया गया है, MirrorVerse हाल के प्रयासों में सुधार करता है लेकिन यह दोषरहित नहीं है।
ऊपरी दाएं छवि में, सिरेमिक जार थोड़े गलत संरेखित हैं, और निचली छवि में, प्राकृतिक परावर्तक कोणों के खिलाफ एक गलत कप प्रतिबिंब दिखाई देता है।
हम इस विधि को निश्चित समाधान के रूप में नहीं, बल्कि डिफ्यूजन मॉडल्स की स्थिर और वीडियो प्रारूपों में सामने आने वाली निरंतर चुनौतियों को उजागर करने के लिए खोजेंगे, जहां प्रतिबिंब डेटा अक्सर विशिष्ट परिदृश्यों से जुड़ा होता है।
इस प्रकार, LDMs प्रतिबिंब सटीकता में NeRF, Gaussian Splatting, और पारंपरिक CGI से पीछे रह सकते हैं।
पेपर, MirrorVerse: Pushing Diffusion Models to Realistically Reflect the World, Vision and AI Lab, IISc Bangalore, और Samsung R&D Institute, Bangalore के शोधकर्ताओं से आता है, जिसमें एक प्रोजेक्ट पेज, Hugging Face डेटासेट, और GitHub कोड शामिल है।
प्रक्रिया
शोधकर्ताओं ने Stable Diffusion और Flux जैसे मॉडल्स की प्रतिबिंब-आधारित संकेतों के साथ कठिनाई को उजागर किया, जैसा कि नीचे दिखाया गया है:

पेपर से: शीर्ष टेक्स्ट-टू-इमेज मॉडल्स, SD3.5 और Flux, सुसंगत, ज्यामितीय रूप से सटीक प्रतिबिंबों के साथ संघर्ष करते हैं।
टीम ने दर्पण प्रतिबिंबों की फोटोरियलिज्म और ज्यामितीय सटीकता को बढ़ाने के लिए एक डिफ्यूजन-आधारित मॉडल MirrorFusion 2.0 विकसित किया। इसे उनके MirrorGen2 डेटासेट पर प्रशिक्षित किया गया, जिसे सामान्यीकरण मुद्दों को संबोधित करने के लिए डिज़ाइन किया गया था।
MirrorGen2 यादृच्छिक वस्तु स्थिति, यादृच्छिक घूर्णन, और स्पष्ट वस्तु ग्राउंडिंग को प्रस्तुत करता है ताकि विविध वस्तु स्थानों में विश्वसनीय प्रतिबिंब सुनिश्चित हो।
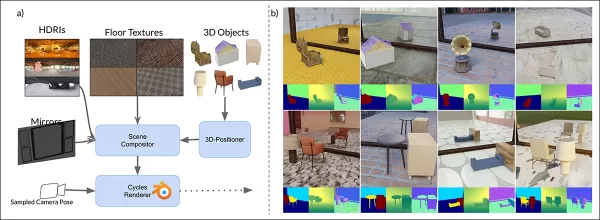
MirrorVerse का सिंथेटिक डेटा स्कीमा: 3D-Positioner के माध्यम से यादृच्छिक स्थिति, घूर्णन, और ग्राउंडिंग, यथार्थवादी स्थानिक अंतःक्रियाओं के लिए जोड़ी गई वस्तुओं के साथ।
MirrorGen2 में अवरोधों और जटिल स्थानिक व्यवस्थाओं को बेहतर ढंग से संभालने के लिए जोड़ी गई वस्तु दृश्य शामिल हैं।
पेपर नोट करता है:
‘श्रेणियां अर्थपूर्ण सुसंगति के लिए जोड़ी जाती हैं, जैसे कुर्सी के साथ मेज। प्राथमिक वस्तु को स्थिति देने के बाद, एक द्वितीयक वस्तु को बिना ओवरलैप के जोड़ा जाता है, जिससे अलग-अलग स्थानिक क्षेत्र सुनिश्चित होते हैं।’
वस्तु ग्राउंडिंग के लिए, लेखकों ने सुनिश्चित किया कि वस्तुएं जमीन पर टिकी हों, सिंथेटिक डेटा में अप्राकृतिक ‘तैरने’ से बचते हुए।
चूंकि डेटासेट नवाचार पेपर की नवीनता को संचालित करता है, हम इसे अगले कवर करेंगे।
डेटा और परीक्षण
SynMirrorV2
SynMirrorV2 डेटासेट प्रतिबिंब प्रशिक्षण डेटा विविधता को बढ़ाता है, Objaverse और Amazon Berkeley Objects (ABO) से 3D वस्तुओं का उपयोग करता है, OBJECT 3DIT और V1 MirrorFusion फ़िल्टरिंग के माध्यम से परिष्कृत, जिससे 66,062 उच्च-गुणवत्ता वाली वस्तुएं प्राप्त हुईं।

Objaverse डेटासेट उदाहरण क्यूरेटेड डेटासेट के लिए उपयोग किए गए। स्रोत: https://arxiv.org/pdf/2212.08051
दृश्यों को CC-Textures से टेक्सचर्ड फर्श और PolyHaven से HDRI पृष्ठभूमि के साथ बनाया गया, पूर्ण-दीवार या आयताकार दर्पणों का उपयोग करके। प्रकाश 45-डिग्री कोण पर एक क्षेत्र-प्रकाश का उपयोग करता था। वस्तुओं को स्केल किया गया, दर्पण-कैमरा फ्रस्टम प्रतिच्छेदन के माध्यम से स्थिति दी गई, और y-अक्ष पर यादृच्छिक रूप से घुमाया गया, तैरने वाले कलाकृतियों से बचने के लिए ग्राउंडिंग के साथ।
बहु-वस्तु दृश्यों ने ABO से 3,140 अर्थपूर्ण सुसंगत जोड़ियों का उपयोग किया, विविध अवरोधों और गहराई को कैप्चर करने के लिए ओवरलैप से बचते हुए।

डेटासेट से बहु-वस्तु वाले रेंडर किए गए दृश्य, खंडन और गहराई मानचित्र दिखाते हुए।
प्रशिक्षण प्रक्रिया
एक तीन-चरणीय पाठ्यक्रम शिक्षण प्रक्रिया ने वास्तविक-विश्व सामान्यीकरण के लिए MirrorFusion 2.0 को प्रशिक्षित किया।
चरण 1 ने Stable Diffusion v1.5 से वजन शुरू किए, SynMirrorV2 के एकल-वस्तु विभाजन पर 40,000 पुनरावृत्तियों के लिए फाइन-ट्यूनिंग, दोनों कंडीशनिंग और जनरेशन शाखाओं को सक्रिय रखते हुए।
चरण 2 ने अवरोधों और जटिल दृश्यों को संभालने के लिए SynMirrorV2 के बहु-वस्तु विभाजन पर 10,000 पुनरावृत्तियों के लिए फाइन-ट्यूनिंग की।
चरण 3 ने Matterport3D गहराई मानचित्रों का उपयोग करके वास्तविक-विश्व MSD डेटासेट डेटा के साथ 10,000 पुनरावृत्तियां जोड़ीं।

MSD डेटासेट उदाहरण गहराई और खंडन मानचित्रों के साथ। स्रोत: https://arxiv.org/pdf/1908.09101
टेक्स्ट संकेत 20% समय छोड़े गए ताकि गहराई जानकारी को प्राथमिकता दी जा सके। प्रशिक्षण में चार NVIDIA A100 GPUs, 1e-5 शिक्षण दर, प्रति GPU 4 का बैच आकार, और AdamW ऑप्टिमाइज़र का उपयोग किया गया।
यह प्रगतिशील प्रशिक्षण सरल सिंथेटिक से जटिल वास्तविक-विश्व दृश्यों तक स्थानांतरण को बेहतर बनाने के लिए गया।
परीक्षण
MirrorFusion 2.0 का MirrorBenchV2 पर बेसलाइन MirrorFusion के खिलाफ परीक्षण किया गया, जिसमें एकल और बहु-वस्तु दृश्य शामिल थे, MSD और Google Scanned Objects (GSO) डेटासेट्स पर गुणात्मक परीक्षणों के साथ।
मूल्यांकन ने 2,991 एकल-वस्तु और 300 दो-वस्तु दृश्यों का उपयोग किया, प्रतिबिंब गुणवत्ता के लिए PSNR, SSIM, और LPIPS को मापा, और संकेत संरेखण के लिए CLIP। चार सीड्स के साथ छवियां उत्पन्न की गईं, सर्वश्रेष्ठ SSIM स्कोर का चयन किया गया।

बाएं: MirrorBenchV2 पर एकल-वस्तु प्रतिबिंब गुणवत्ता, MirrorFusion 2.0 बेसलाइन से बेहतर। दाएं: बहु-वस्तु प्रतिबिंब गुणवत्ता, बहु-वस्तु प्रशिक्षण परिणामों को बेहतर करता है।
लेखकों ने नोट किया:
‘हमारी विधि बेसलाइन से बेहतर प्रदर्शन करती है, और बहु-वस्तु फाइन-ट्यूनिंग जटिल दृश्य परिणामों को बढ़ाती है।’
गुणात्मक परीक्षणों ने MirrorFusion 2.0 के सुधारों पर जोर दिया:

MirrorBenchV2 तुलना: बेसलाइन गलत कुर्सी अभिविन्यास और विकृत प्रतिबिंब दिखाता है; MirrorFusion 2.0 सटीक रूप से रेंडर करता है।
GSO डेटासेट परिणाम:

GSO तुलना: बेसलाइन वस्तु संरचना को विकृत करता है; MirrorFusion 2.0 ज्यामिति, रंग, और विवरण को संरक्षित करता है।
लेखकों ने टिप्पणी की:
‘MirrorFusion 2.0 दराज के हैंडल जैसे विवरणों को सटीक रूप से प्रतिबिंबित करता है, जबकि बेसलाइन अविश्वसनीय परिणाम उत्पन्न करता है।’
वास्तविक-विश्व MSD डेटासेट परिणाम:

MSD परिणाम: MSD पर फाइन-ट्यून किया गया MirrorFusion 2.0, जटिल दृश्यों को अव्यवस्थित वस्तुओं और एकाधिक दर्पणों के साथ सटीक रूप से कैप्चर करता है।
MSD पर फाइन-ट्यूनिंग ने MirrorFusion 2.0 की जटिल वास्तविक-विश्व दृश्यों को संभालने की क्षमता में सुधार किया, प्रतिबिंब सुसंगति को बढ़ाया।
एक उपयोगकर्ता अध्ययन में 84% ने MirrorFusion 2.0 के आउटपुट को प्राथमिकता दी।
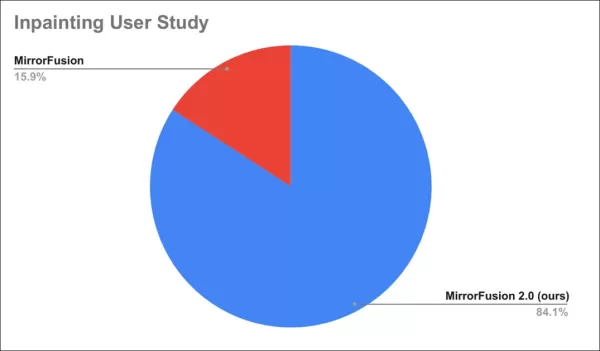
उपयोगकर्ता अध्ययन के परिणाम।
निष्कर्ष
हालांकि MirrorFusion 2.0 प्रगति को चिह्नित करता है, डिफ्यूजन मॉडल्स में प्रतिबिंब सटीकता का आधार कम रहता है, जिससे मामूली सुधार भी उल्लेखनीय हो जाते हैं। डिफ्यूजन मॉडल्स की वास्तुकला सुसंगत भौतिकी के साथ संघर्ष करती है, और यहां किए गए डेटा को जोड़ना एक मानक लेकिन सीमित समाधान है।
बेहतर प्रतिबिंब डेटा वितरण वाले भविष्य के डेटासेट परिणामों में सुधार कर सकते हैं, लेकिन यह कई LDM कमजोरियों पर लागू होता है। किन मुद्दों को प्राथमिकता देना है, यह चुनौती बनी रहती है।
पहली बार सोमवार, 28 अप्रैल, 2025 को प्रकाशित
संबंधित लेख
 AI-चालित ट्रेडिंगव्यू रणनीति बढ़ी हुई सटीकता के लिए
तेजी से बदलते ट्रेडिंग परिदृश्य में, प्रभावी उपकरण महत्वपूर्ण हैं। यह लेख AI संकेतकों का उपयोग करके एक सुव्यवस्थित ट्रेडिंगव्यू रणनीति प्रस्तुत करता है जो ट्रेडिंग सटीकता और लाभप्रदता को बढ़ावा देता ह
AI के साथ अद्वितीय लोगो बनाना: एक चरण-दर-चरण मार्गदर्शिका
व्यवसायों, स्टार्टअप्स और व्यक्तिगत ब्रांडों के लिए एक पेशेवर लोगो डिज़ाइन करना चुनौतीपूर्ण हो सकता है। पारंपरिक तरीकों में अक्सर महंगे डिज़ाइनर या जटिल सॉफ़्टवेयर की आवश्यकता होती है। कृत्रिम बुद्धिम
AI पर निर्भरता से गंभीर सोच कमजोर हो सकती है: MIT अध्ययन में संज्ञानात्मक जोखिमों का खुलासा
एक ऐसे युग में जहां ChatGPT जैसे AI उपकरण उतने ही सामान्य हैं जितना कि स्पेल-चेक, MIT का एक खुलासा करने वाला अध्ययन चेतावनी देता है कि बड़े भाषा मॉडल (LLMs) पर हमारी बढ़ती निर्भरता हमारी गंभीर और गहरी
सूचना (0)
0/200
AI-चालित ट्रेडिंगव्यू रणनीति बढ़ी हुई सटीकता के लिए
तेजी से बदलते ट्रेडिंग परिदृश्य में, प्रभावी उपकरण महत्वपूर्ण हैं। यह लेख AI संकेतकों का उपयोग करके एक सुव्यवस्थित ट्रेडिंगव्यू रणनीति प्रस्तुत करता है जो ट्रेडिंग सटीकता और लाभप्रदता को बढ़ावा देता ह
AI के साथ अद्वितीय लोगो बनाना: एक चरण-दर-चरण मार्गदर्शिका
व्यवसायों, स्टार्टअप्स और व्यक्तिगत ब्रांडों के लिए एक पेशेवर लोगो डिज़ाइन करना चुनौतीपूर्ण हो सकता है। पारंपरिक तरीकों में अक्सर महंगे डिज़ाइनर या जटिल सॉफ़्टवेयर की आवश्यकता होती है। कृत्रिम बुद्धिम
AI पर निर्भरता से गंभीर सोच कमजोर हो सकती है: MIT अध्ययन में संज्ञानात्मक जोखिमों का खुलासा
एक ऐसे युग में जहां ChatGPT जैसे AI उपकरण उतने ही सामान्य हैं जितना कि स्पेल-चेक, MIT का एक खुलासा करने वाला अध्ययन चेतावनी देता है कि बड़े भाषा मॉडल (LLMs) पर हमारी बढ़ती निर्भरता हमारी गंभीर और गहरी
सूचना (0)
0/200
जब से जनरेटिव AI ने व्यापक ध्यान आकर्षित किया, कंप्यूटर विजन शोधकर्ताओं ने भौतिक नियमों को समझने और दोहराने वाले मॉडल विकसित करने के प्रयास तेज किए, विशेष रूप से पिछले पांच वर्षों में गुरुत्वाकर्षण और द्रव गतिकी जैसी चुनौतियों पर ध्यान केंद्रित किया।
2022 से जनरेटिव AI में लेटेंट डिफ्यूजन मॉडल्स (LDMs) के नेतृत्व के साथ, भौतिक घटनाओं को सटीक रूप से चित्रित करने में उनकी कठिनाइयों पर ध्यान केंद्रित हुआ। यह मुद्दा OpenAI के Sora वीडियो मॉडल और हाल के ओपन-सोर्स रिलीज़ जैसे Hunyuan Video और Wan 2.1 के बाद चर्चा में आया।
प्रतिबिंबों के साथ संघर्ष
LDMs की भौतिकी समझ को बेहतर करने के लिए शोध मुख्य रूप से गति सिमुलेशन और न्यूटोनियन गति जैसे क्षेत्रों पर केंद्रित रहा, क्योंकि यहां गलतियां AI-जनरेटेड वीडियो की यथार्थवादिता को कम करती हैं।
फिर भी, एक बढ़ता हुआ शोध क्षेत्र LDM की एक प्रमुख कमजोरी को लक्षित करता है: सटीक प्रतिबिंब उत्पन्न करने की उनकी सीमित क्षमता।
जनवरी 2025 के पेपर ‘Reflecting Reality: Enabling Diffusion Models to Produce Faithful Mirror Reflections’ से, ‘प्रतिबिंब विफलता’ बनाम शोधकर्ताओं का दृष्टिकोण। स्रोत: https://arxiv.org/pdf/2409.14677
यह चुनौती, जो CGI और वीडियो गेमिंग में भी प्रचलित है, रे-ट्रेसिंग एल्गोरिदम पर निर्भर करती है जो प्रकाश की सतहों के साथ अंतःक्रिया को सिमुलेट करता है, यथार्थवादी प्रतिबिंब, अपवर्तन और छायाएं उत्पन्न करता है।
हालांकि, प्रत्येक अतिरिक्त प्रकाश-रे उछाल काफी हद तक कम्प्यूटेशनल मांगों को बढ़ाता है, जिससे रीयल-टाइम अनुप्रयोगों को विलंबता और सटीकता के बीच संतुलन बनाने के लिए उछालों की संख्या को सीमित करना पड़ता है।
3D-आधारित (CGI) परिदृश्य में एक आभासी प्रकाश-किरण, 1960 के दशक की तकनीकों का उपयोग, जो ‘Tron’ (1982) और ‘Jurassic Park’ (1993) के बीच परिष्कृत हुई। स्रोत: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
उदाहरण के लिए, दर्पण के सामने क्रोम चायदान को रेंडर करने में प्रकाश किरणों का बार-बार उछाल शामिल होता है, जो न्यूनतम दृश्य लाभ के साथ लगभग अनंत लूप बनाता है। आमतौर पर, दो से तीन उछाल पर्याप्त प्रतिबिंब के लिए पर्याप्त होते हैं, क्योंकि एकल उछाल एक गहरा दर्पण देता है।
प्रत्येक अतिरिक्त उछाल रेंडरिंग समय को दोगुना करता है, जिससे रे-ट्रेस्ड दृश्यों को बेहतर बनाने के लिए कुशल प्रतिबिंब प्रबंधन महत्वपूर्ण हो जाता है।
प्रतिबिंब फोटोरियलिज्म के लिए महत्वपूर्ण हैं, जैसे गीली शहर की सड़कों, दुकान की खिड़कियों के प्रतिबिंब, या पात्रों के चश्मे में, जहां वस्तुओं और वातावरण को सटीक रूप से दिखना चाहिए।
‘The Matrix’ (1999) में एक दृश्य के लिए पारंपरिक कम्पोजिटिंग के माध्यम से बनाया गया दोहरा प्रतिबिंब।
दृश्यों में चुनौतियां
डिफ्यूजन मॉडल्स से पहले, Neural Radiance Fields (NeRF) और Gaussian Splatting जैसे नए दृष्टिकोणों को स्वाभाविक रूप से प्रतिबिंब चित्रित करने में कठिनाई हुई।
REF2-NeRF परियोजना ने कांच के मामलों वाले दृश्यों के लिए एक NeRF-आधारित विधि प्रस्तावित की, जो दर्शक के दृष्टिकोण के आधार पर अपवर्तन और प्रतिबिंब को मॉडल करती है। इससे कांच की सतहों का अनुमान और प्रत्यक्ष और परावर्तित प्रकाश का पृथक्करण संभव हुआ।
Ref2Nerf पेपर से उदाहरण। स्रोत: https://arxiv.org/pdf/2311.17116
अन्य प्रतिबिंब-केंद्रित NeRF समाधानों में NeRFReN, Reflecting Reality, और Meta का 2024 Planar Reflection-Aware Neural Radiance Fields परियोजना शामिल हैं।
Gaussian Splatting के लिए, Mirror-3DGS, Reflective Gaussian Splatting, और RefGaussian जैसे प्रयासों ने प्रतिबिंब मुद्दों को संबोधित किया, जबकि 2023 Nero परियोजना ने न्यूरल प्रतिनिधित्व के लिए एक अनूठी विधि प्रस्तुत की।
MirrorVerse Breakthrough
डिफ्यूजन मॉडल्स को प्रतिबिंब तर्क संभालना सिखाना Gaussian Splatting या NeRF जैसे संरचनात्मक तरीकों की तुलना में कठिन है। डिफ्यूजन मॉडल्स में विश्वसनीय प्रतिबिंब विविध, उच्च-गुणवत्ता वाले प्रशिक्षण डेटा पर निर्भर करता है।
परंपरागत रूप से, ऐसे व्यवहारों को जोड़ने में LoRA या फाइन-ट्यूनिंग शामिल होती है, लेकिन ये आउटपुट को तिरछा करते हैं या मूल मॉडल के साथ असंगत मॉडल-विशिष्ट उपकरण बनाते हैं।
डिफ्यूजन मॉडल्स को बेहतर बनाने के लिए प्रतिबिंब भौतिकी पर जोर देने वाले प्रशिक्षण डेटा की मांग होती है। हालांकि, प्रत्येक कमजोरी के लिए हाइपरस्केल डेटासेट तैयार करना महंगा और अव्यवहारिक है।
फिर भी, समाधान उभरते हैं, जैसे भारत की MirrorVerse परियोजना, जो डिफ्यूजन मॉडल्स में प्रतिबिंब सटीकता को आगे बढ़ाने के लिए एक उन्नत डेटासेट और प्रशिक्षण विधि प्रदान करती है।
सबसे दाएं, MirrorVerse के परिणाम दो पिछले दृष्टिकोणों (मध्य कॉलम) की तुलना में। स्रोत: https://arxiv.org/pdf/2504.15397
जैसा कि ऊपर दिखाया गया है, MirrorVerse हाल के प्रयासों में सुधार करता है लेकिन यह दोषरहित नहीं है।
ऊपरी दाएं छवि में, सिरेमिक जार थोड़े गलत संरेखित हैं, और निचली छवि में, प्राकृतिक परावर्तक कोणों के खिलाफ एक गलत कप प्रतिबिंब दिखाई देता है।
हम इस विधि को निश्चित समाधान के रूप में नहीं, बल्कि डिफ्यूजन मॉडल्स की स्थिर और वीडियो प्रारूपों में सामने आने वाली निरंतर चुनौतियों को उजागर करने के लिए खोजेंगे, जहां प्रतिबिंब डेटा अक्सर विशिष्ट परिदृश्यों से जुड़ा होता है।
इस प्रकार, LDMs प्रतिबिंब सटीकता में NeRF, Gaussian Splatting, और पारंपरिक CGI से पीछे रह सकते हैं।
पेपर, MirrorVerse: Pushing Diffusion Models to Realistically Reflect the World, Vision and AI Lab, IISc Bangalore, और Samsung R&D Institute, Bangalore के शोधकर्ताओं से आता है, जिसमें एक प्रोजेक्ट पेज, Hugging Face डेटासेट, और GitHub कोड शामिल है।
प्रक्रिया
शोधकर्ताओं ने Stable Diffusion और Flux जैसे मॉडल्स की प्रतिबिंब-आधारित संकेतों के साथ कठिनाई को उजागर किया, जैसा कि नीचे दिखाया गया है:
पेपर से: शीर्ष टेक्स्ट-टू-इमेज मॉडल्स, SD3.5 और Flux, सुसंगत, ज्यामितीय रूप से सटीक प्रतिबिंबों के साथ संघर्ष करते हैं।
टीम ने दर्पण प्रतिबिंबों की फोटोरियलिज्म और ज्यामितीय सटीकता को बढ़ाने के लिए एक डिफ्यूजन-आधारित मॉडल MirrorFusion 2.0 विकसित किया। इसे उनके MirrorGen2 डेटासेट पर प्रशिक्षित किया गया, जिसे सामान्यीकरण मुद्दों को संबोधित करने के लिए डिज़ाइन किया गया था।
MirrorGen2 यादृच्छिक वस्तु स्थिति, यादृच्छिक घूर्णन, और स्पष्ट वस्तु ग्राउंडिंग को प्रस्तुत करता है ताकि विविध वस्तु स्थानों में विश्वसनीय प्रतिबिंब सुनिश्चित हो।
MirrorVerse का सिंथेटिक डेटा स्कीमा: 3D-Positioner के माध्यम से यादृच्छिक स्थिति, घूर्णन, और ग्राउंडिंग, यथार्थवादी स्थानिक अंतःक्रियाओं के लिए जोड़ी गई वस्तुओं के साथ।
MirrorGen2 में अवरोधों और जटिल स्थानिक व्यवस्थाओं को बेहतर ढंग से संभालने के लिए जोड़ी गई वस्तु दृश्य शामिल हैं।
पेपर नोट करता है:
‘श्रेणियां अर्थपूर्ण सुसंगति के लिए जोड़ी जाती हैं, जैसे कुर्सी के साथ मेज। प्राथमिक वस्तु को स्थिति देने के बाद, एक द्वितीयक वस्तु को बिना ओवरलैप के जोड़ा जाता है, जिससे अलग-अलग स्थानिक क्षेत्र सुनिश्चित होते हैं।’
वस्तु ग्राउंडिंग के लिए, लेखकों ने सुनिश्चित किया कि वस्तुएं जमीन पर टिकी हों, सिंथेटिक डेटा में अप्राकृतिक ‘तैरने’ से बचते हुए।
चूंकि डेटासेट नवाचार पेपर की नवीनता को संचालित करता है, हम इसे अगले कवर करेंगे।
डेटा और परीक्षण
SynMirrorV2
SynMirrorV2 डेटासेट प्रतिबिंब प्रशिक्षण डेटा विविधता को बढ़ाता है, Objaverse और Amazon Berkeley Objects (ABO) से 3D वस्तुओं का उपयोग करता है, OBJECT 3DIT और V1 MirrorFusion फ़िल्टरिंग के माध्यम से परिष्कृत, जिससे 66,062 उच्च-गुणवत्ता वाली वस्तुएं प्राप्त हुईं।
Objaverse डेटासेट उदाहरण क्यूरेटेड डेटासेट के लिए उपयोग किए गए। स्रोत: https://arxiv.org/pdf/2212.08051
दृश्यों को CC-Textures से टेक्सचर्ड फर्श और PolyHaven से HDRI पृष्ठभूमि के साथ बनाया गया, पूर्ण-दीवार या आयताकार दर्पणों का उपयोग करके। प्रकाश 45-डिग्री कोण पर एक क्षेत्र-प्रकाश का उपयोग करता था। वस्तुओं को स्केल किया गया, दर्पण-कैमरा फ्रस्टम प्रतिच्छेदन के माध्यम से स्थिति दी गई, और y-अक्ष पर यादृच्छिक रूप से घुमाया गया, तैरने वाले कलाकृतियों से बचने के लिए ग्राउंडिंग के साथ।
बहु-वस्तु दृश्यों ने ABO से 3,140 अर्थपूर्ण सुसंगत जोड़ियों का उपयोग किया, विविध अवरोधों और गहराई को कैप्चर करने के लिए ओवरलैप से बचते हुए।
डेटासेट से बहु-वस्तु वाले रेंडर किए गए दृश्य, खंडन और गहराई मानचित्र दिखाते हुए।
प्रशिक्षण प्रक्रिया
एक तीन-चरणीय पाठ्यक्रम शिक्षण प्रक्रिया ने वास्तविक-विश्व सामान्यीकरण के लिए MirrorFusion 2.0 को प्रशिक्षित किया।
चरण 1 ने Stable Diffusion v1.5 से वजन शुरू किए, SynMirrorV2 के एकल-वस्तु विभाजन पर 40,000 पुनरावृत्तियों के लिए फाइन-ट्यूनिंग, दोनों कंडीशनिंग और जनरेशन शाखाओं को सक्रिय रखते हुए।
चरण 2 ने अवरोधों और जटिल दृश्यों को संभालने के लिए SynMirrorV2 के बहु-वस्तु विभाजन पर 10,000 पुनरावृत्तियों के लिए फाइन-ट्यूनिंग की।
चरण 3 ने Matterport3D गहराई मानचित्रों का उपयोग करके वास्तविक-विश्व MSD डेटासेट डेटा के साथ 10,000 पुनरावृत्तियां जोड़ीं।
MSD डेटासेट उदाहरण गहराई और खंडन मानचित्रों के साथ। स्रोत: https://arxiv.org/pdf/1908.09101
टेक्स्ट संकेत 20% समय छोड़े गए ताकि गहराई जानकारी को प्राथमिकता दी जा सके। प्रशिक्षण में चार NVIDIA A100 GPUs, 1e-5 शिक्षण दर, प्रति GPU 4 का बैच आकार, और AdamW ऑप्टिमाइज़र का उपयोग किया गया।
यह प्रगतिशील प्रशिक्षण सरल सिंथेटिक से जटिल वास्तविक-विश्व दृश्यों तक स्थानांतरण को बेहतर बनाने के लिए गया।
परीक्षण
MirrorFusion 2.0 का MirrorBenchV2 पर बेसलाइन MirrorFusion के खिलाफ परीक्षण किया गया, जिसमें एकल और बहु-वस्तु दृश्य शामिल थे, MSD और Google Scanned Objects (GSO) डेटासेट्स पर गुणात्मक परीक्षणों के साथ।
मूल्यांकन ने 2,991 एकल-वस्तु और 300 दो-वस्तु दृश्यों का उपयोग किया, प्रतिबिंब गुणवत्ता के लिए PSNR, SSIM, और LPIPS को मापा, और संकेत संरेखण के लिए CLIP। चार सीड्स के साथ छवियां उत्पन्न की गईं, सर्वश्रेष्ठ SSIM स्कोर का चयन किया गया।
बाएं: MirrorBenchV2 पर एकल-वस्तु प्रतिबिंब गुणवत्ता, MirrorFusion 2.0 बेसलाइन से बेहतर। दाएं: बहु-वस्तु प्रतिबिंब गुणवत्ता, बहु-वस्तु प्रशिक्षण परिणामों को बेहतर करता है।
लेखकों ने नोट किया:
‘हमारी विधि बेसलाइन से बेहतर प्रदर्शन करती है, और बहु-वस्तु फाइन-ट्यूनिंग जटिल दृश्य परिणामों को बढ़ाती है।’
गुणात्मक परीक्षणों ने MirrorFusion 2.0 के सुधारों पर जोर दिया:
MirrorBenchV2 तुलना: बेसलाइन गलत कुर्सी अभिविन्यास और विकृत प्रतिबिंब दिखाता है; MirrorFusion 2.0 सटीक रूप से रेंडर करता है।
GSO डेटासेट परिणाम:
GSO तुलना: बेसलाइन वस्तु संरचना को विकृत करता है; MirrorFusion 2.0 ज्यामिति, रंग, और विवरण को संरक्षित करता है।
लेखकों ने टिप्पणी की:
‘MirrorFusion 2.0 दराज के हैंडल जैसे विवरणों को सटीक रूप से प्रतिबिंबित करता है, जबकि बेसलाइन अविश्वसनीय परिणाम उत्पन्न करता है।’
वास्तविक-विश्व MSD डेटासेट परिणाम:
MSD परिणाम: MSD पर फाइन-ट्यून किया गया MirrorFusion 2.0, जटिल दृश्यों को अव्यवस्थित वस्तुओं और एकाधिक दर्पणों के साथ सटीक रूप से कैप्चर करता है।
MSD पर फाइन-ट्यूनिंग ने MirrorFusion 2.0 की जटिल वास्तविक-विश्व दृश्यों को संभालने की क्षमता में सुधार किया, प्रतिबिंब सुसंगति को बढ़ाया।
एक उपयोगकर्ता अध्ययन में 84% ने MirrorFusion 2.0 के आउटपुट को प्राथमिकता दी।
उपयोगकर्ता अध्ययन के परिणाम।
निष्कर्ष
हालांकि MirrorFusion 2.0 प्रगति को चिह्नित करता है, डिफ्यूजन मॉडल्स में प्रतिबिंब सटीकता का आधार कम रहता है, जिससे मामूली सुधार भी उल्लेखनीय हो जाते हैं। डिफ्यूजन मॉडल्स की वास्तुकला सुसंगत भौतिकी के साथ संघर्ष करती है, और यहां किए गए डेटा को जोड़ना एक मानक लेकिन सीमित समाधान है।
बेहतर प्रतिबिंब डेटा वितरण वाले भविष्य के डेटासेट परिणामों में सुधार कर सकते हैं, लेकिन यह कई LDM कमजोरियों पर लागू होता है। किन मुद्दों को प्राथमिकता देना है, यह चुनौती बनी रहती है।
पहली बार सोमवार, 28 अप्रैल, 2025 को प्रकाशित










 AI-चालित ट्रेडिंगव्यू रणनीति बढ़ी हुई सटीकता के लिए
तेजी से बदलते ट्रेडिंग परिदृश्य में, प्रभावी उपकरण महत्वपूर्ण हैं। यह लेख AI संकेतकों का उपयोग करके एक सुव्यवस्थित ट्रेडिंगव्यू रणनीति प्रस्तुत करता है जो ट्रेडिंग सटीकता और लाभप्रदता को बढ़ावा देता ह
AI-चालित ट्रेडिंगव्यू रणनीति बढ़ी हुई सटीकता के लिए
तेजी से बदलते ट्रेडिंग परिदृश्य में, प्रभावी उपकरण महत्वपूर्ण हैं। यह लेख AI संकेतकों का उपयोग करके एक सुव्यवस्थित ट्रेडिंगव्यू रणनीति प्रस्तुत करता है जो ट्रेडिंग सटीकता और लाभप्रदता को बढ़ावा देता ह
 AI के साथ अद्वितीय लोगो बनाना: एक चरण-दर-चरण मार्गदर्शिका
व्यवसायों, स्टार्टअप्स और व्यक्तिगत ब्रांडों के लिए एक पेशेवर लोगो डिज़ाइन करना चुनौतीपूर्ण हो सकता है। पारंपरिक तरीकों में अक्सर महंगे डिज़ाइनर या जटिल सॉफ़्टवेयर की आवश्यकता होती है। कृत्रिम बुद्धिम
AI के साथ अद्वितीय लोगो बनाना: एक चरण-दर-चरण मार्गदर्शिका
व्यवसायों, स्टार्टअप्स और व्यक्तिगत ब्रांडों के लिए एक पेशेवर लोगो डिज़ाइन करना चुनौतीपूर्ण हो सकता है। पारंपरिक तरीकों में अक्सर महंगे डिज़ाइनर या जटिल सॉफ़्टवेयर की आवश्यकता होती है। कृत्रिम बुद्धिम
 AI पर निर्भरता से गंभीर सोच कमजोर हो सकती है: MIT अध्ययन में संज्ञानात्मक जोखिमों का खुलासा
एक ऐसे युग में जहां ChatGPT जैसे AI उपकरण उतने ही सामान्य हैं जितना कि स्पेल-चेक, MIT का एक खुलासा करने वाला अध्ययन चेतावनी देता है कि बड़े भाषा मॉडल (LLMs) पर हमारी बढ़ती निर्भरता हमारी गंभीर और गहरी
AI पर निर्भरता से गंभीर सोच कमजोर हो सकती है: MIT अध्ययन में संज्ञानात्मक जोखिमों का खुलासा
एक ऐसे युग में जहां ChatGPT जैसे AI उपकरण उतने ही सामान्य हैं जितना कि स्पेल-चेक, MIT का एक खुलासा करने वाला अध्ययन चेतावनी देता है कि बड़े भाषा मॉडल (LLMs) पर हमारी बढ़ती निर्भरता हमारी गंभीर और गहरी













