
















 Hogar
HogarMejorando la Capacidad de la IA para Renderizar Reflejos Realistas en Espejos
Desde que la IA generativa captó una amplia atención, los investigadores de visión por computadora han intensificado los esfuerzos para desarrollar modelos que comprendan y repliquen las leyes físicas, con un enfoque particular en desafíos como la simulación de la gravedad y la dinámica de fluidos en los últimos cinco años.
Con los modelos de difusión latente (LDMs) liderando la IA generativa desde 2022, la atención se ha centrado en sus dificultades para representar con precisión fenómenos físicos. Este problema ha ganado relevancia tras el modelo de video Sora de OpenAI y los recientes lanzamientos de código abierto de Hunyuan Video y Wan 2.1.
Dificultades con los Reflejos
La investigación para mejorar la comprensión de los LDMs sobre la física se ha centrado principalmente en áreas como la simulación de la marcha y el movimiento newtoniano, ya que las inexactitudes aquí socavan el realismo de los videos generados por IA.
Sin embargo, un creciente cuerpo de trabajo apunta a una debilidad clave de los LDMs: su capacidad limitada para generar reflejos precisos.

Del artículo de enero de 2025 ‘Reflejando la Realidad: Habilitando Modelos de Difusión para Producir Reflejos Fieles en Espejos’, ejemplos de ‘fallo de reflexión’ frente al enfoque de los investigadores. Fuente: https://arxiv.org/pdf/2409.14677
Este desafío, también presente en CGI y videojuegos, depende de algoritmos de trazado de rayos para simular la interacción de la luz con las superficies, produciendo reflejos, refracciones y sombras realistas.
Sin embargo, cada rebote adicional de rayos de luz aumenta significativamente las demandas computacionales, obligando a las aplicaciones en tiempo real a equilibrar la latencia y la precisión limitando el número de rebotes.
![Una representación de un haz de luz calculado virtualmente en un escenario basado en 3D (es decir, CGI), utilizando tecnologías y principios desarrollados por primera vez en la década de 1960, y que fructificaron entre 1982-93 (el período entre Tron [1982] y Jurassic Park [1993]). Fuente: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing](https://img.xix.ai/uploads/55/680fa78ce2769.webp)
Un haz de luz virtual en un escenario basado en 3D (CGI), utilizando técnicas de la década de 1960, refinadas entre ‘Tron’ (1982) y ‘Jurassic Park’ (1993). Fuente: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
Por ejemplo, renderizar una tetera cromada frente a un espejo implica que los rayos de luz reboten repetidamente, creando bucles casi infinitos con un beneficio visual mínimo. Generalmente, dos o tres rebotes son suficientes para reflejos perceptibles, ya que un solo rebote produce un espejo oscuro.
Cada rebote adicional duplica el tiempo de renderizado, haciendo que el manejo eficiente de reflejos sea crítico para mejorar las imágenes trazadas por rayos.
Los reflejos son vitales para el fotorrealismo en casos más sutiles, como calles mojadas, reflejos en escaparates o gafas de personajes, donde los objetos y entornos deben aparecer con precisión.

Un reflejo gemelo creado mediante composición tradicional para una escena en ‘The Matrix’ (1999).
Desafíos en Visuales
Antes de los modelos de difusión, marcos como Neural Radiance Fields (NeRF) y enfoques más recientes como Gaussian Splatting lucharon por representar reflejos de manera natural.
El proyecto REF2-NeRF propuso un método basado en NeRF para escenas con vitrinas, modelando refracción y reflexión según la perspectiva del espectador. Esto permitió estimar superficies de vidrio y separar la luz directa de la reflejada.

Ejemplos del artículo Ref2Nerf. Fuente: https://arxiv.org/pdf/2311.17116
Otras soluciones centradas en reflejos para NeRF incluyen NeRFReN, Reflejando la Realidad y el proyecto de Meta de 2024 Campos de Radiancia Neural Conscientes de Reflejos Planos.
Para Gaussian Splatting, esfuerzos como Mirror-3DGS, Gaussian Splatting Reflexivo y RefGaussian abordaron problemas de reflejos, mientras que el proyecto Nero de 2023 introdujo un método único para representaciones neuronales.
Avance de MirrorVerse
Enseñar a los modelos de difusión a manejar la lógica de los reflejos es más difícil que con métodos estructurales como Gaussian Splatting o NeRF. Un reflejo confiable en modelos de difusión depende de datos de entrenamiento diversos y de alta calidad en diversos escenarios.
Tradicionalmente, añadir tales comportamientos implica LoRA o ajuste fino, pero estos desvían los resultados o crean herramientas específicas del modelo incompatibles con el modelo original.
Mejorar los modelos de difusión requiere datos de entrenamiento que enfatizen la física de los reflejos. Sin embargo, curar conjuntos de datos a hiperescala para cada debilidad es costoso e impráctico.
Aun así, surgen soluciones, como el proyecto MirrorVerse de India, que ofrece un conjunto de datos mejorado y un método de entrenamiento para avanzar en la precisión de los reflejos en modelos de difusión.

A la derecha, resultados de MirrorVerse comparados con dos enfoques anteriores (columnas centrales). Fuente: https://arxiv.org/pdf/2504.15397
Como se muestra arriba, MirrorVerse mejora los esfuerzos recientes, pero no es impecable.
En la imagen superior derecha, los jarros de cerámica están ligeramente desalineados, y en la imagen inferior, aparece un reflejo erróneo de una taza contra los ángulos reflectivos naturales.
Exploraremos este método no como una solución definitiva, sino para destacar los desafíos persistentes que enfrentan los modelos de difusión en formatos estáticos y de video, donde los datos de reflejos suelen estar ligados a escenarios específicos.
Por lo tanto, los LDMs pueden quedarse atrás de NeRF, Gaussian Splatting y CGI tradicional en la precisión de los reflejos.
El artículo, MirrorVerse: Impulsando Modelos de Difusión para Reflejar Realistamente el Mundo, proviene de investigadores del Vision and AI Lab, IISc Bangalore, y Samsung R&D Institute, Bangalore, con una página de proyecto, un conjuntoívne de datos en Hugging Face y código en GitHub.
Metodología
Los investigadores destacan la dificultad que enfrentan modelos como Stable Diffusion y Flux con prompts basados en reflejos, como se muestra a continuación:

Del artículo: Los principales modelos de texto a imagen, SD3.5 y Flux, luchan con reflejos consistentes y geométricamente precisos.
El equipo desarrolló MirrorFusion 2.0, un modelo basado en difusión para mejorar el fotorrealismo y la precisión geométrica de los reflejos en espejos. Fue entrenado en su conjunto de datos MirrorGen2, diseñado para abordar problemas de generalización.
MirrorGen2 introduce posicionamiento aleatorio de objetos, rotaciones aleatorias y anclaje explícito de objetos para garantizar reflejos plausibles en diversas posiciones de objetos.
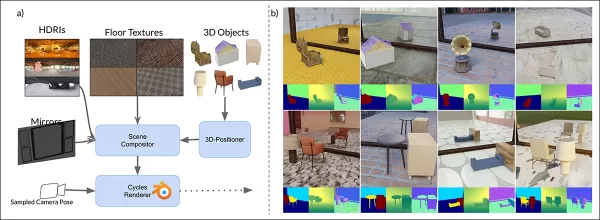
Esquema de datos sintéticos de MirrorVerse: posicionamiento, rotación y anclaje aleatorios mediante 3D-Positioner, con objetos emparejados para interacciones espaciales realistas.
MirrorGen2 incluye escenas de objetos emparejados para manejar mejor oclusiones y disposiciones espaciales complejas en entornos reflectivos.
El artículo señala:
‘Las categorías se emparejan para coherencia semántica, como una silla con una mesa. Tras posicionar el objeto principal, se añade uno secundario sin superposición, asegurando regiones espaciales distintas.’
Para el anclaje de objetos, los autores aseguraron que los objetos estuvieran anclados al suelo, evitando un ‘flotamiento’ no natural en los datos sintéticos.
Dado que la innovación del conjunto de datos impulsa la novedad del artículo, lo cubriremos a continuación.
Datos y Pruebas
SynMirrorV2
El conjunto de datos SynMirrorV2 mejora la diversidad de los datos de entrenamiento de reflejos, utilizando objetos 3D de Objaverse y Amazon Berkeley Objects (ABO), refinados mediante filtrado de OBJECT 3DIT y V1 MirrorFusion, generando 66,062 objetos de alta calidad.

Ejemplos del conjunto de datos Objaverse utilizados para el conjunto de datos curado. Fuente: https://arxiv.org/pdf/2212.08051
Las escenas se construyeron con suelos texturizados de CC-Textures y fondos HDRI de PolyHaven, utilizando espejos de pared completa o rectangulares. La iluminación usó una luz de área a un ángulo de 45 grados. Los objetos se escalaron, posicionaron mediante intersección de frustum de cámara-espejo y rotaron aleatoriamente en el eje y, con anclaje para evitar artefactos de flotación.
Las escenas con múltiples objetos usaron 3,140 emparejamientos semánticamente coherentes de ABO, evitando superposiciones para capturar diversas oclusiones y profundidad.

Vistas renderizadas del conjunto de datos con múltiples objetos, mostrando segmentación y mapas de profundidad.
Proceso de Entrenamiento
Un proceso de aprendizaje curricular de tres etapas entrenó MirrorFusion 2.0 para una generalización robusta en el mundo real.
La Etapa 1 inicializó los pesos desde Stable Diffusion v1.5, ajustando en la división de objetos individuales de SynMirrorV2 durante 40,000 iteraciones, manteniendo activas las ramas de condicionamiento y generación.
La Etapa 2 ajustó durante 10,000 iteraciones en la división de múltiples objetos de SynMirrorV2 para manejar oclusiones y escenas complejas.
La Etapa 3 añadió 10,000 iteraciones con datos del conjunto de datos MSD del mundo real, utilizando mapas de profundidad de Matterport3D.

Ejemplos del conjunto de datos MSD con mapas de profundidad y segmentación. Fuente: https://arxiv.org/pdf/1908.09101
Los prompts de texto se omitieron el 20% del tiempo para priorizar la información de profundidad. El entrenamiento usó cuatro GPUs NVIDIA A100, una tasa de aprendizaje de 1e-5, un tamaño de lote de 4 por GPU y el optimizador AdamW.
Este entrenamiento progresivo pasó de escenas sintéticas simples a escenas complejas del mundo real para una mejor transferibilidad.
Pruebas
MirrorFusion 2.0 fue probado contra la línea base MirrorFusion en MirrorBenchV2, cubriendo escenas de objetos individuales y múltiples, con pruebas cualitativas en los conjuntos de datos MSD y Google Scanned Objects (GSO).
La evaluación usó 2,991 escenas de objetos individuales y 300 escenas de dos objetos, midiendo PSNR, SSIM y LPIPS para la calidad de los reflejos, y CLIP para la alineación con prompts. Las imágenes se generaron con cuatro semillas, seleccionando la mejor puntuación SSIM.

Izquierda: Calidad de reflejos de objetos individuales en MirrorBenchV2, con MirrorFusion 2.0 superando la línea base. Derecha: Calidad de reflejos de múltiples objetos, con entrenamiento multi-objeto mejorando los resultados.
Los autores señalan:
‘Nuestro método supera la línea base, y el ajuste fino multi-objeto mejora los resultados en escenas complejas.’
Las pruebas cualitativas destacaron las mejoras de MirrorFusion 2.0:

Comparación en MirrorBenchV2: La línea base muestra una orientación incorrecta de la silla y reflejos distorsionados; MirrorFusion 2.0 renderiza con precisión.
La línea base tuvo problemas con la orientación de objetos y artefactos espaciales, mientras que MirrorFusion 2.0, entrenado en SynMirrorV2, mantuvo un posicionamiento preciso y reflejos realistas.
Resultados del conjunto de datos GSO:

Comparación en GSO: La línea base distorsiona la estructura de los objetos; MirrorFusion 2.0 preserva geometría, color y detalles.
Los autores comentan:
‘MirrorFusion 2.0 refleja con precisión detalles como tiradores de cajones, mientras que la línea base produce resultados inverosímiles.’
Resultados del conjunto de datos MSD del mundo real:

Resultados de MSD: MirrorFusion 2.0, ajustado en MSD, captura escenas complejas con objetos desordenados y múltiples espejos con precisión.
El ajuste fino en MSD mejoró el manejo de escenas complejas del mundo real por parte de MirrorFusion 2.0, mejorando la coherencia de los reflejos.
Un estudio de usuarios encontró que el 84% prefirió los resultados de MirrorFusion 2.0.
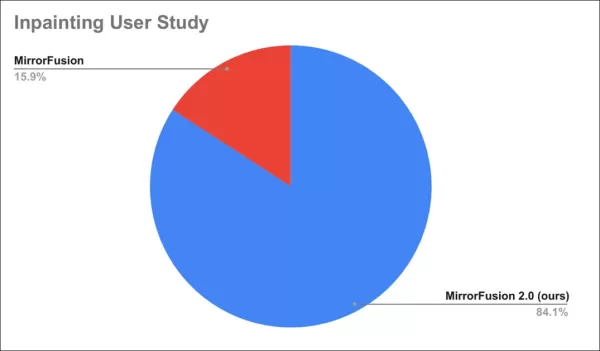
Resultados del estudio de usuarios.
Conclusión
Aunque MirrorFusion 2.0 marca un progreso, la línea base para la precisión de los reflejos en modelos de difusión sigue siendo baja, haciendo que incluso mejoras modestas sean notables. La arquitectura de los modelos de difusión lucha con una física consistente, y añadir datos, como se hizo aquí, es una solución estándar pero limitada.
Conjuntos de datos futuros con una mejor distribución de datos de reflejos podrían mejorar los resultados, pero esto aplica a muchas debilidades de los LDMs. Priorizar qué problemas abordar sigue siendo un desafío.
Publicado por primera vez el lunes, 28 de abril de 2025
Artículo relacionado
 Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
OpenAI modifica en secreto sus estatutos para dificultar la destitución de Altman
Tras el incidente similar a un golpe de Estado ocurrido en 2023, OpenAI ha reforzado aún más las garantías de protección para su director ejecutivo, Sam Altman, mediante la actualización de sus estatu
Meta AI ya responde a los mensajes de los compradores en Facebook Marketplace
Facebook Marketplace presenta nuevas funciones de Meta AI, entre las que se incluyen respuestas automáticas a las consultas de los compradores, según anunció la empresa el jueves. La plataforma tambié
Recomendaciones de temas especiales relacionados
Productividad
Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
OpenAI modifica en secreto sus estatutos para dificultar la destitución de Altman
Tras el incidente similar a un golpe de Estado ocurrido en 2023, OpenAI ha reforzado aún más las garantías de protección para su director ejecutivo, Sam Altman, mediante la actualización de sus estatu
Meta AI ya responde a los mensajes de los compradores en Facebook Marketplace
Facebook Marketplace presenta nuevas funciones de Meta AI, entre las que se incluyen respuestas automáticas a las consultas de los compradores, según anunció la empresa el jueves. La plataforma tambié
Recomendaciones de temas especiales relacionados
Productividad
 Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
 10 herramientas
10 herramientas
 xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai
chatbot
Los mejores entrenadores de IA para ligar y conversar: mejora tu carisma social y tu confianza en tiempo real
Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai
código
Las mejores herramientas de IA para pruebas unitarias automatizadas: genera casos de prueba con Jest, PyTest y JUnit con un solo clic
Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai
Análisis de datos
Las mejores herramientas de visualización de datos con IA: genera automáticamente paneles de BI interactivos a partir de archivos sin procesar
Descubre las mejores herramientas de visualización de datos con IA de 2026 en XIX.AI. Nuestra selección, cuidadosamente elegida y con las mejores valoraciones, te ayuda a generar automáticamente y al instante potentes paneles de BI interactivos a partir de archivos sin procesar. Compara las opciones gratuitas con las de pago mediante pruebas en condiciones reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo todo el potencial de tus datos.
10 herramientas
xix.ai

 comentario (4)
0/500
comentario (4)
0/500
![GaryWalker]()
鏡の反射をリアルに描画するAIの進歩ってすごいですね!でも、これが深フェイクに悪用されたらどうなるんだろう…ちょっと怖いかも😅 反射の物理法則を理解するって、AIが現実世界を「見る」能力が向上している証拠でしょうか?
![JimmyWilson]()
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
![FredGreen]()
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
![RogerNelson]()
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯
Desde que la IA generativa captó una amplia atención, los investigadores de visión por computadora han intensificado los esfuerzos para desarrollar modelos que comprendan y repliquen las leyes físicas, con un enfoque particular en desafíos como la simulación de la gravedad y la dinámica de fluidos en los últimos cinco años.
Con los modelos de difusión latente (LDMs) liderando la IA generativa desde 2022, la atención se ha centrado en sus dificultades para representar con precisión fenómenos físicos. Este problema ha ganado relevancia tras el modelo de video Sora de OpenAI y los recientes lanzamientos de código abierto de Hunyuan Video y Wan 2.1.
Dificultades con los Reflejos
La investigación para mejorar la comprensión de los LDMs sobre la física se ha centrado principalmente en áreas como la simulación de la marcha y el movimiento newtoniano, ya que las inexactitudes aquí socavan el realismo de los videos generados por IA.
Sin embargo, un creciente cuerpo de trabajo apunta a una debilidad clave de los LDMs: su capacidad limitada para generar reflejos precisos.
Del artículo de enero de 2025 ‘Reflejando la Realidad: Habilitando Modelos de Difusión para Producir Reflejos Fieles en Espejos’, ejemplos de ‘fallo de reflexión’ frente al enfoque de los investigadores. Fuente: https://arxiv.org/pdf/2409.14677
Este desafío, también presente en CGI y videojuegos, depende de algoritmos de trazado de rayos para simular la interacción de la luz con las superficies, produciendo reflejos, refracciones y sombras realistas.
Sin embargo, cada rebote adicional de rayos de luz aumenta significativamente las demandas computacionales, obligando a las aplicaciones en tiempo real a equilibrar la latencia y la precisión limitando el número de rebotes.
Un haz de luz virtual en un escenario basado en 3D (CGI), utilizando técnicas de la década de 1960, refinadas entre ‘Tron’ (1982) y ‘Jurassic Park’ (1993). Fuente: https://www.unrealengine.com/en-US/explainers/ray-tracing/what-is-real-time-ray-tracing
Por ejemplo, renderizar una tetera cromada frente a un espejo implica que los rayos de luz reboten repetidamente, creando bucles casi infinitos con un beneficio visual mínimo. Generalmente, dos o tres rebotes son suficientes para reflejos perceptibles, ya que un solo rebote produce un espejo oscuro.
Cada rebote adicional duplica el tiempo de renderizado, haciendo que el manejo eficiente de reflejos sea crítico para mejorar las imágenes trazadas por rayos.
Los reflejos son vitales para el fotorrealismo en casos más sutiles, como calles mojadas, reflejos en escaparates o gafas de personajes, donde los objetos y entornos deben aparecer con precisión.
Un reflejo gemelo creado mediante composición tradicional para una escena en ‘The Matrix’ (1999).
Desafíos en Visuales
Antes de los modelos de difusión, marcos como Neural Radiance Fields (NeRF) y enfoques más recientes como Gaussian Splatting lucharon por representar reflejos de manera natural.
El proyecto REF2-NeRF propuso un método basado en NeRF para escenas con vitrinas, modelando refracción y reflexión según la perspectiva del espectador. Esto permitió estimar superficies de vidrio y separar la luz directa de la reflejada.
Ejemplos del artículo Ref2Nerf. Fuente: https://arxiv.org/pdf/2311.17116
Otras soluciones centradas en reflejos para NeRF incluyen NeRFReN, Reflejando la Realidad y el proyecto de Meta de 2024 Campos de Radiancia Neural Conscientes de Reflejos Planos.
Para Gaussian Splatting, esfuerzos como Mirror-3DGS, Gaussian Splatting Reflexivo y RefGaussian abordaron problemas de reflejos, mientras que el proyecto Nero de 2023 introdujo un método único para representaciones neuronales.
Avance de MirrorVerse
Enseñar a los modelos de difusión a manejar la lógica de los reflejos es más difícil que con métodos estructurales como Gaussian Splatting o NeRF. Un reflejo confiable en modelos de difusión depende de datos de entrenamiento diversos y de alta calidad en diversos escenarios.
Tradicionalmente, añadir tales comportamientos implica LoRA o ajuste fino, pero estos desvían los resultados o crean herramientas específicas del modelo incompatibles con el modelo original.
Mejorar los modelos de difusión requiere datos de entrenamiento que enfatizen la física de los reflejos. Sin embargo, curar conjuntos de datos a hiperescala para cada debilidad es costoso e impráctico.
Aun así, surgen soluciones, como el proyecto MirrorVerse de India, que ofrece un conjunto de datos mejorado y un método de entrenamiento para avanzar en la precisión de los reflejos en modelos de difusión.
A la derecha, resultados de MirrorVerse comparados con dos enfoques anteriores (columnas centrales). Fuente: https://arxiv.org/pdf/2504.15397
Como se muestra arriba, MirrorVerse mejora los esfuerzos recientes, pero no es impecable.
En la imagen superior derecha, los jarros de cerámica están ligeramente desalineados, y en la imagen inferior, aparece un reflejo erróneo de una taza contra los ángulos reflectivos naturales.
Exploraremos este método no como una solución definitiva, sino para destacar los desafíos persistentes que enfrentan los modelos de difusión en formatos estáticos y de video, donde los datos de reflejos suelen estar ligados a escenarios específicos.
Por lo tanto, los LDMs pueden quedarse atrás de NeRF, Gaussian Splatting y CGI tradicional en la precisión de los reflejos.
El artículo, MirrorVerse: Impulsando Modelos de Difusión para Reflejar Realistamente el Mundo, proviene de investigadores del Vision and AI Lab, IISc Bangalore, y Samsung R&D Institute, Bangalore, con una página de proyecto, un conjuntoívne de datos en Hugging Face y código en GitHub.
Metodología
Los investigadores destacan la dificultad que enfrentan modelos como Stable Diffusion y Flux con prompts basados en reflejos, como se muestra a continuación:
Del artículo: Los principales modelos de texto a imagen, SD3.5 y Flux, luchan con reflejos consistentes y geométricamente precisos.
El equipo desarrolló MirrorFusion 2.0, un modelo basado en difusión para mejorar el fotorrealismo y la precisión geométrica de los reflejos en espejos. Fue entrenado en su conjunto de datos MirrorGen2, diseñado para abordar problemas de generalización.
MirrorGen2 introduce posicionamiento aleatorio de objetos, rotaciones aleatorias y anclaje explícito de objetos para garantizar reflejos plausibles en diversas posiciones de objetos.
Esquema de datos sintéticos de MirrorVerse: posicionamiento, rotación y anclaje aleatorios mediante 3D-Positioner, con objetos emparejados para interacciones espaciales realistas.
MirrorGen2 incluye escenas de objetos emparejados para manejar mejor oclusiones y disposiciones espaciales complejas en entornos reflectivos.
El artículo señala:
‘Las categorías se emparejan para coherencia semántica, como una silla con una mesa. Tras posicionar el objeto principal, se añade uno secundario sin superposición, asegurando regiones espaciales distintas.’
Para el anclaje de objetos, los autores aseguraron que los objetos estuvieran anclados al suelo, evitando un ‘flotamiento’ no natural en los datos sintéticos.
Dado que la innovación del conjunto de datos impulsa la novedad del artículo, lo cubriremos a continuación.
Datos y Pruebas
SynMirrorV2
El conjunto de datos SynMirrorV2 mejora la diversidad de los datos de entrenamiento de reflejos, utilizando objetos 3D de Objaverse y Amazon Berkeley Objects (ABO), refinados mediante filtrado de OBJECT 3DIT y V1 MirrorFusion, generando 66,062 objetos de alta calidad.
Ejemplos del conjunto de datos Objaverse utilizados para el conjunto de datos curado. Fuente: https://arxiv.org/pdf/2212.08051
Las escenas se construyeron con suelos texturizados de CC-Textures y fondos HDRI de PolyHaven, utilizando espejos de pared completa o rectangulares. La iluminación usó una luz de área a un ángulo de 45 grados. Los objetos se escalaron, posicionaron mediante intersección de frustum de cámara-espejo y rotaron aleatoriamente en el eje y, con anclaje para evitar artefactos de flotación.
Las escenas con múltiples objetos usaron 3,140 emparejamientos semánticamente coherentes de ABO, evitando superposiciones para capturar diversas oclusiones y profundidad.
Vistas renderizadas del conjunto de datos con múltiples objetos, mostrando segmentación y mapas de profundidad.
Proceso de Entrenamiento
Un proceso de aprendizaje curricular de tres etapas entrenó MirrorFusion 2.0 para una generalización robusta en el mundo real.
La Etapa 1 inicializó los pesos desde Stable Diffusion v1.5, ajustando en la división de objetos individuales de SynMirrorV2 durante 40,000 iteraciones, manteniendo activas las ramas de condicionamiento y generación.
La Etapa 2 ajustó durante 10,000 iteraciones en la división de múltiples objetos de SynMirrorV2 para manejar oclusiones y escenas complejas.
La Etapa 3 añadió 10,000 iteraciones con datos del conjunto de datos MSD del mundo real, utilizando mapas de profundidad de Matterport3D.
Ejemplos del conjunto de datos MSD con mapas de profundidad y segmentación. Fuente: https://arxiv.org/pdf/1908.09101
Los prompts de texto se omitieron el 20% del tiempo para priorizar la información de profundidad. El entrenamiento usó cuatro GPUs NVIDIA A100, una tasa de aprendizaje de 1e-5, un tamaño de lote de 4 por GPU y el optimizador AdamW.
Este entrenamiento progresivo pasó de escenas sintéticas simples a escenas complejas del mundo real para una mejor transferibilidad.
Pruebas
MirrorFusion 2.0 fue probado contra la línea base MirrorFusion en MirrorBenchV2, cubriendo escenas de objetos individuales y múltiples, con pruebas cualitativas en los conjuntos de datos MSD y Google Scanned Objects (GSO).
La evaluación usó 2,991 escenas de objetos individuales y 300 escenas de dos objetos, midiendo PSNR, SSIM y LPIPS para la calidad de los reflejos, y CLIP para la alineación con prompts. Las imágenes se generaron con cuatro semillas, seleccionando la mejor puntuación SSIM.
Izquierda: Calidad de reflejos de objetos individuales en MirrorBenchV2, con MirrorFusion 2.0 superando la línea base. Derecha: Calidad de reflejos de múltiples objetos, con entrenamiento multi-objeto mejorando los resultados.
Los autores señalan:
‘Nuestro método supera la línea base, y el ajuste fino multi-objeto mejora los resultados en escenas complejas.’
Las pruebas cualitativas destacaron las mejoras de MirrorFusion 2.0:
Comparación en MirrorBenchV2: La línea base muestra una orientación incorrecta de la silla y reflejos distorsionados; MirrorFusion 2.0 renderiza con precisión.
La línea base tuvo problemas con la orientación de objetos y artefactos espaciales, mientras que MirrorFusion 2.0, entrenado en SynMirrorV2, mantuvo un posicionamiento preciso y reflejos realistas.
Resultados del conjunto de datos GSO:
Comparación en GSO: La línea base distorsiona la estructura de los objetos; MirrorFusion 2.0 preserva geometría, color y detalles.
Los autores comentan:
‘MirrorFusion 2.0 refleja con precisión detalles como tiradores de cajones, mientras que la línea base produce resultados inverosímiles.’
Resultados del conjunto de datos MSD del mundo real:
Resultados de MSD: MirrorFusion 2.0, ajustado en MSD, captura escenas complejas con objetos desordenados y múltiples espejos con precisión.
El ajuste fino en MSD mejoró el manejo de escenas complejas del mundo real por parte de MirrorFusion 2.0, mejorando la coherencia de los reflejos.
Un estudio de usuarios encontró que el 84% prefirió los resultados de MirrorFusion 2.0.
Resultados del estudio de usuarios.
Conclusión
Aunque MirrorFusion 2.0 marca un progreso, la línea base para la precisión de los reflejos en modelos de difusión sigue siendo baja, haciendo que incluso mejoras modestas sean notables. La arquitectura de los modelos de difusión lucha con una física consistente, y añadir datos, como se hizo aquí, es una solución estándar pero limitada.
Conjuntos de datos futuros con una mejor distribución de datos de reflejos podrían mejorar los resultados, pero esto aplica a muchas debilidades de los LDMs. Priorizar qué problemas abordar sigue siendo un desafío.
Publicado por primera vez el lunes, 28 de abril de 2025










 Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
Grok, de Musk: 1,5 billones de parámetros y absorción de código de cursor: ¿un punto de inflexión o un farol?
Elon Musk por fin está dando un paso adelante.En la carrera por la programación de IA, OpenAI y Anthropic están acelerando, mientras que xAI parece quedarse atrás. Musk ha manifestado en numerosas oca
 OpenAI modifica en secreto sus estatutos para dificultar la destitución de Altman
Tras el incidente similar a un golpe de Estado ocurrido en 2023, OpenAI ha reforzado aún más las garantías de protección para su director ejecutivo, Sam Altman, mediante la actualización de sus estatu
OpenAI modifica en secreto sus estatutos para dificultar la destitución de Altman
Tras el incidente similar a un golpe de Estado ocurrido en 2023, OpenAI ha reforzado aún más las garantías de protección para su director ejecutivo, Sam Altman, mediante la actualización de sus estatu
 Meta AI ya responde a los mensajes de los compradores en Facebook Marketplace
Facebook Marketplace presenta nuevas funciones de Meta AI, entre las que se incluyen respuestas automáticas a las consultas de los compradores, según anunció la empresa el jueves. La plataforma tambié
Meta AI ya responde a los mensajes de los compradores en Facebook Marketplace
Facebook Marketplace presenta nuevas funciones de Meta AI, entre las que se incluyen respuestas automáticas a las consultas de los compradores, según anunció la empresa el jueves. La plataforma tambié

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai

Descubre las mejores herramientas de visualización de datos con IA de 2026 en XIX.AI. Nuestra selección, cuidadosamente elegida y con las mejores valoraciones, te ayuda a generar automáticamente y al instante potentes paneles de BI interactivos a partir de archivos sin procesar. Compara las opciones gratuitas con las de pago mediante pruebas en condiciones reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo todo el potencial de tus datos.
10 herramientas
xix.ai

鏡の反射をリアルに描画するAIの進歩ってすごいですね!でも、これが深フェイクに悪用されたらどうなるんだろう…ちょっと怖いかも😅 反射の物理法則を理解するって、AIが現実世界を「見る」能力が向上している証拠でしょうか?
This article on AI mirror reflections is wild! It's like teaching a robot to see itself in a funhouse mirror and actually get it right. Can't wait to see this in video games! 😎
This article on AI rendering mirror reflections is mind-blowing! It's crazy how far computer vision has come. 😮 Makes me wonder if we'll soon see AI designing entire virtual worlds with perfect physics!
This article on AI rendering realistic mirror reflections is fascinating! It’s wild to think how far computer vision has come, mimicking actual physics like that. Makes me wonder if we’ll soon see AI designing entire virtual worlds that feel totally real. 🤯













