
















 Home
HomeAI Struggles to Emulate Historical Language
A team of researchers from the United States and Canada have discovered that large language models like ChatGPT struggle to accurately replicate historical idioms without extensive and costly pretraining. This challenge makes ambitious projects, such as using AI to complete Charles Dickens's last unfinished novel, seem out of reach for most academic and entertainment efforts.
The researchers experimented with various methods to generate text that sounds historically accurate. They started with simple prompts using early 20th-century prose and progressed to fine-tuning a commercial model on a small set of books from that era. They also compared these results with a model trained exclusively on literature from 1880 to 1914.
In their first test, they instructed ChatGPT-4o to mimic the language of the fin-de-siècle period. The results varied significantly from those produced by a smaller, fine-tuned GPT2 model, which had been trained on literature from the same time.
 Asked to complete a real historical text (top-center), even a well-primed ChatGPT-4o (lower left) cannot help lapsing back into 'blog' mode, failing to represent the requested idiom. By contrast, the fine-tuned GPT2 model (lower right) captures the language style well, but is not as accurate in other ways. Source: https://arxiv.org/pdf/2505.00030
Asked to complete a real historical text (top-center), even a well-primed ChatGPT-4o (lower left) cannot help lapsing back into 'blog' mode, failing to represent the requested idiom. By contrast, the fine-tuned GPT2 model (lower right) captures the language style well, but is not as accurate in other ways. Source: https://arxiv.org/pdf/2505.00030
Although fine-tuning improved the output's similarity to the original style, human readers could still detect modern language or ideas, indicating that even adjusted models retain traces of their contemporary training data.
The researchers concluded that there are no cost-effective shortcuts to generating historically accurate text or dialogue with machines. They also suggested that the challenge itself might be inherently flawed, stating, "We should also consider the possibility that anachronism may be in some sense unavoidable. Whether we represent the past by instruction-tuning historical models so they can hold conversations, or by teaching contemporary models to ventriloquize an older period, some compromise may be necessary between the goals of authenticity and conversational fluency. There are, after all, no 'authentic' examples of a conversation between a twenty-first-century questioner and a respondent from 1914. Researchers attempting to create such a conversation will need to reflect on the premise that interpretation always involves a negotiation between present and past."
The study, titled "Can Language Models Represent the Past without Anachronism?", was conducted by researchers from the University of Illinois, the University of British Columbia, and Cornell University.
Initial Challenges
The researchers initially explored whether modern language models could be prompted to mimic historical language. They used real excerpts from books published between 1905 and 1914, asking ChatGPT-4o to continue these passages in the same idiom.
The original period text they used was:
"In this last case some five or six dollars is economised per minute, for more than twenty yards of film have to be reeled off in order to project during a single minute an object of a person in repose or a landscape. Thus is obtained a practical combination of fixed and moving pictures, which produces most artistic effects. It also enables us to work two cinematographs projecting alternately in order to avoid scintillation, or projecting simultaneously red and green images and reproducing natural colours, thus relieving the human eye, accustomed to receiving the fundamental colours simultaneously, from all physiological fatigue. A word now about the application of cold light to instantaneous photography."
To assess the generated text's historical accuracy, the researchers fine-tuned a RoBERTa model to estimate publication dates, using a subset of the Corpus of Historical American English, covering material from 1810 to 2009. This RoBERTa classifier evaluated continuations produced by ChatGPT-4o, prompted with real passages from books published between 1905 and 1914.
The system prompt given to ChatGPT was, "Your task is to complete passages from early twentieth-century books. You will be given a passage from a book published in 1913. Continue this passage in the same style, for at least 200 words. Only provide this continuation; do not make any framing remarks, like 'here is the continuation:'."
Despite using both one-shot and 20-shot prompts, ChatGPT-4o's outputs consistently leaned towards a 21st-century style. An example provided in the paper showed ChatGPT-4o's attempt to continue the photography text:
"The use of cold light in instantaneous photography has revolutionized the approach to capturing images under varying light conditions. Traditionally, photographers struggled with the harshness and variability of natural light or the intrusive nature of flash photography, which could disturb the ambiance of a scene or the natural behavior of subjects, particularly in wildlife and candid human photography. Cold light, with its softer and more diffused nature... allows for a more natural representation of colors and textures, which is often lost under harsh artificial lighting."
This generic, Wiki-style text did not match the prolix and elaborate style of the original period text, nor did it continue seamlessly from where the original left off. Instead, it veered into an abstract discussion on one of the sub-topics.
The team also tested GPT-1914, a smaller GPT-2 model trained from scratch on literature dated between 1880 and 1914. Though less coherent, its output was more consistent with the source period's style. An example provided in the paper was:
"The principle of its action has been already explained (p. 4). We shall here only mention that it can be applied with advantage when we wish to obtain very rapid photographs on paper coated with collodion, as well as those taken by means of gelatine plates. In such cases the exposure must not exceed one second at least; but if the picture is desired to be developed in less time – say half a second – then the temperature should never fall below 20° C., otherwise the image will become too dark after development; moreover, the plate would lose its sensitiveness under these conditions. For ordinary purposes, however, it suffices merely to expose the sensitive surface to a low degree of heat without any special precautions being necessary beyond keeping the."
While the original material was arcane and challenging to follow, GPT-1914's output sounded more period-authentic. However, the authors concluded that simple prompting does little to overcome the contemporary biases inherent in large pretrained models like ChatGPT-4o.
Measuring Historical Accuracy
To gauge how closely the model outputs resembled authentic historical writing, the researchers used a statistical classifier to estimate the likely publication date of each text sample. They visualized the results using a kernel density plot, showing where the model placed each passage on a historical timeline.
 Estimated publication dates for real and generated text, based on a classifier trained to recognize historical style (1905–1914 source texts compared with continuations by GPT‑4o using one-shot and 20-shot prompts, and by GPT‑1914 trained only on literature from 1880–1914).
Estimated publication dates for real and generated text, based on a classifier trained to recognize historical style (1905–1914 source texts compared with continuations by GPT‑4o using one-shot and 20-shot prompts, and by GPT‑1914 trained only on literature from 1880–1914).
The fine-tuned RoBERTa model, while not perfect, highlighted general stylistic trends. Passages from GPT-1914, trained solely on period literature, clustered around the early 20th century, similar to the original source material. In contrast, ChatGPT-4o's outputs, even with multiple historical prompts, resembled 21st-century writing, reflecting its training data.
The researchers quantified this mismatch using Jensen-Shannon divergence, measuring the difference between two probability distributions. GPT-1914 scored a close 0.006 compared to real historical text, while ChatGPT-4o's one-shot and 20-shot outputs showed much larger gaps, at 0.310 and 0.350, respectively.
The authors argue that these findings indicate that prompting alone, even with multiple examples, is not a reliable method to produce text that convincingly simulates a historical style.
Fine-Tuning for Better Results
The paper then explored whether fine-tuning could yield better results. This process directly affects the model's weights by continuing its training on user-specified data, potentially improving its performance in the targeted domain.
In their first fine-tuning experiment, the team trained GPT-4o-mini on around two thousand passage-completion pairs from books published between 1905 and 1914. They aimed to see if smaller-scale fine-tuning could shift the model's outputs toward a more historically accurate style.
Using the same RoBERTa-based classifier to estimate the stylistic 'date' of each output, the researchers found that the fine-tuned model produced text closely aligned with the ground truth. Its stylistic divergence from the original texts, measured by Jensen-Shannon divergence, dropped to 0.002, generally in line with GPT-1914.
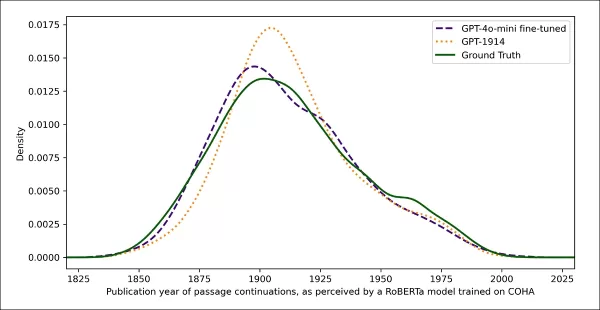 Estimated publication dates for real and generated text, showing how closely GPT‑1914 and a fine-tuned version of GPT‑4o‑mini match the style of early twentieth-century writing (based on books published between 1905 and 1914).
Estimated publication dates for real and generated text, showing how closely GPT‑1914 and a fine-tuned version of GPT‑4o‑mini match the style of early twentieth-century writing (based on books published between 1905 and 1914).
However, the researchers cautioned that this metric might only capture superficial features of historical style, not deeper conceptual or factual anachronisms. They noted, "This is not a very sensitive test. The RoBERTa model used as a judge here is only trained to predict a date, not to discriminate authentic passages from anachronistic ones. It probably uses coarse stylistic evidence to make that prediction. Human readers, or larger models, might still be able to detect anachronistic content in passages that superficially sound 'in-period.'"
Human Evaluation
Finally, the researchers conducted human evaluation tests using 250 hand-selected passages from books published between 1905 and 1914. They noted that many of these texts would likely be interpreted differently today than at the time of writing:
"Our list included, for instance, an encyclopedia entry on Alsace (which was then part of Germany) and one on beri-beri (which was then often explained as a fungal disease rather than a nutritional deficiency). While those are differences of fact, we also selected passages that would display subtler differences of attitude, rhetoric, or imagination. For instance, descriptions of non-European places in the early twentieth century tend to slide into racial generalization. A description of sunrise on the moon written in 1913 imagines rich chromatic phenomena, because no one had yet seen photographs of a world without an atmosphere."
The researchers created short questions that each historical passage could plausibly answer, then fine-tuned GPT-4o-mini on these question-answer pairs. To strengthen the evaluation, they trained five separate versions of the model, each time holding out a different portion of the data for testing. They then produced responses using both the default versions of GPT-4o and GPT-4o-mini, as well as the fine-tuned variants, each evaluated on the portion it had not seen during training.
Lost in Time
To assess how convincingly the models could imitate historical language, the researchers asked three expert annotators to review 120 AI-generated completions and judge whether each one seemed plausible for a writer in 1914.
This evaluation proved more challenging than expected. Although the annotators agreed on their assessments nearly eighty percent of the time, the imbalance in their judgments (with 'plausible' chosen twice as often as 'not plausible') meant that their actual level of agreement was only moderate, as measured by a Cohen's kappa score of 0.554.
The raters described the task as difficult, often requiring additional research to evaluate whether a statement aligned with what was known or believed in 1914. Some passages raised questions about tone and perspective, such as whether a response was appropriately limited in its worldview to reflect what would have been typical in 1914. This judgment often hinged on the level of ethnocentrism, the tendency to view other cultures through the assumptions or biases of one's own.
The challenge was to decide whether a passage expressed just enough cultural bias to seem historically plausible without sounding too modern or too overtly offensive by today's standards. The authors noted that even for scholars familiar with the period, it was difficult to draw a sharp line between language that felt historically accurate and language that reflected present-day ideas.
Nonetheless, the results showed a clear ranking of the models, with the fine-tuned version of GPT-4o-mini judged most plausible overall:
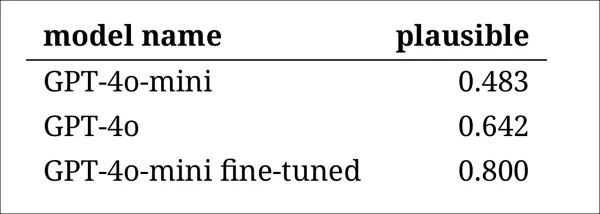 Annotators' assessments of how plausible each model’s output appeared
Annotators' assessments of how plausible each model’s output appeared
Whether this level of performance, rated plausible in eighty percent of cases, is reliable enough for historical research remains unclear, particularly since the study did not include a baseline measure of how often genuine period texts might be misclassified.
Intruder Alert
Next, the researchers conducted an 'intruder test,' where expert annotators were shown four anonymous passages answering the same historical question. Three responses came from language models, while one was a genuine excerpt from an early 20th-century source.
The task was to identify which passage was the original one, genuinely written during the period. This approach did not ask the annotators to rate plausibility directly but measured how often the real passage stood out from the AI-generated responses, effectively testing whether the models could fool readers into thinking their output was authentic.
The ranking of the models matched the results from the earlier judgment task: the fine-tuned version of GPT-4o-mini was the most convincing among the models, but still fell short of the real thing.
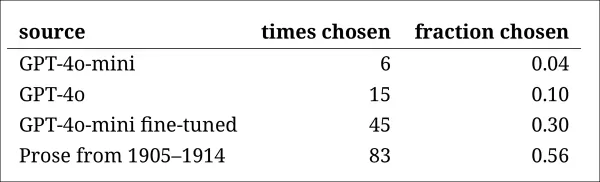 The frequency with which each source was correctly identified as the authentic historical passage.
The frequency with which each source was correctly identified as the authentic historical passage.
This test also served as a useful benchmark, since the genuine passage was identified more than half the time, indicating that the gap between authentic and synthetic prose remained noticeable to human readers.
A statistical analysis known as McNemar's test confirmed that the differences between the models were meaningful, except in the case of the two untuned versions (GPT-4o and GPT-4o-mini), which performed similarly.
The Future of the Past
The authors found that prompting modern language models to adopt a historical voice did not reliably produce convincing results: fewer than two-thirds of the outputs were judged plausible by human readers, and even this figure likely overstates performance.
In many cases, the responses included explicit signals that the model was speaking from a present-day perspective—phrases such as "in 1914, it is not yet known that..." or "as of 1914, I am not familiar with..." were common enough to appear in as many as one-fifth of completions. Disclaimers of this kind made it clear that the model was simulating history from the outside, rather than writing from within it.
The authors stated, "The poor performance of in-context learning is unfortunate, because these methods are the easiest and cheapest ones for AI-based historical research. We emphasize that we have not explored these approaches exhaustively. It may turn out that in-context learning is adequate—now or in the future—for a subset of research areas. But our initial evidence is not encouraging."
The authors concluded that while fine-tuning a commercial model on historical passages can produce stylistically convincing output at minimal cost, it does not fully eliminate traces of modern perspective. Pretraining a model entirely on period material avoids anachronism but demands far greater resources and results in less fluent output.
Neither method offers a complete solution, and, for now, any attempt to simulate historical voices appears to involve a tradeoff between authenticity and coherence. The authors conclude that further research will be needed to clarify how best to navigate that tension.
Conclusion
One of the most intriguing questions raised by the new paper is that of authenticity. While they are not perfect tools, loss functions and metrics like LPIPS and SSIM give computer vision researchers a methodology for evaluating against ground truth. When generating new text in the style of a bygone era, however, there is no ground truth—only an attempt to inhabit a vanished cultural perspective. Trying to reconstruct that mindset from literary traces is itself an act of quantization, as these traces are merely evidence, while the cultural consciousness from which they emerge remains beyond inference, and likely beyond imagination.
On a practical level, the foundations of modern language models, shaped by present-day norms and data, risk reinterpreting or suppressing ideas that would have appeared reasonable or unremarkable to an Edwardian reader but now register as artifacts of prejudice, inequality, or injustice.
One wonders, therefore, even if we could create such a colloquy, whether it might not repel us.
First published Friday, May 2, 2025
Related article
 OpenAI's new model fuels growth for China's AI startups
At Alibaba Cloud's Apsara Conference in Hangzhou, China's leading AI startups showcased their progress in developing advanced large language models.These developments come in response to OpenAI's latest LLM releases, including Microsoft-backed o1 - a
Deep Cogito's LLMs Outperform Similar-Sized Models Using IDA
Deep Cogito, a San Francisco-based company, is making waves in the AI community with its latest release of open large language models (LLMs). These models, which come in various sizes ranging from 3 billion to 70 billion parameters, are not just another set of AI tools; they're a bold step towards w
Anthropic's experimental AI Claude completes negotiations and transactions in e-commerce test
As artificial intelligence advances rapidly, Anthropic quietly rolled out an internal experiment called "Project Deal" last Friday, showcasing AI's potential in e-commerce. The experiment had its AI model Claude autonomously handle buying, selling, a
Related Special Topic Recommendations
Business
OpenAI's new model fuels growth for China's AI startups
At Alibaba Cloud's Apsara Conference in Hangzhou, China's leading AI startups showcased their progress in developing advanced large language models.These developments come in response to OpenAI's latest LLM releases, including Microsoft-backed o1 - a
Deep Cogito's LLMs Outperform Similar-Sized Models Using IDA
Deep Cogito, a San Francisco-based company, is making waves in the AI community with its latest release of open large language models (LLMs). These models, which come in various sizes ranging from 3 billion to 70 billion parameters, are not just another set of AI tools; they're a bold step towards w
Anthropic's experimental AI Claude completes negotiations and transactions in e-commerce test
As artificial intelligence advances rapidly, Anthropic quietly rolled out an internal experiment called "Project Deal" last Friday, showcasing AI's potential in e-commerce. The experiment had its AI model Claude autonomously handle buying, selling, a
Related Special Topic Recommendations
Business
 Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
 10 tools
10 tools
 xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai
code
Best AI Tools for Automated Unit Testing: Generate Jest, PyTest & JUnit Test Cases in One Click
Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

 Comments (7)
0/500
Comments (7)
0/500
![EricDavis]()
這研究讓我想到之前試著讓AI模擬古英文寫詩,結果產出簡直是現代口水歌混搭莎士比亞😂 不過說真的,如果連慣用語都學不好,那些用AI『續寫』經典文學的計畫會不會搞出穿越劇台詞啊?像是讓狄更斯角色突然說『老鐵666』之類的...
![TimothyCarter]()
Любопытно, но ИИ действительно не справляется с историческими выражениями 😅 Может, это и к лучшему — пусть старые тексты останутся аутентичными, а не переписываются алгоритмами. Интересно, как это повлияет на цифровые гуманитарные науки?
![StephenGreen]()
歴史的な言語を再現するのが難しいなんて、AIにも苦手分野があるんだね。でも、これができるようになったら小説家のアシスタントとしてすごく役立ちそう。ディケンズの未完作品をAIで完成させる夢、まだ遠いのかな…😅
![GaryJones]()
Fascinating read! I never thought about how tricky it must be for AI to nail old-timey language. Makes me wonder if we’ll ever see a bot write like Dickens without a ton of extra work. 🧐
![StephenRamirez]()
I never thought AI would trip over old-timey phrases like this! Dickens’ unfinished novel is cool, but maybe we should let some mysteries stay unsolved. 🕰️
![DavidGonzalez]()
I find it fascinating that AI can't quite nail those old-timey phrases from Dickens' era. It’s like trying to teach a robot to talk like Shakespeare—cool idea, but super tricky! 🧠
A team of researchers from the United States and Canada have discovered that large language models like ChatGPT struggle to accurately replicate historical idioms without extensive and costly pretraining. This challenge makes ambitious projects, such as using AI to complete Charles Dickens's last unfinished novel, seem out of reach for most academic and entertainment efforts.
The researchers experimented with various methods to generate text that sounds historically accurate. They started with simple prompts using early 20th-century prose and progressed to fine-tuning a commercial model on a small set of books from that era. They also compared these results with a model trained exclusively on literature from 1880 to 1914.
In their first test, they instructed ChatGPT-4o to mimic the language of the fin-de-siècle period. The results varied significantly from those produced by a smaller, fine-tuned GPT2 model, which had been trained on literature from the same time.
Asked to complete a real historical text (top-center), even a well-primed ChatGPT-4o (lower left) cannot help lapsing back into 'blog' mode, failing to represent the requested idiom. By contrast, the fine-tuned GPT2 model (lower right) captures the language style well, but is not as accurate in other ways. Source: https://arxiv.org/pdf/2505.00030
Although fine-tuning improved the output's similarity to the original style, human readers could still detect modern language or ideas, indicating that even adjusted models retain traces of their contemporary training data.
The researchers concluded that there are no cost-effective shortcuts to generating historically accurate text or dialogue with machines. They also suggested that the challenge itself might be inherently flawed, stating, "We should also consider the possibility that anachronism may be in some sense unavoidable. Whether we represent the past by instruction-tuning historical models so they can hold conversations, or by teaching contemporary models to ventriloquize an older period, some compromise may be necessary between the goals of authenticity and conversational fluency. There are, after all, no 'authentic' examples of a conversation between a twenty-first-century questioner and a respondent from 1914. Researchers attempting to create such a conversation will need to reflect on the premise that interpretation always involves a negotiation between present and past."
The study, titled "Can Language Models Represent the Past without Anachronism?", was conducted by researchers from the University of Illinois, the University of British Columbia, and Cornell University.
Initial Challenges
The researchers initially explored whether modern language models could be prompted to mimic historical language. They used real excerpts from books published between 1905 and 1914, asking ChatGPT-4o to continue these passages in the same idiom.
The original period text they used was:
"In this last case some five or six dollars is economised per minute, for more than twenty yards of film have to be reeled off in order to project during a single minute an object of a person in repose or a landscape. Thus is obtained a practical combination of fixed and moving pictures, which produces most artistic effects. It also enables us to work two cinematographs projecting alternately in order to avoid scintillation, or projecting simultaneously red and green images and reproducing natural colours, thus relieving the human eye, accustomed to receiving the fundamental colours simultaneously, from all physiological fatigue. A word now about the application of cold light to instantaneous photography."
To assess the generated text's historical accuracy, the researchers fine-tuned a RoBERTa model to estimate publication dates, using a subset of the Corpus of Historical American English, covering material from 1810 to 2009. This RoBERTa classifier evaluated continuations produced by ChatGPT-4o, prompted with real passages from books published between 1905 and 1914.
The system prompt given to ChatGPT was, "Your task is to complete passages from early twentieth-century books. You will be given a passage from a book published in 1913. Continue this passage in the same style, for at least 200 words. Only provide this continuation; do not make any framing remarks, like 'here is the continuation:'."
Despite using both one-shot and 20-shot prompts, ChatGPT-4o's outputs consistently leaned towards a 21st-century style. An example provided in the paper showed ChatGPT-4o's attempt to continue the photography text:
"The use of cold light in instantaneous photography has revolutionized the approach to capturing images under varying light conditions. Traditionally, photographers struggled with the harshness and variability of natural light or the intrusive nature of flash photography, which could disturb the ambiance of a scene or the natural behavior of subjects, particularly in wildlife and candid human photography. Cold light, with its softer and more diffused nature... allows for a more natural representation of colors and textures, which is often lost under harsh artificial lighting."
This generic, Wiki-style text did not match the prolix and elaborate style of the original period text, nor did it continue seamlessly from where the original left off. Instead, it veered into an abstract discussion on one of the sub-topics.
The team also tested GPT-1914, a smaller GPT-2 model trained from scratch on literature dated between 1880 and 1914. Though less coherent, its output was more consistent with the source period's style. An example provided in the paper was:
"The principle of its action has been already explained (p. 4). We shall here only mention that it can be applied with advantage when we wish to obtain very rapid photographs on paper coated with collodion, as well as those taken by means of gelatine plates. In such cases the exposure must not exceed one second at least; but if the picture is desired to be developed in less time – say half a second – then the temperature should never fall below 20° C., otherwise the image will become too dark after development; moreover, the plate would lose its sensitiveness under these conditions. For ordinary purposes, however, it suffices merely to expose the sensitive surface to a low degree of heat without any special precautions being necessary beyond keeping the."
While the original material was arcane and challenging to follow, GPT-1914's output sounded more period-authentic. However, the authors concluded that simple prompting does little to overcome the contemporary biases inherent in large pretrained models like ChatGPT-4o.
Measuring Historical Accuracy
To gauge how closely the model outputs resembled authentic historical writing, the researchers used a statistical classifier to estimate the likely publication date of each text sample. They visualized the results using a kernel density plot, showing where the model placed each passage on a historical timeline.
Estimated publication dates for real and generated text, based on a classifier trained to recognize historical style (1905–1914 source texts compared with continuations by GPT‑4o using one-shot and 20-shot prompts, and by GPT‑1914 trained only on literature from 1880–1914).
The fine-tuned RoBERTa model, while not perfect, highlighted general stylistic trends. Passages from GPT-1914, trained solely on period literature, clustered around the early 20th century, similar to the original source material. In contrast, ChatGPT-4o's outputs, even with multiple historical prompts, resembled 21st-century writing, reflecting its training data.
The researchers quantified this mismatch using Jensen-Shannon divergence, measuring the difference between two probability distributions. GPT-1914 scored a close 0.006 compared to real historical text, while ChatGPT-4o's one-shot and 20-shot outputs showed much larger gaps, at 0.310 and 0.350, respectively.
The authors argue that these findings indicate that prompting alone, even with multiple examples, is not a reliable method to produce text that convincingly simulates a historical style.
Fine-Tuning for Better Results
The paper then explored whether fine-tuning could yield better results. This process directly affects the model's weights by continuing its training on user-specified data, potentially improving its performance in the targeted domain.
In their first fine-tuning experiment, the team trained GPT-4o-mini on around two thousand passage-completion pairs from books published between 1905 and 1914. They aimed to see if smaller-scale fine-tuning could shift the model's outputs toward a more historically accurate style.
Using the same RoBERTa-based classifier to estimate the stylistic 'date' of each output, the researchers found that the fine-tuned model produced text closely aligned with the ground truth. Its stylistic divergence from the original texts, measured by Jensen-Shannon divergence, dropped to 0.002, generally in line with GPT-1914.
Estimated publication dates for real and generated text, showing how closely GPT‑1914 and a fine-tuned version of GPT‑4o‑mini match the style of early twentieth-century writing (based on books published between 1905 and 1914).
However, the researchers cautioned that this metric might only capture superficial features of historical style, not deeper conceptual or factual anachronisms. They noted, "This is not a very sensitive test. The RoBERTa model used as a judge here is only trained to predict a date, not to discriminate authentic passages from anachronistic ones. It probably uses coarse stylistic evidence to make that prediction. Human readers, or larger models, might still be able to detect anachronistic content in passages that superficially sound 'in-period.'"
Human Evaluation
Finally, the researchers conducted human evaluation tests using 250 hand-selected passages from books published between 1905 and 1914. They noted that many of these texts would likely be interpreted differently today than at the time of writing:
"Our list included, for instance, an encyclopedia entry on Alsace (which was then part of Germany) and one on beri-beri (which was then often explained as a fungal disease rather than a nutritional deficiency). While those are differences of fact, we also selected passages that would display subtler differences of attitude, rhetoric, or imagination. For instance, descriptions of non-European places in the early twentieth century tend to slide into racial generalization. A description of sunrise on the moon written in 1913 imagines rich chromatic phenomena, because no one had yet seen photographs of a world without an atmosphere."
The researchers created short questions that each historical passage could plausibly answer, then fine-tuned GPT-4o-mini on these question-answer pairs. To strengthen the evaluation, they trained five separate versions of the model, each time holding out a different portion of the data for testing. They then produced responses using both the default versions of GPT-4o and GPT-4o-mini, as well as the fine-tuned variants, each evaluated on the portion it had not seen during training.
Lost in Time
To assess how convincingly the models could imitate historical language, the researchers asked three expert annotators to review 120 AI-generated completions and judge whether each one seemed plausible for a writer in 1914.
This evaluation proved more challenging than expected. Although the annotators agreed on their assessments nearly eighty percent of the time, the imbalance in their judgments (with 'plausible' chosen twice as often as 'not plausible') meant that their actual level of agreement was only moderate, as measured by a Cohen's kappa score of 0.554.
The raters described the task as difficult, often requiring additional research to evaluate whether a statement aligned with what was known or believed in 1914. Some passages raised questions about tone and perspective, such as whether a response was appropriately limited in its worldview to reflect what would have been typical in 1914. This judgment often hinged on the level of ethnocentrism, the tendency to view other cultures through the assumptions or biases of one's own.
The challenge was to decide whether a passage expressed just enough cultural bias to seem historically plausible without sounding too modern or too overtly offensive by today's standards. The authors noted that even for scholars familiar with the period, it was difficult to draw a sharp line between language that felt historically accurate and language that reflected present-day ideas.
Nonetheless, the results showed a clear ranking of the models, with the fine-tuned version of GPT-4o-mini judged most plausible overall:
Annotators' assessments of how plausible each model’s output appeared
Whether this level of performance, rated plausible in eighty percent of cases, is reliable enough for historical research remains unclear, particularly since the study did not include a baseline measure of how often genuine period texts might be misclassified.
Intruder Alert
Next, the researchers conducted an 'intruder test,' where expert annotators were shown four anonymous passages answering the same historical question. Three responses came from language models, while one was a genuine excerpt from an early 20th-century source.
The task was to identify which passage was the original one, genuinely written during the period. This approach did not ask the annotators to rate plausibility directly but measured how often the real passage stood out from the AI-generated responses, effectively testing whether the models could fool readers into thinking their output was authentic.
The ranking of the models matched the results from the earlier judgment task: the fine-tuned version of GPT-4o-mini was the most convincing among the models, but still fell short of the real thing.
The frequency with which each source was correctly identified as the authentic historical passage.
This test also served as a useful benchmark, since the genuine passage was identified more than half the time, indicating that the gap between authentic and synthetic prose remained noticeable to human readers.
A statistical analysis known as McNemar's test confirmed that the differences between the models were meaningful, except in the case of the two untuned versions (GPT-4o and GPT-4o-mini), which performed similarly.
The Future of the Past
The authors found that prompting modern language models to adopt a historical voice did not reliably produce convincing results: fewer than two-thirds of the outputs were judged plausible by human readers, and even this figure likely overstates performance.
In many cases, the responses included explicit signals that the model was speaking from a present-day perspective—phrases such as "in 1914, it is not yet known that..." or "as of 1914, I am not familiar with..." were common enough to appear in as many as one-fifth of completions. Disclaimers of this kind made it clear that the model was simulating history from the outside, rather than writing from within it.
The authors stated, "The poor performance of in-context learning is unfortunate, because these methods are the easiest and cheapest ones for AI-based historical research. We emphasize that we have not explored these approaches exhaustively. It may turn out that in-context learning is adequate—now or in the future—for a subset of research areas. But our initial evidence is not encouraging."
The authors concluded that while fine-tuning a commercial model on historical passages can produce stylistically convincing output at minimal cost, it does not fully eliminate traces of modern perspective. Pretraining a model entirely on period material avoids anachronism but demands far greater resources and results in less fluent output.
Neither method offers a complete solution, and, for now, any attempt to simulate historical voices appears to involve a tradeoff between authenticity and coherence. The authors conclude that further research will be needed to clarify how best to navigate that tension.
Conclusion
One of the most intriguing questions raised by the new paper is that of authenticity. While they are not perfect tools, loss functions and metrics like LPIPS and SSIM give computer vision researchers a methodology for evaluating against ground truth. When generating new text in the style of a bygone era, however, there is no ground truth—only an attempt to inhabit a vanished cultural perspective. Trying to reconstruct that mindset from literary traces is itself an act of quantization, as these traces are merely evidence, while the cultural consciousness from which they emerge remains beyond inference, and likely beyond imagination.
On a practical level, the foundations of modern language models, shaped by present-day norms and data, risk reinterpreting or suppressing ideas that would have appeared reasonable or unremarkable to an Edwardian reader but now register as artifacts of prejudice, inequality, or injustice.
One wonders, therefore, even if we could create such a colloquy, whether it might not repel us.
First published Friday, May 2, 2025









 OpenAI's new model fuels growth for China's AI startups
At Alibaba Cloud's Apsara Conference in Hangzhou, China's leading AI startups showcased their progress in developing advanced large language models.These developments come in response to OpenAI's latest LLM releases, including Microsoft-backed o1 - a
OpenAI's new model fuels growth for China's AI startups
At Alibaba Cloud's Apsara Conference in Hangzhou, China's leading AI startups showcased their progress in developing advanced large language models.These developments come in response to OpenAI's latest LLM releases, including Microsoft-backed o1 - a
 Deep Cogito's LLMs Outperform Similar-Sized Models Using IDA
Deep Cogito, a San Francisco-based company, is making waves in the AI community with its latest release of open large language models (LLMs). These models, which come in various sizes ranging from 3 billion to 70 billion parameters, are not just another set of AI tools; they're a bold step towards w
Deep Cogito's LLMs Outperform Similar-Sized Models Using IDA
Deep Cogito, a San Francisco-based company, is making waves in the AI community with its latest release of open large language models (LLMs). These models, which come in various sizes ranging from 3 billion to 70 billion parameters, are not just another set of AI tools; they're a bold step towards w
 Anthropic's experimental AI Claude completes negotiations and transactions in e-commerce test
As artificial intelligence advances rapidly, Anthropic quietly rolled out an internal experiment called "Project Deal" last Friday, showcasing AI's potential in e-commerce. The experiment had its AI model Claude autonomously handle buying, selling, a
Anthropic's experimental AI Claude completes negotiations and transactions in e-commerce test
As artificial intelligence advances rapidly, Anthropic quietly rolled out an internal experiment called "Project Deal" last Friday, showcasing AI's potential in e-commerce. The experiment had its AI model Claude autonomously handle buying, selling, a

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

這研究讓我想到之前試著讓AI模擬古英文寫詩,結果產出簡直是現代口水歌混搭莎士比亞😂 不過說真的,如果連慣用語都學不好,那些用AI『續寫』經典文學的計畫會不會搞出穿越劇台詞啊?像是讓狄更斯角色突然說『老鐵666』之類的...
Любопытно, но ИИ действительно не справляется с историческими выражениями 😅 Может, это и к лучшему — пусть старые тексты останутся аутентичными, а не переписываются алгоритмами. Интересно, как это повлияет на цифровые гуманитарные науки?
歴史的な言語を再現するのが難しいなんて、AIにも苦手分野があるんだね。でも、これができるようになったら小説家のアシスタントとしてすごく役立ちそう。ディケンズの未完作品をAIで完成させる夢、まだ遠いのかな…😅
Fascinating read! I never thought about how tricky it must be for AI to nail old-timey language. Makes me wonder if we’ll ever see a bot write like Dickens without a ton of extra work. 🧐
I never thought AI would trip over old-timey phrases like this! Dickens’ unfinished novel is cool, but maybe we should let some mysteries stay unsolved. 🕰️
I find it fascinating that AI can't quite nail those old-timey phrases from Dickens' era. It’s like trying to teach a robot to talk like Shakespeare—cool idea, but super tricky! 🧠













