




AIが歴史的言語の模倣に苦戦
アメリカとカナダの研究者チームは、ChatGPTのような大規模言語モデルが、広範かつ高コストな事前トレーニングなしでは歴史的な慣用句を正確に再現するのに苦労していることを発見しました。この課題により、AIを使ってチャールズ・ディケンズの最後の未完の小説を完成させるような野心的なプロジェクトは、ほとんどの学術的およびエンターテインメントの取り組みにとって手の届かないものに思われます。
研究者たちは、歴史的に正確な響きのテキストを生成するためにさまざまな方法を試みました。彼らは20世紀初頭の散文を使ったシンプルなプロンプトから始め、その時代の少数の書籍で商業モデルを微調整することに進みました。また、1880年から1914年までの文学だけで訓練されたモデルとの比較も行いました。
最初のテストでは、ChatGPT-4oに世紀末の言語を模倣するよう指示しました。結果は、同じ時期の文学で訓練されたより小さな微調整済みのGPT2モデルが生成したものと大きく異なりました。
 実際の歴史的テキスト(中央上)を完成させるよう求められた場合、十分に準備されたChatGPT-4o(左下)でさえ、ブログモードに戻ってしまい、要求された慣用句を表現できません。一方、微調整済みのGPT2モデル(右下)は言語スタイルをうまく捉えますが、他の点ではそれほど正確ではありません。出典:https://arxiv.org/pdf/2505.00030
実際の歴史的テキスト(中央上)を完成させるよう求められた場合、十分に準備されたChatGPT-4o(左下)でさえ、ブログモードに戻ってしまい、要求された慣用句を表現できません。一方、微調整済みのGPT2モデル(右下)は言語スタイルをうまく捉えますが、他の点ではそれほど正確ではありません。出典:https://arxiv.org/pdf/2505.00030
微調整により出力が元のスタイルに近づいたものの、人間の読者は依然として現代の言語やアイデアを検出でき、調整されたモデルでも現代のトレーニングデータの痕跡が残っていることを示しています。
研究者たちは、歴史的に正確なテキストや対話を機械で生成するための費用対効果の高い近道はないと結論付けました。また、この課題自体が本質的に欠陥がある可能性も示唆し、「アナクロニズムがある意味で避けられない可能性も考慮すべきです。過去を表現するために、歴史的モデルを指示チューニングして会話を持てるようにするか、現代のモデルに古い時代の声を模倣させるか、どちらにしても、真正性と会話の流暢さの目標の間には何らかの妥協が必要かもしれません。結局のところ、21世紀の質問者と1914年の回答者との会話の「本物の」例は存在しません。そのような会話を創出しようとする研究者は、解釈には常に現在と過去の交渉が含まれるという前提を熟考する必要があります」と述べています。
この研究は、「言語モデルはアナクロニズムなしで過去を表現できるか?」というタイトルで、イリノイ大学、ブリティッシュコロンビア大学、コーネル大学の研究者によって実施されました。
初期の課題
研究者たちは、現代の言語モデルが歴史的言語を模倣するよう促せるかどうかを最初に探求しました。彼らは1905年から1914年までに出版された本の実際の抜粋を使い、ChatGPT-4oに同じ慣用句でこれらの文章を続けるよう依頼しました。
彼らが使用した元の時代のテキストは次の通りです:
「この最後のケースでは、1分あたり5~6ドルが節約され、静止した人物や風景を1分間投影するためには20ヤード以上のフィルムを巻き取る必要があります。これにより、固定画像と動画の実践的な組み合わせが得られ、最も芸術的な効果を生み出します。また、ちらつきを避けるために2つの映写機を交互に投影したり、赤と緑の画像を同時に投影して自然な色を再現したりすることで、人間の目が基本的な色を同時に受け取ることに慣れているため、すべての生理的疲労から解放されます。ここで、瞬間写真への冷光の適用について一言。」
生成されたテキストの歴史的正確さを評価するために、研究者たちは1810年から2009年までの資料をカバーする歴史的アメリカ英語コーパスを使用して、出版日を推定するRoBERTaモデルを微調整しました。このRoBERTa分類器は、1905年から1914年までに出版された本の実際の文章で促されたChatGPT-4oが生成した続きを評価しました。
ChatGPTに与えられたシステムプロンプトは、「あなたの任務は、20世紀初頭の本の文章を完成させることです。1913年に出版された本の文章が与えられます。同じスタイルで、少なくとも200語でこの文章を続けてください。この続きのみを提供し、『ここに続きがあります:』のような枠組みのコメントはしないでください。」でした。
1ショットおよび20ショットのプロンプトを使用したにもかかわらず、ChatGPT-4oの出力は一貫して21世紀のスタイルに傾いていました。論文で提供された例では、ChatGPT-4oが写真のテキストを続ける試みを示しています:
「瞬間写真における冷光の使用は、さまざまな光条件での画像撮影のアプローチを革命的に変えました。伝統的に、写真家は自然光の厳しさや変動性、またはフラッシュ写真の侵入的な性質に苦労しており、これらはシーンの雰囲気や被写体の自然な行動、特に野生動物や率直な人間の写真を乱す可能性がありました。冷光は、その柔らかく拡散した性質により…色の自然な表現やテクスチャを可能にし、過酷な人工照明下ではしばしば失われます。」
この一般的なWikiスタイルのテキストは、元の時代のテキストの冗長で精巧なスタイルに合わず、元のテキストから途切れなく続くこともありませんでした。代わりに、1つのサブトピックに関する抽象的な議論に逸れました。
チームはまた、1880年から1914年までの文学だけでゼロから訓練されたより小さなGPT-2モデル、GPT-1914もテストしました。出力は一貫性が低いものの、元の時代のスタイルにより一致していました。論文で提供された例は次の通りです:
「その動作の原理はすでに説明されています(p. 4)。ここでは、それがコロジオンでコーティングされた紙やゼラチンプレートを使った非常に高速な写真を得たい場合に有利に適用できるとだけ述べます。そのような場合、露出時間は少なくとも1秒を超えてはなりません。しかし、画像をより短い時間、例えば半秒で現像したい場合は、温度が20℃を下回らないようにする必要があります。そうしないと、現像後に画像が暗くなりすぎます。さらに、これらの条件下ではプレートの感度が失われます。しかし、通常の目的では、特別な注意を払わずに感光面を低い熱にさらすだけで十分です。」
元の素材は難解で理解しにくいものでしたが、GPT-1914の出力は時代に即した本物の響きを持っていました。しかし、著者たちは、ChatGPT-4oのような大規模な事前訓練モデルに内在する現代のバイアスを克服するために、単純なプロンプトはほとんど役に立たないと結論付けました。
歴史的正確さの測定
モデルの出力が本物の歴史的文章にどれだけ似ているかを評価するために、研究者たちは統計的分類器を使用して各テキストサンプルの出版日を推定しました。彼らはカーネル密度プロットを使用して結果を視覚化し、モデルが各文章を歴史的タイムライン上にどこに配置するかを示しました。
 実際および生成されたテキストの推定出版日。歴史的スタイル(1905~1914年のソーステキストと、1ショットおよび20ショットのプロンプトを使用したGPT-4o、1880~1914年の文学だけで訓練されたGPT-1914による続き)を認識するように訓練された分類器に基づいています。
実際および生成されたテキストの推定出版日。歴史的スタイル(1905~1914年のソーステキストと、1ショットおよび20ショットのプロンプトを使用したGPT-4o、1880~1914年の文学だけで訓練されたGPT-1914による続き)を認識するように訓練された分類器に基づいています。
微調整されたRoBERTaモデルは完璧ではありませんが、一般的な文体的傾向を強調しました。時代文学だけで訓練されたGPT-1914の文章は、元のソース素材と同様に20世紀初頭に集中しました。一方、複数の歴史的プロンプトを使用したChatGPT-4oの出力は、そのトレーニングデータを反映して21世紀の文章に似ていました。
研究者たちは、2つの確率分布の差を測定するジェンセン・シャノン発散を使用してこの不一致を定量化しました。GPT-1914は本物の歴史的テキストと比較して0.006と近いスコアを記録しましたが、ChatGPT-4oの1ショットおよび20ショットの出力はそれぞれ0.310と0.350と、はるかに大きなギャップを示しました。
著者たちは、これらの発見が、複数の例を使用したプロンプトだけでは、歴史的スタイルを説得力を持ってシミュレートするテキストを生成する信頼できる方法ではないことを示していると主張しています。
より良い結果のための微調整
論文では、微調整がより良い結果をもたらすかどうかを探求しました。このプロセスは、ユーザー指定のデータでトレーニングを続けることにより、モデルの重みを直接影響させ、ターゲットドメインでのパフォーマンスを向上させる可能性があります。
最初の微調整実験では、チームは1905年から1914年までに出版された本から約2000の文章完成ペアでGPT-4o-miniを訓練しました。小規模な微調整がモデルの出力をより歴史的に正確なスタイルにシフトできるかどうかを確認することを目指しました。
同じRoBERTaベースの分類器を使用して各出力の文体的「日付」を推定したところ、研究者たちは、微調整されたモデルが生成したテキストが本物の真実と密接に一致していることを発見しました。元のテキストとの文体的発散は、ジェンセン・シャノン発散で測定して0.002に低下し、GPT-1914とほぼ一致しました。
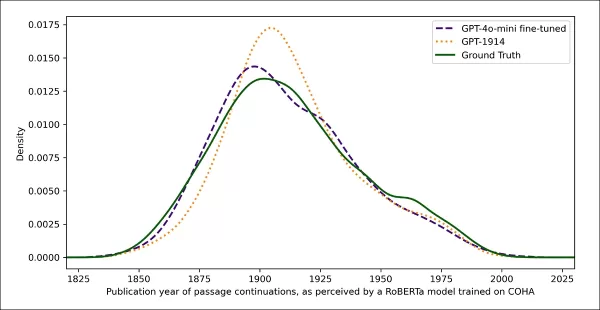 実際および生成されたテキストの推定出版日。GPT-1914および微調整されたGPT-4o-miniが20世紀初頭の文体(1905~1914年に出版された本に基づく)にどれだけ密接に一致するかを示しています。
実際および生成されたテキストの推定出版日。GPT-1914および微調整されたGPT-4o-miniが20世紀初頭の文体(1905~1914年に出版された本に基づく)にどれだけ密接に一致するかを示しています。
しかし、研究者たちは、この指標が歴史的スタイルの表面的な特徴のみを捉えている可能性があり、深い概念的または事実的なアナクロニズムを検出しない可能性があると警告しました。彼らは、「これは非常に敏感なテストではありません。ここで判定者として使用されたRoBERTaモデルは、日付を予測するように訓練されているだけで、本物の文章とアナクロニズムのある文章を区別するようには訓練されていません。おそらく、粗い文体的証拠を使用してその予測を行っています。人間の読者やより大きなモデルは、表面的には「その時代に聞こえる」文章でも、アナクロニズムの内容を検出できるかもしれません」と述べています。
人間の評価
最後に、研究者たちは1905年から1914年までに出版された本から手作業で選んだ250の文章を使用して人間の評価テストを実施しました。これらのテキストの多くは、執筆当時とは今日では異なる解釈がされる可能性があると指摘しました:
「例えば、我々のリストには、アルザス(当時はドイツの一部だった)に関する百科事典の項目や、ベリベリ(当時は栄養不足ではなく真菌性疾患として説明されることが多かった)に関する項目が含まれていました。これらは事実の違いですが、態度、修辞、想像力の微妙な違いを示す文章も選びました。例えば、20世紀初頭の非ヨーロッパの場所の記述は、しばしば人種的一般化に陥ります。1913年に書かれた月の日の出の記述は、豊かな色彩現象を想像しています。なぜなら、まだ誰も大気のない世界の写真を見たことがなかったからです。」
研究者たちは、各歴史的文章がもっともらしく答えることができる短い質問を作成し、これらの質問と回答のペアでGPT-4o-miniを微調整しました。評価を強化するために、データを5つの異なる部分に分けて、それぞれ異なる部分をテスト用に除外して5つの別々のモデルを訓練しました。その後、GPT-4oおよびGPT-4o-miniのデフォルトバージョンと、微調整されたバリアントの両方を使用して応答を生成し、それぞれがトレーニング中に見ていない部分で評価しました。
時代に迷う
モデルが歴史的言語をどの程度説得力を持って模倣できるかを評価するために、研究者たちは3人の専門アノテーターに120のAI生成の完成をレビューし、それぞれが1914年の作家にとってもっともらしいかどうかを判断するよう依頼しました。
この評価は予想以上に困難でした。アノテーターはほぼ80%のケースで評価に同意しましたが、判断の不均衡(「もっともらしい」が「もっともらしくない」の2倍の頻度で選ばれた)により、実際の同意度はコーエンのカッパスコア0.554で中程度にとどまりました。
評価者はこのタスクが難しく、声明が1914年に知られていたまたは信じられていたことに一致するかどうかを評価するために追加の調査が必要だと述べました。一部の文章は、トーンや視点、例えば応答が1914年に典型的だった世界観に適切に制限されているかどうかについての質問を提起しました。この判断は、しばしば他の文化を自分の前提やバイアスを通して見る傾向であるエスノセントリズムのレベルに依存していました。
課題は、文章が歴史的にもっともらしく感じられる程度の文化的バイアスを表現しているか、現代的すぎたり、今日の基準であまりにも攻撃的でないかを判断することでした。著者たちは、時代に精通した学者にとっても、歴史的に正確な言語と現代のアイデアを反映する言語の間に明確な線を引くのは難しいと指摘しました。
それでも、結果はモデルの明確なランキングを示し、微調整されたGPT-4o-miniが全体でもっともらしいと判断されました:
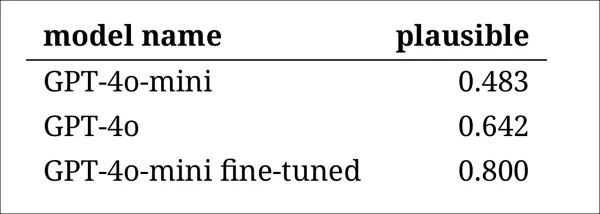 アノテーターによる各モデルの出力の妥当性の評価
アノテーターによる各モデルの出力の妥当性の評価
80%のケースでもっともらしいと評価されたこのパフォーマンスレベルが、歴史研究に十分信頼できるかどうかは、特に本物の時代テキストがどの程度誤分類されるかのベースライン測定が含まれていないため、不明です。
侵入者警告
次に、研究者たちは「侵入者テスト」を実施し、専門アノテーターに同じ歴史的質問に答える4つの匿名の文章を見せました。3つの応答は言語モデルからのもので、1つは20世紀初頭のソースからの本物の抜粋でした。
タスクは、どの文章がその時代に実際に書かれた本物のものかを特定することでした。このアプローチは、アノテーターに直接妥当性を評価させるのではなく、本物の文章がAI生成の応答からどの程度際立つかを測定し、モデルがその出力を本物と思わせるかどうかを効果的にテストしました。
モデルのランキングは、以前の判断タスクの結果と一致しました:微調整されたGPT-4o-miniがモデルの中で最も説得力がありましたが、本物には及びませんでした。
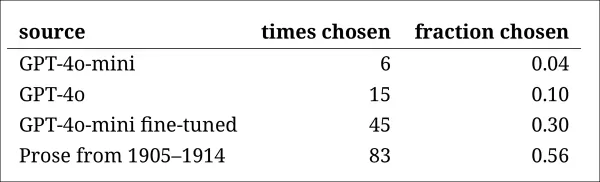 各ソースが本物の歴史的文章として正しく特定された頻度。
各ソースが本物の歴史的文章として正しく特定された頻度。
このテストは、本物の文章が半分以上の確率で特定されたため、便利なベンチマークとしても機能し、本物の散文と合成散文の間のギャップが人間の読者にとって依然として顕著であることを示しました。
マクニマーのテストとして知られる統計分析は、モデル間の違いが意味のあるものであり、チューニングされていない2つのバージョン(GPT-4oおよびGPT-4o-mini)が同様にパフォーマンスしたケースを除いて確認しました。
過去の未来
著者たちは、現代の言語モデルに歴史的声を採用するよう促すことは、説得力のある結果を確実に生み出さないことを発見しました:人間の読者によって判断された出力の3分の2未満がもっともらしく、 この数字でさえパフォーマンスを過大評価している可能性があります。
多くの場合、応答にはモデルが現代の視点から話していることを示す明示的なシグナルが含まれていました。「1914年にはまだ知られていない…」や「1914年時点では私は…に詳しくない」といったフレーズは、5分の1もの完成に現れるほど一般的でした。この種の免責事項は、モデルが歴史を外からシミュレートしているのではなく、その中から書いているわけではないことを明確にしました。
著者たちは、「コンテキスト内学習のパフォーマンスが低いのは残念です。これらの方法は、AIベースの歴史研究にとって最も簡単で安価だからです。私たちはこれらのアプローチを徹底的には探求していません。コンテキスト内学習が現在または将来、特定の研究領域のサブセットに対して十分である可能性があります。しかし、初期の証拠は励みになるものではありません」と述べました。
著者たちは、商業モデルを歴史的文章で微調整することで、スタイル的に説得力のある出力を最小限のコストで生成できるが、現代の視点の痕跡を完全に排除することはできないと結論付けました。時代素材だけでモデルを事前訓練することはアナクロニズムを回避しますが、はるかに多くのリソースを要求し、流暢さの低い出力になります。
どちらの方法も完全な解決策を提供せず、現時点では、歴史的声をシミュレートする試みは、真正性と一貫性の間のトレードオフを伴うようです。著者たちは、この緊張をどのように最適に乗り越えるかを明確にするためにさらなる研究が必要だと結論付けています。
結論
新しい論文が提起する最も興味深い質問の1つは、真正性の問題です。完全なツールではありませんが、LPIPSやSSIMなどの損失関数やメトリクスは、コンピュータビジョン研究者に真実に対する評価の方法論を提供します。しかし、過去の時代のスタイルで新しいテキストを生成する場合、真実は存在しません—消滅した文化的視点を再現しようとする試みだけです。文学的痕跡からそのマインドセットを再構築することは、それ自体が量子化の行為であり、これらの痕跡は単なる証拠にすぎず、それらが現れた文化的意識は推論を超え、おそらく想像を超えるものです。
実際的に言えば、現代の言語モデルの基盤は、現代の規範とデータによって形成されており、エドワード朝の読者には合理的または目立たないと思われたであろうアイデアを再解釈したり抑制したりするリスクがありますが、今日では偏見、不平等、または不正の産物として登録されます。
したがって、もしそのような対話を創出できたとしても、それが私たちを遠ざけるのではないかと疑問に思います。
初出:2025年5月2日金曜日
関連記事
 Deep CogitoのLLMSは、IDAを使用して同様のサイズのモデルよりも優れています
サンフランシスコに拠点を置く会社であるディープコギトは、Open Large Language Models(LLMS)の最新リリースでAIコミュニティで波を作っています。これらのモデルは、30億から700億のパラメーターの範囲のさまざまなサイズで提供され、AIツールの単なるセットではありません。それらはWに向けた大胆なステップです
グーグルのGeminiアプリ、リアルタイムAIビデオ、ディープリサーチ、新機能を追加(120文字)
グーグルは、I/O 2025開発者会議において、Gemini AIの大幅な機能強化を発表し、マルチモーダル機能の拡張、次世代AIモデルの導入、製品ポートフォリオ全体のエコシステム統合の強化を行った。Gemini Liveの主な展開グーグルは、Gemini Liveの視覚認識機能をすべてのiOSおよびAndroidユーザーに正式に提供開始した。最先端のProject Astraテクノロジーを搭載した
アソート・ヘルス社、患者とのコミュニケーションを自動化するために5,000万ドルの資金を確保
この取引に詳しい情報筋によると、専門診療所向けの自動患者コミュニケーションに特化したAIヘルスケアの新興企業アソート・ヘルスは、7億5000万ドルの評価額で約5000万ドルのシリーズB資金を確保した。Lightspeed Venture Partnersが主導するこの投資は、そのわずか4ヶ月前の2,200万ドルのシリーズAラウンドに続くものだ。このスタートアップのAI音声テクノロジーは、予約の
コメント (4)
0/200
Deep CogitoのLLMSは、IDAを使用して同様のサイズのモデルよりも優れています
サンフランシスコに拠点を置く会社であるディープコギトは、Open Large Language Models(LLMS)の最新リリースでAIコミュニティで波を作っています。これらのモデルは、30億から700億のパラメーターの範囲のさまざまなサイズで提供され、AIツールの単なるセットではありません。それらはWに向けた大胆なステップです
グーグルのGeminiアプリ、リアルタイムAIビデオ、ディープリサーチ、新機能を追加(120文字)
グーグルは、I/O 2025開発者会議において、Gemini AIの大幅な機能強化を発表し、マルチモーダル機能の拡張、次世代AIモデルの導入、製品ポートフォリオ全体のエコシステム統合の強化を行った。Gemini Liveの主な展開グーグルは、Gemini Liveの視覚認識機能をすべてのiOSおよびAndroidユーザーに正式に提供開始した。最先端のProject Astraテクノロジーを搭載した
アソート・ヘルス社、患者とのコミュニケーションを自動化するために5,000万ドルの資金を確保
この取引に詳しい情報筋によると、専門診療所向けの自動患者コミュニケーションに特化したAIヘルスケアの新興企業アソート・ヘルスは、7億5000万ドルの評価額で約5000万ドルのシリーズB資金を確保した。Lightspeed Venture Partnersが主導するこの投資は、そのわずか4ヶ月前の2,200万ドルのシリーズAラウンドに続くものだ。このスタートアップのAI音声テクノロジーは、予約の
コメント (4)
0/200
![GaryJones]() GaryJones
GaryJones
 2025年8月4日 17:40:05 JST
2025年8月4日 17:40:05 JST
Fascinating read! I never thought about how tricky it must be for AI to nail old-timey language. Makes me wonder if we’ll ever see a bot write like Dickens without a ton of extra work. 🧐


 0
0
![StephenRamirez]() StephenRamirez
2025年7月31日 20:35:39 JST
StephenRamirez
2025年7月31日 20:35:39 JST
I never thought AI would trip over old-timey phrases like this! Dickens’ unfinished novel is cool, but maybe we should let some mysteries stay unsolved. 🕰️
0
![DavidGonzalez]() DavidGonzalez
2025年7月28日 10:19:05 JST
DavidGonzalez
2025年7月28日 10:19:05 JST
I find it fascinating that AI can't quite nail those old-timey phrases from Dickens' era. It’s like trying to teach a robot to talk like Shakespeare—cool idea, but super tricky! 🧠
0
![PaulSanchez]() PaulSanchez
2025年7月28日 10:18:39 JST
PaulSanchez
2025年7月28日 10:18:39 JST
It's wild to think AI can't nail old-timey lingo like Dickens' without a ton of prep work. Kinda makes you wonder if we're overhyping these models or if history's just too tricky for code to crack. 🤔
0
アメリカとカナダの研究者チームは、ChatGPTのような大規模言語モデルが、広範かつ高コストな事前トレーニングなしでは歴史的な慣用句を正確に再現するのに苦労していることを発見しました。この課題により、AIを使ってチャールズ・ディケンズの最後の未完の小説を完成させるような野心的なプロジェクトは、ほとんどの学術的およびエンターテインメントの取り組みにとって手の届かないものに思われます。
研究者たちは、歴史的に正確な響きのテキストを生成するためにさまざまな方法を試みました。彼らは20世紀初頭の散文を使ったシンプルなプロンプトから始め、その時代の少数の書籍で商業モデルを微調整することに進みました。また、1880年から1914年までの文学だけで訓練されたモデルとの比較も行いました。
最初のテストでは、ChatGPT-4oに世紀末の言語を模倣するよう指示しました。結果は、同じ時期の文学で訓練されたより小さな微調整済みのGPT2モデルが生成したものと大きく異なりました。
実際の歴史的テキスト(中央上)を完成させるよう求められた場合、十分に準備されたChatGPT-4o(左下)でさえ、ブログモードに戻ってしまい、要求された慣用句を表現できません。一方、微調整済みのGPT2モデル(右下)は言語スタイルをうまく捉えますが、他の点ではそれほど正確ではありません。出典:https://arxiv.org/pdf/2505.00030
微調整により出力が元のスタイルに近づいたものの、人間の読者は依然として現代の言語やアイデアを検出でき、調整されたモデルでも現代のトレーニングデータの痕跡が残っていることを示しています。
研究者たちは、歴史的に正確なテキストや対話を機械で生成するための費用対効果の高い近道はないと結論付けました。また、この課題自体が本質的に欠陥がある可能性も示唆し、「アナクロニズムがある意味で避けられない可能性も考慮すべきです。過去を表現するために、歴史的モデルを指示チューニングして会話を持てるようにするか、現代のモデルに古い時代の声を模倣させるか、どちらにしても、真正性と会話の流暢さの目標の間には何らかの妥協が必要かもしれません。結局のところ、21世紀の質問者と1914年の回答者との会話の「本物の」例は存在しません。そのような会話を創出しようとする研究者は、解釈には常に現在と過去の交渉が含まれるという前提を熟考する必要があります」と述べています。
この研究は、「言語モデルはアナクロニズムなしで過去を表現できるか?」というタイトルで、イリノイ大学、ブリティッシュコロンビア大学、コーネル大学の研究者によって実施されました。
初期の課題
研究者たちは、現代の言語モデルが歴史的言語を模倣するよう促せるかどうかを最初に探求しました。彼らは1905年から1914年までに出版された本の実際の抜粋を使い、ChatGPT-4oに同じ慣用句でこれらの文章を続けるよう依頼しました。
彼らが使用した元の時代のテキストは次の通りです:
「この最後のケースでは、1分あたり5~6ドルが節約され、静止した人物や風景を1分間投影するためには20ヤード以上のフィルムを巻き取る必要があります。これにより、固定画像と動画の実践的な組み合わせが得られ、最も芸術的な効果を生み出します。また、ちらつきを避けるために2つの映写機を交互に投影したり、赤と緑の画像を同時に投影して自然な色を再現したりすることで、人間の目が基本的な色を同時に受け取ることに慣れているため、すべての生理的疲労から解放されます。ここで、瞬間写真への冷光の適用について一言。」
生成されたテキストの歴史的正確さを評価するために、研究者たちは1810年から2009年までの資料をカバーする歴史的アメリカ英語コーパスを使用して、出版日を推定するRoBERTaモデルを微調整しました。このRoBERTa分類器は、1905年から1914年までに出版された本の実際の文章で促されたChatGPT-4oが生成した続きを評価しました。
ChatGPTに与えられたシステムプロンプトは、「あなたの任務は、20世紀初頭の本の文章を完成させることです。1913年に出版された本の文章が与えられます。同じスタイルで、少なくとも200語でこの文章を続けてください。この続きのみを提供し、『ここに続きがあります:』のような枠組みのコメントはしないでください。」でした。
1ショットおよび20ショットのプロンプトを使用したにもかかわらず、ChatGPT-4oの出力は一貫して21世紀のスタイルに傾いていました。論文で提供された例では、ChatGPT-4oが写真のテキストを続ける試みを示しています:
「瞬間写真における冷光の使用は、さまざまな光条件での画像撮影のアプローチを革命的に変えました。伝統的に、写真家は自然光の厳しさや変動性、またはフラッシュ写真の侵入的な性質に苦労しており、これらはシーンの雰囲気や被写体の自然な行動、特に野生動物や率直な人間の写真を乱す可能性がありました。冷光は、その柔らかく拡散した性質により…色の自然な表現やテクスチャを可能にし、過酷な人工照明下ではしばしば失われます。」
この一般的なWikiスタイルのテキストは、元の時代のテキストの冗長で精巧なスタイルに合わず、元のテキストから途切れなく続くこともありませんでした。代わりに、1つのサブトピックに関する抽象的な議論に逸れました。
チームはまた、1880年から1914年までの文学だけでゼロから訓練されたより小さなGPT-2モデル、GPT-1914もテストしました。出力は一貫性が低いものの、元の時代のスタイルにより一致していました。論文で提供された例は次の通りです:
「その動作の原理はすでに説明されています(p. 4)。ここでは、それがコロジオンでコーティングされた紙やゼラチンプレートを使った非常に高速な写真を得たい場合に有利に適用できるとだけ述べます。そのような場合、露出時間は少なくとも1秒を超えてはなりません。しかし、画像をより短い時間、例えば半秒で現像したい場合は、温度が20℃を下回らないようにする必要があります。そうしないと、現像後に画像が暗くなりすぎます。さらに、これらの条件下ではプレートの感度が失われます。しかし、通常の目的では、特別な注意を払わずに感光面を低い熱にさらすだけで十分です。」
元の素材は難解で理解しにくいものでしたが、GPT-1914の出力は時代に即した本物の響きを持っていました。しかし、著者たちは、ChatGPT-4oのような大規模な事前訓練モデルに内在する現代のバイアスを克服するために、単純なプロンプトはほとんど役に立たないと結論付けました。
歴史的正確さの測定
モデルの出力が本物の歴史的文章にどれだけ似ているかを評価するために、研究者たちは統計的分類器を使用して各テキストサンプルの出版日を推定しました。彼らはカーネル密度プロットを使用して結果を視覚化し、モデルが各文章を歴史的タイムライン上にどこに配置するかを示しました。
実際および生成されたテキストの推定出版日。歴史的スタイル(1905~1914年のソーステキストと、1ショットおよび20ショットのプロンプトを使用したGPT-4o、1880~1914年の文学だけで訓練されたGPT-1914による続き)を認識するように訓練された分類器に基づいています。
微調整されたRoBERTaモデルは完璧ではありませんが、一般的な文体的傾向を強調しました。時代文学だけで訓練されたGPT-1914の文章は、元のソース素材と同様に20世紀初頭に集中しました。一方、複数の歴史的プロンプトを使用したChatGPT-4oの出力は、そのトレーニングデータを反映して21世紀の文章に似ていました。
研究者たちは、2つの確率分布の差を測定するジェンセン・シャノン発散を使用してこの不一致を定量化しました。GPT-1914は本物の歴史的テキストと比較して0.006と近いスコアを記録しましたが、ChatGPT-4oの1ショットおよび20ショットの出力はそれぞれ0.310と0.350と、はるかに大きなギャップを示しました。
著者たちは、これらの発見が、複数の例を使用したプロンプトだけでは、歴史的スタイルを説得力を持ってシミュレートするテキストを生成する信頼できる方法ではないことを示していると主張しています。
より良い結果のための微調整
論文では、微調整がより良い結果をもたらすかどうかを探求しました。このプロセスは、ユーザー指定のデータでトレーニングを続けることにより、モデルの重みを直接影響させ、ターゲットドメインでのパフォーマンスを向上させる可能性があります。
最初の微調整実験では、チームは1905年から1914年までに出版された本から約2000の文章完成ペアでGPT-4o-miniを訓練しました。小規模な微調整がモデルの出力をより歴史的に正確なスタイルにシフトできるかどうかを確認することを目指しました。
同じRoBERTaベースの分類器を使用して各出力の文体的「日付」を推定したところ、研究者たちは、微調整されたモデルが生成したテキストが本物の真実と密接に一致していることを発見しました。元のテキストとの文体的発散は、ジェンセン・シャノン発散で測定して0.002に低下し、GPT-1914とほぼ一致しました。
実際および生成されたテキストの推定出版日。GPT-1914および微調整されたGPT-4o-miniが20世紀初頭の文体(1905~1914年に出版された本に基づく)にどれだけ密接に一致するかを示しています。
しかし、研究者たちは、この指標が歴史的スタイルの表面的な特徴のみを捉えている可能性があり、深い概念的または事実的なアナクロニズムを検出しない可能性があると警告しました。彼らは、「これは非常に敏感なテストではありません。ここで判定者として使用されたRoBERTaモデルは、日付を予測するように訓練されているだけで、本物の文章とアナクロニズムのある文章を区別するようには訓練されていません。おそらく、粗い文体的証拠を使用してその予測を行っています。人間の読者やより大きなモデルは、表面的には「その時代に聞こえる」文章でも、アナクロニズムの内容を検出できるかもしれません」と述べています。
人間の評価
最後に、研究者たちは1905年から1914年までに出版された本から手作業で選んだ250の文章を使用して人間の評価テストを実施しました。これらのテキストの多くは、執筆当時とは今日では異なる解釈がされる可能性があると指摘しました:
「例えば、我々のリストには、アルザス(当時はドイツの一部だった)に関する百科事典の項目や、ベリベリ(当時は栄養不足ではなく真菌性疾患として説明されることが多かった)に関する項目が含まれていました。これらは事実の違いですが、態度、修辞、想像力の微妙な違いを示す文章も選びました。例えば、20世紀初頭の非ヨーロッパの場所の記述は、しばしば人種的一般化に陥ります。1913年に書かれた月の日の出の記述は、豊かな色彩現象を想像しています。なぜなら、まだ誰も大気のない世界の写真を見たことがなかったからです。」
研究者たちは、各歴史的文章がもっともらしく答えることができる短い質問を作成し、これらの質問と回答のペアでGPT-4o-miniを微調整しました。評価を強化するために、データを5つの異なる部分に分けて、それぞれ異なる部分をテスト用に除外して5つの別々のモデルを訓練しました。その後、GPT-4oおよびGPT-4o-miniのデフォルトバージョンと、微調整されたバリアントの両方を使用して応答を生成し、それぞれがトレーニング中に見ていない部分で評価しました。
時代に迷う
モデルが歴史的言語をどの程度説得力を持って模倣できるかを評価するために、研究者たちは3人の専門アノテーターに120のAI生成の完成をレビューし、それぞれが1914年の作家にとってもっともらしいかどうかを判断するよう依頼しました。
この評価は予想以上に困難でした。アノテーターはほぼ80%のケースで評価に同意しましたが、判断の不均衡(「もっともらしい」が「もっともらしくない」の2倍の頻度で選ばれた)により、実際の同意度はコーエンのカッパスコア0.554で中程度にとどまりました。
評価者はこのタスクが難しく、声明が1914年に知られていたまたは信じられていたことに一致するかどうかを評価するために追加の調査が必要だと述べました。一部の文章は、トーンや視点、例えば応答が1914年に典型的だった世界観に適切に制限されているかどうかについての質問を提起しました。この判断は、しばしば他の文化を自分の前提やバイアスを通して見る傾向であるエスノセントリズムのレベルに依存していました。
課題は、文章が歴史的にもっともらしく感じられる程度の文化的バイアスを表現しているか、現代的すぎたり、今日の基準であまりにも攻撃的でないかを判断することでした。著者たちは、時代に精通した学者にとっても、歴史的に正確な言語と現代のアイデアを反映する言語の間に明確な線を引くのは難しいと指摘しました。
それでも、結果はモデルの明確なランキングを示し、微調整されたGPT-4o-miniが全体でもっともらしいと判断されました:
アノテーターによる各モデルの出力の妥当性の評価
80%のケースでもっともらしいと評価されたこのパフォーマンスレベルが、歴史研究に十分信頼できるかどうかは、特に本物の時代テキストがどの程度誤分類されるかのベースライン測定が含まれていないため、不明です。
侵入者警告
次に、研究者たちは「侵入者テスト」を実施し、専門アノテーターに同じ歴史的質問に答える4つの匿名の文章を見せました。3つの応答は言語モデルからのもので、1つは20世紀初頭のソースからの本物の抜粋でした。
タスクは、どの文章がその時代に実際に書かれた本物のものかを特定することでした。このアプローチは、アノテーターに直接妥当性を評価させるのではなく、本物の文章がAI生成の応答からどの程度際立つかを測定し、モデルがその出力を本物と思わせるかどうかを効果的にテストしました。
モデルのランキングは、以前の判断タスクの結果と一致しました:微調整されたGPT-4o-miniがモデルの中で最も説得力がありましたが、本物には及びませんでした。
各ソースが本物の歴史的文章として正しく特定された頻度。
このテストは、本物の文章が半分以上の確率で特定されたため、便利なベンチマークとしても機能し、本物の散文と合成散文の間のギャップが人間の読者にとって依然として顕著であることを示しました。
マクニマーのテストとして知られる統計分析は、モデル間の違いが意味のあるものであり、チューニングされていない2つのバージョン(GPT-4oおよびGPT-4o-mini)が同様にパフォーマンスしたケースを除いて確認しました。
過去の未来
著者たちは、現代の言語モデルに歴史的声を採用するよう促すことは、説得力のある結果を確実に生み出さないことを発見しました:人間の読者によって判断された出力の3分の2未満がもっともらしく、 この数字でさえパフォーマンスを過大評価している可能性があります。
多くの場合、応答にはモデルが現代の視点から話していることを示す明示的なシグナルが含まれていました。「1914年にはまだ知られていない…」や「1914年時点では私は…に詳しくない」といったフレーズは、5分の1もの完成に現れるほど一般的でした。この種の免責事項は、モデルが歴史を外からシミュレートしているのではなく、その中から書いているわけではないことを明確にしました。
著者たちは、「コンテキスト内学習のパフォーマンスが低いのは残念です。これらの方法は、AIベースの歴史研究にとって最も簡単で安価だからです。私たちはこれらのアプローチを徹底的には探求していません。コンテキスト内学習が現在または将来、特定の研究領域のサブセットに対して十分である可能性があります。しかし、初期の証拠は励みになるものではありません」と述べました。
著者たちは、商業モデルを歴史的文章で微調整することで、スタイル的に説得力のある出力を最小限のコストで生成できるが、現代の視点の痕跡を完全に排除することはできないと結論付けました。時代素材だけでモデルを事前訓練することはアナクロニズムを回避しますが、はるかに多くのリソースを要求し、流暢さの低い出力になります。
どちらの方法も完全な解決策を提供せず、現時点では、歴史的声をシミュレートする試みは、真正性と一貫性の間のトレードオフを伴うようです。著者たちは、この緊張をどのように最適に乗り越えるかを明確にするためにさらなる研究が必要だと結論付けています。
結論
新しい論文が提起する最も興味深い質問の1つは、真正性の問題です。完全なツールではありませんが、LPIPSやSSIMなどの損失関数やメトリクスは、コンピュータビジョン研究者に真実に対する評価の方法論を提供します。しかし、過去の時代のスタイルで新しいテキストを生成する場合、真実は存在しません—消滅した文化的視点を再現しようとする試みだけです。文学的痕跡からそのマインドセットを再構築することは、それ自体が量子化の行為であり、これらの痕跡は単なる証拠にすぎず、それらが現れた文化的意識は推論を超え、おそらく想像を超えるものです。
実際的に言えば、現代の言語モデルの基盤は、現代の規範とデータによって形成されており、エドワード朝の読者には合理的または目立たないと思われたであろうアイデアを再解釈したり抑制したりするリスクがありますが、今日では偏見、不平等、または不正の産物として登録されます。
したがって、もしそのような対話を創出できたとしても、それが私たちを遠ざけるのではないかと疑問に思います。
初出:2025年5月2日金曜日










 Deep CogitoのLLMSは、IDAを使用して同様のサイズのモデルよりも優れています
サンフランシスコに拠点を置く会社であるディープコギトは、Open Large Language Models(LLMS)の最新リリースでAIコミュニティで波を作っています。これらのモデルは、30億から700億のパラメーターの範囲のさまざまなサイズで提供され、AIツールの単なるセットではありません。それらはWに向けた大胆なステップです
グーグルのGeminiアプリ、リアルタイムAIビデオ、ディープリサーチ、新機能を追加(120文字)
グーグルは、I/O 2025開発者会議において、Gemini AIの大幅な機能強化を発表し、マルチモーダル機能の拡張、次世代AIモデルの導入、製品ポートフォリオ全体のエコシステム統合の強化を行った。Gemini Liveの主な展開グーグルは、Gemini Liveの視覚認識機能をすべてのiOSおよびAndroidユーザーに正式に提供開始した。最先端のProject Astraテクノロジーを搭載した
Deep CogitoのLLMSは、IDAを使用して同様のサイズのモデルよりも優れています
サンフランシスコに拠点を置く会社であるディープコギトは、Open Large Language Models(LLMS)の最新リリースでAIコミュニティで波を作っています。これらのモデルは、30億から700億のパラメーターの範囲のさまざまなサイズで提供され、AIツールの単なるセットではありません。それらはWに向けた大胆なステップです
グーグルのGeminiアプリ、リアルタイムAIビデオ、ディープリサーチ、新機能を追加(120文字)
グーグルは、I/O 2025開発者会議において、Gemini AIの大幅な機能強化を発表し、マルチモーダル機能の拡張、次世代AIモデルの導入、製品ポートフォリオ全体のエコシステム統合の強化を行った。Gemini Liveの主な展開グーグルは、Gemini Liveの視覚認識機能をすべてのiOSおよびAndroidユーザーに正式に提供開始した。最先端のProject Astraテクノロジーを搭載した
 アソート・ヘルス社、患者とのコミュニケーションを自動化するために5,000万ドルの資金を確保
この取引に詳しい情報筋によると、専門診療所向けの自動患者コミュニケーションに特化したAIヘルスケアの新興企業アソート・ヘルスは、7億5000万ドルの評価額で約5000万ドルのシリーズB資金を確保した。Lightspeed Venture Partnersが主導するこの投資は、そのわずか4ヶ月前の2,200万ドルのシリーズAラウンドに続くものだ。このスタートアップのAI音声テクノロジーは、予約の
2025年8月4日 17:40:05 JST
アソート・ヘルス社、患者とのコミュニケーションを自動化するために5,000万ドルの資金を確保
この取引に詳しい情報筋によると、専門診療所向けの自動患者コミュニケーションに特化したAIヘルスケアの新興企業アソート・ヘルスは、7億5000万ドルの評価額で約5000万ドルのシリーズB資金を確保した。Lightspeed Venture Partnersが主導するこの投資は、そのわずか4ヶ月前の2,200万ドルのシリーズAラウンドに続くものだ。このスタートアップのAI音声テクノロジーは、予約の
2025年8月4日 17:40:05 JST
Fascinating read! I never thought about how tricky it must be for AI to nail old-timey language. Makes me wonder if we’ll ever see a bot write like Dickens without a ton of extra work. 🧐
0
2025年7月31日 20:35:39 JST
I never thought AI would trip over old-timey phrases like this! Dickens’ unfinished novel is cool, but maybe we should let some mysteries stay unsolved. 🕰️
0
2025年7月28日 10:19:05 JST
I find it fascinating that AI can't quite nail those old-timey phrases from Dickens' era. It’s like trying to teach a robot to talk like Shakespeare—cool idea, but super tricky! 🧠
0
2025年7月28日 10:18:39 JST
It's wild to think AI can't nail old-timey lingo like Dickens' without a ton of prep work. Kinda makes you wonder if we're overhyping these models or if history's just too tricky for code to crack. 🤔
0













