
















 首页
首页AI难以模仿历史语言
来自美国和加拿大的研究团队发现,像ChatGPT这样的大型语言模型在未经广泛且昂贵的预训练情况下,难以准确复制历史习语。这一挑战使得使用AI完成查尔斯·狄更斯最后未完成小说等雄心勃勃的项目对大多数学术和娱乐工作来说似乎遥不可及。
研究人员尝试了多种方法生成听起来具有历史准确性的文本。他们从使用20世纪初的散文进行简单提示开始,逐步对一个商业模型进行微调,使用那个时代的一小部分书籍。他们还将这些结果与仅在1880年至1914年的文学作品上训练的模型进行比较。
在第一次测试中,他们指示ChatGPT-4o模仿世纪末时期的语言。结果与在同一时期文学上训练的较小规模、微调过的GPT2模型产生的结果有显著差异。
 被要求完成真实的歷史文本(上中),即使是经过良好预处理的ChatGPT-4o(左下)也无法避免滑回‘博客’模式,未能呈现要求的习语。相比之下,微调的GPT2模型(右下)很好地捕捉了语言风格,但在其他方面不够准确。来源:https://arxiv.org/pdf/2505.00030
被要求完成真实的歷史文本(上中),即使是经过良好预处理的ChatGPT-4o(左下)也无法避免滑回‘博客’模式,未能呈现要求的习语。相比之下,微调的GPT2模型(右下)很好地捕捉了语言风格,但在其他方面不够准确。来源:https://arxiv.org/pdf/2505.00030
尽管微调提高了输出与原始风格的相似度,但人类读者仍能察觉现代语言或观念,表明即使调整后的模型仍保留当代训练数据的痕迹。
研究人员得出结论,没有成本效益高的捷径来生成历史准确的文本或对话。他们还指出,这一挑战本身可能存在根本性缺陷,称:“我们还应考虑时代错误在某种程度上可能是不可避免的。无论我们是通过指令调整历史模型使其能进行对话,还是教当代模型模仿较早的时期,在真实性和对话流畅性的目标之间可能需要某种妥协。毕竟,没有1914年的回答者与21世纪提问者之间的‘真实’对话示例。试图创建此类对话的研究人员需要反思,解释总是涉及现在与过去之间的协商。”
这项研究题为“语言模型能否无时代错误地呈现过去?”,由伊利诺伊大学、不列颠哥伦比亚大学和康奈尔大学的研究人员进行。
初期挑战
研究人员最初探索现代语言模型是否能被提示模仿历史语言。他们使用了1905年至1914年间出版的书籍中的真实摘录,要求ChatGPT-4o以相同习语继续这些段落。
他们使用的原始时期文本为:
“在最后一种情况下,每分钟可节省大约五六美元,因为需要放映超过二十码的胶片,以便在一分钟内投影出静止或风景中的人物。因此,获得了固定和移动画面的实用组合,产生了最艺术的效果。这还使我们能够使用两台放映机交替放映以避免闪烁,或同时放映红色和绿色图像并再现自然颜色,从而缓解人眼因习惯同时接收基本颜色而产生的所有生理疲劳。现在谈谈冷光在瞬时摄影中的应用。”
为评估生成文本的历史准确性,研究人员微调了一个RoBERTa模型以估计出版日期,使用1810年至2009年的历史美国英语语料库子集。该RoBERTa分类器评估了ChatGPT-4o在1905年至1914年间出版的书籍真实段落提示下生成的续写。
给ChatGPT的系统提示为:“你的任务是续写20世纪初书籍的段落。你将收到1913年出版的书籍中的一段。以相同风格续写至少200字,仅提供续写内容;不要添加任何框架性说明,如‘以下是续写:’。”
尽管使用了单次和20次提示,ChatGPT-4o的输出始终偏向21世纪风格。论文中提供的一个例子显示了ChatGPT-4o尝试续写摄影文本:
“冷光在瞬时摄影中的使用彻底改变了在不同光线条件下捕捉图像的方法。传统上,摄影师们难以应对自然光的苛刻和变化,或闪光摄影的侵入性,这可能干扰场景氛围或拍摄对象的自然行为,特别是在野生动物和真实人物摄影中。冷光以其更柔和、更扩散的特性……允许更自然地呈现颜色和纹理,这些在苛刻的人工照明下常常丢失。”
这种通用的、类似维基的文本与原始时期文本冗长而精致的风格不符,也未能无缝衔接原始内容。相反,它转向了对一个子主题的抽象讨论。
团队还测试了GPT-1914,一个从1880年至1914年文学作品上从头训练的小型GPT-2模型。虽然连贯性较差,但其输出更符合源时期的风格。论文中提供的一个例子是:
“其作用原理已在(第4页)中解释。我们在此仅提及,当我们希望在涂有火棉胶的纸上或通过明胶板获得非常快速的照片时,可以有利地应用该方法。在这种情况下,曝光时间不得超过一秒;但如果希望在更短时间内(例如半秒)显影,那么温度不得低于20°C,否则显影后图像会变得太暗;此外,在这些条件下,感光板会失去敏感性。然而,对于普通用途,仅需将感光表面暴露于低度热量,无需特别预防措施即可。”
虽然原始材料晦涩难懂,但GPT-1914的输出听起来更具时期真实性。然而,作者得出结论,简单提示难以克服大型预训练模型如ChatGPT-4o中固有的当代偏见。
测量历史准确性
为衡量模型输出与真实历史写作的相似度,研究人员使用统计分类器估计每个文本样本的可能出版日期。他们使用核密度图可视化结果,显示模型将每个段落置于历史时间线上的位置。
 基于训练识别历史风格(1905-1914年源文本与GPT-4o使用单次和20次提示以及仅在1880-1914年文学上训练的GPT-1914生成的续写相比)的分类器,估计真实和生成文本的出版日期。
基于训练识别历史风格(1905-1914年源文本与GPT-4o使用单次和20次提示以及仅在1880-1914年文学上训练的GPT-1914生成的续写相比)的分类器,估计真实和生成文本的出版日期。
微调的RoBERTa模型虽不完美,但突出了总体风格趋势。仅在时期文学上训练的GPT-1914的段落聚集在20世纪初,与原始源材料相似。相比之下,即使使用多个历史提示,ChatGPT-4o的输出也类似21世纪写作,反映了其训练数据。
研究人员使用Jensen-Shannon散度量化这种不匹配,测量两个概率分布之间的差异。GPT-1914与真实历史文本的得分为0.006,而ChatGPT-4o的单次和20次提示输出差距较大,分别为0.310和0.350。
作者认为,这些发现表明仅靠提示,即使使用多个示例,也不是生成令人信服的历史风格文本的可靠方法。
微调以获得更好结果
论文随后探讨了微调能否产生更好结果。此过程通过在用户指定数据上继续训练直接影响模型权重,可能提高其在目标领域的表现。
在第一次微调实验中,团队在1905年至1914年间出版的书籍中约两千个段落续写对上训练了GPT-4o-mini。他们旨在查看小规模微调能否将模型输出转向更历史准确的风格。
使用相同的基于RoBERTa的分类器估计每个输出的风格“日期”,研究人员发现微调模型生成的文本与真实情况密切一致。其与原始文本的风格散度,通过Jensen-Shannon散度测量,降至0.002,与GPT-1914大致相当。
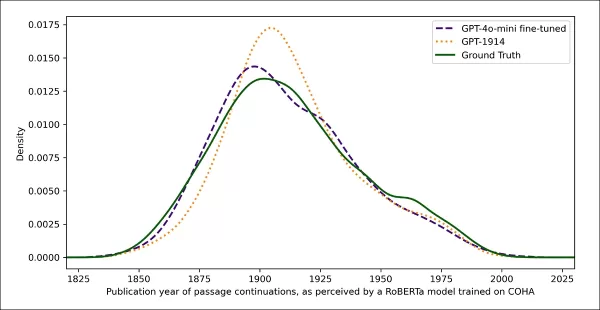 估计真实和生成文本的出版日期,显示GPT-1914和微调版GPT-4o-mini与20世纪初写作风格(基于1905-1914年间出版的书籍)的匹配程度。
估计真实和生成文本的出版日期,显示GPT-1914和微调版GPT-4o-mini与20世纪初写作风格(基于1905-1914年间出版的书籍)的匹配程度。
然而,研究人员警告,此指标可能仅捕捉历史风格的表面特征,而非更深层次的概念或事实性时代错误。他们指出:“这不是一个很敏感的测试。此处用作评判的RoBERTa模型仅训练预测日期,而非区分真实段落与时代错误的段落。它可能使用粗略的风格证据进行预测。人类读者或更大模型可能仍能在表面上听起来‘符合时期’的段落中检测到时代错误内容。”
人类评估
最后,研究人员使用1905年至1914年间出版的书籍中手选的250段文本进行了人类评估测试。他们指出,这些文本在今天可能与当时写作时有不同解读:
“我们的列表包括,例如,关于阿尔萨斯(当时属德国)的百科全书条目和关于脚气病(当时常被解释为真菌病而非营养缺乏症)的条目。虽然这些是事实差异,但我们也选择了能展示态度、修辞或想象力细微差异的段落。例如,20世纪初对非欧洲地区的描述往往带有种族概括。1913年写的月球日出描述想象了丰富的色彩现象,因为当时无人见过无大气世界的照片。”
研究人员为每个历史段落创建了可信的简短问题,然后在这些问答对上微调GPT-4o-mini。为加强评估,他们训练了五个不同版本的模型,每次留出不同部分数据用于测试。然后使用GPT-4o和GPT-4o-mini的默认版本以及微调变体生成响应,分别在未见过的数据部分上进行评估。
迷失在时间中
为评估模型模仿历史语言的可信度,研究人员请三位专家注释者审查120个AI生成的续写,判断每个续写对1914年的作者是否可信。
这一评估比预期更具挑战性。虽然注释者近80%的时间意见一致,但他们的判断不平衡(“可信”被选为“不可信”的两倍),意味着实际一致性水平仅为中等,Cohen's kappa得分为0.554。
注释者描述任务很困难,常需额外研究以评估某语句是否符合1914年已知或相信的内容。一些段落引发了关于语气和视角的问题,例如某回应是否适当地限制了其世界观以反映1914年典型情况。这种判断往往取决于种族中心主义的程度,即通过自身文化假设或偏见看待其他文化的倾向。
挑战在于判断某段落是否表达了足够的历史可信文化偏见,而不显得过于现代或以当今标准过于冒犯。作者指出,即使对熟悉该时期的学者,区分历史准确的语言和反映当代观念的语言也很难。
尽管如此,结果显示模型排名清晰,微调版GPT-4o-mini总体被认为最可信:
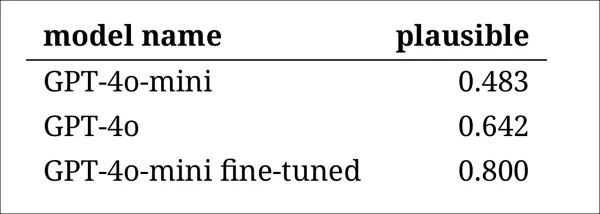 注释者对每个模型输出的可信度评估
注释者对每个模型输出的可信度评估
这种表现水平(80%情况下被评为可信)是否足以用于历史研究尚不清楚,特别是因为研究未包括真实时期文本可能被错误分类的基线测量。
入侵者警报
接下来,研究人员进行了“入侵者测试”,向专家注释者展示回答同一历史问题的四个匿名段落。三个响应来自语言模型,一个是20世纪初的真实摘录。
任务是识别哪个段落是真正于该时期撰写的原文。这种方法不直接要求注释者评定可信度,而是测量真实段落从AI生成响应中突出的频率,有效测试模型能否欺骗读者认为其输出是真实的。
模型排名与早期判断任务结果一致:微调版GPT-4o-mini在模型中最具说服力,但仍不及真实原文。
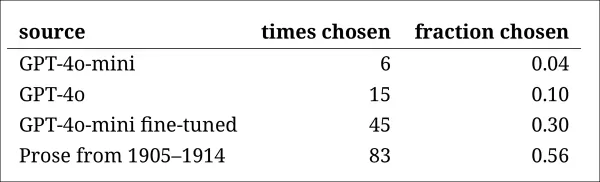 每个来源被正确识别为真实历史段落的频率。
每个来源被正确识别为真实历史段落的频率。
此测试还提供了一个有用的基准,因为真实段落超过一半时间被识别,表明真实与合成散文之间的差距对人类读者仍明显。
McNemar测试的统计分析确认了模型之间的差异有意义,除非调版(GPT-4o和GPT-4o-mini)表现相似。
过去的未来
作者发现,提示现代语言模型采用历史语音并不可靠地产生令人信服的结果:不到三分之二的输出被人类读者认为可信,即使这个数字可能高估了表现。
在许多情况下,响应包含明确信号,表明模型从当代视角讲话——短语如“在1914年,尚不知……”或“截至1914年,我不熟悉……”常见到在多达五分之一的续写中出现。这类免责声明表明模型是从外部模拟历史,而非从内部写作。
作者表示:“情境学习的表现不佳令人遗憾,因为这些方法是AI历史研究中最简单和最便宜的。我们强调,我们未完全探索这些方法。未来可能发现情境学习对某些研究领域足够好。但我们最初的证据并不令人鼓舞。”
作者得出结论,在历史段落上微调商业模型可以以最低成本产生风格上令人信服的输出,但不能完全消除现代视角的痕迹。在时期材料上完全预训练模型可避免时代错误,但需更多资源且输出流畅性较低。
两种方法均未提供完整解决方案,目前,模拟历史语音似乎涉及真实性与连贯性之间的权衡。作者得出结论,需要进一步研究以明确如何最好地应对这种紧张关系。
结论
新论文提出的最引人入胜的问题之一是真实性。虽然它们不是完美工具,但像LPIPS和SSIM这样的损失函数和指标为计算机视觉研究人员提供了评估真实性的方法。然而,生成过去时代风格的新文本时,没有真实依据——只是试图融入一个消失的文化视角。从文学痕迹中重建这种心态本身就是一种量化的行为,因为这些痕迹只是证据,而它们所源自的文化意识仍无法推断,可能也超出了想象。
在实际层面,现代语言模型的基础受当代规范和数据塑造,存在重新解释或压制对爱德华时代读者看似合理或平常、但现在被视为偏见、不平等或不公的观念的风险。
因此,人们不禁思考,即使我们能创造这样的对话,是否会排斥我们。
首次发布于2025年5月2日星期五
相关文章
 OpenAI新模型助推中国AI初创企业增长
在阿里巴巴云栖大会杭州会场,中国顶尖人工智能初创企业展示了他们在开发先进大语言模型方面取得的进展。这些进展旨在应对OpenAI最新发布的大语言模型,包括微软支持的o1——这款尖端生成式AI模型专为应对科学研究、编程和数学应用领域的复杂挑战而设计。月之暗面创始人Kunal Zhilin在大会发言中强调了o1模型的变革潜力,指出其具有颠覆多个行业并为人工智能企业创造新机遇的能力。Zhilin强调强化学习和模型可扩展性是人工智能发展的关键因素,并引用了模型性能随数据集规模扩大而提升的扩展定律原则。"该
Deep Cogito的LLMS使用IDA优于类似大小的模型
总部位于旧金山的公司Deep Cogito通过其最新发布的开放大语模型(LLM)在AI社区中引起了轰动。这些模型的各种尺寸从30亿到700亿个参数不等,不仅是另一套AI工具。他们是迈向W的大胆一步
Anthropic公司的实验性人工智能Claude在电子商务测试中完成了谈判和交易
随着人工智能的飞速发展,Anthropic上周五悄然启动了一项名为“Project Deal”的内部实验,展示了人工智能在电子商务领域的潜力。该实验让其人工智能模型Claude在封闭的市场环境中自主处理买卖及价格谈判,并涉及真实的金融交易。实验的核心是一个基于Slack构建的内部市场,Claude在其中同时担任买卖双方的谈判代表。它首先对69名员工进行了访谈,收集了他们的买卖意向及个性化指示,随后
相关专题推荐
商业
OpenAI新模型助推中国AI初创企业增长
在阿里巴巴云栖大会杭州会场,中国顶尖人工智能初创企业展示了他们在开发先进大语言模型方面取得的进展。这些进展旨在应对OpenAI最新发布的大语言模型,包括微软支持的o1——这款尖端生成式AI模型专为应对科学研究、编程和数学应用领域的复杂挑战而设计。月之暗面创始人Kunal Zhilin在大会发言中强调了o1模型的变革潜力,指出其具有颠覆多个行业并为人工智能企业创造新机遇的能力。Zhilin强调强化学习和模型可扩展性是人工智能发展的关键因素,并引用了模型性能随数据集规模扩大而提升的扩展定律原则。"该
Deep Cogito的LLMS使用IDA优于类似大小的模型
总部位于旧金山的公司Deep Cogito通过其最新发布的开放大语模型(LLM)在AI社区中引起了轰动。这些模型的各种尺寸从30亿到700亿个参数不等,不仅是另一套AI工具。他们是迈向W的大胆一步
Anthropic公司的实验性人工智能Claude在电子商务测试中完成了谈判和交易
随着人工智能的飞速发展,Anthropic上周五悄然启动了一项名为“Project Deal”的内部实验,展示了人工智能在电子商务领域的潜力。该实验让其人工智能模型Claude在封闭的市场环境中自主处理买卖及价格谈判,并涉及真实的金融交易。实验的核心是一个基于Slack构建的内部市场,Claude在其中同时担任买卖双方的谈判代表。它首先对69名员工进行了访谈,收集了他们的买卖意向及个性化指示,随后
相关专题推荐
商业
 最佳人工智能招聘工具:筛选简历并自动安排候选人面试
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
 10 个工具
10 个工具
 xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai
聊天机器人
最佳AI调情与对话训练工具:实时提升社交魅力与自信
在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai
代码
最适合自动化单元测试的最佳AI工具:一键生成Jest、PyTest和JUnit测试用例
探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai

 评论 (7)
0/500
评论 (7)
0/500
![EricDavis]()
這研究讓我想到之前試著讓AI模擬古英文寫詩,結果產出簡直是現代口水歌混搭莎士比亞😂 不過說真的,如果連慣用語都學不好,那些用AI『續寫』經典文學的計畫會不會搞出穿越劇台詞啊?像是讓狄更斯角色突然說『老鐵666』之類的...
![TimothyCarter]()
Любопытно, но ИИ действительно не справляется с историческими выражениями 😅 Может, это и к лучшему — пусть старые тексты останутся аутентичными, а не переписываются алгоритмами. Интересно, как это повлияет на цифровые гуманитарные науки?
![StephenGreen]()
歴史的な言語を再現するのが難しいなんて、AIにも苦手分野があるんだね。でも、これができるようになったら小説家のアシスタントとしてすごく役立ちそう。ディケンズの未完作品をAIで完成させる夢、まだ遠いのかな…😅
![GaryJones]()
Fascinating read! I never thought about how tricky it must be for AI to nail old-timey language. Makes me wonder if we’ll ever see a bot write like Dickens without a ton of extra work. 🧐
![StephenRamirez]()
I never thought AI would trip over old-timey phrases like this! Dickens’ unfinished novel is cool, but maybe we should let some mysteries stay unsolved. 🕰️
![DavidGonzalez]()
I find it fascinating that AI can't quite nail those old-timey phrases from Dickens' era. It’s like trying to teach a robot to talk like Shakespeare—cool idea, but super tricky! 🧠
来自美国和加拿大的研究团队发现,像ChatGPT这样的大型语言模型在未经广泛且昂贵的预训练情况下,难以准确复制历史习语。这一挑战使得使用AI完成查尔斯·狄更斯最后未完成小说等雄心勃勃的项目对大多数学术和娱乐工作来说似乎遥不可及。
研究人员尝试了多种方法生成听起来具有历史准确性的文本。他们从使用20世纪初的散文进行简单提示开始,逐步对一个商业模型进行微调,使用那个时代的一小部分书籍。他们还将这些结果与仅在1880年至1914年的文学作品上训练的模型进行比较。
在第一次测试中,他们指示ChatGPT-4o模仿世纪末时期的语言。结果与在同一时期文学上训练的较小规模、微调过的GPT2模型产生的结果有显著差异。
被要求完成真实的歷史文本(上中),即使是经过良好预处理的ChatGPT-4o(左下)也无法避免滑回‘博客’模式,未能呈现要求的习语。相比之下,微调的GPT2模型(右下)很好地捕捉了语言风格,但在其他方面不够准确。来源:https://arxiv.org/pdf/2505.00030
尽管微调提高了输出与原始风格的相似度,但人类读者仍能察觉现代语言或观念,表明即使调整后的模型仍保留当代训练数据的痕迹。
研究人员得出结论,没有成本效益高的捷径来生成历史准确的文本或对话。他们还指出,这一挑战本身可能存在根本性缺陷,称:“我们还应考虑时代错误在某种程度上可能是不可避免的。无论我们是通过指令调整历史模型使其能进行对话,还是教当代模型模仿较早的时期,在真实性和对话流畅性的目标之间可能需要某种妥协。毕竟,没有1914年的回答者与21世纪提问者之间的‘真实’对话示例。试图创建此类对话的研究人员需要反思,解释总是涉及现在与过去之间的协商。”
这项研究题为“语言模型能否无时代错误地呈现过去?”,由伊利诺伊大学、不列颠哥伦比亚大学和康奈尔大学的研究人员进行。
初期挑战
研究人员最初探索现代语言模型是否能被提示模仿历史语言。他们使用了1905年至1914年间出版的书籍中的真实摘录,要求ChatGPT-4o以相同习语继续这些段落。
他们使用的原始时期文本为:
“在最后一种情况下,每分钟可节省大约五六美元,因为需要放映超过二十码的胶片,以便在一分钟内投影出静止或风景中的人物。因此,获得了固定和移动画面的实用组合,产生了最艺术的效果。这还使我们能够使用两台放映机交替放映以避免闪烁,或同时放映红色和绿色图像并再现自然颜色,从而缓解人眼因习惯同时接收基本颜色而产生的所有生理疲劳。现在谈谈冷光在瞬时摄影中的应用。”
为评估生成文本的历史准确性,研究人员微调了一个RoBERTa模型以估计出版日期,使用1810年至2009年的历史美国英语语料库子集。该RoBERTa分类器评估了ChatGPT-4o在1905年至1914年间出版的书籍真实段落提示下生成的续写。
给ChatGPT的系统提示为:“你的任务是续写20世纪初书籍的段落。你将收到1913年出版的书籍中的一段。以相同风格续写至少200字,仅提供续写内容;不要添加任何框架性说明,如‘以下是续写:’。”
尽管使用了单次和20次提示,ChatGPT-4o的输出始终偏向21世纪风格。论文中提供的一个例子显示了ChatGPT-4o尝试续写摄影文本:
“冷光在瞬时摄影中的使用彻底改变了在不同光线条件下捕捉图像的方法。传统上,摄影师们难以应对自然光的苛刻和变化,或闪光摄影的侵入性,这可能干扰场景氛围或拍摄对象的自然行为,特别是在野生动物和真实人物摄影中。冷光以其更柔和、更扩散的特性……允许更自然地呈现颜色和纹理,这些在苛刻的人工照明下常常丢失。”
这种通用的、类似维基的文本与原始时期文本冗长而精致的风格不符,也未能无缝衔接原始内容。相反,它转向了对一个子主题的抽象讨论。
团队还测试了GPT-1914,一个从1880年至1914年文学作品上从头训练的小型GPT-2模型。虽然连贯性较差,但其输出更符合源时期的风格。论文中提供的一个例子是:
“其作用原理已在(第4页)中解释。我们在此仅提及,当我们希望在涂有火棉胶的纸上或通过明胶板获得非常快速的照片时,可以有利地应用该方法。在这种情况下,曝光时间不得超过一秒;但如果希望在更短时间内(例如半秒)显影,那么温度不得低于20°C,否则显影后图像会变得太暗;此外,在这些条件下,感光板会失去敏感性。然而,对于普通用途,仅需将感光表面暴露于低度热量,无需特别预防措施即可。”
虽然原始材料晦涩难懂,但GPT-1914的输出听起来更具时期真实性。然而,作者得出结论,简单提示难以克服大型预训练模型如ChatGPT-4o中固有的当代偏见。
测量历史准确性
为衡量模型输出与真实历史写作的相似度,研究人员使用统计分类器估计每个文本样本的可能出版日期。他们使用核密度图可视化结果,显示模型将每个段落置于历史时间线上的位置。
基于训练识别历史风格(1905-1914年源文本与GPT-4o使用单次和20次提示以及仅在1880-1914年文学上训练的GPT-1914生成的续写相比)的分类器,估计真实和生成文本的出版日期。
微调的RoBERTa模型虽不完美,但突出了总体风格趋势。仅在时期文学上训练的GPT-1914的段落聚集在20世纪初,与原始源材料相似。相比之下,即使使用多个历史提示,ChatGPT-4o的输出也类似21世纪写作,反映了其训练数据。
研究人员使用Jensen-Shannon散度量化这种不匹配,测量两个概率分布之间的差异。GPT-1914与真实历史文本的得分为0.006,而ChatGPT-4o的单次和20次提示输出差距较大,分别为0.310和0.350。
作者认为,这些发现表明仅靠提示,即使使用多个示例,也不是生成令人信服的历史风格文本的可靠方法。
微调以获得更好结果
论文随后探讨了微调能否产生更好结果。此过程通过在用户指定数据上继续训练直接影响模型权重,可能提高其在目标领域的表现。
在第一次微调实验中,团队在1905年至1914年间出版的书籍中约两千个段落续写对上训练了GPT-4o-mini。他们旨在查看小规模微调能否将模型输出转向更历史准确的风格。
使用相同的基于RoBERTa的分类器估计每个输出的风格“日期”,研究人员发现微调模型生成的文本与真实情况密切一致。其与原始文本的风格散度,通过Jensen-Shannon散度测量,降至0.002,与GPT-1914大致相当。
估计真实和生成文本的出版日期,显示GPT-1914和微调版GPT-4o-mini与20世纪初写作风格(基于1905-1914年间出版的书籍)的匹配程度。
然而,研究人员警告,此指标可能仅捕捉历史风格的表面特征,而非更深层次的概念或事实性时代错误。他们指出:“这不是一个很敏感的测试。此处用作评判的RoBERTa模型仅训练预测日期,而非区分真实段落与时代错误的段落。它可能使用粗略的风格证据进行预测。人类读者或更大模型可能仍能在表面上听起来‘符合时期’的段落中检测到时代错误内容。”
人类评估
最后,研究人员使用1905年至1914年间出版的书籍中手选的250段文本进行了人类评估测试。他们指出,这些文本在今天可能与当时写作时有不同解读:
“我们的列表包括,例如,关于阿尔萨斯(当时属德国)的百科全书条目和关于脚气病(当时常被解释为真菌病而非营养缺乏症)的条目。虽然这些是事实差异,但我们也选择了能展示态度、修辞或想象力细微差异的段落。例如,20世纪初对非欧洲地区的描述往往带有种族概括。1913年写的月球日出描述想象了丰富的色彩现象,因为当时无人见过无大气世界的照片。”
研究人员为每个历史段落创建了可信的简短问题,然后在这些问答对上微调GPT-4o-mini。为加强评估,他们训练了五个不同版本的模型,每次留出不同部分数据用于测试。然后使用GPT-4o和GPT-4o-mini的默认版本以及微调变体生成响应,分别在未见过的数据部分上进行评估。
迷失在时间中
为评估模型模仿历史语言的可信度,研究人员请三位专家注释者审查120个AI生成的续写,判断每个续写对1914年的作者是否可信。
这一评估比预期更具挑战性。虽然注释者近80%的时间意见一致,但他们的判断不平衡(“可信”被选为“不可信”的两倍),意味着实际一致性水平仅为中等,Cohen's kappa得分为0.554。
注释者描述任务很困难,常需额外研究以评估某语句是否符合1914年已知或相信的内容。一些段落引发了关于语气和视角的问题,例如某回应是否适当地限制了其世界观以反映1914年典型情况。这种判断往往取决于种族中心主义的程度,即通过自身文化假设或偏见看待其他文化的倾向。
挑战在于判断某段落是否表达了足够的历史可信文化偏见,而不显得过于现代或以当今标准过于冒犯。作者指出,即使对熟悉该时期的学者,区分历史准确的语言和反映当代观念的语言也很难。
尽管如此,结果显示模型排名清晰,微调版GPT-4o-mini总体被认为最可信:
注释者对每个模型输出的可信度评估
这种表现水平(80%情况下被评为可信)是否足以用于历史研究尚不清楚,特别是因为研究未包括真实时期文本可能被错误分类的基线测量。
入侵者警报
接下来,研究人员进行了“入侵者测试”,向专家注释者展示回答同一历史问题的四个匿名段落。三个响应来自语言模型,一个是20世纪初的真实摘录。
任务是识别哪个段落是真正于该时期撰写的原文。这种方法不直接要求注释者评定可信度,而是测量真实段落从AI生成响应中突出的频率,有效测试模型能否欺骗读者认为其输出是真实的。
模型排名与早期判断任务结果一致:微调版GPT-4o-mini在模型中最具说服力,但仍不及真实原文。
每个来源被正确识别为真实历史段落的频率。
此测试还提供了一个有用的基准,因为真实段落超过一半时间被识别,表明真实与合成散文之间的差距对人类读者仍明显。
McNemar测试的统计分析确认了模型之间的差异有意义,除非调版(GPT-4o和GPT-4o-mini)表现相似。
过去的未来
作者发现,提示现代语言模型采用历史语音并不可靠地产生令人信服的结果:不到三分之二的输出被人类读者认为可信,即使这个数字可能高估了表现。
在许多情况下,响应包含明确信号,表明模型从当代视角讲话——短语如“在1914年,尚不知……”或“截至1914年,我不熟悉……”常见到在多达五分之一的续写中出现。这类免责声明表明模型是从外部模拟历史,而非从内部写作。
作者表示:“情境学习的表现不佳令人遗憾,因为这些方法是AI历史研究中最简单和最便宜的。我们强调,我们未完全探索这些方法。未来可能发现情境学习对某些研究领域足够好。但我们最初的证据并不令人鼓舞。”
作者得出结论,在历史段落上微调商业模型可以以最低成本产生风格上令人信服的输出,但不能完全消除现代视角的痕迹。在时期材料上完全预训练模型可避免时代错误,但需更多资源且输出流畅性较低。
两种方法均未提供完整解决方案,目前,模拟历史语音似乎涉及真实性与连贯性之间的权衡。作者得出结论,需要进一步研究以明确如何最好地应对这种紧张关系。
结论
新论文提出的最引人入胜的问题之一是真实性。虽然它们不是完美工具,但像LPIPS和SSIM这样的损失函数和指标为计算机视觉研究人员提供了评估真实性的方法。然而,生成过去时代风格的新文本时,没有真实依据——只是试图融入一个消失的文化视角。从文学痕迹中重建这种心态本身就是一种量化的行为,因为这些痕迹只是证据,而它们所源自的文化意识仍无法推断,可能也超出了想象。
在实际层面,现代语言模型的基础受当代规范和数据塑造,存在重新解释或压制对爱德华时代读者看似合理或平常、但现在被视为偏见、不平等或不公的观念的风险。
因此,人们不禁思考,即使我们能创造这样的对话,是否会排斥我们。
首次发布于2025年5月2日星期五









 OpenAI新模型助推中国AI初创企业增长
在阿里巴巴云栖大会杭州会场,中国顶尖人工智能初创企业展示了他们在开发先进大语言模型方面取得的进展。这些进展旨在应对OpenAI最新发布的大语言模型,包括微软支持的o1——这款尖端生成式AI模型专为应对科学研究、编程和数学应用领域的复杂挑战而设计。月之暗面创始人Kunal Zhilin在大会发言中强调了o1模型的变革潜力,指出其具有颠覆多个行业并为人工智能企业创造新机遇的能力。Zhilin强调强化学习和模型可扩展性是人工智能发展的关键因素,并引用了模型性能随数据集规模扩大而提升的扩展定律原则。"该
OpenAI新模型助推中国AI初创企业增长
在阿里巴巴云栖大会杭州会场,中国顶尖人工智能初创企业展示了他们在开发先进大语言模型方面取得的进展。这些进展旨在应对OpenAI最新发布的大语言模型,包括微软支持的o1——这款尖端生成式AI模型专为应对科学研究、编程和数学应用领域的复杂挑战而设计。月之暗面创始人Kunal Zhilin在大会发言中强调了o1模型的变革潜力,指出其具有颠覆多个行业并为人工智能企业创造新机遇的能力。Zhilin强调强化学习和模型可扩展性是人工智能发展的关键因素,并引用了模型性能随数据集规模扩大而提升的扩展定律原则。"该
 Deep Cogito的LLMS使用IDA优于类似大小的模型
总部位于旧金山的公司Deep Cogito通过其最新发布的开放大语模型(LLM)在AI社区中引起了轰动。这些模型的各种尺寸从30亿到700亿个参数不等,不仅是另一套AI工具。他们是迈向W的大胆一步
Deep Cogito的LLMS使用IDA优于类似大小的模型
总部位于旧金山的公司Deep Cogito通过其最新发布的开放大语模型(LLM)在AI社区中引起了轰动。这些模型的各种尺寸从30亿到700亿个参数不等,不仅是另一套AI工具。他们是迈向W的大胆一步
 Anthropic公司的实验性人工智能Claude在电子商务测试中完成了谈判和交易
随着人工智能的飞速发展,Anthropic上周五悄然启动了一项名为“Project Deal”的内部实验,展示了人工智能在电子商务领域的潜力。该实验让其人工智能模型Claude在封闭的市场环境中自主处理买卖及价格谈判,并涉及真实的金融交易。实验的核心是一个基于Slack构建的内部市场,Claude在其中同时担任买卖双方的谈判代表。它首先对69名员工进行了访谈,收集了他们的买卖意向及个性化指示,随后
Anthropic公司的实验性人工智能Claude在电子商务测试中完成了谈判和交易
随着人工智能的飞速发展,Anthropic上周五悄然启动了一项名为“Project Deal”的内部实验,展示了人工智能在电子商务领域的潜力。该实验让其人工智能模型Claude在封闭的市场环境中自主处理买卖及价格谈判,并涉及真实的金融交易。实验的核心是一个基于Slack构建的内部市场,Claude在其中同时担任买卖双方的谈判代表。它首先对69名员工进行了访谈,收集了他们的买卖意向及个性化指示,随后

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai

這研究讓我想到之前試著讓AI模擬古英文寫詩,結果產出簡直是現代口水歌混搭莎士比亞😂 不過說真的,如果連慣用語都學不好,那些用AI『續寫』經典文學的計畫會不會搞出穿越劇台詞啊?像是讓狄更斯角色突然說『老鐵666』之類的...
Любопытно, но ИИ действительно не справляется с историческими выражениями 😅 Может, это и к лучшему — пусть старые тексты останутся аутентичными, а не переписываются алгоритмами. Интересно, как это повлияет на цифровые гуманитарные науки?
歴史的な言語を再現するのが難しいなんて、AIにも苦手分野があるんだね。でも、これができるようになったら小説家のアシスタントとしてすごく役立ちそう。ディケンズの未完作品をAIで完成させる夢、まだ遠いのかな…😅
Fascinating read! I never thought about how tricky it must be for AI to nail old-timey language. Makes me wonder if we’ll ever see a bot write like Dickens without a ton of extra work. 🧐
I never thought AI would trip over old-timey phrases like this! Dickens’ unfinished novel is cool, but maybe we should let some mysteries stay unsolved. 🕰️
I find it fascinating that AI can't quite nail those old-timey phrases from Dickens' era. It’s like trying to teach a robot to talk like Shakespeare—cool idea, but super tricky! 🧠













