
















 首頁
首頁AI難以模擬歷史語言
來自美國和加拿大的研究團隊發現,像ChatGPT這樣的大型語言模型在未經廣泛且昂貴的預訓練情況下,難以準確複製歷史成語。這一挑戰使得使用AI完成查爾斯·狄更斯最後未完成小說等雄心勃勃的項目,對大多數學術和娛樂努力來說似乎遙不可及。
研究人員嘗試了多種方法來生成聽起來具有歷史準確性的文本。他們從使用20世紀初散文的簡單提示開始,進而對一個商業模型進行微調,基於該時代的一小部分書籍。他們還將這些結果與僅在1880年至1914年文學上訓練的模型進行比較。
在他們的第一次測試中,他們指示ChatGPT-4o模仿世紀末時期的語言。結果與一個在同一時期文學上訓練的較小型、微調過的GPT2模型所產生的結果有顯著差異。
 被要求完成真實歷史文本(上中),即使是經過良好準備的ChatGPT-4o(左下)也無法避免回歸「部落格」模式,未能表現出要求的成語。相比之下,微調的GPT2模型(右下)很好地捕捉了語言風格,但在其他方面不夠準確。來源:https://arxiv.org/pdf/2505.00030
被要求完成真實歷史文本(上中),即使是經過良好準備的ChatGPT-4o(左下)也無法避免回歸「部落格」模式,未能表現出要求的成語。相比之下,微調的GPT2模型(右下)很好地捕捉了語言風格,但在其他方面不夠準確。來源:https://arxiv.org/pdf/2505.00030
雖然微調改善了輸出與原始風格的相似性,但人類讀者仍能察覺現代語言或觀念,顯示即使調整後的模型仍保留其當代訓練數據的痕跡。
研究人員得出結論,生成歷史上準確的文本或對話沒有成本效益高的捷徑。他們還建議,這一挑戰本身可能存在固有缺陷,指出:「我們也應考慮時代錯誤在某種程度上可能是不可避免的。無論是通過指令調整歷史模型使其能進行對話,還是教導當代模型模仿較早的時期,在真實性和對話流暢性的目標之間可能需要某種妥協。畢竟,沒有21世紀提問者與1914年回應者之間的「真實」對話範例。試圖創造這種對話的研究人員需要反思,詮釋總是涉及當前與過去之間的協商。」
這項研究題為「語言模型能否無時代錯誤地表現過去?」,由伊利諾伊大學、不列顛哥倫比亞大學和康奈爾大學的研究人員進行。
初始挑戰
研究人員最初探索現代語言模型是否能通過提示模仿歷史語言。他們使用了1905年至1914年間出版的書籍中的真實摘錄,要求ChatGPT-4o以相同成語繼續這些段落。
他們使用的原始時代文本為:
「在這最後一種情況下,每分鐘可節省約五或六美元,因為為了在一分鐘內投影一個靜止的人或風景,必須捲動超過二十碼的膠片。由此獲得固定與活動圖片的實際結合,產生最具藝術性的效果。它還使我們能夠操作兩台交替投影的電影放映機,以避免閃爍,或同時投影紅色和綠色圖像並重現自然色彩,從而減輕人類眼睛的生理疲勞,因為人眼習慣於同時接收基本色彩。現在談談冷光在瞬間攝影中的應用。」
為了評估生成文本的歷史準確性,研究人員微調了一個RoBERTa模型來估計出版日期,使用了涵蓋1810年至2009年材料的歷史美國英語語料庫子集。這個RoBERTa分類器評估了ChatGPT-4o在1905年至1914年間出版的書籍真實段落提示下生成的續篇。
給ChatGPT的系統提示為:「你的任務是完成20世紀初書籍的段落。你將獲得1913年出版的書籍中的一段。以相同風格繼續這段,至少200字。僅提供續篇;不要添加任何框架性評論,如『以下是續篇:』。」
儘管使用了單次和20次提示,ChatGPT-4o的輸出始終傾向於21世紀風格。論文中提供的一個例子顯示ChatGPT-4o試圖繼續攝影文本:
「冷光在瞬間攝影中的使用徹底改變了在不同光線條件下捕捉圖像的方法。傳統上,攝影師們難以應對自然光的苛刻和變化性,或閃光攝影的侵入性質,這可能會干擾場景的氛圍或主題的自然行為,特別是在野生動物和偷拍人像攝影中。冷光以其較柔和且更分散的特性……允許更自然地呈現顏色和紋理,這在苛刻的人工照明下往往會丟失。」
這種通用的、維基風格的文本與原始時代文本的冗長和精緻風格不符,也未能從原始文本結束處無縫繼續。相反,它轉向了對一個子主題的抽象討論。
研究團隊還測試了GPT-1914,一個從頭訓練的較小型GPT-2模型,基於1880年至1914年間的文學。雖然不夠連貫,但其輸出與來源時代的風格更一致。論文中提供的一個例子是:
「其作用原理已在(第4頁)中解釋。我們在此僅提及,當我們希望在塗有火棉膠的紙上或使用明膠板獲得非常快速的照片時,可有利地應用該原理。在這種情況下,曝光時間不得超過一秒;但如果希望在更短的時間內顯影圖片——例如半秒——則溫度不得低於20°C,否則顯影後圖像將過暗;此外,在這些條件下,感光板將失去其敏感性。然而,對於普通用途,只需將感光表面暴露於低溫熱量,無需任何特殊預防措施即可。」
雖然原始材料晦澀難懂,但GPT-1914的輸出聽起來更具時代真實性。然而,作者結論認為,簡單的提示無法克服大型預訓練模型如ChatGPT-4o固有的當代偏見。
測量歷史準確性
為了評估模型輸出與真實歷史寫作的相似程度,研究人員使用統計分類器來估計每個文本樣本的可能出版日期。他們使用核密度圖可視化結果,顯示模型將每個段落放置在歷史時間線上的位置。
 真實與生成文本的估計出版日期,基於訓練識別歷史風格的分類器(1905-1914年來源文本與GPT-4o使用單次和20次提示的續篇,以及僅在1880-1914年文學上訓練的GPT-1914的續篇比較)。
真實與生成文本的估計出版日期,基於訓練識別歷史風格的分類器(1905-1914年來源文本與GPT-4o使用單次和20次提示的續篇,以及僅在1880-1914年文學上訓練的GPT-1914的續篇比較)。
微調的RoBERTa模型雖不完美,但突顯了總體風格趨勢。僅在時代文學上訓練的GPT-1914的段落集中在20世紀初,與原始來源材料相似。相反,ChatGPT-4o的輸出,即使使用多個歷史提示,也類似於21世紀的寫作,反映了其訓練數據。
研究人員使用Jensen-Shannon散度量化這種不匹配,測量兩個概率分佈之間的差異。GPT-1914與真實歷史文本的得分接近0.006,而ChatGPT-4o的單次和20次提示輸出顯示出更大的差距,分別為0.310和0.350。
作者認為,這些發現表明,僅靠提示,即使有多個範例,也不是生成令人信服的歷史風格文本的可靠方法。
微調以獲得更好結果
論文隨後探討了微調是否能產生更好結果。此過程通過在用戶指定數據上繼續訓練,直接影響模型的權重,可能改善其在目標領域的表現。
在第一次微調實驗中,團隊在1905年至1914年間出版的書籍中,訓練GPT-4o-mini約兩千個段落完成對。他們旨在檢視小規模微調是否能將模型輸出轉向更具歷史準確性的風格。
使用相同的RoBERTa分類器估計每個輸出的風格「日期」,研究人員發現,微調模型生成的文本與真實文本密切對齊。其與原始文本的風格散度,通過Jensen-Shannon散度測量,降至0.002,與GPT-1914大體一致。
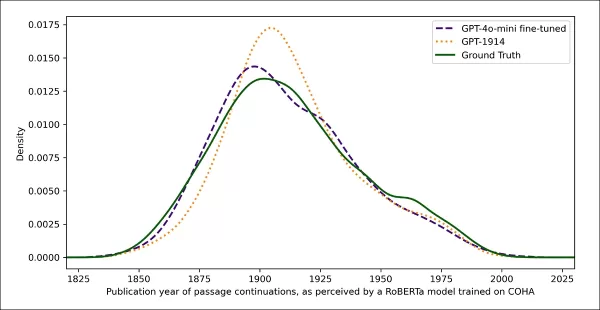 真實與生成文本的估計出版日期,顯示GPT-1914和微調版本的GPT-4o-mini與20世紀初寫作風格的匹配程度(基於1905-1914年間出版的書籍)。
真實與生成文本的估計出版日期,顯示GPT-1914和微調版本的GPT-4o-mini與20世紀初寫作風格的匹配程度(基於1905-1914年間出版的書籍)。
然而,研究人員警告說,這個指標可能僅捕捉歷史風格的表面特徵,而非更深層的概念或事實時代錯誤。他們指出:「這不是一個非常敏感的測試。這裡用作評判的RoBERTa模型僅訓練來預測日期,而非區分真實段落與時代錯誤的段落。它可能使用粗略的風格證據進行預測。人類讀者或更大的模型可能仍能在表面上聽起來「符合時代」的段落中檢測到時代錯誤的內容。」
人類評估
最後,研究人員使用1905年至1914年間出版的書籍中手選的250個段落進行了人類評估測試。他們指出,這些文本在今天可能與當時的解釋不同:
「我們的列表中包括,例如,關於阿爾薩斯(當時屬於德國)的百科全書條目和關於腳氣病(當時常被解釋為真菌疾病而非營養缺乏)的條目。雖然這些是事實上的差異,但我們也選擇了顯示態度、修辭或想像力細微差異的段落。例如,20世紀初對非歐洲地方的描述往往陷入種族概括。1913年寫的月球日出描述想像出豐富的色彩現象,因為當時還沒有人見過沒有大氣的世界的照片。」
研究人員創建了每個歷史段落可能合理回答的簡短問題,然後在這些問答對上微調GPT-4o-mini。為了加強評估,他們訓練了五個獨立的模型版本,每次保留不同部分的數據用於測試。然後,他們使用GPT-4o和GPT-4o-mini的默認版本以及微調變體生成回應,每個版本在未見過的數據部分上進行評估。
迷失於時間
為了評估模型模仿歷史語言的說服力,研究人員請三位專家評估者審查120個AI生成的續篇,判斷每個續篇是否對1914年的作家來說似乎合理。
這項評估比預期更具挑戰性。雖然評估者在近80%的情況下意見一致,但他們的判斷不平衡(「合理」被選中的頻率是「不合理」的兩倍),意味著實際一致性水平僅為中等,通過Cohen's kappa得分0.554測量。
評估者描述這項任務很困難,通常需要額外研究來評估某個陳述是否與1914年已知或相信的內容一致。一些段落引發了關於語氣和觀點的問題,例如回應是否適當地限制在反映1914年典型世界觀的範圍內。這種判斷往往取決於民族中心主義的程度,即通過自身文化的假設或偏見看待其他文化的傾向。
挑戰在於決定一個段落是否表達了足夠的文化偏見,使其看起來具有歷史合理性,同時不顯得太現代或以當今標準過於冒犯。作者指出,即使對於熟悉該時期的學者,也難以在感覺歷史上準確的語言與反映當今觀念的語言之間劃清界限。
儘管如此,結果顯示模型的明確排名,微調版本的GPT-4o-mini總體上被認為是最合理的:
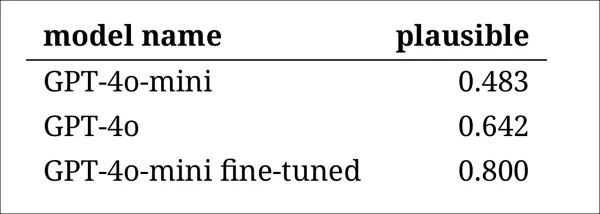 評估者對每個模型輸出看起來合理程度的評估
評估者對每個模型輸出看起來合理程度的評估
這種表現水平(在80%的情況下被評為合理)是否對歷史研究足夠可靠尚不清楚,特別是因為該研究未包括真實時代文本可能被誤分類的基準測量。
入侵者警報
接下來,研究人員進行了「入侵者測試」,向專家評估者展示回答同一歷史問題的四個匿名段落。三個回應來自語言模型,而一個是來自20世紀初的真實摘錄。
任務是辨認哪個段落是在該時期真實撰寫的原文。這種方法不直接要求評估者評估合理性,而是測量真實段落從AI生成回應中脫穎而出的頻率,有效測試模型是否能欺騙讀者認為其輸出是真實的。
模型的排名與之前的判斷任務結果一致:微調版本的GPT-4o-mini在模型中最具說服力,但仍不及真實文本。
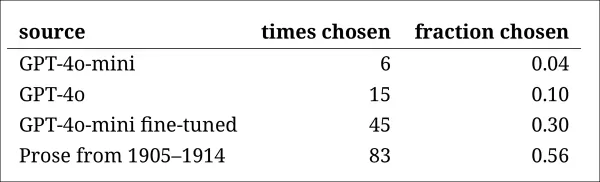 每個來源被正確識別為真實歷史段落的頻率。
每個來源被正確識別為真實歷史段落的頻率。
這項測試也作為有用的基準,因為真實段落超過一半時間被識別出來,表明真實與合成散文之間的差距對人類讀者來說仍然顯著。
一項名為McNemar測試的統計分析確認了模型之間的差異是有意義的,除了未調整的兩個版本(GPT-4o和GPT-4o-mini)表現相似的情況外。
過去的未來
作者發現,提示現代語言模型採用歷史語音無法可靠地產生令人信服的結果:人類讀者認為不到三分之二的輸出是合理的,甚至這個數字可能高估了表現。
在許多情況下,回應包含明確信號,表明模型從當代視角說話——諸如「在1914年,尚未知曉……」或「截至1914年,我不熟悉……」的短語在多達五分之一的續篇中出現。這類免責聲明清楚表明,模型是從外部模擬歷史,而非從內部撰寫。
作者表示:「情境學習的表現不佳令人遺憾,因為這些方法是AI歷史研究中最簡單且成本最低的。我們強調,我們尚未詳盡探索這些方法。情境學習可能現在或將來對於某些研究領域是足夠的。但我們的初步證據並不令人鼓舞。」
作者結論認為,雖然在歷史段落上微調商業模型可以以最小的成本產生風格上令人信服的輸出,但無法完全消除現代視角的痕跡。完全在時代材料上預訓練模型可避免時代錯誤,但需要更多資源且輸出流暢度較低。
兩種方法均未提供完整解決方案,目前,模擬歷史語音的任何嘗試似乎都涉及真實性與連貫性之間的權衡。作者結論認為,需要進一步研究以澄清如何最好地應對這種緊張關係。
結論
新論文提出的最引人入勝的問題之一是真實性的問題。雖然它們不是完美的工具,但像LPIPS和SSIM這樣的損失函數和指標為計算機視覺研究人員提供了一種針對真實基準的評估方法。然而,在生成過去時代風格的新文本時,沒有真實基準——只有嘗試融入已消失的文化視角。從文學痕跡重建這種心態本身就是一種量化的行為,因為這些痕跡僅是證據,而其背後的文化意識可能無法推斷,也可能無法想像。
在實踐層面上,現代語言模型的基礎受當今規範和數據的塑造,存在重新詮釋或壓制對愛德華時代讀者來說合理或不顯眼的觀念的風險,這些觀念如今被視為偏見、不平等或不公的痕跡。
因此,人們不禁思考,即使我們能創造這樣的對話,是否會讓我們感到排斥。
首次發表於2025年5月2日,星期五
相關文章
 OpenAI新模型助長中國AI新創蓬勃發展
在阿里巴巴雲的雲棲大會上,中國頂尖的人工智慧新創公司展示了他們在開發先進大型語言模型方面的進展。這些發展是為了因應OpenAI最新發布的大型語言模型,包括由微軟支持的o1——這是一種尖端生成式人工智慧模型,專為處理科學研究、程式設計和數學應用中的複雜挑戰而設計。Moonshot AI創始人Kunal Zhilin在會議發言中強調了o1模型的變革潛力,指出其具有顛覆多個產業的能力,同時為人工智慧企業創造新的機會。Zhilin強調強化學習和模型可擴展性是人工智慧進步的關鍵因素,並參考了規模法則原理,
Deep Cogito的LLMS使用IDA優於類似大小的模型
總部位於舊金山的公司Deep Cogito通過其最新發布的開放大語模型(LLM)在AI社區中引起了轟動。這些模型的各種尺寸從30億到700億個參數不等,不僅是另一套AI工具。他們是邁向W的大膽一步
耀科傳媒首部AIGC劇集《秦嶺青銅之謎》今日上線,主演均由AI選角
今日,耀科傳媒的AIGC奇幻懸疑短劇《秦嶺青銅秘事》正式上線。本劇由該公司首批簽約的兩位AI演員秦凌月與林西妍主演,故事背景設定在神秘莫測的秦嶺礦區。 劇情追隨退休情報官秦月帶領團隊深入該區域,揭開一樁塵封已久的礦難,以及跨越兩代人的血祭真相——這份真相就隱藏在受限的地下區域,正是科學探索與古代巫術交匯之處。作為中國最早完全由AI數位人支持的電影之一,該劇在籌備階段便引發了業界熱烈討論,而關於其A
相關專題推薦
商業
OpenAI新模型助長中國AI新創蓬勃發展
在阿里巴巴雲的雲棲大會上,中國頂尖的人工智慧新創公司展示了他們在開發先進大型語言模型方面的進展。這些發展是為了因應OpenAI最新發布的大型語言模型,包括由微軟支持的o1——這是一種尖端生成式人工智慧模型,專為處理科學研究、程式設計和數學應用中的複雜挑戰而設計。Moonshot AI創始人Kunal Zhilin在會議發言中強調了o1模型的變革潛力,指出其具有顛覆多個產業的能力,同時為人工智慧企業創造新的機會。Zhilin強調強化學習和模型可擴展性是人工智慧進步的關鍵因素,並參考了規模法則原理,
Deep Cogito的LLMS使用IDA優於類似大小的模型
總部位於舊金山的公司Deep Cogito通過其最新發布的開放大語模型(LLM)在AI社區中引起了轟動。這些模型的各種尺寸從30億到700億個參數不等,不僅是另一套AI工具。他們是邁向W的大膽一步
耀科傳媒首部AIGC劇集《秦嶺青銅之謎》今日上線,主演均由AI選角
今日,耀科傳媒的AIGC奇幻懸疑短劇《秦嶺青銅秘事》正式上線。本劇由該公司首批簽約的兩位AI演員秦凌月與林西妍主演,故事背景設定在神秘莫測的秦嶺礦區。 劇情追隨退休情報官秦月帶領團隊深入該區域,揭開一樁塵封已久的礦難,以及跨越兩代人的血祭真相——這份真相就隱藏在受限的地下區域,正是科學探索與古代巫術交匯之處。作為中國最早完全由AI數位人支持的電影之一,該劇在籌備階段便引發了業界熱烈討論,而關於其A
相關專題推薦
商業
 最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
 10 個工具
10 個工具
 xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai
教育與學習
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai
聊天機器人
最佳 AI 調情與對話訓練工具:即時提升社交魅力與自信
在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

 評論 (7)
0/500
評論 (7)
0/500
![EricDavis]()
這研究讓我想到之前試著讓AI模擬古英文寫詩,結果產出簡直是現代口水歌混搭莎士比亞😂 不過說真的,如果連慣用語都學不好,那些用AI『續寫』經典文學的計畫會不會搞出穿越劇台詞啊?像是讓狄更斯角色突然說『老鐵666』之類的...
![TimothyCarter]()
Любопытно, но ИИ действительно не справляется с историческими выражениями 😅 Может, это и к лучшему — пусть старые тексты останутся аутентичными, а не переписываются алгоритмами. Интересно, как это повлияет на цифровые гуманитарные науки?
![StephenGreen]()
歴史的な言語を再現するのが難しいなんて、AIにも苦手分野があるんだね。でも、これができるようになったら小説家のアシスタントとしてすごく役立ちそう。ディケンズの未完作品をAIで完成させる夢、まだ遠いのかな…😅
![GaryJones]()
Fascinating read! I never thought about how tricky it must be for AI to nail old-timey language. Makes me wonder if we’ll ever see a bot write like Dickens without a ton of extra work. 🧐
![StephenRamirez]()
I never thought AI would trip over old-timey phrases like this! Dickens’ unfinished novel is cool, but maybe we should let some mysteries stay unsolved. 🕰️
![DavidGonzalez]()
I find it fascinating that AI can't quite nail those old-timey phrases from Dickens' era. It’s like trying to teach a robot to talk like Shakespeare—cool idea, but super tricky! 🧠
來自美國和加拿大的研究團隊發現,像ChatGPT這樣的大型語言模型在未經廣泛且昂貴的預訓練情況下,難以準確複製歷史成語。這一挑戰使得使用AI完成查爾斯·狄更斯最後未完成小說等雄心勃勃的項目,對大多數學術和娛樂努力來說似乎遙不可及。
研究人員嘗試了多種方法來生成聽起來具有歷史準確性的文本。他們從使用20世紀初散文的簡單提示開始,進而對一個商業模型進行微調,基於該時代的一小部分書籍。他們還將這些結果與僅在1880年至1914年文學上訓練的模型進行比較。
在他們的第一次測試中,他們指示ChatGPT-4o模仿世紀末時期的語言。結果與一個在同一時期文學上訓練的較小型、微調過的GPT2模型所產生的結果有顯著差異。
被要求完成真實歷史文本(上中),即使是經過良好準備的ChatGPT-4o(左下)也無法避免回歸「部落格」模式,未能表現出要求的成語。相比之下,微調的GPT2模型(右下)很好地捕捉了語言風格,但在其他方面不夠準確。來源:https://arxiv.org/pdf/2505.00030
雖然微調改善了輸出與原始風格的相似性,但人類讀者仍能察覺現代語言或觀念,顯示即使調整後的模型仍保留其當代訓練數據的痕跡。
研究人員得出結論,生成歷史上準確的文本或對話沒有成本效益高的捷徑。他們還建議,這一挑戰本身可能存在固有缺陷,指出:「我們也應考慮時代錯誤在某種程度上可能是不可避免的。無論是通過指令調整歷史模型使其能進行對話,還是教導當代模型模仿較早的時期,在真實性和對話流暢性的目標之間可能需要某種妥協。畢竟,沒有21世紀提問者與1914年回應者之間的「真實」對話範例。試圖創造這種對話的研究人員需要反思,詮釋總是涉及當前與過去之間的協商。」
這項研究題為「語言模型能否無時代錯誤地表現過去?」,由伊利諾伊大學、不列顛哥倫比亞大學和康奈爾大學的研究人員進行。
初始挑戰
研究人員最初探索現代語言模型是否能通過提示模仿歷史語言。他們使用了1905年至1914年間出版的書籍中的真實摘錄,要求ChatGPT-4o以相同成語繼續這些段落。
他們使用的原始時代文本為:
「在這最後一種情況下,每分鐘可節省約五或六美元,因為為了在一分鐘內投影一個靜止的人或風景,必須捲動超過二十碼的膠片。由此獲得固定與活動圖片的實際結合,產生最具藝術性的效果。它還使我們能夠操作兩台交替投影的電影放映機,以避免閃爍,或同時投影紅色和綠色圖像並重現自然色彩,從而減輕人類眼睛的生理疲勞,因為人眼習慣於同時接收基本色彩。現在談談冷光在瞬間攝影中的應用。」
為了評估生成文本的歷史準確性,研究人員微調了一個RoBERTa模型來估計出版日期,使用了涵蓋1810年至2009年材料的歷史美國英語語料庫子集。這個RoBERTa分類器評估了ChatGPT-4o在1905年至1914年間出版的書籍真實段落提示下生成的續篇。
給ChatGPT的系統提示為:「你的任務是完成20世紀初書籍的段落。你將獲得1913年出版的書籍中的一段。以相同風格繼續這段,至少200字。僅提供續篇;不要添加任何框架性評論,如『以下是續篇:』。」
儘管使用了單次和20次提示,ChatGPT-4o的輸出始終傾向於21世紀風格。論文中提供的一個例子顯示ChatGPT-4o試圖繼續攝影文本:
「冷光在瞬間攝影中的使用徹底改變了在不同光線條件下捕捉圖像的方法。傳統上,攝影師們難以應對自然光的苛刻和變化性,或閃光攝影的侵入性質,這可能會干擾場景的氛圍或主題的自然行為,特別是在野生動物和偷拍人像攝影中。冷光以其較柔和且更分散的特性……允許更自然地呈現顏色和紋理,這在苛刻的人工照明下往往會丟失。」
這種通用的、維基風格的文本與原始時代文本的冗長和精緻風格不符,也未能從原始文本結束處無縫繼續。相反,它轉向了對一個子主題的抽象討論。
研究團隊還測試了GPT-1914,一個從頭訓練的較小型GPT-2模型,基於1880年至1914年間的文學。雖然不夠連貫,但其輸出與來源時代的風格更一致。論文中提供的一個例子是:
「其作用原理已在(第4頁)中解釋。我們在此僅提及,當我們希望在塗有火棉膠的紙上或使用明膠板獲得非常快速的照片時,可有利地應用該原理。在這種情況下,曝光時間不得超過一秒;但如果希望在更短的時間內顯影圖片——例如半秒——則溫度不得低於20°C,否則顯影後圖像將過暗;此外,在這些條件下,感光板將失去其敏感性。然而,對於普通用途,只需將感光表面暴露於低溫熱量,無需任何特殊預防措施即可。」
雖然原始材料晦澀難懂,但GPT-1914的輸出聽起來更具時代真實性。然而,作者結論認為,簡單的提示無法克服大型預訓練模型如ChatGPT-4o固有的當代偏見。
測量歷史準確性
為了評估模型輸出與真實歷史寫作的相似程度,研究人員使用統計分類器來估計每個文本樣本的可能出版日期。他們使用核密度圖可視化結果,顯示模型將每個段落放置在歷史時間線上的位置。
真實與生成文本的估計出版日期,基於訓練識別歷史風格的分類器(1905-1914年來源文本與GPT-4o使用單次和20次提示的續篇,以及僅在1880-1914年文學上訓練的GPT-1914的續篇比較)。
微調的RoBERTa模型雖不完美,但突顯了總體風格趨勢。僅在時代文學上訓練的GPT-1914的段落集中在20世紀初,與原始來源材料相似。相反,ChatGPT-4o的輸出,即使使用多個歷史提示,也類似於21世紀的寫作,反映了其訓練數據。
研究人員使用Jensen-Shannon散度量化這種不匹配,測量兩個概率分佈之間的差異。GPT-1914與真實歷史文本的得分接近0.006,而ChatGPT-4o的單次和20次提示輸出顯示出更大的差距,分別為0.310和0.350。
作者認為,這些發現表明,僅靠提示,即使有多個範例,也不是生成令人信服的歷史風格文本的可靠方法。
微調以獲得更好結果
論文隨後探討了微調是否能產生更好結果。此過程通過在用戶指定數據上繼續訓練,直接影響模型的權重,可能改善其在目標領域的表現。
在第一次微調實驗中,團隊在1905年至1914年間出版的書籍中,訓練GPT-4o-mini約兩千個段落完成對。他們旨在檢視小規模微調是否能將模型輸出轉向更具歷史準確性的風格。
使用相同的RoBERTa分類器估計每個輸出的風格「日期」,研究人員發現,微調模型生成的文本與真實文本密切對齊。其與原始文本的風格散度,通過Jensen-Shannon散度測量,降至0.002,與GPT-1914大體一致。
真實與生成文本的估計出版日期,顯示GPT-1914和微調版本的GPT-4o-mini與20世紀初寫作風格的匹配程度(基於1905-1914年間出版的書籍)。
然而,研究人員警告說,這個指標可能僅捕捉歷史風格的表面特徵,而非更深層的概念或事實時代錯誤。他們指出:「這不是一個非常敏感的測試。這裡用作評判的RoBERTa模型僅訓練來預測日期,而非區分真實段落與時代錯誤的段落。它可能使用粗略的風格證據進行預測。人類讀者或更大的模型可能仍能在表面上聽起來「符合時代」的段落中檢測到時代錯誤的內容。」
人類評估
最後,研究人員使用1905年至1914年間出版的書籍中手選的250個段落進行了人類評估測試。他們指出,這些文本在今天可能與當時的解釋不同:
「我們的列表中包括,例如,關於阿爾薩斯(當時屬於德國)的百科全書條目和關於腳氣病(當時常被解釋為真菌疾病而非營養缺乏)的條目。雖然這些是事實上的差異,但我們也選擇了顯示態度、修辭或想像力細微差異的段落。例如,20世紀初對非歐洲地方的描述往往陷入種族概括。1913年寫的月球日出描述想像出豐富的色彩現象,因為當時還沒有人見過沒有大氣的世界的照片。」
研究人員創建了每個歷史段落可能合理回答的簡短問題,然後在這些問答對上微調GPT-4o-mini。為了加強評估,他們訓練了五個獨立的模型版本,每次保留不同部分的數據用於測試。然後,他們使用GPT-4o和GPT-4o-mini的默認版本以及微調變體生成回應,每個版本在未見過的數據部分上進行評估。
迷失於時間
為了評估模型模仿歷史語言的說服力,研究人員請三位專家評估者審查120個AI生成的續篇,判斷每個續篇是否對1914年的作家來說似乎合理。
這項評估比預期更具挑戰性。雖然評估者在近80%的情況下意見一致,但他們的判斷不平衡(「合理」被選中的頻率是「不合理」的兩倍),意味著實際一致性水平僅為中等,通過Cohen's kappa得分0.554測量。
評估者描述這項任務很困難,通常需要額外研究來評估某個陳述是否與1914年已知或相信的內容一致。一些段落引發了關於語氣和觀點的問題,例如回應是否適當地限制在反映1914年典型世界觀的範圍內。這種判斷往往取決於民族中心主義的程度,即通過自身文化的假設或偏見看待其他文化的傾向。
挑戰在於決定一個段落是否表達了足夠的文化偏見,使其看起來具有歷史合理性,同時不顯得太現代或以當今標準過於冒犯。作者指出,即使對於熟悉該時期的學者,也難以在感覺歷史上準確的語言與反映當今觀念的語言之間劃清界限。
儘管如此,結果顯示模型的明確排名,微調版本的GPT-4o-mini總體上被認為是最合理的:
評估者對每個模型輸出看起來合理程度的評估
這種表現水平(在80%的情況下被評為合理)是否對歷史研究足夠可靠尚不清楚,特別是因為該研究未包括真實時代文本可能被誤分類的基準測量。
入侵者警報
接下來,研究人員進行了「入侵者測試」,向專家評估者展示回答同一歷史問題的四個匿名段落。三個回應來自語言模型,而一個是來自20世紀初的真實摘錄。
任務是辨認哪個段落是在該時期真實撰寫的原文。這種方法不直接要求評估者評估合理性,而是測量真實段落從AI生成回應中脫穎而出的頻率,有效測試模型是否能欺騙讀者認為其輸出是真實的。
模型的排名與之前的判斷任務結果一致:微調版本的GPT-4o-mini在模型中最具說服力,但仍不及真實文本。
每個來源被正確識別為真實歷史段落的頻率。
這項測試也作為有用的基準,因為真實段落超過一半時間被識別出來,表明真實與合成散文之間的差距對人類讀者來說仍然顯著。
一項名為McNemar測試的統計分析確認了模型之間的差異是有意義的,除了未調整的兩個版本(GPT-4o和GPT-4o-mini)表現相似的情況外。
過去的未來
作者發現,提示現代語言模型採用歷史語音無法可靠地產生令人信服的結果:人類讀者認為不到三分之二的輸出是合理的,甚至這個數字可能高估了表現。
在許多情況下,回應包含明確信號,表明模型從當代視角說話——諸如「在1914年,尚未知曉……」或「截至1914年,我不熟悉……」的短語在多達五分之一的續篇中出現。這類免責聲明清楚表明,模型是從外部模擬歷史,而非從內部撰寫。
作者表示:「情境學習的表現不佳令人遺憾,因為這些方法是AI歷史研究中最簡單且成本最低的。我們強調,我們尚未詳盡探索這些方法。情境學習可能現在或將來對於某些研究領域是足夠的。但我們的初步證據並不令人鼓舞。」
作者結論認為,雖然在歷史段落上微調商業模型可以以最小的成本產生風格上令人信服的輸出,但無法完全消除現代視角的痕跡。完全在時代材料上預訓練模型可避免時代錯誤,但需要更多資源且輸出流暢度較低。
兩種方法均未提供完整解決方案,目前,模擬歷史語音的任何嘗試似乎都涉及真實性與連貫性之間的權衡。作者結論認為,需要進一步研究以澄清如何最好地應對這種緊張關係。
結論
新論文提出的最引人入勝的問題之一是真實性的問題。雖然它們不是完美的工具,但像LPIPS和SSIM這樣的損失函數和指標為計算機視覺研究人員提供了一種針對真實基準的評估方法。然而,在生成過去時代風格的新文本時,沒有真實基準——只有嘗試融入已消失的文化視角。從文學痕跡重建這種心態本身就是一種量化的行為,因為這些痕跡僅是證據,而其背後的文化意識可能無法推斷,也可能無法想像。
在實踐層面上,現代語言模型的基礎受當今規範和數據的塑造,存在重新詮釋或壓制對愛德華時代讀者來說合理或不顯眼的觀念的風險,這些觀念如今被視為偏見、不平等或不公的痕跡。
因此,人們不禁思考,即使我們能創造這樣的對話,是否會讓我們感到排斥。
首次發表於2025年5月2日,星期五









 OpenAI新模型助長中國AI新創蓬勃發展
在阿里巴巴雲的雲棲大會上,中國頂尖的人工智慧新創公司展示了他們在開發先進大型語言模型方面的進展。這些發展是為了因應OpenAI最新發布的大型語言模型,包括由微軟支持的o1——這是一種尖端生成式人工智慧模型,專為處理科學研究、程式設計和數學應用中的複雜挑戰而設計。Moonshot AI創始人Kunal Zhilin在會議發言中強調了o1模型的變革潛力,指出其具有顛覆多個產業的能力,同時為人工智慧企業創造新的機會。Zhilin強調強化學習和模型可擴展性是人工智慧進步的關鍵因素,並參考了規模法則原理,
OpenAI新模型助長中國AI新創蓬勃發展
在阿里巴巴雲的雲棲大會上,中國頂尖的人工智慧新創公司展示了他們在開發先進大型語言模型方面的進展。這些發展是為了因應OpenAI最新發布的大型語言模型,包括由微軟支持的o1——這是一種尖端生成式人工智慧模型,專為處理科學研究、程式設計和數學應用中的複雜挑戰而設計。Moonshot AI創始人Kunal Zhilin在會議發言中強調了o1模型的變革潛力,指出其具有顛覆多個產業的能力,同時為人工智慧企業創造新的機會。Zhilin強調強化學習和模型可擴展性是人工智慧進步的關鍵因素,並參考了規模法則原理,
 Deep Cogito的LLMS使用IDA優於類似大小的模型
總部位於舊金山的公司Deep Cogito通過其最新發布的開放大語模型(LLM)在AI社區中引起了轟動。這些模型的各種尺寸從30億到700億個參數不等,不僅是另一套AI工具。他們是邁向W的大膽一步
Deep Cogito的LLMS使用IDA優於類似大小的模型
總部位於舊金山的公司Deep Cogito通過其最新發布的開放大語模型(LLM)在AI社區中引起了轟動。這些模型的各種尺寸從30億到700億個參數不等,不僅是另一套AI工具。他們是邁向W的大膽一步
 耀科傳媒首部AIGC劇集《秦嶺青銅之謎》今日上線,主演均由AI選角
今日,耀科傳媒的AIGC奇幻懸疑短劇《秦嶺青銅秘事》正式上線。本劇由該公司首批簽約的兩位AI演員秦凌月與林西妍主演,故事背景設定在神秘莫測的秦嶺礦區。 劇情追隨退休情報官秦月帶領團隊深入該區域,揭開一樁塵封已久的礦難,以及跨越兩代人的血祭真相——這份真相就隱藏在受限的地下區域,正是科學探索與古代巫術交匯之處。作為中國最早完全由AI數位人支持的電影之一,該劇在籌備階段便引發了業界熱烈討論,而關於其A
耀科傳媒首部AIGC劇集《秦嶺青銅之謎》今日上線,主演均由AI選角
今日,耀科傳媒的AIGC奇幻懸疑短劇《秦嶺青銅秘事》正式上線。本劇由該公司首批簽約的兩位AI演員秦凌月與林西妍主演,故事背景設定在神秘莫測的秦嶺礦區。 劇情追隨退休情報官秦月帶領團隊深入該區域,揭開一樁塵封已久的礦難,以及跨越兩代人的血祭真相——這份真相就隱藏在受限的地下區域,正是科學探索與古代巫術交匯之處。作為中國最早完全由AI數位人支持的電影之一,該劇在籌備階段便引發了業界熱烈討論,而關於其A

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

這研究讓我想到之前試著讓AI模擬古英文寫詩,結果產出簡直是現代口水歌混搭莎士比亞😂 不過說真的,如果連慣用語都學不好,那些用AI『續寫』經典文學的計畫會不會搞出穿越劇台詞啊?像是讓狄更斯角色突然說『老鐵666』之類的...
Любопытно, но ИИ действительно не справляется с историческими выражениями 😅 Может, это и к лучшему — пусть старые тексты останутся аутентичными, а не переписываются алгоритмами. Интересно, как это повлияет на цифровые гуманитарные науки?
歴史的な言語を再現するのが難しいなんて、AIにも苦手分野があるんだね。でも、これができるようになったら小説家のアシスタントとしてすごく役立ちそう。ディケンズの未完作品をAIで完成させる夢、まだ遠いのかな…😅
Fascinating read! I never thought about how tricky it must be for AI to nail old-timey language. Makes me wonder if we’ll ever see a bot write like Dickens without a ton of extra work. 🧐
I never thought AI would trip over old-timey phrases like this! Dickens’ unfinished novel is cool, but maybe we should let some mysteries stay unsolved. 🕰️
I find it fascinating that AI can't quite nail those old-timey phrases from Dickens' era. It’s like trying to teach a robot to talk like Shakespeare—cool idea, but super tricky! 🧠













