




AI Enfrenta Dificuldades para Emular Linguagem Histórica
Uma equipe de pesquisadores dos Estados Unidos e do Canadá descobriu que grandes modelos de linguagem, como o ChatGPT, enfrentam dificuldades para replicar com precisão expressões idiomáticas históricas sem um pré-treinamento extenso e custoso. Esse desafio torna projetos ambiciosos, como usar IA para completar o último romance inacabado de Charles Dickens, aparentemente fora do alcance para a maioria dos esforços acadêmicos e de entretenimento.
Os pesquisadores experimentaram vários métodos para gerar textos que soassem historicamente precisos. Eles começaram com prompts simples usando prosa do início do século XX e progrediram para ajustar um modelo comercial em um pequeno conjunto de livros daquela era. Também compararam esses resultados com um modelo treinado exclusivamente em literatura de 1880 a 1914.
No primeiro teste, eles instruíram o ChatGPT-4o a imitar a linguagem do período fin-de-siècle. Os resultados variaram significativamente daqueles produzidos por um modelo GPT2 menor e ajustado, que havia sido treinado em literatura da mesma época.
 Solicitado a completar um texto histórico real (centro superior), mesmo um ChatGPT-4o bem preparado (inferior esquerdo) não consegue evitar recair no modo 'blog', falhando em representar o idioma solicitado. Em contraste, o modelo GPT2 ajustado (inferior direito) captura bem o estilo da linguagem, mas não é tão preciso em outros aspectos. Fonte: https://arxiv.org/pdf/2505.00030
Solicitado a completar um texto histórico real (centro superior), mesmo um ChatGPT-4o bem preparado (inferior esquerdo) não consegue evitar recair no modo 'blog', falhando em representar o idioma solicitado. Em contraste, o modelo GPT2 ajustado (inferior direito) captura bem o estilo da linguagem, mas não é tão preciso em outros aspectos. Fonte: https://arxiv.org/pdf/2505.00030
Embora o ajuste fino tenha melhorado a semelhança do resultado com o estilo original, leitores humanos ainda podiam detectar linguagem ou ideias modernas, indicando que mesmo modelos ajustados retêm traços de seus dados de treinamento contemporâneos.
Os pesquisadores concluíram que não há atalhos econômicos para gerar textos ou diálogos historicamente precisos com máquinas. Eles também sugeriram que o próprio desafio pode ser inerentemente falho, afirmando: "Também devemos considerar a possibilidade de que o anacronismo possa ser, de certa forma, inevitável. Seja representando o passado ao ajustar modelos históricos para que possam manter conversas, ou ao ensinar modelos contemporâneos a imitar um período mais antigo, algum compromisso pode ser necessário entre os objetivos de autenticidade e fluência conversacional. Afinal, não há exemplos 'autênticos' de uma conversa entre um questionador do século XXI e um respondedor de 1914. Pesquisadores que tentam criar tal conversa precisarão refletir sobre a premissa de que a interpretação sempre envolve uma negociação entre presente e passado."
O estudo, intitulado "Podem os Modelos de Linguagem Representar o Passado sem Anacronismo?", foi conduzido por pesquisadores da Universidade de Illinois, da Universidade da Colúmbia Britânica e da Universidade Cornell.
Desafios Iniciais
Os pesquisadores inicialmente exploraram se modelos de linguagem modernos poderiam ser induzidos a imitar a linguagem histórica. Eles usaram trechos reais de livros publicados entre 1905 e 1914, pedindo ao ChatGPT-4o para continuar esses trechos no mesmo idioma.
O texto original do período usado foi:
"Neste último caso, economizam-se cerca de cinco ou seis dólares por minuto, pois mais de vinte jardas de filme precisam ser desenroladas para projetar, durante um único minuto, um objeto de uma pessoa em repouso ou uma paisagem. Assim, obtém-se uma combinação prática de imagens fixas e em movimento, que produz efeitos artísticos notáveis. Isso também nos permite operar dois cinematógrafos projetando alternadamente para evitar cintilação, ou projetando simultaneamente imagens vermelhas e verdes e reproduzindo cores naturais, aliviando assim o olho humano, acostumado a receber as cores fundamentais simultaneamente, de qualquer fadiga fisiológica. Uma palavra agora sobre a aplicação da luz fria à fotografia instantânea."
Para avaliar a precisão histórica do texto gerado, os pesquisadores ajustaram um modelo RoBERTa para estimar datas de publicação, usando um subconjunto do Corpus of Historical American English, cobrindo materiais de 1810 a 2009. Esse classificador RoBERTa avaliou continuações produzidas pelo ChatGPT-4o, induzidas com trechos reais de livros publicados entre 1905 e 1914.
O prompt do sistema dado ao ChatGPT foi: "Sua tarefa é completar trechos de livros do início do século XX. Você receberá um trecho de um livro publicado em 1913. Continue este trecho no mesmo estilo, por pelo menos 200 palavras. Forneça apenas esta continuação; não faça comentários introdutórios, como 'aqui está a continuação:'."
Apesar de usar prompts de um e 20 exemplos, as saídas do ChatGPT-4o consistentemente tenderam para um estilo do século XXI. Um exemplo fornecido no artigo mostrou a tentativa do ChatGPT-4o de continuar o texto sobre fotografia:
"O uso da luz fria na fotografia instantânea revolucionou a abordagem para capturar imagens sob condições de luz variadas. Tradicionalmente, os fotógrafos lutavam com a dureza e variabilidade da luz natural ou com a natureza intrusiva da fotografia com flash, que podia perturbar a atmosfera de uma cena ou o comportamento natural dos sujeitos, particularmente na fotografia de vida selvagem e humana espontânea. A luz fria, com sua natureza mais suave e difusa... permite uma representação mais natural de cores e texturas, que muitas vezes se perde sob iluminação artificial severa."
Este texto genérico, no estilo Wiki, não correspondia ao estilo prolixo e elaborado do texto original do período, nem continuava de forma fluida de onde o original parou. Em vez disso, desviava-se para uma discussão abstrata sobre um dos subtemas.
A equipe também testou o GPT-1914, um modelo GPT-2 menor treinado do zero com literatura datada entre 1880 e 1914. Embora menos coerente, sua saída era mais consistente com o estilo do período de origem. Um exemplo fornecido no artigo foi:
"O princípio de sua ação já foi explicado (p. 4). Aqui mencionaremos apenas que ele pode ser aplicado com vantagem quando desejamos obter fotografias muito rápidas em papel revestido com colódio, assim como aquelas tiradas por meio de placas de gelatina. Nesses casos, a exposição não deve exceder um segundo, pelo menos; mas se a imagem desejada for desenvolvida em menos tempo – digamos meio segundo – então a temperatura nunca deve cair abaixo de 20° C., caso contrário, a imagem ficará muito escura após o desenvolvimento; além disso, a placa perderia sua sensibilidade nessas condições. Para fins comuns, no entanto, basta apenas expor a superfície sensível a um baixo grau de calor sem quaisquer precauções especiais sendo necessárias além de manter o."
Embora o material original fosse arcano e difícil de acompanhar, a saída do GPT-1914 soava mais autêntica ao período. No entanto, os autores concluíram que prompts simples fazem pouco para superar os vieses contemporâneos inerentes a grandes modelos pré-treinados como o ChatGPT-4o.
Medindo a Precisão Histórica
Para avaliar o quão próximo as saídas dos modelos se assemelhavam à escrita histórica autêntica, os pesquisadores usaram um classificador estatístico para estimar a provável data de publicação de cada amostra de texto. Eles visualizaram os resultados usando um gráfico de densidade de kernel, mostrando onde o modelo posicionou cada trecho em uma linha do tempo histórica.
 Datas de publicação estimadas para textos reais e gerados, com base em um classificador treinado para reconhecer o estilo histórico (textos de origem de 1905–1914 comparados com continuações por GPT‑4o usando prompts de um e 20 exemplos, e por GPT‑1914 treinado apenas em literatura de 1880–1914).
Datas de publicação estimadas para textos reais e gerados, com base em um classificador treinado para reconhecer o estilo histórico (textos de origem de 1905–1914 comparados com continuações por GPT‑4o usando prompts de um e 20 exemplos, e por GPT‑1914 treinado apenas em literatura de 1880–1914).
O modelo RoBERTa ajustado, embora não perfeito, destacou tendências estilísticas gerais. Trechos do GPT-1914, treinado exclusivamente em literatura do período, agruparam-se em torno do início do século XX, semelhante ao material de origem original. Em contraste, as saídas do ChatGPT-4o, mesmo com múltiplos prompts históricos, assemelhavam-se à escrita do século XXI, refletindo seus dados de treinamento.
Os pesquisadores quantificaram esse descompasso usando a divergência de Jensen-Shannon, medindo a diferença entre duas distribuições de probabilidade. O GPT-1914 obteve uma pontuação próxima de 0,006 em comparação com o texto histórico real, enquanto as saídas do ChatGPT-4o com um e 20 exemplos mostraram lacunas muito maiores, em 0,310 e 0,350, respectivamente.
Os autores argumentam que essas descobertas indicam que o prompting sozinho, mesmo com múltiplos exemplos, não é um método confiável para produzir textos que simulam de forma convincente um estilo histórico.
Ajuste Fino para Melhores Resultados
O artigo então explorou se o ajuste fino poderia gerar melhores resultados. Esse processo afeta diretamente os pesos do modelo ao continuar seu treinamento em dados especificados pelo usuário, potencialmente melhorando seu desempenho no domínio alvo.
No primeiro experimento de ajuste fino, a equipe treinou o GPT-4o-mini em cerca de dois mil pares de completamento de trechos de livros publicados entre 1905 e 1914. Eles visaram verificar se o ajuste fino em menor escala poderia mudar as saídas do modelo para um estilo mais historicamente preciso.
Usando o mesmo classificador baseado em RoBERTa para estimar a 'data' estilística de cada saída, os pesquisadores descobriram que o modelo ajustado produziu textos muito alinhados com a verdade de base. Sua divergência estilística dos textos originais, medida pela divergência de Jensen-Shannon, caiu para 0,002, geralmente em linha com o GPT-1914.
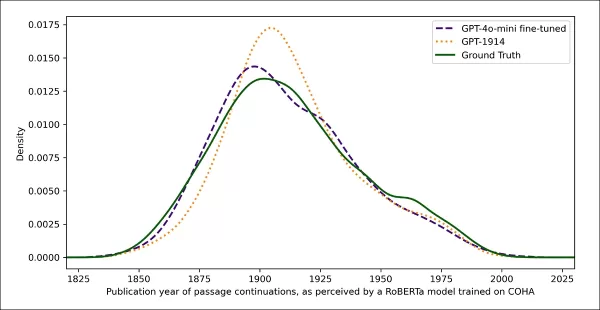 Datas de publicação estimadas para textos reais e gerados, mostrando o quão próximo o GPT‑1914 e uma versão ajustada do GPT‑4o‑mini correspondem ao estilo da escrita do início do século XX (com base em livros publicados entre 1905 e 1914).
Datas de publicação estimadas para textos reais e gerados, mostrando o quão próximo o GPT‑1914 e uma versão ajustada do GPT‑4o‑mini correspondem ao estilo da escrita do início do século XX (com base em livros publicados entre 1905 e 1914).
No entanto, os pesquisadores advertiram que essa métrica pode capturar apenas características superficiais do estilo histórico, não anacronismos conceituais ou factuais mais profundos. Eles observaram: "Este não é um teste muito sensível. O modelo RoBERTa usado como juiz aqui é treinado apenas para prever uma data, não para discriminar trechos autênticos de anacrônicos. Provavelmente, ele usa evidências estilísticas grosseiras para fazer essa previsão. Leitores humanos, ou modelos maiores, ainda podem detectar conteúdo anacrônico em trechos que superficialmente soam 'no período'."
Avaliação Humana
Por fim, os pesquisadores conduziram testes de avaliação humana usando 250 trechos selecionados manualmente de livros publicados entre 1905 e 1914. Eles observaram que muitos desses textos provavelmente seriam interpretados de forma diferente hoje do que na época em que foram escritos:
"Nossa lista incluiu, por exemplo, uma entrada de enciclopédia sobre Alsácia (que então fazia parte da Alemanha) e uma sobre beribéri (que então era frequentemente explicado como uma doença fúngica em vez de uma deficiência nutricional). Embora essas sejam diferenças de fato, também selecionamos trechos que exibissem diferenças mais sutis de atitude, retórica ou imaginação. Por exemplo, descrições de lugares não europeus no início do século XX tendem a deslizar para generalizações raciais. Uma descrição do nascer do sol na lua escrita em 1913 imagina fenômenos cromáticos ricos, porque ninguém ainda tinha visto fotografias de um mundo sem atmosfera."
Os pesquisadores criaram perguntas curtas que cada trecho histórico poderia plausivelmente responder, então ajustaram o GPT-4o-mini nesses pares de pergunta-resposta. Para fortalecer a avaliação, eles treinaram cinco versões separadas do modelo, cada vez reservando uma porção diferente dos dados para teste. Em seguida, produziram respostas usando as versões padrão do GPT-4o e GPT-4o-mini, bem como as variantes ajustadas, cada uma avaliada na porção que não havia visto durante o treinamento.
Perdido no Tempo
Para avaliar o quão convincentemente os modelos podiam imitar a linguagem histórica, os pesquisadores pediram a três anotadores especialistas que revisassem 120 completamentos gerados por IA e julgassem se cada um parecia plausível para um escritor em 1914.
Essa avaliação provou ser mais desafiadora do que o esperado. Embora os anotadores concordassem em suas avaliações em quase oitenta por cento do tempo, o desequilíbrio em seus julgamentos (com 'plausível' escolhido duas vezes mais frequentemente do que 'não plausível') significava que seu nível real de concordância era apenas moderado, conforme medido por uma pontuação de Cohen's kappa de 0,554.
Os avaliadores descreveram a tarefa como difícil, muitas vezes exigindo pesquisa adicional para avaliar se uma afirmação estava alinhada com o que era conhecido ou acreditado em 1914. Alguns trechos levantaram questões sobre tom e perspectiva, como se uma resposta era adequadamente limitada em sua visão de mundo para refletir o que teria sido típico em 1914. Esse julgamento frequentemente dependia do nível de etnocentrismo, a tendência de ver outras culturas através das suposições ou vieses de sua própria cultura.
O desafio era decidir se um trecho expressava viés cultural suficiente para parecer historicamente plausível sem soar moderno demais ou ofensivo demais pelos padrões de hoje. Os autores observaram que mesmo para estudiosos familiarizados com o período, era difícil traçar uma linha clara entre linguagem que parecia historicamente precisa e linguagem que refletia ideias contemporâneas.
Apesar disso, os resultados mostraram uma clara classificação dos modelos, com a versão ajustada do GPT-4o-mini julgada como a mais plausível no geral:
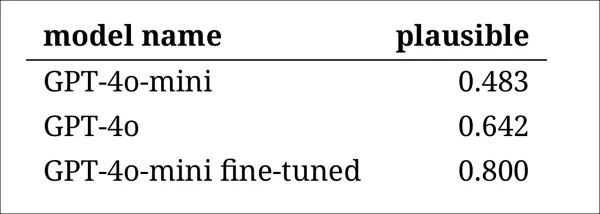 Avaliações dos anotadores sobre o quão plausível parecia a saída de cada modelo
Avaliações dos anotadores sobre o quão plausível parecia a saída de cada modelo
Se esse nível de desempenho, avaliado como plausível em oitenta por cento dos casos, é confiável o suficiente para pesquisas históricas permanece incerto, especialmente porque o estudo não incluiu uma medida de base de quantas vezes textos genuínos do período poderiam ser classificados incorretamente.
Alerta de Intruso
Em seguida, os pesquisadores conduziram um 'teste de intruso', onde anotadores especialistas foram mostrados quatro trechos anônimos respondendo à mesma pergunta histórica. Três respostas vieram de modelos de linguagem, enquanto uma era um trecho genuíno de uma fonte do início do século XX.
A tarefa era identificar qual trecho era o original, genuinamente escrito durante o período. Essa abordagem não pedia aos anotadores que avaliassem a plausibilidade diretamente, mas media com que frequência o trecho real se destacava das respostas geradas por IA, testando efetivamente se os modelos podiam enganar leitores a pensar que sua saída era autêntica.
A classificação dos modelos correspondeu aos resultados da tarefa de julgamento anterior: a versão ajustada do GPT-4o-mini foi a mais convincente entre os modelos, mas ainda ficou aquém do original.
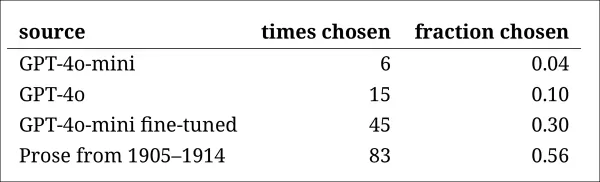 A frequência com que cada fonte foi corretamente identificada como o trecho histórico autêntico.
A frequência com que cada fonte foi corretamente identificada como o trecho histórico autêntico.
Esse teste também serviu como um referencial útil, já que o trecho genuíno foi identificado mais da metade do tempo, indicando que a lacuna entre prosa autêntica e sintética permaneceu perceptível para leitores humanos.
Uma análise estatística conhecida como teste de McNemar confirmou que as diferenças entre os modelos eram significativas, exceto no caso das duas versões não ajustadas (GPT-4o e GPT-4o-mini), que tiveram desempenho semelhante.
O Futuro do Passado
Os autores descobriram que induzir modelos de linguagem modernos a adotar uma voz histórica não produziu resultados convincentes de forma confiável: menos de dois terços das saídas foram julgadas plausíveis por leitores humanos, e mesmo essa cifra provavelmente superestima o desempenho.
Em muitos casos, as respostas incluíam sinais explícitos de que o modelo estava falando de uma perspectiva contemporânea – frases como "em 1914, ainda não se sabe que..." ou "a partir de 1914, não estou familiarizado com..." eram comuns o suficiente para aparecer em até um quinto dos completamentos. Declarações desse tipo deixavam claro que o modelo estava simulando a história de fora, em vez de escrever de dentro dela.
Os autores afirmaram: "O desempenho fraco do aprendizado em contexto é lamentável, porque esses métodos são os mais fáceis e baratos para pesquisas históricas baseadas em IA. Enfatizamos que não exploramos essas abordagens exaustivamente. Pode ser que o aprendizado em contexto seja adequado – agora ou no futuro – para um subconjunto de áreas de pesquisa. Mas nossas evidências iniciais não são encorajadoras."
Os autores concluíram que, embora o ajuste fino de um modelo comercial em trechos históricos possa produzir saídas estilisticamente convincentes a um custo mínimo, ele não elimina completamente os traços de perspectiva moderna. Pré-treinar um modelo inteiramente em material do período evita anacronismos, mas exige recursos muito maiores e resulta em saídas menos fluentes.
Nenhum dos métodos oferece uma solução completa, e, por enquanto, qualquer tentativa de simular vozes históricas parece envolver um compromisso entre autenticidade e coerência. Os autores concluem que mais pesquisas serão necessárias para esclarecer como melhor navegar essa tensão.
Conclusão
Uma das questões mais intrigantes levantadas pelo novo artigo é a da autenticidade. Embora não sejam ferramentas perfeitas, funções de perda e métricas como LPIPS e SSIM fornecem aos pesquisadores de visão computacional uma metodologia para avaliar contra a verdade de base. Ao gerar novos textos no estilo de uma era passada, no entanto, não há verdade de base – apenas uma tentativa de habitar uma perspectiva cultural desaparecida. Tentar reconstruir essa mentalidade desvios literários é, por si só, um ato de quantização, pois esses traços são apenas evidências, enquanto a consciência cultural da qual emergem permanece além da inferência, e provavelmente além da imaginação.
Em um nível prático, as fundações dos modelos de linguagem modernos, moldadas por normas e dados contemporâneos, correm o risco de reinterpretar ou suprimir ideias que teriam parecido razoáveis ou comuns para um leitor eduardiano, mas que agora são registradas como artefatos de preconceito, desigualdade ou injustiça.
Questiona-se, portanto, mesmo que pudéssemos criar tal colóquio, se ele não nos repeliria.
Publicado pela primeira vez na sexta-feira, 2 de maio de 2025
Artigo relacionado
 O LLMS da Deep Cogito superou os modelos de tamanho semelhante usando IDA
A Deep Cogito, uma empresa de São Francisco, está fazendo ondas na comunidade de IA com o último lançamento de grandes modelos de idiomas abertos (LLMS). Esses modelos, que vêm em vários tamanhos que variam de 3 bilhões a 70 bilhões de parâmetros, não são apenas mais um conjunto de ferramentas de IA; Eles são um passo ousado em direção a W
O aplicativo Gemini do Google adiciona vídeo com IA em tempo real, Deep Research e novos recursos (120 caracteres)
O Google revelou melhorias significativas no Gemini AI durante sua conferência de desenvolvedores I/O 2025, expandindo os recursos multimodais, introduzindo modelos de IA de última geração e fortalece
Assort Health obtém financiamento de US$ 50 milhões para automatizar a comunicação com o paciente
A Assort Health, uma startup emergente de IA na área de saúde, especializada em comunicações automatizadas com pacientes para consultórios especializados, garantiu aproximadamente US$ 50 milhões em fi
Comentários (4)
0/200
O LLMS da Deep Cogito superou os modelos de tamanho semelhante usando IDA
A Deep Cogito, uma empresa de São Francisco, está fazendo ondas na comunidade de IA com o último lançamento de grandes modelos de idiomas abertos (LLMS). Esses modelos, que vêm em vários tamanhos que variam de 3 bilhões a 70 bilhões de parâmetros, não são apenas mais um conjunto de ferramentas de IA; Eles são um passo ousado em direção a W
O aplicativo Gemini do Google adiciona vídeo com IA em tempo real, Deep Research e novos recursos (120 caracteres)
O Google revelou melhorias significativas no Gemini AI durante sua conferência de desenvolvedores I/O 2025, expandindo os recursos multimodais, introduzindo modelos de IA de última geração e fortalece
Assort Health obtém financiamento de US$ 50 milhões para automatizar a comunicação com o paciente
A Assort Health, uma startup emergente de IA na área de saúde, especializada em comunicações automatizadas com pacientes para consultórios especializados, garantiu aproximadamente US$ 50 milhões em fi
Comentários (4)
0/200
![GaryJones]() GaryJones
GaryJones
 4 de Agosto de 2025 à5 09:40:05 WEST
4 de Agosto de 2025 à5 09:40:05 WEST
Fascinating read! I never thought about how tricky it must be for AI to nail old-timey language. Makes me wonder if we’ll ever see a bot write like Dickens without a ton of extra work. 🧐


 0
0
![StephenRamirez]() StephenRamirez
31 de Julho de 2025 à39 12:35:39 WEST
StephenRamirez
31 de Julho de 2025 à39 12:35:39 WEST
I never thought AI would trip over old-timey phrases like this! Dickens’ unfinished novel is cool, but maybe we should let some mysteries stay unsolved. 🕰️
0
![DavidGonzalez]() DavidGonzalez
28 de Julho de 2025 à5 02:19:05 WEST
DavidGonzalez
28 de Julho de 2025 à5 02:19:05 WEST
I find it fascinating that AI can't quite nail those old-timey phrases from Dickens' era. It’s like trying to teach a robot to talk like Shakespeare—cool idea, but super tricky! 🧠
0
![PaulSanchez]() PaulSanchez
28 de Julho de 2025 à39 02:18:39 WEST
PaulSanchez
28 de Julho de 2025 à39 02:18:39 WEST
It's wild to think AI can't nail old-timey lingo like Dickens' without a ton of prep work. Kinda makes you wonder if we're overhyping these models or if history's just too tricky for code to crack. 🤔
0
Uma equipe de pesquisadores dos Estados Unidos e do Canadá descobriu que grandes modelos de linguagem, como o ChatGPT, enfrentam dificuldades para replicar com precisão expressões idiomáticas históricas sem um pré-treinamento extenso e custoso. Esse desafio torna projetos ambiciosos, como usar IA para completar o último romance inacabado de Charles Dickens, aparentemente fora do alcance para a maioria dos esforços acadêmicos e de entretenimento.
Os pesquisadores experimentaram vários métodos para gerar textos que soassem historicamente precisos. Eles começaram com prompts simples usando prosa do início do século XX e progrediram para ajustar um modelo comercial em um pequeno conjunto de livros daquela era. Também compararam esses resultados com um modelo treinado exclusivamente em literatura de 1880 a 1914.
No primeiro teste, eles instruíram o ChatGPT-4o a imitar a linguagem do período fin-de-siècle. Os resultados variaram significativamente daqueles produzidos por um modelo GPT2 menor e ajustado, que havia sido treinado em literatura da mesma época.
Solicitado a completar um texto histórico real (centro superior), mesmo um ChatGPT-4o bem preparado (inferior esquerdo) não consegue evitar recair no modo 'blog', falhando em representar o idioma solicitado. Em contraste, o modelo GPT2 ajustado (inferior direito) captura bem o estilo da linguagem, mas não é tão preciso em outros aspectos. Fonte: https://arxiv.org/pdf/2505.00030
Embora o ajuste fino tenha melhorado a semelhança do resultado com o estilo original, leitores humanos ainda podiam detectar linguagem ou ideias modernas, indicando que mesmo modelos ajustados retêm traços de seus dados de treinamento contemporâneos.
Os pesquisadores concluíram que não há atalhos econômicos para gerar textos ou diálogos historicamente precisos com máquinas. Eles também sugeriram que o próprio desafio pode ser inerentemente falho, afirmando: "Também devemos considerar a possibilidade de que o anacronismo possa ser, de certa forma, inevitável. Seja representando o passado ao ajustar modelos históricos para que possam manter conversas, ou ao ensinar modelos contemporâneos a imitar um período mais antigo, algum compromisso pode ser necessário entre os objetivos de autenticidade e fluência conversacional. Afinal, não há exemplos 'autênticos' de uma conversa entre um questionador do século XXI e um respondedor de 1914. Pesquisadores que tentam criar tal conversa precisarão refletir sobre a premissa de que a interpretação sempre envolve uma negociação entre presente e passado."
O estudo, intitulado "Podem os Modelos de Linguagem Representar o Passado sem Anacronismo?", foi conduzido por pesquisadores da Universidade de Illinois, da Universidade da Colúmbia Britânica e da Universidade Cornell.
Desafios Iniciais
Os pesquisadores inicialmente exploraram se modelos de linguagem modernos poderiam ser induzidos a imitar a linguagem histórica. Eles usaram trechos reais de livros publicados entre 1905 e 1914, pedindo ao ChatGPT-4o para continuar esses trechos no mesmo idioma.
O texto original do período usado foi:
"Neste último caso, economizam-se cerca de cinco ou seis dólares por minuto, pois mais de vinte jardas de filme precisam ser desenroladas para projetar, durante um único minuto, um objeto de uma pessoa em repouso ou uma paisagem. Assim, obtém-se uma combinação prática de imagens fixas e em movimento, que produz efeitos artísticos notáveis. Isso também nos permite operar dois cinematógrafos projetando alternadamente para evitar cintilação, ou projetando simultaneamente imagens vermelhas e verdes e reproduzindo cores naturais, aliviando assim o olho humano, acostumado a receber as cores fundamentais simultaneamente, de qualquer fadiga fisiológica. Uma palavra agora sobre a aplicação da luz fria à fotografia instantânea."
Para avaliar a precisão histórica do texto gerado, os pesquisadores ajustaram um modelo RoBERTa para estimar datas de publicação, usando um subconjunto do Corpus of Historical American English, cobrindo materiais de 1810 a 2009. Esse classificador RoBERTa avaliou continuações produzidas pelo ChatGPT-4o, induzidas com trechos reais de livros publicados entre 1905 e 1914.
O prompt do sistema dado ao ChatGPT foi: "Sua tarefa é completar trechos de livros do início do século XX. Você receberá um trecho de um livro publicado em 1913. Continue este trecho no mesmo estilo, por pelo menos 200 palavras. Forneça apenas esta continuação; não faça comentários introdutórios, como 'aqui está a continuação:'."
Apesar de usar prompts de um e 20 exemplos, as saídas do ChatGPT-4o consistentemente tenderam para um estilo do século XXI. Um exemplo fornecido no artigo mostrou a tentativa do ChatGPT-4o de continuar o texto sobre fotografia:
"O uso da luz fria na fotografia instantânea revolucionou a abordagem para capturar imagens sob condições de luz variadas. Tradicionalmente, os fotógrafos lutavam com a dureza e variabilidade da luz natural ou com a natureza intrusiva da fotografia com flash, que podia perturbar a atmosfera de uma cena ou o comportamento natural dos sujeitos, particularmente na fotografia de vida selvagem e humana espontânea. A luz fria, com sua natureza mais suave e difusa... permite uma representação mais natural de cores e texturas, que muitas vezes se perde sob iluminação artificial severa."
Este texto genérico, no estilo Wiki, não correspondia ao estilo prolixo e elaborado do texto original do período, nem continuava de forma fluida de onde o original parou. Em vez disso, desviava-se para uma discussão abstrata sobre um dos subtemas.
A equipe também testou o GPT-1914, um modelo GPT-2 menor treinado do zero com literatura datada entre 1880 e 1914. Embora menos coerente, sua saída era mais consistente com o estilo do período de origem. Um exemplo fornecido no artigo foi:
"O princípio de sua ação já foi explicado (p. 4). Aqui mencionaremos apenas que ele pode ser aplicado com vantagem quando desejamos obter fotografias muito rápidas em papel revestido com colódio, assim como aquelas tiradas por meio de placas de gelatina. Nesses casos, a exposição não deve exceder um segundo, pelo menos; mas se a imagem desejada for desenvolvida em menos tempo – digamos meio segundo – então a temperatura nunca deve cair abaixo de 20° C., caso contrário, a imagem ficará muito escura após o desenvolvimento; além disso, a placa perderia sua sensibilidade nessas condições. Para fins comuns, no entanto, basta apenas expor a superfície sensível a um baixo grau de calor sem quaisquer precauções especiais sendo necessárias além de manter o."
Embora o material original fosse arcano e difícil de acompanhar, a saída do GPT-1914 soava mais autêntica ao período. No entanto, os autores concluíram que prompts simples fazem pouco para superar os vieses contemporâneos inerentes a grandes modelos pré-treinados como o ChatGPT-4o.
Medindo a Precisão Histórica
Para avaliar o quão próximo as saídas dos modelos se assemelhavam à escrita histórica autêntica, os pesquisadores usaram um classificador estatístico para estimar a provável data de publicação de cada amostra de texto. Eles visualizaram os resultados usando um gráfico de densidade de kernel, mostrando onde o modelo posicionou cada trecho em uma linha do tempo histórica.
Datas de publicação estimadas para textos reais e gerados, com base em um classificador treinado para reconhecer o estilo histórico (textos de origem de 1905–1914 comparados com continuações por GPT‑4o usando prompts de um e 20 exemplos, e por GPT‑1914 treinado apenas em literatura de 1880–1914).
O modelo RoBERTa ajustado, embora não perfeito, destacou tendências estilísticas gerais. Trechos do GPT-1914, treinado exclusivamente em literatura do período, agruparam-se em torno do início do século XX, semelhante ao material de origem original. Em contraste, as saídas do ChatGPT-4o, mesmo com múltiplos prompts históricos, assemelhavam-se à escrita do século XXI, refletindo seus dados de treinamento.
Os pesquisadores quantificaram esse descompasso usando a divergência de Jensen-Shannon, medindo a diferença entre duas distribuições de probabilidade. O GPT-1914 obteve uma pontuação próxima de 0,006 em comparação com o texto histórico real, enquanto as saídas do ChatGPT-4o com um e 20 exemplos mostraram lacunas muito maiores, em 0,310 e 0,350, respectivamente.
Os autores argumentam que essas descobertas indicam que o prompting sozinho, mesmo com múltiplos exemplos, não é um método confiável para produzir textos que simulam de forma convincente um estilo histórico.
Ajuste Fino para Melhores Resultados
O artigo então explorou se o ajuste fino poderia gerar melhores resultados. Esse processo afeta diretamente os pesos do modelo ao continuar seu treinamento em dados especificados pelo usuário, potencialmente melhorando seu desempenho no domínio alvo.
No primeiro experimento de ajuste fino, a equipe treinou o GPT-4o-mini em cerca de dois mil pares de completamento de trechos de livros publicados entre 1905 e 1914. Eles visaram verificar se o ajuste fino em menor escala poderia mudar as saídas do modelo para um estilo mais historicamente preciso.
Usando o mesmo classificador baseado em RoBERTa para estimar a 'data' estilística de cada saída, os pesquisadores descobriram que o modelo ajustado produziu textos muito alinhados com a verdade de base. Sua divergência estilística dos textos originais, medida pela divergência de Jensen-Shannon, caiu para 0,002, geralmente em linha com o GPT-1914.
Datas de publicação estimadas para textos reais e gerados, mostrando o quão próximo o GPT‑1914 e uma versão ajustada do GPT‑4o‑mini correspondem ao estilo da escrita do início do século XX (com base em livros publicados entre 1905 e 1914).
No entanto, os pesquisadores advertiram que essa métrica pode capturar apenas características superficiais do estilo histórico, não anacronismos conceituais ou factuais mais profundos. Eles observaram: "Este não é um teste muito sensível. O modelo RoBERTa usado como juiz aqui é treinado apenas para prever uma data, não para discriminar trechos autênticos de anacrônicos. Provavelmente, ele usa evidências estilísticas grosseiras para fazer essa previsão. Leitores humanos, ou modelos maiores, ainda podem detectar conteúdo anacrônico em trechos que superficialmente soam 'no período'."
Avaliação Humana
Por fim, os pesquisadores conduziram testes de avaliação humana usando 250 trechos selecionados manualmente de livros publicados entre 1905 e 1914. Eles observaram que muitos desses textos provavelmente seriam interpretados de forma diferente hoje do que na época em que foram escritos:
"Nossa lista incluiu, por exemplo, uma entrada de enciclopédia sobre Alsácia (que então fazia parte da Alemanha) e uma sobre beribéri (que então era frequentemente explicado como uma doença fúngica em vez de uma deficiência nutricional). Embora essas sejam diferenças de fato, também selecionamos trechos que exibissem diferenças mais sutis de atitude, retórica ou imaginação. Por exemplo, descrições de lugares não europeus no início do século XX tendem a deslizar para generalizações raciais. Uma descrição do nascer do sol na lua escrita em 1913 imagina fenômenos cromáticos ricos, porque ninguém ainda tinha visto fotografias de um mundo sem atmosfera."
Os pesquisadores criaram perguntas curtas que cada trecho histórico poderia plausivelmente responder, então ajustaram o GPT-4o-mini nesses pares de pergunta-resposta. Para fortalecer a avaliação, eles treinaram cinco versões separadas do modelo, cada vez reservando uma porção diferente dos dados para teste. Em seguida, produziram respostas usando as versões padrão do GPT-4o e GPT-4o-mini, bem como as variantes ajustadas, cada uma avaliada na porção que não havia visto durante o treinamento.
Perdido no Tempo
Para avaliar o quão convincentemente os modelos podiam imitar a linguagem histórica, os pesquisadores pediram a três anotadores especialistas que revisassem 120 completamentos gerados por IA e julgassem se cada um parecia plausível para um escritor em 1914.
Essa avaliação provou ser mais desafiadora do que o esperado. Embora os anotadores concordassem em suas avaliações em quase oitenta por cento do tempo, o desequilíbrio em seus julgamentos (com 'plausível' escolhido duas vezes mais frequentemente do que 'não plausível') significava que seu nível real de concordância era apenas moderado, conforme medido por uma pontuação de Cohen's kappa de 0,554.
Os avaliadores descreveram a tarefa como difícil, muitas vezes exigindo pesquisa adicional para avaliar se uma afirmação estava alinhada com o que era conhecido ou acreditado em 1914. Alguns trechos levantaram questões sobre tom e perspectiva, como se uma resposta era adequadamente limitada em sua visão de mundo para refletir o que teria sido típico em 1914. Esse julgamento frequentemente dependia do nível de etnocentrismo, a tendência de ver outras culturas através das suposições ou vieses de sua própria cultura.
O desafio era decidir se um trecho expressava viés cultural suficiente para parecer historicamente plausível sem soar moderno demais ou ofensivo demais pelos padrões de hoje. Os autores observaram que mesmo para estudiosos familiarizados com o período, era difícil traçar uma linha clara entre linguagem que parecia historicamente precisa e linguagem que refletia ideias contemporâneas.
Apesar disso, os resultados mostraram uma clara classificação dos modelos, com a versão ajustada do GPT-4o-mini julgada como a mais plausível no geral:
Avaliações dos anotadores sobre o quão plausível parecia a saída de cada modelo
Se esse nível de desempenho, avaliado como plausível em oitenta por cento dos casos, é confiável o suficiente para pesquisas históricas permanece incerto, especialmente porque o estudo não incluiu uma medida de base de quantas vezes textos genuínos do período poderiam ser classificados incorretamente.
Alerta de Intruso
Em seguida, os pesquisadores conduziram um 'teste de intruso', onde anotadores especialistas foram mostrados quatro trechos anônimos respondendo à mesma pergunta histórica. Três respostas vieram de modelos de linguagem, enquanto uma era um trecho genuíno de uma fonte do início do século XX.
A tarefa era identificar qual trecho era o original, genuinamente escrito durante o período. Essa abordagem não pedia aos anotadores que avaliassem a plausibilidade diretamente, mas media com que frequência o trecho real se destacava das respostas geradas por IA, testando efetivamente se os modelos podiam enganar leitores a pensar que sua saída era autêntica.
A classificação dos modelos correspondeu aos resultados da tarefa de julgamento anterior: a versão ajustada do GPT-4o-mini foi a mais convincente entre os modelos, mas ainda ficou aquém do original.
A frequência com que cada fonte foi corretamente identificada como o trecho histórico autêntico.
Esse teste também serviu como um referencial útil, já que o trecho genuíno foi identificado mais da metade do tempo, indicando que a lacuna entre prosa autêntica e sintética permaneceu perceptível para leitores humanos.
Uma análise estatística conhecida como teste de McNemar confirmou que as diferenças entre os modelos eram significativas, exceto no caso das duas versões não ajustadas (GPT-4o e GPT-4o-mini), que tiveram desempenho semelhante.
O Futuro do Passado
Os autores descobriram que induzir modelos de linguagem modernos a adotar uma voz histórica não produziu resultados convincentes de forma confiável: menos de dois terços das saídas foram julgadas plausíveis por leitores humanos, e mesmo essa cifra provavelmente superestima o desempenho.
Em muitos casos, as respostas incluíam sinais explícitos de que o modelo estava falando de uma perspectiva contemporânea – frases como "em 1914, ainda não se sabe que..." ou "a partir de 1914, não estou familiarizado com..." eram comuns o suficiente para aparecer em até um quinto dos completamentos. Declarações desse tipo deixavam claro que o modelo estava simulando a história de fora, em vez de escrever de dentro dela.
Os autores afirmaram: "O desempenho fraco do aprendizado em contexto é lamentável, porque esses métodos são os mais fáceis e baratos para pesquisas históricas baseadas em IA. Enfatizamos que não exploramos essas abordagens exaustivamente. Pode ser que o aprendizado em contexto seja adequado – agora ou no futuro – para um subconjunto de áreas de pesquisa. Mas nossas evidências iniciais não são encorajadoras."
Os autores concluíram que, embora o ajuste fino de um modelo comercial em trechos históricos possa produzir saídas estilisticamente convincentes a um custo mínimo, ele não elimina completamente os traços de perspectiva moderna. Pré-treinar um modelo inteiramente em material do período evita anacronismos, mas exige recursos muito maiores e resulta em saídas menos fluentes.
Nenhum dos métodos oferece uma solução completa, e, por enquanto, qualquer tentativa de simular vozes históricas parece envolver um compromisso entre autenticidade e coerência. Os autores concluem que mais pesquisas serão necessárias para esclarecer como melhor navegar essa tensão.
Conclusão
Uma das questões mais intrigantes levantadas pelo novo artigo é a da autenticidade. Embora não sejam ferramentas perfeitas, funções de perda e métricas como LPIPS e SSIM fornecem aos pesquisadores de visão computacional uma metodologia para avaliar contra a verdade de base. Ao gerar novos textos no estilo de uma era passada, no entanto, não há verdade de base – apenas uma tentativa de habitar uma perspectiva cultural desaparecida. Tentar reconstruir essa mentalidade desvios literários é, por si só, um ato de quantização, pois esses traços são apenas evidências, enquanto a consciência cultural da qual emergem permanece além da inferência, e provavelmente além da imaginação.
Em um nível prático, as fundações dos modelos de linguagem modernos, moldadas por normas e dados contemporâneos, correm o risco de reinterpretar ou suprimir ideias que teriam parecido razoáveis ou comuns para um leitor eduardiano, mas que agora são registradas como artefatos de preconceito, desigualdade ou injustiça.
Questiona-se, portanto, mesmo que pudéssemos criar tal colóquio, se ele não nos repeliria.
Publicado pela primeira vez na sexta-feira, 2 de maio de 2025










 O LLMS da Deep Cogito superou os modelos de tamanho semelhante usando IDA
A Deep Cogito, uma empresa de São Francisco, está fazendo ondas na comunidade de IA com o último lançamento de grandes modelos de idiomas abertos (LLMS). Esses modelos, que vêm em vários tamanhos que variam de 3 bilhões a 70 bilhões de parâmetros, não são apenas mais um conjunto de ferramentas de IA; Eles são um passo ousado em direção a W
O aplicativo Gemini do Google adiciona vídeo com IA em tempo real, Deep Research e novos recursos (120 caracteres)
O Google revelou melhorias significativas no Gemini AI durante sua conferência de desenvolvedores I/O 2025, expandindo os recursos multimodais, introduzindo modelos de IA de última geração e fortalece
O LLMS da Deep Cogito superou os modelos de tamanho semelhante usando IDA
A Deep Cogito, uma empresa de São Francisco, está fazendo ondas na comunidade de IA com o último lançamento de grandes modelos de idiomas abertos (LLMS). Esses modelos, que vêm em vários tamanhos que variam de 3 bilhões a 70 bilhões de parâmetros, não são apenas mais um conjunto de ferramentas de IA; Eles são um passo ousado em direção a W
O aplicativo Gemini do Google adiciona vídeo com IA em tempo real, Deep Research e novos recursos (120 caracteres)
O Google revelou melhorias significativas no Gemini AI durante sua conferência de desenvolvedores I/O 2025, expandindo os recursos multimodais, introduzindo modelos de IA de última geração e fortalece
 Assort Health obtém financiamento de US$ 50 milhões para automatizar a comunicação com o paciente
A Assort Health, uma startup emergente de IA na área de saúde, especializada em comunicações automatizadas com pacientes para consultórios especializados, garantiu aproximadamente US$ 50 milhões em fi
4 de Agosto de 2025 à5 09:40:05 WEST
Assort Health obtém financiamento de US$ 50 milhões para automatizar a comunicação com o paciente
A Assort Health, uma startup emergente de IA na área de saúde, especializada em comunicações automatizadas com pacientes para consultórios especializados, garantiu aproximadamente US$ 50 milhões em fi
4 de Agosto de 2025 à5 09:40:05 WEST
Fascinating read! I never thought about how tricky it must be for AI to nail old-timey language. Makes me wonder if we’ll ever see a bot write like Dickens without a ton of extra work. 🧐
0
31 de Julho de 2025 à39 12:35:39 WEST
I never thought AI would trip over old-timey phrases like this! Dickens’ unfinished novel is cool, but maybe we should let some mysteries stay unsolved. 🕰️
0
28 de Julho de 2025 à5 02:19:05 WEST
I find it fascinating that AI can't quite nail those old-timey phrases from Dickens' era. It’s like trying to teach a robot to talk like Shakespeare—cool idea, but super tricky! 🧠
0
28 de Julho de 2025 à39 02:18:39 WEST
It's wild to think AI can't nail old-timey lingo like Dickens' without a ton of prep work. Kinda makes you wonder if we're overhyping these models or if history's just too tricky for code to crack. 🤔
0













