
















 Home
HomeOptimizing AI Model Selection for Real-World Performance
Businesses must ensure their application-driving AI models perform effectively in real-world scenarios. Predicting these scenarios can be challenging, complicating evaluations. The updated RewardBench 2 benchmark offers organizations clearer insights into a model’s practical performance.
The Allen Institute for AI (Ai2) introduced RewardBench 2, an enhanced version of its RewardBench benchmark, designed to provide a comprehensive assessment of model performance and alignment with enterprise objectives.
Ai2 developed RewardBench with classification tasks that evaluate correlations via inference-time compute and downstream training. RewardBench focuses on reward models (RMs), which judge large language model outputs by assigning scores or “rewards” to guide reinforcement learning with human feedback (RHLF).
RewardBench 2 is here! We took a long time to learn from our first reward model evaluation tool to make one that is substantially harder and more correlated with both downstream RLHF and inference-time scaling. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) June 2, 2025
Nathan Lambert, a senior research scientist at Ai2, told VentureBeat that the original RewardBench functioned well initially, but evolving model environments demanded updated benchmarks.
“As reward models grew more sophisticated and use cases more complex, we saw, alongside the community, that the first version didn’t fully address real-world human preference complexities,” he explained.
Lambert noted that RewardBench 2 improves evaluation scope and depth, incorporating diverse, challenging prompts and refined methods to better reflect human judgment of AI outputs. It features new human prompts, a tougher scoring system, and additional domains.
Leveraging Evaluations for Model Assessment
Reward models evaluate model performance, but alignment with company values is critical. Misaligned RMs can amplify issues like hallucinations, reduce generalization, or overly favor harmful responses during fine-tuning and reinforcement learning.
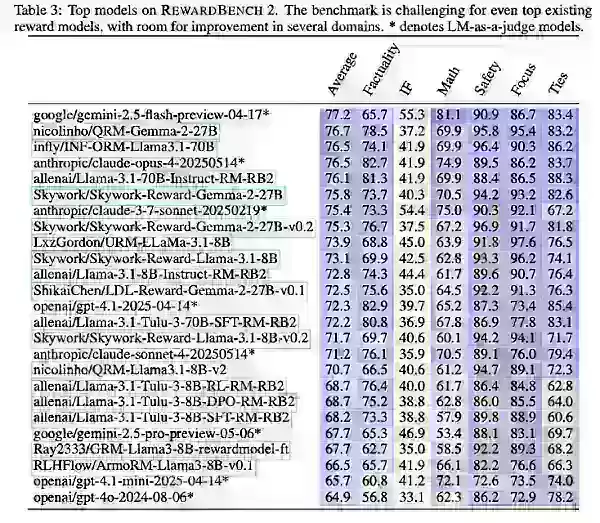
RewardBench 2 spans six domains: factuality, precise instruction adherence, math, safety, focus, and ties.
“Enterprises can use RewardBench 2 in two ways based on their needs. For RLHF, they should integrate best practices and datasets from top models into their pipelines, as reward models require on-policy training. For inference-time scaling or data filtering, RewardBench 2 helps select the best model for their domain with correlated performance,” Lambert said.
Lambert emphasized that benchmarks like RewardBench allow users to assess models based on priorities most relevant to them, rather than a generic score. He noted that performance is subjective, heavily tied to user context and goals, with human preferences often highly nuanced.
Ai2 launched the original RewardBench in March 2024, calling it the first reward model benchmark and leaderboard. Since then, new methods like Meta’s FAIR reWordBench and DeepSeek’s Self-Principled Critique Tuning have emerged for smarter, scalable RMs.
Super excited that our second reward model evaluation is out. It's substantially harder, much cleaner, and well correlated with downstream PPO/BoN sampling.
Happy hillclimbing!
Huge congrats to @saumyamalik44 who lead the project with a total commitment to excellence. https://t.co/c0b6rHTXY5
— Nathan Lambert (@natolambert) June 2, 2025
Model Performance Insights
With RewardBench 2, Ai2 tested both existing and newly trained models, including variants of Gemini, Claude, GPT-4.1, and Llama-3.1, alongside datasets and models like Qwen, Skywork, and Tulu.
Findings showed larger reward models excel due to stronger base models. Llama-3.1 Instruct variants topped the benchmark, with Skywork data aiding focus and safety, and Tulu performing well in factuality.
Ai2 noted that while RewardBench 2 advances multi-domain, accuracy-focused evaluation for reward models, it should primarily guide enterprises in selecting models best suited to their specific needs.
Related article
 Anthropic's experimental AI Claude completes negotiations and transactions in e-commerce test
As artificial intelligence advances rapidly, Anthropic quietly rolled out an internal experiment called "Project Deal" last Friday, showcasing AI's potential in e-commerce. The experiment had its AI model Claude autonomously handle buying, selling, a
DeepSeek Code poised for launch
As AI technology accelerates, DeepSeek is at a thrilling juncture. The AI company recently revealed it has secured over 70 billion yuan in funding. Leadership has emphasized a commitment to groundbreaking AI research over immediate commercial gains.
Musk’s Grok: 1.5 Trillion Parameters and Cursor Code Absorption—Game Changer or Bluff?
Elon Musk is finally making a move.In the AI programming race, OpenAI and Anthropic are accelerating, while xAI appears to be lagging. Musk has often stated his aim to rival Claude, yet despite multiple updates to the Grok4.X series, the results look
Related Special Topic Recommendations
Business
Anthropic's experimental AI Claude completes negotiations and transactions in e-commerce test
As artificial intelligence advances rapidly, Anthropic quietly rolled out an internal experiment called "Project Deal" last Friday, showcasing AI's potential in e-commerce. The experiment had its AI model Claude autonomously handle buying, selling, a
DeepSeek Code poised for launch
As AI technology accelerates, DeepSeek is at a thrilling juncture. The AI company recently revealed it has secured over 70 billion yuan in funding. Leadership has emphasized a commitment to groundbreaking AI research over immediate commercial gains.
Musk’s Grok: 1.5 Trillion Parameters and Cursor Code Absorption—Game Changer or Bluff?
Elon Musk is finally making a move.In the AI programming race, OpenAI and Anthropic are accelerating, while xAI appears to be lagging. Musk has often stated his aim to rival Claude, yet despite multiple updates to the Grok4.X series, the results look
Related Special Topic Recommendations
Business
 Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
 10 tools
10 tools
 xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai
code
Best AI Tools for Automated Unit Testing: Generate Jest, PyTest & JUnit Test Cases in One Click
Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

 Comments (3)
0/500
Comments (3)
0/500
![JeffreyThomas]()
Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
![DonaldGonzález]()
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
![CarlMartin]()
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅
Businesses must ensure their application-driving AI models perform effectively in real-world scenarios. Predicting these scenarios can be challenging, complicating evaluations. The updated RewardBench 2 benchmark offers organizations clearer insights into a model’s practical performance.
The Allen Institute for AI (Ai2) introduced RewardBench 2, an enhanced version of its RewardBench benchmark, designed to provide a comprehensive assessment of model performance and alignment with enterprise objectives.
Ai2 developed RewardBench with classification tasks that evaluate correlations via inference-time compute and downstream training. RewardBench focuses on reward models (RMs), which judge large language model outputs by assigning scores or “rewards” to guide reinforcement learning with human feedback (RHLF).
RewardBench 2 is here! We took a long time to learn from our first reward model evaluation tool to make one that is substantially harder and more correlated with both downstream RLHF and inference-time scaling. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) June 2, 2025
Nathan Lambert, a senior research scientist at Ai2, told VentureBeat that the original RewardBench functioned well initially, but evolving model environments demanded updated benchmarks.
“As reward models grew more sophisticated and use cases more complex, we saw, alongside the community, that the first version didn’t fully address real-world human preference complexities,” he explained.
Lambert noted that RewardBench 2 improves evaluation scope and depth, incorporating diverse, challenging prompts and refined methods to better reflect human judgment of AI outputs. It features new human prompts, a tougher scoring system, and additional domains.
Leveraging Evaluations for Model Assessment
Reward models evaluate model performance, but alignment with company values is critical. Misaligned RMs can amplify issues like hallucinations, reduce generalization, or overly favor harmful responses during fine-tuning and reinforcement learning.
RewardBench 2 spans six domains: factuality, precise instruction adherence, math, safety, focus, and ties.
“Enterprises can use RewardBench 2 in two ways based on their needs. For RLHF, they should integrate best practices and datasets from top models into their pipelines, as reward models require on-policy training. For inference-time scaling or data filtering, RewardBench 2 helps select the best model for their domain with correlated performance,” Lambert said.
Lambert emphasized that benchmarks like RewardBench allow users to assess models based on priorities most relevant to them, rather than a generic score. He noted that performance is subjective, heavily tied to user context and goals, with human preferences often highly nuanced.
Ai2 launched the original RewardBench in March 2024, calling it the first reward model benchmark and leaderboard. Since then, new methods like Meta’s FAIR reWordBench and DeepSeek’s Self-Principled Critique Tuning have emerged for smarter, scalable RMs.
Super excited that our second reward model evaluation is out. It's substantially harder, much cleaner, and well correlated with downstream PPO/BoN sampling.
— Nathan Lambert (@natolambert) June 2, 2025
Happy hillclimbing!
Huge congrats to @saumyamalik44 who lead the project with a total commitment to excellence. https://t.co/c0b6rHTXY5
Model Performance Insights
With RewardBench 2, Ai2 tested both existing and newly trained models, including variants of Gemini, Claude, GPT-4.1, and Llama-3.1, alongside datasets and models like Qwen, Skywork, and Tulu.
Findings showed larger reward models excel due to stronger base models. Llama-3.1 Instruct variants topped the benchmark, with Skywork data aiding focus and safety, and Tulu performing well in factuality.
Ai2 noted that while RewardBench 2 advances multi-domain, accuracy-focused evaluation for reward models, it should primarily guide enterprises in selecting models best suited to their specific needs.










 Anthropic's experimental AI Claude completes negotiations and transactions in e-commerce test
As artificial intelligence advances rapidly, Anthropic quietly rolled out an internal experiment called "Project Deal" last Friday, showcasing AI's potential in e-commerce. The experiment had its AI model Claude autonomously handle buying, selling, a
Anthropic's experimental AI Claude completes negotiations and transactions in e-commerce test
As artificial intelligence advances rapidly, Anthropic quietly rolled out an internal experiment called "Project Deal" last Friday, showcasing AI's potential in e-commerce. The experiment had its AI model Claude autonomously handle buying, selling, a
 DeepSeek Code poised for launch
As AI technology accelerates, DeepSeek is at a thrilling juncture. The AI company recently revealed it has secured over 70 billion yuan in funding. Leadership has emphasized a commitment to groundbreaking AI research over immediate commercial gains.
DeepSeek Code poised for launch
As AI technology accelerates, DeepSeek is at a thrilling juncture. The AI company recently revealed it has secured over 70 billion yuan in funding. Leadership has emphasized a commitment to groundbreaking AI research over immediate commercial gains.
 Musk’s Grok: 1.5 Trillion Parameters and Cursor Code Absorption—Game Changer or Bluff?
Elon Musk is finally making a move.In the AI programming race, OpenAI and Anthropic are accelerating, while xAI appears to be lagging. Musk has often stated his aim to rival Claude, yet despite multiple updates to the Grok4.X series, the results look
Musk’s Grok: 1.5 Trillion Parameters and Cursor Code Absorption—Game Changer or Bluff?
Elon Musk is finally making a move.In the AI programming race, OpenAI and Anthropic are accelerating, while xAI appears to be lagging. Musk has often stated his aim to rival Claude, yet despite multiple updates to the Grok4.X series, the results look

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI tools for automated unit testing. Our curated selection features powerful, game-changing solutions to generate Jest, PyTest & JUnit test cases instantly. Compare free vs paid options with real-world tests and weekly updated rankings on XIX.AI. Unlock your AI edge and boost development productivity today.
10 tools
xix.ai

Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅













