
















 首頁
首頁優化AI模型選擇以提升現實世界表現
企業必須確保其應用驅動的AI模型在現實世界場景中有效運作。預測這些場景可能具有挑戰性,進而使評估變得複雜。更新後的RewardBench 2基準為組織提供了更清晰的模型實際表現洞察。
Allen Institute for AI (Ai2) 推出了RewardBench 2,這是其RewardBench基準的增強版本,旨在提供對模型表現和企業目標一致性的全面評估。
Ai2開發的RewardBench包含分類任務,通過推理時計算和下游訓練來評估相關性。RewardBench專注於獎勵模型(RMs),這些模型通過為大型語言模型輸出分配分數或“獎勵”來指導基於人類反饋的強化學習(RHLF)。
RewardBench 2 is here! We took a long time to learn from our first reward model evaluation tool to make one that is substantially harder and more correlated with both downstream RLHF and inference-time scaling. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) June 2, 2025
Ai2的高級研究科學家Nathan Lambert向VentureBeat表示,原始的RewardBench最初表現良好,但隨著模型環境的演進,需求更新基準。
“隨著獎勵模型變得更加複雜以及使用場景更為繁雜,我們與社群一同觀察到,第一版無法完全應對現實世界中人類偏好的複雜性,”他解釋道。
Lambert指出,RewardBench 2提升了評估範圍和深度,納入了多樣化且具挑戰性的提示,以及改進的方法,以更好地反映人類對AI輸出的判斷。它包含新的人類提示、更嚴格的評分系統和額外的領域。
利用評估進行模型評估
獎勵模型評估模型表現,但與公司價值觀的一致性至關重要。未對齊的RMs可能會放大幻覺問題,降低泛化能力,或在微調和強化學習期間過分偏向有害回應。
RewardBench 2涵蓋六個領域:事實性、精確指令遵循、數學、安全性、焦點和平衡。
“企業可以根據需求以兩種方式使用RewardBench 2。對於RHLF,他們應將頂尖模型的最佳實踐和數據集整合到其流程中,因為獎勵模型需要策略性訓練。對於推理時擴展或數據過濾,RewardBench 2有助於選擇最適合其領域的模型,並具有相關的表現,”Lambert說道。
Lambert強調,像RewardBench這樣的基準允許用戶根據對他們最重要的優先級來評估模型,而不是通用的分數。他指出,表現是主觀的,與用戶情境和目標密切相關,人類偏好往往極其細緻。
Ai2於2024年3月推出了原始的RewardBench,稱其為首個獎勵模型基準和排行榜。此後,出現了如Meta的FAIR reWordBench和DeepSeek的Self-Principled Critique Tuning等新方法,用於更智能、可擴展的RMs。
Super excited that our second reward model evaluation is out. It's substantially harder, much cleaner, and well correlated with downstream PPO/BoN sampling.
Happy hillclimbing!
Huge congrats to @saumyamalik44 who lead the project with a total commitment to excellence. https://t.co/c0b6rHTXY5
— Nathan Lambert (@natolambert) June 2, 2025
模型表現洞察
通過RewardBench 2,Ai2測試了現有和新訓練的模型,包括Gemini、Claude、GPT-4.1和Llama-3.1的變體,以及Qwen、Skywork和Tulu等數據集和模型。
結果顯示,較大的獎勵模型因其更強大的基礎模型而表現出色。Llama-3.1 Instruct變體在基準中名列前茅,Skywork數據有助於提升焦點和安全性,Tulu在事實性方面表現良好。
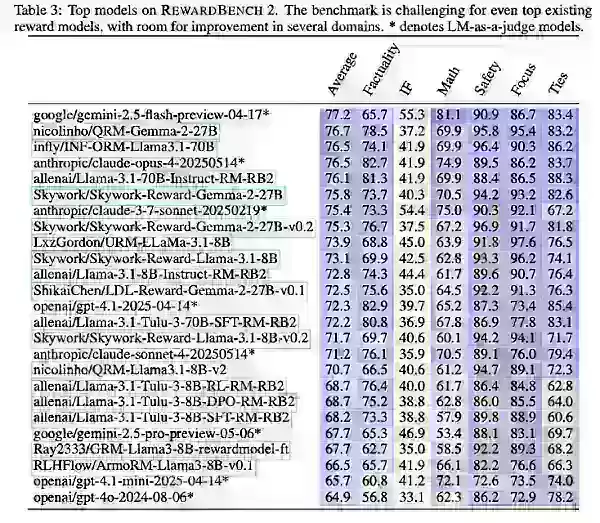
Ai2指出,雖然RewardBench 2推進了多領域、精確度導向的獎勵模型評估,但它主要應指導企業選擇最適合其特定需求的模型。
相關文章
 如何保護資產、建築物及個人健康?
在這個充滿變數的世界裡,保障已不再僅是選項,而是戰略上的必要之舉。無論是守護財務、強化建築結構,還是關注個人健康,長期的穩定都仰賴於主動規劃。真正的安全是多層次的,取決於財務管理、結構韌性與明智的健康意識三者相輔相成。守護最重要的事物,意味著必須未雨綢繆,而非僅在損害發生後才做出反應。財務保障:第一道防線每個人與每家企業都運作於財務架構之中。收入、支出、負債與投資構成了穩定的基石。若缺乏有條不紊的
AI 瀏覽器 Comet 正式上線,在 iPad 上全面支援多工處理
Perplexity 的 AI 瀏覽器 Comet 已正式推出 iPad 版本,現已全面相容於 iPadOS。此次更新導入多視窗瀏覽功能、多工處理支援,並與 OpenAI 和 Anthropic 等頂尖 AI 模型深度整合,帶來更智能的網路體驗。Comet 瀏覽器拓展了使用者探索網路及與 AI 聊天機器人互動的方式,提供直觀的管道存取 OpenAI 和 Anthropic 等頂尖 AI 模型,以進
Trace籌集了300萬美元,用於解決企業採用AI智慧助手時所遇到的各種障礙。
儘管人工智慧代理具有巨大潛力,但它們在企業中仍難以取得實質性進展。一家新興的初創企業認為,根本問題在於缺乏上下文資訊。Trace是一家專注於工作流程協作的初創企業,它作為Y Combinator 2025年夏季培訓專案的一部分誕生,旨在彌補這一空白。該公司能夠梳理複雜的企業環境和業務流程,為人工智慧代理提供所需的上下文資訊,從而幫助它們快速發展。“OpenAI和Anthropic培養出了非常優秀的人工智慧實習生,企業完全可以利用這些資源,”Trace的執行長Tim Cherkasov解釋
相關專題推薦
商業
如何保護資產、建築物及個人健康?
在這個充滿變數的世界裡,保障已不再僅是選項,而是戰略上的必要之舉。無論是守護財務、強化建築結構,還是關注個人健康,長期的穩定都仰賴於主動規劃。真正的安全是多層次的,取決於財務管理、結構韌性與明智的健康意識三者相輔相成。守護最重要的事物,意味著必須未雨綢繆,而非僅在損害發生後才做出反應。財務保障:第一道防線每個人與每家企業都運作於財務架構之中。收入、支出、負債與投資構成了穩定的基石。若缺乏有條不紊的
AI 瀏覽器 Comet 正式上線,在 iPad 上全面支援多工處理
Perplexity 的 AI 瀏覽器 Comet 已正式推出 iPad 版本,現已全面相容於 iPadOS。此次更新導入多視窗瀏覽功能、多工處理支援,並與 OpenAI 和 Anthropic 等頂尖 AI 模型深度整合,帶來更智能的網路體驗。Comet 瀏覽器拓展了使用者探索網路及與 AI 聊天機器人互動的方式,提供直觀的管道存取 OpenAI 和 Anthropic 等頂尖 AI 模型,以進
Trace籌集了300萬美元,用於解決企業採用AI智慧助手時所遇到的各種障礙。
儘管人工智慧代理具有巨大潛力,但它們在企業中仍難以取得實質性進展。一家新興的初創企業認為,根本問題在於缺乏上下文資訊。Trace是一家專注於工作流程協作的初創企業,它作為Y Combinator 2025年夏季培訓專案的一部分誕生,旨在彌補這一空白。該公司能夠梳理複雜的企業環境和業務流程,為人工智慧代理提供所需的上下文資訊,從而幫助它們快速發展。“OpenAI和Anthropic培養出了非常優秀的人工智慧實習生,企業完全可以利用這些資源,”Trace的執行長Tim Cherkasov解釋
相關專題推薦
商業
 頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
 10 個工具
10 個工具
 xix.ai
代碼
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
xix.ai
代碼
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai
文字轉語音
專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai
漫畫創作
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

 評論 (3)
0/500
評論 (3)
0/500
![JeffreyThomas]()
Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
![DonaldGonzález]()
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
![CarlMartin]()
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅
企業必須確保其應用驅動的AI模型在現實世界場景中有效運作。預測這些場景可能具有挑戰性,進而使評估變得複雜。更新後的RewardBench 2基準為組織提供了更清晰的模型實際表現洞察。
Allen Institute for AI (Ai2) 推出了RewardBench 2,這是其RewardBench基準的增強版本,旨在提供對模型表現和企業目標一致性的全面評估。
Ai2開發的RewardBench包含分類任務,通過推理時計算和下游訓練來評估相關性。RewardBench專注於獎勵模型(RMs),這些模型通過為大型語言模型輸出分配分數或“獎勵”來指導基於人類反饋的強化學習(RHLF)。
RewardBench 2 is here! We took a long time to learn from our first reward model evaluation tool to make one that is substantially harder and more correlated with both downstream RLHF and inference-time scaling. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) June 2, 2025
Ai2的高級研究科學家Nathan Lambert向VentureBeat表示,原始的RewardBench最初表現良好,但隨著模型環境的演進,需求更新基準。
“隨著獎勵模型變得更加複雜以及使用場景更為繁雜,我們與社群一同觀察到,第一版無法完全應對現實世界中人類偏好的複雜性,”他解釋道。
Lambert指出,RewardBench 2提升了評估範圍和深度,納入了多樣化且具挑戰性的提示,以及改進的方法,以更好地反映人類對AI輸出的判斷。它包含新的人類提示、更嚴格的評分系統和額外的領域。
利用評估進行模型評估
獎勵模型評估模型表現,但與公司價值觀的一致性至關重要。未對齊的RMs可能會放大幻覺問題,降低泛化能力,或在微調和強化學習期間過分偏向有害回應。
RewardBench 2涵蓋六個領域:事實性、精確指令遵循、數學、安全性、焦點和平衡。
“企業可以根據需求以兩種方式使用RewardBench 2。對於RHLF,他們應將頂尖模型的最佳實踐和數據集整合到其流程中,因為獎勵模型需要策略性訓練。對於推理時擴展或數據過濾,RewardBench 2有助於選擇最適合其領域的模型,並具有相關的表現,”Lambert說道。
Lambert強調,像RewardBench這樣的基準允許用戶根據對他們最重要的優先級來評估模型,而不是通用的分數。他指出,表現是主觀的,與用戶情境和目標密切相關,人類偏好往往極其細緻。
Ai2於2024年3月推出了原始的RewardBench,稱其為首個獎勵模型基準和排行榜。此後,出現了如Meta的FAIR reWordBench和DeepSeek的Self-Principled Critique Tuning等新方法,用於更智能、可擴展的RMs。
Super excited that our second reward model evaluation is out. It's substantially harder, much cleaner, and well correlated with downstream PPO/BoN sampling.
— Nathan Lambert (@natolambert) June 2, 2025
Happy hillclimbing!
Huge congrats to @saumyamalik44 who lead the project with a total commitment to excellence. https://t.co/c0b6rHTXY5
模型表現洞察
通過RewardBench 2,Ai2測試了現有和新訓練的模型,包括Gemini、Claude、GPT-4.1和Llama-3.1的變體,以及Qwen、Skywork和Tulu等數據集和模型。
結果顯示,較大的獎勵模型因其更強大的基礎模型而表現出色。Llama-3.1 Instruct變體在基準中名列前茅,Skywork數據有助於提升焦點和安全性,Tulu在事實性方面表現良好。
Ai2指出,雖然RewardBench 2推進了多領域、精確度導向的獎勵模型評估,但它主要應指導企業選擇最適合其特定需求的模型。










 如何保護資產、建築物及個人健康?
在這個充滿變數的世界裡,保障已不再僅是選項,而是戰略上的必要之舉。無論是守護財務、強化建築結構,還是關注個人健康,長期的穩定都仰賴於主動規劃。真正的安全是多層次的,取決於財務管理、結構韌性與明智的健康意識三者相輔相成。守護最重要的事物,意味著必須未雨綢繆,而非僅在損害發生後才做出反應。財務保障:第一道防線每個人與每家企業都運作於財務架構之中。收入、支出、負債與投資構成了穩定的基石。若缺乏有條不紊的
如何保護資產、建築物及個人健康?
在這個充滿變數的世界裡,保障已不再僅是選項,而是戰略上的必要之舉。無論是守護財務、強化建築結構,還是關注個人健康,長期的穩定都仰賴於主動規劃。真正的安全是多層次的,取決於財務管理、結構韌性與明智的健康意識三者相輔相成。守護最重要的事物,意味著必須未雨綢繆,而非僅在損害發生後才做出反應。財務保障:第一道防線每個人與每家企業都運作於財務架構之中。收入、支出、負債與投資構成了穩定的基石。若缺乏有條不紊的
 AI 瀏覽器 Comet 正式上線,在 iPad 上全面支援多工處理
Perplexity 的 AI 瀏覽器 Comet 已正式推出 iPad 版本,現已全面相容於 iPadOS。此次更新導入多視窗瀏覽功能、多工處理支援,並與 OpenAI 和 Anthropic 等頂尖 AI 模型深度整合,帶來更智能的網路體驗。Comet 瀏覽器拓展了使用者探索網路及與 AI 聊天機器人互動的方式,提供直觀的管道存取 OpenAI 和 Anthropic 等頂尖 AI 模型,以進
AI 瀏覽器 Comet 正式上線,在 iPad 上全面支援多工處理
Perplexity 的 AI 瀏覽器 Comet 已正式推出 iPad 版本,現已全面相容於 iPadOS。此次更新導入多視窗瀏覽功能、多工處理支援,並與 OpenAI 和 Anthropic 等頂尖 AI 模型深度整合,帶來更智能的網路體驗。Comet 瀏覽器拓展了使用者探索網路及與 AI 聊天機器人互動的方式,提供直觀的管道存取 OpenAI 和 Anthropic 等頂尖 AI 模型,以進
 Trace籌集了300萬美元,用於解決企業採用AI智慧助手時所遇到的各種障礙。
儘管人工智慧代理具有巨大潛力,但它們在企業中仍難以取得實質性進展。一家新興的初創企業認為,根本問題在於缺乏上下文資訊。Trace是一家專注於工作流程協作的初創企業,它作為Y Combinator 2025年夏季培訓專案的一部分誕生,旨在彌補這一空白。該公司能夠梳理複雜的企業環境和業務流程,為人工智慧代理提供所需的上下文資訊,從而幫助它們快速發展。“OpenAI和Anthropic培養出了非常優秀的人工智慧實習生,企業完全可以利用這些資源,”Trace的執行長Tim Cherkasov解釋
Trace籌集了300萬美元,用於解決企業採用AI智慧助手時所遇到的各種障礙。
儘管人工智慧代理具有巨大潛力,但它們在企業中仍難以取得實質性進展。一家新興的初創企業認為,根本問題在於缺乏上下文資訊。Trace是一家專注於工作流程協作的初創企業,它作為Y Combinator 2025年夏季培訓專案的一部分誕生,旨在彌補這一空白。該公司能夠梳理複雜的企業環境和業務流程,為人工智慧代理提供所需的上下文資訊,從而幫助它們快速發展。“OpenAI和Anthropic培養出了非常優秀的人工智慧實習生,企業完全可以利用這些資源,”Trace的執行長Tim Cherkasov解釋

立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai

探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅













