
















 Maison
MaisonOptimisation de la sélection de modèles d'IA pour des performances réelles
Les entreprises doivent s'assurer que leurs modèles d'IA, qui pilotent les applications, fonctionnent efficacement dans des scénarios réels. Prédire ces scénarios peut être difficile, compliquant les évaluations. Le benchmark RewardBench 2 mis à jour offre aux organisations des informations plus claires sur les performances pratiques d'un modèle.
L’Institut Allen pour l’IA (Ai2) a introduit RewardBench 2, une version améliorée de son benchmark RewardBench, conçue pour fournir une évaluation complète des performances des modèles et de leur alignement avec les objectifs des entreprises.
Ai2 a développé RewardBench avec des tâches de classification évaluant les corrélations via le calcul au moment de l'inférence et l'entraînement en aval. RewardBench se concentre sur les modèles de récompense (RMs), qui jugent les sorties des grands modèles de langage en attribuant des scores ou « récompenses » pour guider l'apprentissage par renforcement avec retour humain (RHLF).
RewardBench 2 est là ! Nous avons pris le temps d’apprendre de notre premier outil d’évaluation de modèle de récompense pour en créer un nettement plus difficile et plus corrélé avec l’RLHF en aval et l’échelle au moment de l’inférence. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2 juin 2025
Nathan Lambert, chercheur senior chez Ai2, a déclaré à VentureBeat que le RewardBench original fonctionnait bien initialement, mais l’évolution des environnements des modèles exigeait des benchmarks actualisés.
« À mesure que les modèles de récompense devenaient plus sophistiqués et les cas d’utilisation plus complexes, nous avons constaté, avec la communauté, que la première version ne répondait pas pleinement aux complexités des préférences humaines en conditions réelles », a-t-il expliqué.
Lambert a noté que RewardBench 2 améliore la portée et la profondeur des évaluations, intégrant des invites variées et exigeantes ainsi que des méthodes affinées pour mieux refléter le jugement humain des sorties d’IA. Il inclut de nouvelles invites humaines, un système de notation plus strict et des domaines supplémentaires.
Utilisation des évaluations pour l'évaluation des modèles
Les modèles de récompense évaluent les performances des modèles, mais l’alignement avec les valeurs de l’entreprise est crucial. Des RMs mal alignés peuvent amplifier des problèmes comme les hallucinations, réduire la généralisation ou favoriser excessivement des réponses nuisibles pendant l’ajustement fin et l’apprentissage par renforcement.
RewardBench 2 couvre six domaines : factualité, respect précis des instructions, mathématiques, sécurité, concentration et égalités.
« Les entreprises peuvent utiliser RewardBench 2 de deux manières selon leurs besoins. Pour l’RLHF, elles doivent intégrer les meilleures pratiques et ensembles de données des meilleurs modèles dans leurs pipelines, car les modèles de récompense nécessitent un entraînement sur politique. Pour l’échelle au moment de l’inférence ou le filtrage des données, RewardBench 2 aide à sélectionner le meilleur modèle pour leur domaine avec des performances corrélées », a déclaré Lambert.
Lambert a souligné que des benchmarks comme RewardBench permettent aux utilisateurs d’évaluer les modèles en fonction des priorités les plus pertinentes pour eux, plutôt qu’un score générique. Il a noté que les performances sont subjectives, fortement liées au contexte et aux objectifs des utilisateurs, avec des préférences humaines souvent très nuancées.
Ai2 a lancé le RewardBench original en mars 2024, le qualifiant de premier benchmark et classement des modèles de récompense. Depuis, de nouvelles méthodes comme FAIR reWordBench de Meta et Self-Principled Critique Tuning de DeepSeek ont émergé pour des RMs plus intelligents et évolutifs.
Super excité que notre deuxième évaluation de modèle de récompense soit sortie. Elle est nettement plus difficile, beaucoup plus propre et bien corrélée avec l’échantillonnage PPO/BoN en aval.
Joyeuse ascension !
Félicitations énormes à @saumyamalik44 qui a dirigé le projet avec un engagement total pour l’excellence. https://t.co/c0b6rHTXY5
— Nathan Lambert (@natolambert) 2 juin 2025
Perspectives sur les performances des modèles
Avec RewardBench 2, Ai2 a testé des modèles existants et nouvellement entraînés, y compris des variantes de Gemini, Claude, GPT-4.1 et Llama-3.1, ainsi que des ensembles de données et modèles comme Qwen, Skywork et Tulu.
Les résultats ont montré que les modèles de récompense plus grands excellent grâce à des modèles de base plus robustes. Les variantes Instruct de Llama-3.1 ont dominé le benchmark, avec les données Skywork aidant à la concentration et à la sécurité, et Tulu performant bien en factualité.
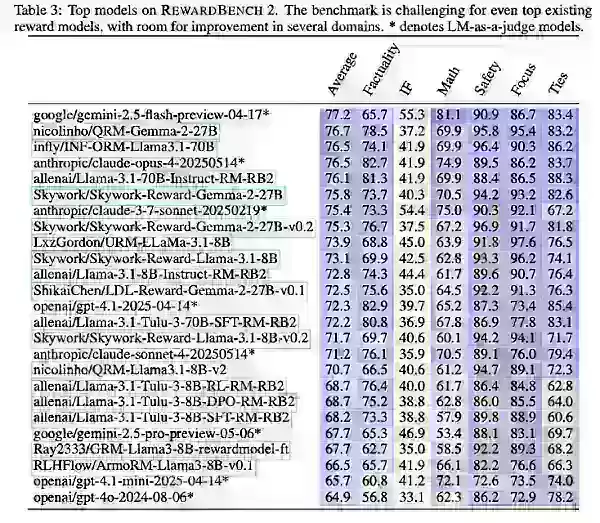
Ai2 a noté que bien que RewardBench 2 fasse progresser l’évaluation multidomaine axée sur la précision pour les modèles de récompense, il devrait principalement guider les entreprises dans la sélection des modèles les mieux adaptés à leurs besoins spécifiques.
Article connexe
 Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Claude Opus 4.7 fait son entrée sur le marché en misant davantage sur la fiabilité que sur l'intelligence
Anthropic a maintenu un rythme soutenu cette année, en déployant de nouvelles fonctionnalités presque tous les deux jours. Le très attendu Claude Opus 4.7 vient d'être officiellement lancé, et il est
Haier lance le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde, pesant seulement 1,75 kg
Le groupe Haier a présenté le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde : le Haier Exoskeleton Robot W3. Ce lancement établit un nouveau record de légèreté
Recommandations de sujets spéciaux liés
Création de bande dessinée
Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Claude Opus 4.7 fait son entrée sur le marché en misant davantage sur la fiabilité que sur l'intelligence
Anthropic a maintenu un rythme soutenu cette année, en déployant de nouvelles fonctionnalités presque tous les deux jours. Le très attendu Claude Opus 4.7 vient d'être officiellement lancé, et il est
Haier lance le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde, pesant seulement 1,75 kg
Le groupe Haier a présenté le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde : le Haier Exoskeleton Robot W3. Ce lancement établit un nouveau record de légèreté
Recommandations de sujets spéciaux liés
Création de bande dessinée
 Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
 15 outils
15 outils
 xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

 commentaires (3)
commentaires (3)
![JeffreyThomas]()
Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
![DonaldGonzález]()
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
![CarlMartin]()
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅
Les entreprises doivent s'assurer que leurs modèles d'IA, qui pilotent les applications, fonctionnent efficacement dans des scénarios réels. Prédire ces scénarios peut être difficile, compliquant les évaluations. Le benchmark RewardBench 2 mis à jour offre aux organisations des informations plus claires sur les performances pratiques d'un modèle.
L’Institut Allen pour l’IA (Ai2) a introduit RewardBench 2, une version améliorée de son benchmark RewardBench, conçue pour fournir une évaluation complète des performances des modèles et de leur alignement avec les objectifs des entreprises.
Ai2 a développé RewardBench avec des tâches de classification évaluant les corrélations via le calcul au moment de l'inférence et l'entraînement en aval. RewardBench se concentre sur les modèles de récompense (RMs), qui jugent les sorties des grands modèles de langage en attribuant des scores ou « récompenses » pour guider l'apprentissage par renforcement avec retour humain (RHLF).
RewardBench 2 est là ! Nous avons pris le temps d’apprendre de notre premier outil d’évaluation de modèle de récompense pour en créer un nettement plus difficile et plus corrélé avec l’RLHF en aval et l’échelle au moment de l’inférence. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2 juin 2025
Nathan Lambert, chercheur senior chez Ai2, a déclaré à VentureBeat que le RewardBench original fonctionnait bien initialement, mais l’évolution des environnements des modèles exigeait des benchmarks actualisés.
« À mesure que les modèles de récompense devenaient plus sophistiqués et les cas d’utilisation plus complexes, nous avons constaté, avec la communauté, que la première version ne répondait pas pleinement aux complexités des préférences humaines en conditions réelles », a-t-il expliqué.
Lambert a noté que RewardBench 2 améliore la portée et la profondeur des évaluations, intégrant des invites variées et exigeantes ainsi que des méthodes affinées pour mieux refléter le jugement humain des sorties d’IA. Il inclut de nouvelles invites humaines, un système de notation plus strict et des domaines supplémentaires.
Utilisation des évaluations pour l'évaluation des modèles
Les modèles de récompense évaluent les performances des modèles, mais l’alignement avec les valeurs de l’entreprise est crucial. Des RMs mal alignés peuvent amplifier des problèmes comme les hallucinations, réduire la généralisation ou favoriser excessivement des réponses nuisibles pendant l’ajustement fin et l’apprentissage par renforcement.
RewardBench 2 couvre six domaines : factualité, respect précis des instructions, mathématiques, sécurité, concentration et égalités.
« Les entreprises peuvent utiliser RewardBench 2 de deux manières selon leurs besoins. Pour l’RLHF, elles doivent intégrer les meilleures pratiques et ensembles de données des meilleurs modèles dans leurs pipelines, car les modèles de récompense nécessitent un entraînement sur politique. Pour l’échelle au moment de l’inférence ou le filtrage des données, RewardBench 2 aide à sélectionner le meilleur modèle pour leur domaine avec des performances corrélées », a déclaré Lambert.
Lambert a souligné que des benchmarks comme RewardBench permettent aux utilisateurs d’évaluer les modèles en fonction des priorités les plus pertinentes pour eux, plutôt qu’un score générique. Il a noté que les performances sont subjectives, fortement liées au contexte et aux objectifs des utilisateurs, avec des préférences humaines souvent très nuancées.
Ai2 a lancé le RewardBench original en mars 2024, le qualifiant de premier benchmark et classement des modèles de récompense. Depuis, de nouvelles méthodes comme FAIR reWordBench de Meta et Self-Principled Critique Tuning de DeepSeek ont émergé pour des RMs plus intelligents et évolutifs.
Super excité que notre deuxième évaluation de modèle de récompense soit sortie. Elle est nettement plus difficile, beaucoup plus propre et bien corrélée avec l’échantillonnage PPO/BoN en aval.
— Nathan Lambert (@natolambert) 2 juin 2025
Joyeuse ascension !
Félicitations énormes à @saumyamalik44 qui a dirigé le projet avec un engagement total pour l’excellence. https://t.co/c0b6rHTXY5
Perspectives sur les performances des modèles
Avec RewardBench 2, Ai2 a testé des modèles existants et nouvellement entraînés, y compris des variantes de Gemini, Claude, GPT-4.1 et Llama-3.1, ainsi que des ensembles de données et modèles comme Qwen, Skywork et Tulu.
Les résultats ont montré que les modèles de récompense plus grands excellent grâce à des modèles de base plus robustes. Les variantes Instruct de Llama-3.1 ont dominé le benchmark, avec les données Skywork aidant à la concentration et à la sécurité, et Tulu performant bien en factualité.
Ai2 a noté que bien que RewardBench 2 fasse progresser l’évaluation multidomaine axée sur la précision pour les modèles de récompense, il devrait principalement guider les entreprises dans la sélection des modèles les mieux adaptés à leurs besoins spécifiques.










 Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
 Claude Opus 4.7 fait son entrée sur le marché en misant davantage sur la fiabilité que sur l'intelligence
Anthropic a maintenu un rythme soutenu cette année, en déployant de nouvelles fonctionnalités presque tous les deux jours. Le très attendu Claude Opus 4.7 vient d'être officiellement lancé, et il est
Claude Opus 4.7 fait son entrée sur le marché en misant davantage sur la fiabilité que sur l'intelligence
Anthropic a maintenu un rythme soutenu cette année, en déployant de nouvelles fonctionnalités presque tous les deux jours. Le très attendu Claude Opus 4.7 vient d'être officiellement lancé, et il est
 Haier lance le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde, pesant seulement 1,75 kg
Le groupe Haier a présenté le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde : le Haier Exoskeleton Robot W3. Ce lancement établit un nouveau record de légèreté
Haier lance le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde, pesant seulement 1,75 kg
Le groupe Haier a présenté le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde : le Haier Exoskeleton Robot W3. Ce lancement établit un nouveau record de légèreté

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅













