
















 Hogar
HogarOptimización de la Selección de Modelos de IA para un Rendimiento en el Mundo Real
Las empresas deben asegurarse de que los modelos de IA que impulsan sus aplicaciones funcionen eficazmente en escenarios del mundo real. Predecir estos escenarios puede ser desafiante, lo que complica las evaluaciones. El benchmark actualizado RewardBench 2 ofrece a las organizaciones una visión más clara del rendimiento práctico de un modelo.
El Instituto Allen para la IA (Ai2) presentó RewardBench 2, una versión mejorada de su benchmark RewardBench, diseñada para proporcionar una evaluación completa del rendimiento del modelo y su alineación con los objetivos empresariales.
Ai2 desarrolló RewardBench con tareas de clasificación que evalúan correlaciones a través de cómputo en tiempo de inferencia y entrenamiento descendente. RewardBench se centra en modelos de recompensa (RMs), que evalúan las salidas de modelos de lenguaje grandes asignando puntuaciones o “recompensas” para guiar el aprendizaje por refuerzo con retroalimentación humana (RHLF).
¡RewardBench 2 está aquí! Nos tomamos mucho tiempo para aprender de nuestra primera herramienta de evaluación de modelos de recompensa para crear una que es sustancialmente más difícil y más correlacionada con el RLHF descendente y la escalabilidad en tiempo de inferencia. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2 de junio de 2025
Nathan Lambert, científico investigador senior en Ai2, dijo a VentureBeat que el RewardBench original funcionó bien inicialmente, pero los entornos de modelos en evolución exigían benchmarks actualizados.
“A medida que los modelos de recompensa se volvieron más sofisticados y los casos de uso más complejos, vimos, junto con la comunidad, que la primera versión no abordaba completamente las complejidades de las preferencias humanas en el mundo real,” explicó.
Lambert señaló que RewardBench 2 mejora el alcance y la profundidad de la evaluación, incorporando prompts diversos y desafiantes, y métodos refinados para reflejar mejor el juicio humano sobre las salidas de IA. Incluye nuevos prompts humanos, un sistema de puntuación más riguroso y dominios adicionales.
Aprovechando Evaluaciones para la Evaluación de Modelos
Los modelos de recompensa evalúan el rendimiento del modelo, pero la alineación con los valores de la empresa es crítica. Los RMs desalineados pueden amplificar problemas como alucinaciones, reducir la generalización o favorecer excesivamente respuestas perjudiciales durante el ajuste fino y el aprendizaje por refuerzo.
RewardBench 2 abarca seis dominios: factualidad, adherencia precisa a instrucciones, matemáticas, seguridad, enfoque y empates.
“Las empresas pueden usar RewardBench 2 de dos maneras según sus necesidades. Para RLHF, deben integrar las mejores prácticas y conjuntos de datos de los mejores modelos en sus flujos de trabajo, ya que los modelos de recompensa requieren entrenamiento en política. Para la escalabilidad en tiempo de inferencia o el filtrado de datos, RewardBench 2 ayuda a seleccionar el mejor modelo para su dominio con un rendimiento correlacionado,” dijo Lambert.
Lambert enfatizó que los benchmarks como RewardBench permiten a los usuarios evaluar modelos según las prioridades más relevantes para ellos, en lugar de una puntuación genérica. Señaló que el rendimiento es subjetivo, muy ligado al contexto y los objetivos del usuario, con preferencias humanas a menudo muy matizadas.
Ai2 lanzó el RewardBench original en marzo de 2024, llamándolo el primer benchmark y tabla de clasificación de modelos de recompensa. Desde entonces, han surgido nuevos métodos como FAIR reWordBench de Meta y Self-Principled Critique Tuning de DeepSeek para RMs más inteligentes y escalables.
¡Súper emocionado de que nuestra segunda evaluación de modelos de recompensa esté lista! Es sustancialmente más difícil, mucho más limpia y bien correlacionada con el muestreo PPO/BoN descendente.
¡Feliz escalada!
Enorme felicitación a @saumyamalik44, quien lideró el proyecto con un compromiso total con la excelencia. https://t.co/c0b6rHTXY5
— Nathan Lambert (@natolambert) 2 de junio de 2025
Perspectivas sobre el Rendimiento de los Modelos
Con RewardBench 2, Ai2 probó tanto modelos existentes como recién entrenados, incluyendo variantes de Gemini, Claude, GPT-4.1 y Llama-3.1, junto con conjuntos de datos y modelos como Qwen, Skywork y Tulu.
Los hallazgos mostraron que los modelos de recompensa más grandes destacan debido a modelos base más fuertes. Las variantes de Llama-3.1 Instruct lideraron el benchmark, con los datos de Skywork ayudando en enfoque y seguridad, y Tulu destacando en factualidad.
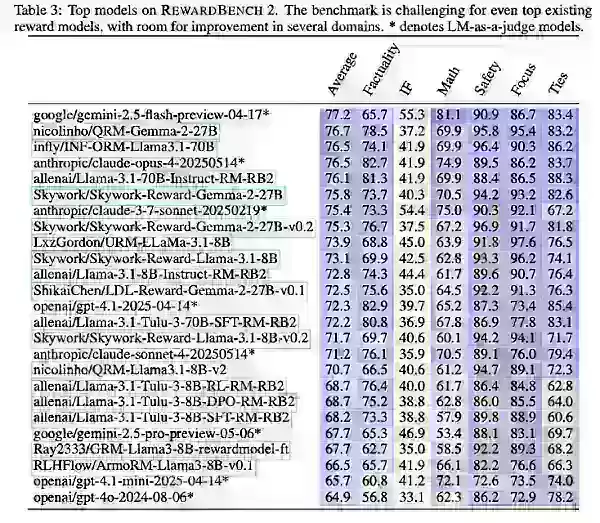
Ai2 señaló que, aunque RewardBench 2 avanza en la evaluación multidominio y centrada en la precisión para modelos de recompensa, debería guiar principalmente a las empresas en la selección de modelos más adecuados para sus necesidades específicas.
Artículo relacionado
 Haier lanza el robot exoesqueleto deportivo con IA más ligero del mundo, con un peso de tan solo 1,75 kg
El Grupo Haier ha presentado el robot exoesqueleto con inteligencia artificial más ligero del mundo para el deporte: el Haier Exoskeleton Robot W3. Este lanzamiento establece un nuevo récord del secto
La primera serie de AIGC de Yaoke Media, «El misterio del bronce en Qinling», se estrena hoy con protagonistas creados por IA
Hoy se estrena oficialmente la miniserie de misterio y fantasía con IA generativa (AIGC) de Yaoke Media, «La historia secreta del bronce de Qinling». Protagonizada por los dos primeros actores de IA c
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Recomendaciones de temas especiales relacionados
Negocio
Haier lanza el robot exoesqueleto deportivo con IA más ligero del mundo, con un peso de tan solo 1,75 kg
El Grupo Haier ha presentado el robot exoesqueleto con inteligencia artificial más ligero del mundo para el deporte: el Haier Exoskeleton Robot W3. Este lanzamiento establece un nuevo récord del secto
La primera serie de AIGC de Yaoke Media, «El misterio del bronce en Qinling», se estrena hoy con protagonistas creados por IA
Hoy se estrena oficialmente la miniserie de misterio y fantasía con IA generativa (AIGC) de Yaoke Media, «La historia secreta del bronce de Qinling». Protagonizada por los dos primeros actores de IA c
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Recomendaciones de temas especiales relacionados
Negocio
 Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
 10 herramientas
10 herramientas
 xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai
chatbot
Los mejores entrenadores de IA para ligar y conversar: mejora tu carisma social y tu confianza en tiempo real
Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

 comentario (3)
0/500
comentario (3)
0/500
![JeffreyThomas]()
Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
![DonaldGonzález]()
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
![CarlMartin]()
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅
Las empresas deben asegurarse de que los modelos de IA que impulsan sus aplicaciones funcionen eficazmente en escenarios del mundo real. Predecir estos escenarios puede ser desafiante, lo que complica las evaluaciones. El benchmark actualizado RewardBench 2 ofrece a las organizaciones una visión más clara del rendimiento práctico de un modelo.
El Instituto Allen para la IA (Ai2) presentó RewardBench 2, una versión mejorada de su benchmark RewardBench, diseñada para proporcionar una evaluación completa del rendimiento del modelo y su alineación con los objetivos empresariales.
Ai2 desarrolló RewardBench con tareas de clasificación que evalúan correlaciones a través de cómputo en tiempo de inferencia y entrenamiento descendente. RewardBench se centra en modelos de recompensa (RMs), que evalúan las salidas de modelos de lenguaje grandes asignando puntuaciones o “recompensas” para guiar el aprendizaje por refuerzo con retroalimentación humana (RHLF).
¡RewardBench 2 está aquí! Nos tomamos mucho tiempo para aprender de nuestra primera herramienta de evaluación de modelos de recompensa para crear una que es sustancialmente más difícil y más correlacionada con el RLHF descendente y la escalabilidad en tiempo de inferencia. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2 de junio de 2025
Nathan Lambert, científico investigador senior en Ai2, dijo a VentureBeat que el RewardBench original funcionó bien inicialmente, pero los entornos de modelos en evolución exigían benchmarks actualizados.
“A medida que los modelos de recompensa se volvieron más sofisticados y los casos de uso más complejos, vimos, junto con la comunidad, que la primera versión no abordaba completamente las complejidades de las preferencias humanas en el mundo real,” explicó.
Lambert señaló que RewardBench 2 mejora el alcance y la profundidad de la evaluación, incorporando prompts diversos y desafiantes, y métodos refinados para reflejar mejor el juicio humano sobre las salidas de IA. Incluye nuevos prompts humanos, un sistema de puntuación más riguroso y dominios adicionales.
Aprovechando Evaluaciones para la Evaluación de Modelos
Los modelos de recompensa evalúan el rendimiento del modelo, pero la alineación con los valores de la empresa es crítica. Los RMs desalineados pueden amplificar problemas como alucinaciones, reducir la generalización o favorecer excesivamente respuestas perjudiciales durante el ajuste fino y el aprendizaje por refuerzo.
RewardBench 2 abarca seis dominios: factualidad, adherencia precisa a instrucciones, matemáticas, seguridad, enfoque y empates.
“Las empresas pueden usar RewardBench 2 de dos maneras según sus necesidades. Para RLHF, deben integrar las mejores prácticas y conjuntos de datos de los mejores modelos en sus flujos de trabajo, ya que los modelos de recompensa requieren entrenamiento en política. Para la escalabilidad en tiempo de inferencia o el filtrado de datos, RewardBench 2 ayuda a seleccionar el mejor modelo para su dominio con un rendimiento correlacionado,” dijo Lambert.
Lambert enfatizó que los benchmarks como RewardBench permiten a los usuarios evaluar modelos según las prioridades más relevantes para ellos, en lugar de una puntuación genérica. Señaló que el rendimiento es subjetivo, muy ligado al contexto y los objetivos del usuario, con preferencias humanas a menudo muy matizadas.
Ai2 lanzó el RewardBench original en marzo de 2024, llamándolo el primer benchmark y tabla de clasificación de modelos de recompensa. Desde entonces, han surgido nuevos métodos como FAIR reWordBench de Meta y Self-Principled Critique Tuning de DeepSeek para RMs más inteligentes y escalables.
¡Súper emocionado de que nuestra segunda evaluación de modelos de recompensa esté lista! Es sustancialmente más difícil, mucho más limpia y bien correlacionada con el muestreo PPO/BoN descendente.
— Nathan Lambert (@natolambert) 2 de junio de 2025
¡Feliz escalada!
Enorme felicitación a @saumyamalik44, quien lideró el proyecto con un compromiso total con la excelencia. https://t.co/c0b6rHTXY5
Perspectivas sobre el Rendimiento de los Modelos
Con RewardBench 2, Ai2 probó tanto modelos existentes como recién entrenados, incluyendo variantes de Gemini, Claude, GPT-4.1 y Llama-3.1, junto con conjuntos de datos y modelos como Qwen, Skywork y Tulu.
Los hallazgos mostraron que los modelos de recompensa más grandes destacan debido a modelos base más fuertes. Las variantes de Llama-3.1 Instruct lideraron el benchmark, con los datos de Skywork ayudando en enfoque y seguridad, y Tulu destacando en factualidad.
Ai2 señaló que, aunque RewardBench 2 avanza en la evaluación multidominio y centrada en la precisión para modelos de recompensa, debería guiar principalmente a las empresas en la selección de modelos más adecuados para sus necesidades específicas.










 Haier lanza el robot exoesqueleto deportivo con IA más ligero del mundo, con un peso de tan solo 1,75 kg
El Grupo Haier ha presentado el robot exoesqueleto con inteligencia artificial más ligero del mundo para el deporte: el Haier Exoskeleton Robot W3. Este lanzamiento establece un nuevo récord del secto
Haier lanza el robot exoesqueleto deportivo con IA más ligero del mundo, con un peso de tan solo 1,75 kg
El Grupo Haier ha presentado el robot exoesqueleto con inteligencia artificial más ligero del mundo para el deporte: el Haier Exoskeleton Robot W3. Este lanzamiento establece un nuevo récord del secto
 La primera serie de AIGC de Yaoke Media, «El misterio del bronce en Qinling», se estrena hoy con protagonistas creados por IA
Hoy se estrena oficialmente la miniserie de misterio y fantasía con IA generativa (AIGC) de Yaoke Media, «La historia secreta del bronce de Qinling». Protagonizada por los dos primeros actores de IA c
La primera serie de AIGC de Yaoke Media, «El misterio del bronce en Qinling», se estrena hoy con protagonistas creados por IA
Hoy se estrena oficialmente la miniserie de misterio y fantasía con IA generativa (AIGC) de Yaoke Media, «La historia secreta del bronce de Qinling». Protagonizada por los dos primeros actores de IA c
 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos

Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅













