
















 首页
首页优化AI模型选择以实现现实世界性能
企业必须确保其驱动应用的AI模型在现实世界场景中有效运行。预测这些场景可能具有挑战性,使评估复杂化。更新后的RewardBench 2基准为组织提供了更清晰的模型实际性能洞察。
艾伦人工智能研究所(Ai2)推出了RewardBench 2,这是其RewardBench基准的增强版,旨在全面评估模型性能以及与企业目标的契合度。
Ai2开发了RewardBench,包含分类任务,通过推理时计算和下游训练评估相关性。RewardBench专注于奖励模型(RMs),这些模型通过分配分数或“奖励”来判断大型语言模型输出,以指导基于人类反馈的强化学习(RHLF)。
RewardBench 2来了!我们花了很长时间从首个奖励模型评估工具中学习,打造了一个难度大幅提升、与下游RLHF和推理时扩展更相关的工具。pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2025年6月2日
Ai2高级研究科学家Nathan Lambert对VentureBeat表示,最初的RewardBench表现良好,但模型环境的演变要求更新基准。
“随着奖励模型变得更复杂,用例更复杂,我们与社区一起发现,第一版未能完全解决现实世界中人类偏好的复杂性,”他解释道。
Lambert指出,RewardBench 2改进了评估范围和深度,纳入了多样化、具有挑战性的提示和优化方法,以更好地反映人类对AI输出的判断。它包括新的人类提示、更严格的评分系统和额外领域。
利用评估进行模型评估
奖励模型评估模型性能,但与公司价值观的契合至关重要。未对齐的奖励模型可能放大幻觉、降低泛化能力或在微调和强化学习中过度偏向有害响应。
RewardBench 2涵盖六个领域:事实性、精确指令遵循、数学、安全性、专注度和关联性。
“企业可根据需求以两种方式使用RewardBench 2。对于RLHF,应将顶级模型的最佳实践和数据集整合到其流程中,因为奖励模型需要在线训练。对于推理时扩展或数据过滤,RewardBench 2帮助选择与其领域性能相关的最佳模型,”Lambert说。
Lambert强调,像RewardBench这样的基准允许用户根据最相关的优先级评估模型,而非通用分数。他指出,性能是主观的,与用户背景和目标密切相关,人类偏好往往非常微妙。
Ai2于2024年3月推出原始RewardBench,称其为首个奖励模型基准和排行榜。此后,出现了Meta的FAIR reWordBench和DeepSeek的自我原则批判调优等新方法,用于更智能、可扩展的奖励模型。
非常兴奋我们的第二个奖励模型评估发布。它难度大幅提升,更清晰,与下游PPO/BoN采样高度相关。
祝爬坡愉快!
衷心祝贺@saumyamalik44,她以卓越的承诺领导了这个项目。https://t.co/c0b6rHTXY5
— Nathan Lambert (@natolambert) 2025年6月2日
模型性能洞察
通过RewardBench 2,Ai2测试了现有和新训练的模型,包括Gemini、Claude、GPT-4.1和Llama-3.1的变体,以及Qwen、Skywork和Tulu等数据集和模型。
结果显示,较大的奖励模型因更强大的基础模型而表现优异。Llama-3.1 Instruct变体在基准测试中名列前茅,Skywork数据有助于专注度和安全性,Tulu在事实性方面表现良好。
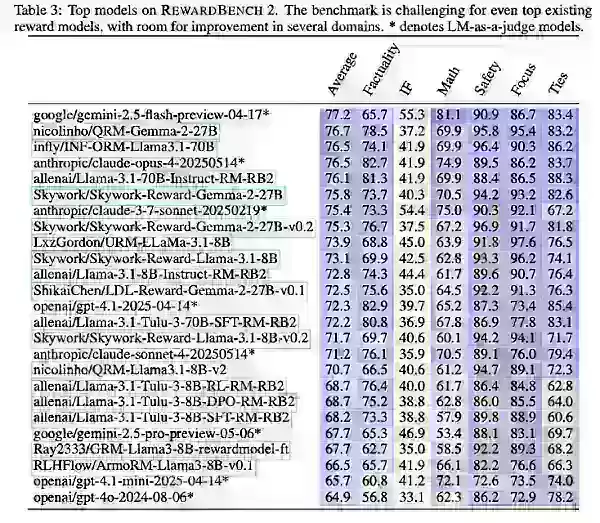
Ai2指出,虽然RewardBench 2推动了多领域、注重准确性的奖励模型评估,但企业应主要用它来选择最适合其特定需求的模型。
相关文章
 小红书进行组织架构调整:柯南出任总裁,新设AI主营部门Dots及海外业务部门Rednote
4月30日,小红书向全体员工发布内部通告,宣布启动新一轮组织架构调整。此次调整的核心在于将社区、电商和商业化三大业务线与公司的技术系统全面整合。 公司新设了名为“Dots”的AI优先部门,这标志着小红书已正式将AI提升为最高战略优先级,旨在使其从工具性功能转变为核心生产力。在人事任命方面,南(丁玲)被任命为小红书总裁,负责公司核心业务运营,并直接向CEO邢宇汇报。 各业务板块负责人也已明确:智恒将
腾讯旗下“小龙虾”表现远超预期,团队将运力扩大10倍,并致歉及提供补偿
腾讯正式推出全场景AI智能助手“WorkBuddy”,凭借高度集成和低部署门槛,标志着大型模型应用层竞争进入新阶段。该产品在发布当天便引发了业界广泛关注。 用户流量远超预期,导致相关产品腾讯云代码助手(CodeBuddy)出现登录故障及服务不稳定。腾讯云团队随后发布致歉声明,表示技术团队已紧急将容量扩容十倍,目前服务已全面恢复。受影响用户获得了5,000腾讯云代金券作为补偿。业界观察人士将Work
Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争
相关专题推荐
漫画创作
小红书进行组织架构调整:柯南出任总裁,新设AI主营部门Dots及海外业务部门Rednote
4月30日,小红书向全体员工发布内部通告,宣布启动新一轮组织架构调整。此次调整的核心在于将社区、电商和商业化三大业务线与公司的技术系统全面整合。 公司新设了名为“Dots”的AI优先部门,这标志着小红书已正式将AI提升为最高战略优先级,旨在使其从工具性功能转变为核心生产力。在人事任命方面,南(丁玲)被任命为小红书总裁,负责公司核心业务运营,并直接向CEO邢宇汇报。 各业务板块负责人也已明确:智恒将
腾讯旗下“小龙虾”表现远超预期,团队将运力扩大10倍,并致歉及提供补偿
腾讯正式推出全场景AI智能助手“WorkBuddy”,凭借高度集成和低部署门槛,标志着大型模型应用层竞争进入新阶段。该产品在发布当天便引发了业界广泛关注。 用户流量远超预期,导致相关产品腾讯云代码助手(CodeBuddy)出现登录故障及服务不稳定。腾讯云团队随后发布致歉声明,表示技术团队已紧急将容量扩容十倍,目前服务已全面恢复。受影响用户获得了5,000腾讯云代金券作为补偿。业界观察人士将Work
Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争
相关专题推荐
漫画创作
 少年漫画顶级AI生成器:打造高能动作场面与特效
少年漫画顶级AI生成器:打造高能动作场面与特效
在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
 15 个工具
15 个工具
 xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

 评论 (3)
0/500
评论 (3)
0/500
![JeffreyThomas]()
Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
![DonaldGonzález]()
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
![CarlMartin]()
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅
企业必须确保其驱动应用的AI模型在现实世界场景中有效运行。预测这些场景可能具有挑战性,使评估复杂化。更新后的RewardBench 2基准为组织提供了更清晰的模型实际性能洞察。
艾伦人工智能研究所(Ai2)推出了RewardBench 2,这是其RewardBench基准的增强版,旨在全面评估模型性能以及与企业目标的契合度。
Ai2开发了RewardBench,包含分类任务,通过推理时计算和下游训练评估相关性。RewardBench专注于奖励模型(RMs),这些模型通过分配分数或“奖励”来判断大型语言模型输出,以指导基于人类反馈的强化学习(RHLF)。
RewardBench 2来了!我们花了很长时间从首个奖励模型评估工具中学习,打造了一个难度大幅提升、与下游RLHF和推理时扩展更相关的工具。pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2025年6月2日
Ai2高级研究科学家Nathan Lambert对VentureBeat表示,最初的RewardBench表现良好,但模型环境的演变要求更新基准。
“随着奖励模型变得更复杂,用例更复杂,我们与社区一起发现,第一版未能完全解决现实世界中人类偏好的复杂性,”他解释道。
Lambert指出,RewardBench 2改进了评估范围和深度,纳入了多样化、具有挑战性的提示和优化方法,以更好地反映人类对AI输出的判断。它包括新的人类提示、更严格的评分系统和额外领域。
利用评估进行模型评估
奖励模型评估模型性能,但与公司价值观的契合至关重要。未对齐的奖励模型可能放大幻觉、降低泛化能力或在微调和强化学习中过度偏向有害响应。
RewardBench 2涵盖六个领域:事实性、精确指令遵循、数学、安全性、专注度和关联性。
“企业可根据需求以两种方式使用RewardBench 2。对于RLHF,应将顶级模型的最佳实践和数据集整合到其流程中,因为奖励模型需要在线训练。对于推理时扩展或数据过滤,RewardBench 2帮助选择与其领域性能相关的最佳模型,”Lambert说。
Lambert强调,像RewardBench这样的基准允许用户根据最相关的优先级评估模型,而非通用分数。他指出,性能是主观的,与用户背景和目标密切相关,人类偏好往往非常微妙。
Ai2于2024年3月推出原始RewardBench,称其为首个奖励模型基准和排行榜。此后,出现了Meta的FAIR reWordBench和DeepSeek的自我原则批判调优等新方法,用于更智能、可扩展的奖励模型。
非常兴奋我们的第二个奖励模型评估发布。它难度大幅提升,更清晰,与下游PPO/BoN采样高度相关。
— Nathan Lambert (@natolambert) 2025年6月2日
祝爬坡愉快!
衷心祝贺@saumyamalik44,她以卓越的承诺领导了这个项目。https://t.co/c0b6rHTXY5
模型性能洞察
通过RewardBench 2,Ai2测试了现有和新训练的模型,包括Gemini、Claude、GPT-4.1和Llama-3.1的变体,以及Qwen、Skywork和Tulu等数据集和模型。
结果显示,较大的奖励模型因更强大的基础模型而表现优异。Llama-3.1 Instruct变体在基准测试中名列前茅,Skywork数据有助于专注度和安全性,Tulu在事实性方面表现良好。
Ai2指出,虽然RewardBench 2推动了多领域、注重准确性的奖励模型评估,但企业应主要用它来选择最适合其特定需求的模型。










 小红书进行组织架构调整:柯南出任总裁,新设AI主营部门Dots及海外业务部门Rednote
4月30日,小红书向全体员工发布内部通告,宣布启动新一轮组织架构调整。此次调整的核心在于将社区、电商和商业化三大业务线与公司的技术系统全面整合。 公司新设了名为“Dots”的AI优先部门,这标志着小红书已正式将AI提升为最高战略优先级,旨在使其从工具性功能转变为核心生产力。在人事任命方面,南(丁玲)被任命为小红书总裁,负责公司核心业务运营,并直接向CEO邢宇汇报。 各业务板块负责人也已明确:智恒将
小红书进行组织架构调整:柯南出任总裁,新设AI主营部门Dots及海外业务部门Rednote
4月30日,小红书向全体员工发布内部通告,宣布启动新一轮组织架构调整。此次调整的核心在于将社区、电商和商业化三大业务线与公司的技术系统全面整合。 公司新设了名为“Dots”的AI优先部门,这标志着小红书已正式将AI提升为最高战略优先级,旨在使其从工具性功能转变为核心生产力。在人事任命方面,南(丁玲)被任命为小红书总裁,负责公司核心业务运营,并直接向CEO邢宇汇报。 各业务板块负责人也已明确:智恒将
 腾讯旗下“小龙虾”表现远超预期,团队将运力扩大10倍,并致歉及提供补偿
腾讯正式推出全场景AI智能助手“WorkBuddy”,凭借高度集成和低部署门槛,标志着大型模型应用层竞争进入新阶段。该产品在发布当天便引发了业界广泛关注。 用户流量远超预期,导致相关产品腾讯云代码助手(CodeBuddy)出现登录故障及服务不稳定。腾讯云团队随后发布致歉声明,表示技术团队已紧急将容量扩容十倍,目前服务已全面恢复。受影响用户获得了5,000腾讯云代金券作为补偿。业界观察人士将Work
腾讯旗下“小龙虾”表现远超预期,团队将运力扩大10倍,并致歉及提供补偿
腾讯正式推出全场景AI智能助手“WorkBuddy”,凭借高度集成和低部署门槛,标志着大型模型应用层竞争进入新阶段。该产品在发布当天便引发了业界广泛关注。 用户流量远超预期,导致相关产品腾讯云代码助手(CodeBuddy)出现登录故障及服务不稳定。腾讯云团队随后发布致歉声明,表示技术团队已紧急将容量扩容十倍,目前服务已全面恢复。受影响用户获得了5,000腾讯云代金券作为补偿。业界观察人士将Work
 Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争
Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争

在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅













