
















 家
家実世界のパフォーマンスのためのAIモデル選択の最適化
企業は、アプリケーションを駆動するAIモデルが実際のシナリオで効果的に機能することを確保する必要があります。これらのシナリオを予測することは難しく、評価を複雑にします。更新されたRewardBench 2ベンチマークは、組織にモデルの実際のパフォーマンスに関するより明確な洞察を提供します。
Allen Institute for AI(Ai2)は、RewardBench 2を導入しました。これは、モデルのパフォーマンスと企業の目標との整合性を包括的に評価するために設計されたRewardBenchベンチマークの改良版です。
Ai2は、推論時の計算や下流のトレーニングを通じて相関を評価する分類タスクでRewardBenchを開発しました。RewardBenchは、報酬モデル(RMs)に焦点を当て、大規模言語モデルの出力を評価し、人間のフィードバックによる強化学習(RHLF)を導くためにスコアまたは「報酬」を割り当てます。
RewardBench 2が登場!私たちは最初の報酬モデル評価ツールから学び、はるかに難しく、下流のRLHFや推論時のスケーリングにより強く相関するものを作りました。pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2025年6月2日
Ai2の主任研究者であるNathan Lambertは、VentureBeatに対し、元のRewardBenchは当初は良好に機能したが、進化するモデル環境には更新されたベンチマークが必要だったと語りました。
「報酬モデルがより高度になり、ユースケースが複雑になるにつれ、コミュニティと共に、最初のバージョンが実世界の人間の好みの複雑さを完全に扱えていないことがわかりました」と彼は説明しました。
Lambertは、RewardBench 2が評価の範囲と深さを改善し、多様で挑戦的なプロンプトや、AI出力の人間の判断をよりよく反映する改良された手法を組み込んでいると指摘しました。これには新しい人間のプロンプト、より厳しいスコアリングシステム、追加のドメインが含まれます。
モデル評価のための評価の活用
報酬モデルはモデルパフォーマンスを評価しますが、企業の価値観との整合性が重要です。整合性のない報酬モデルは、幻覚を増幅したり、一般化を減少させたり、微調整や強化学習中に有害な応答を過度に優先する問題を引き起こす可能性があります。
RewardBench 2は、事実性、正確な指示の遵守、数学、安全性、焦点、タイの6つのドメインをカバーしています。
「企業は、ニーズに基づいてRewardBench 2を2つの方法で使用できます。RLHFの場合、トップモデルのベストプラクティスとデータセットをパイプラインに統合する必要があります。報酬モデルにはオンライントレーニングが必要です。推論時のスケーリングやデータフィルタリングの場合、RewardBench 2は相関するパフォーマンスでドメインに最適なモデルを選択するのに役立ちます」とLambertは述べました。
Lambertは、RewardBenchのようなベンチマークを使用することで、ユーザーは一般的なスコアではなく、自分にとって最も関連性の高い優先順位に基づいてモデルを評価できると強調しました。彼は、パフォーマンスは主観的であり、ユーザーのコンテキストや目標に強く関連し、人間の好みはしばしば非常に微妙であると指摘しました。
Ai2は、2024年3月に最初のRewardBenchを立ち上げ、初の報酬モデルベンチマークおよびリーダーボードと呼びました。それ以来、MetaのFAIR reWordBenchやDeepSeekのSelf-Principled Critique Tuningなど、よりスマートでスケーラブルな報酬モデルのための新しい手法が登場しています。
2番目の報酬モデル評価が公開されてとても興奮しています。はるかに難しく、ずっとクリーンで、下流のPPO/BoNサンプリングとよく相関しています。
ハッピー・ヒルクライミング!
@saumyamalik44がプロジェクトを卓越したコミットメントでリードしたことを大いに祝福します。https://t.co/c0b6rHTXY5
— Nathan Lambert (@natolambert) 2025年6月2日
モデルパフォーマンスの洞察
RewardBench 2を使用して、Ai2は既存および新たに訓練されたモデルをテストしました。これには、Gemini、Claude、GPT-4.1、Llama-3.1のバリアントや、Qwen、Skywork、Tuluなどのデータセットやモデルが含まれます。
結果は、より強力な基盤モデルにより、大きな報酬モデルが優れていることを示しました。Llama-3.1 Instructバリアントがベンチマークのトップに立ち、Skyworkデータは焦点と安全性を助け、Tuluは事実性で優れたパフォーマンスを示しました。
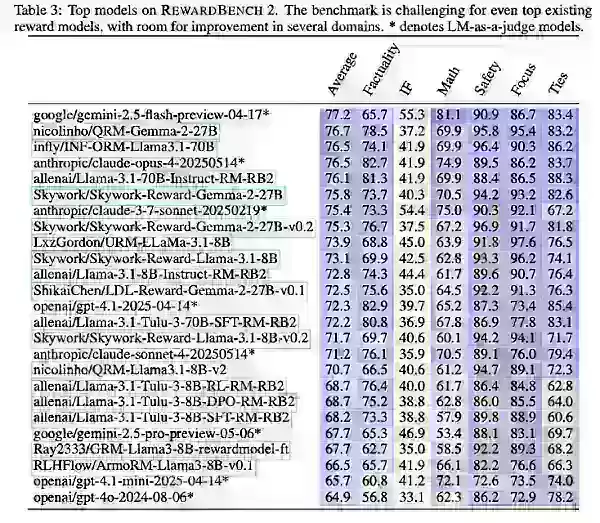
Ai2は、RewardBench 2が多ドメインで精度に焦点を当てた報酬モデルの評価を進化させる一方で、主に企業が特定のニーズに最適なモデルを選択する際のガイドとなるべきだと指摘しました。
関連記事
 「Claude Opus 4.7」がリリース、AIの知能よりも信頼性を重視
Anthropicは今年、ほぼ1日おきに新機能をリリースするなど、積極的なペースを維持しています。待望のClaude Opus 4.7がついに正式にリリースされましたが、興味深いことに、Anthropicは発表の中で「これは当社で最も強力なモデルではありません」と率直に述べています。 噂されている、より強力な「Claude Mythos Preview」は依然として待機状態にある。それでも、Opu
ハイアール、重量わずか1.75kgの世界最軽量AIスポーツ用外骨格ロボットを発表
ハイアールグループは、スポーツ用として世界最軽量のAI搭載外骨格ロボット「ハイアール・エクソスケルトン・ロボット W3」を発表しました。この製品の発売により、軽量化において業界新記録を樹立し、軽量設計と人間の動作をインテリジェントに強化する技術において大きな飛躍を遂げました。高級素材が実現する超軽量設計W3は、フルカーボンファイバーとチタン合金を組み合わせた革新的な一体成型プロセスを採用しています
Yaoke Media初のAIGCドラマ『秦嶺の青銅の謎』が本日配信開始、AIが演じる主演キャストが登場
本日、Yaoke MediaのAIGCファンタジー・ミステリー短編ドラマ『秦嶺青銅の秘話』が正式に公開されました。同社が初めて契約した2人のAI俳優、秦凌月と林西燕燕が主演を務め、物語は謎に包まれた秦嶺の鉱山地帯を舞台に展開されます。 物語は、引退した諜報員・秦月がチームを率いてその奥深くへと入り込み、長年埋もれていた鉱山事故と、2世代にわたる血の生贄の真実を暴いていく様子を描きます。その真実は、
関連特集おすすめ
仕事
「Claude Opus 4.7」がリリース、AIの知能よりも信頼性を重視
Anthropicは今年、ほぼ1日おきに新機能をリリースするなど、積極的なペースを維持しています。待望のClaude Opus 4.7がついに正式にリリースされましたが、興味深いことに、Anthropicは発表の中で「これは当社で最も強力なモデルではありません」と率直に述べています。 噂されている、より強力な「Claude Mythos Preview」は依然として待機状態にある。それでも、Opu
ハイアール、重量わずか1.75kgの世界最軽量AIスポーツ用外骨格ロボットを発表
ハイアールグループは、スポーツ用として世界最軽量のAI搭載外骨格ロボット「ハイアール・エクソスケルトン・ロボット W3」を発表しました。この製品の発売により、軽量化において業界新記録を樹立し、軽量設計と人間の動作をインテリジェントに強化する技術において大きな飛躍を遂げました。高級素材が実現する超軽量設計W3は、フルカーボンファイバーとチタン合金を組み合わせた革新的な一体成型プロセスを採用しています
Yaoke Media初のAIGCドラマ『秦嶺の青銅の謎』が本日配信開始、AIが演じる主演キャストが登場
本日、Yaoke MediaのAIGCファンタジー・ミステリー短編ドラマ『秦嶺青銅の秘話』が正式に公開されました。同社が初めて契約した2人のAI俳優、秦凌月と林西燕燕が主演を務め、物語は謎に包まれた秦嶺の鉱山地帯を舞台に展開されます。 物語は、引退した諜報員・秦月がチームを率いてその奥深くへと入り込み、長年埋もれていた鉱山事故と、2世代にわたる血の生贄の真実を暴いていく様子を描きます。その真実は、
関連特集おすすめ
仕事
 おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
 10 ツール
10 ツール
 xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

 コメント (3)
0/500
コメント (3)
0/500
![JeffreyThomas]()
Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
![DonaldGonzález]()
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
![CarlMartin]()
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅
企業は、アプリケーションを駆動するAIモデルが実際のシナリオで効果的に機能することを確保する必要があります。これらのシナリオを予測することは難しく、評価を複雑にします。更新されたRewardBench 2ベンチマークは、組織にモデルの実際のパフォーマンスに関するより明確な洞察を提供します。
Allen Institute for AI(Ai2)は、RewardBench 2を導入しました。これは、モデルのパフォーマンスと企業の目標との整合性を包括的に評価するために設計されたRewardBenchベンチマークの改良版です。
Ai2は、推論時の計算や下流のトレーニングを通じて相関を評価する分類タスクでRewardBenchを開発しました。RewardBenchは、報酬モデル(RMs)に焦点を当て、大規模言語モデルの出力を評価し、人間のフィードバックによる強化学習(RHLF)を導くためにスコアまたは「報酬」を割り当てます。
RewardBench 2が登場!私たちは最初の報酬モデル評価ツールから学び、はるかに難しく、下流のRLHFや推論時のスケーリングにより強く相関するものを作りました。pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2025年6月2日
Ai2の主任研究者であるNathan Lambertは、VentureBeatに対し、元のRewardBenchは当初は良好に機能したが、進化するモデル環境には更新されたベンチマークが必要だったと語りました。
「報酬モデルがより高度になり、ユースケースが複雑になるにつれ、コミュニティと共に、最初のバージョンが実世界の人間の好みの複雑さを完全に扱えていないことがわかりました」と彼は説明しました。
Lambertは、RewardBench 2が評価の範囲と深さを改善し、多様で挑戦的なプロンプトや、AI出力の人間の判断をよりよく反映する改良された手法を組み込んでいると指摘しました。これには新しい人間のプロンプト、より厳しいスコアリングシステム、追加のドメインが含まれます。
モデル評価のための評価の活用
報酬モデルはモデルパフォーマンスを評価しますが、企業の価値観との整合性が重要です。整合性のない報酬モデルは、幻覚を増幅したり、一般化を減少させたり、微調整や強化学習中に有害な応答を過度に優先する問題を引き起こす可能性があります。
RewardBench 2は、事実性、正確な指示の遵守、数学、安全性、焦点、タイの6つのドメインをカバーしています。
「企業は、ニーズに基づいてRewardBench 2を2つの方法で使用できます。RLHFの場合、トップモデルのベストプラクティスとデータセットをパイプラインに統合する必要があります。報酬モデルにはオンライントレーニングが必要です。推論時のスケーリングやデータフィルタリングの場合、RewardBench 2は相関するパフォーマンスでドメインに最適なモデルを選択するのに役立ちます」とLambertは述べました。
Lambertは、RewardBenchのようなベンチマークを使用することで、ユーザーは一般的なスコアではなく、自分にとって最も関連性の高い優先順位に基づいてモデルを評価できると強調しました。彼は、パフォーマンスは主観的であり、ユーザーのコンテキストや目標に強く関連し、人間の好みはしばしば非常に微妙であると指摘しました。
Ai2は、2024年3月に最初のRewardBenchを立ち上げ、初の報酬モデルベンチマークおよびリーダーボードと呼びました。それ以来、MetaのFAIR reWordBenchやDeepSeekのSelf-Principled Critique Tuningなど、よりスマートでスケーラブルな報酬モデルのための新しい手法が登場しています。
2番目の報酬モデル評価が公開されてとても興奮しています。はるかに難しく、ずっとクリーンで、下流のPPO/BoNサンプリングとよく相関しています。
— Nathan Lambert (@natolambert) 2025年6月2日
ハッピー・ヒルクライミング!
@saumyamalik44がプロジェクトを卓越したコミットメントでリードしたことを大いに祝福します。https://t.co/c0b6rHTXY5
モデルパフォーマンスの洞察
RewardBench 2を使用して、Ai2は既存および新たに訓練されたモデルをテストしました。これには、Gemini、Claude、GPT-4.1、Llama-3.1のバリアントや、Qwen、Skywork、Tuluなどのデータセットやモデルが含まれます。
結果は、より強力な基盤モデルにより、大きな報酬モデルが優れていることを示しました。Llama-3.1 Instructバリアントがベンチマークのトップに立ち、Skyworkデータは焦点と安全性を助け、Tuluは事実性で優れたパフォーマンスを示しました。
Ai2は、RewardBench 2が多ドメインで精度に焦点を当てた報酬モデルの評価を進化させる一方で、主に企業が特定のニーズに最適なモデルを選択する際のガイドとなるべきだと指摘しました。










 「Claude Opus 4.7」がリリース、AIの知能よりも信頼性を重視
Anthropicは今年、ほぼ1日おきに新機能をリリースするなど、積極的なペースを維持しています。待望のClaude Opus 4.7がついに正式にリリースされましたが、興味深いことに、Anthropicは発表の中で「これは当社で最も強力なモデルではありません」と率直に述べています。 噂されている、より強力な「Claude Mythos Preview」は依然として待機状態にある。それでも、Opu
「Claude Opus 4.7」がリリース、AIの知能よりも信頼性を重視
Anthropicは今年、ほぼ1日おきに新機能をリリースするなど、積極的なペースを維持しています。待望のClaude Opus 4.7がついに正式にリリースされましたが、興味深いことに、Anthropicは発表の中で「これは当社で最も強力なモデルではありません」と率直に述べています。 噂されている、より強力な「Claude Mythos Preview」は依然として待機状態にある。それでも、Opu
 ハイアール、重量わずか1.75kgの世界最軽量AIスポーツ用外骨格ロボットを発表
ハイアールグループは、スポーツ用として世界最軽量のAI搭載外骨格ロボット「ハイアール・エクソスケルトン・ロボット W3」を発表しました。この製品の発売により、軽量化において業界新記録を樹立し、軽量設計と人間の動作をインテリジェントに強化する技術において大きな飛躍を遂げました。高級素材が実現する超軽量設計W3は、フルカーボンファイバーとチタン合金を組み合わせた革新的な一体成型プロセスを採用しています
ハイアール、重量わずか1.75kgの世界最軽量AIスポーツ用外骨格ロボットを発表
ハイアールグループは、スポーツ用として世界最軽量のAI搭載外骨格ロボット「ハイアール・エクソスケルトン・ロボット W3」を発表しました。この製品の発売により、軽量化において業界新記録を樹立し、軽量設計と人間の動作をインテリジェントに強化する技術において大きな飛躍を遂げました。高級素材が実現する超軽量設計W3は、フルカーボンファイバーとチタン合金を組み合わせた革新的な一体成型プロセスを採用しています
 Yaoke Media初のAIGCドラマ『秦嶺の青銅の謎』が本日配信開始、AIが演じる主演キャストが登場
本日、Yaoke MediaのAIGCファンタジー・ミステリー短編ドラマ『秦嶺青銅の秘話』が正式に公開されました。同社が初めて契約した2人のAI俳優、秦凌月と林西燕燕が主演を務め、物語は謎に包まれた秦嶺の鉱山地帯を舞台に展開されます。 物語は、引退した諜報員・秦月がチームを率いてその奥深くへと入り込み、長年埋もれていた鉱山事故と、2世代にわたる血の生贄の真実を暴いていく様子を描きます。その真実は、
Yaoke Media初のAIGCドラマ『秦嶺の青銅の謎』が本日配信開始、AIが演じる主演キャストが登場
本日、Yaoke MediaのAIGCファンタジー・ミステリー短編ドラマ『秦嶺青銅の秘話』が正式に公開されました。同社が初めて契約した2人のAI俳優、秦凌月と林西燕燕が主演を務め、物語は謎に包まれた秦嶺の鉱山地帯を舞台に展開されます。 物語は、引退した諜報員・秦月がチームを率いてその奥深くへと入り込み、長年埋もれていた鉱山事故と、2世代にわたる血の生贄の真実を暴いていく様子を描きます。その真実は、

2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅













