
















 Heim
HeimOptimierung der Auswahl von KI-Modellen für reale Leistung
Unternehmen müssen sicherstellen, dass ihre anwendungstreibenden KI-Modelle in realen Szenarien effektiv funktionieren. Die Vorhersage dieser Szenarien kann herausfordernd sein und Bewertungen erschweren. Der aktualisierte RewardBench 2-Benchmark bietet Organisationen klarere Einblicke in die praktische Leistung eines Modells.
Das Allen Institute for AI (Ai2) hat RewardBench 2 eingeführt, eine verbesserte Version seines RewardBench-Benchmarks, der entwickelt wurde, um eine umfassende Bewertung der Modellleistung und Ausrichtung auf Unternehmensziele zu bieten.
Ai2 entwickelte RewardBench mit Klassifikationsaufgaben, die Korrelationen über Inferenzzeit-Berechnungen und nachgelagertes Training bewerten. RewardBench konzentriert sich auf Belohnungsmodelle (RMs), die die Ausgaben großer Sprachmodelle bewerten, indem sie Punktzahlen oder „Belohnungen“ vergeben, um Reinforcement Learning mit menschlichem Feedback (RHLF) zu steuern.
RewardBench 2 ist da! Wir haben lange gelernt aus unserem ersten Belohnungsmodell-Bewertungstool, um eines zu entwickeln, das deutlich schwieriger ist und stärker mit nachgelagertem RLHF und Inferenzzeit-Skalierung korreliert. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2. Juni 2025
Nathan Lambert, ein leitender Forschungswissenschaftler bei Ai2, sagte VentureBeat, dass der ursprüngliche RewardBench zunächst gut funktionierte, aber sich entwickelnde Modellumgebungen aktualisierte Benchmarks erforderten.
„Da Belohnungsmodelle ausgefeilter wurden und Anwendungsfälle komplexer, sahen wir zusammen mit der Gemeinschaft, dass die erste Version die Komplexitäten menschlicher Präferenzen in der realen Welt nicht vollständig abdeckte“, erklärte er.
Lambert betonte, dass RewardBench 2 den Bewertungsumfang und die Tiefe verbessert, indem es vielfältige, herausfordernde Eingaben und verfeinerte Methoden integriert, um menschliche Urteile über KI-Ausgaben besser widerzuspiegeln. Es umfasst neue menschliche Eingaben, ein härteres Bewertungssystem und zusätzliche Domänen.
Nutzung von Bewertungen für die Modellbeurteilung
Belohnungsmodelle bewerten die Modellleistung, aber die Ausrichtung auf Unternehmenswerte ist entscheidend. Nicht ausgerichtete RMs können Probleme wie Halluzinationen verstärken, die Verallgemeinerung reduzieren oder schädliche Antworten während des Feinabstimmens und Reinforcement Learnings übermäßig begünstigen.
RewardBench 2 umfasst sechs Domänen: Faktenhaltigkeit, präzise Befolgen von Anweisungen, Mathematik, Sicherheit, Fokus und Gleichstand.
„Unternehmen können RewardBench 2 auf zwei Arten je nach ihren Bedürfnissen nutzen. Für RLHF sollten sie Best Practices und Datensätze von Top-Modellen in ihre Pipelines integrieren, da Belohnungsmodelle ein On-Policy-Training erfordern. Für Inferenzzeit-Skalierung oder Datenfilterung hilft RewardBench 2, das beste Modell für ihre Domäne mit korrelierter Leistung auszuwählen“, sagte Lambert.
Lambert betonte, dass Benchmarks wie RewardBench Nutzern ermöglichen, Modelle basierend auf ihren wichtigsten Prioritäten zu bewerten, anstatt auf eine generische Punktzahl. Er merkte an, dass die Leistung subjektiv ist, stark an den Nutzerkontext und die Ziele gebunden, wobei menschliche Präferenzen oft sehr nuanciert sind.
Ai2 brachte den ursprünglichen RewardBench im März 2024 auf den Markt und nannte ihn den ersten Benchmark und Leaderboard für Belohnungsmodelle. Seitdem sind neue Methoden wie Meta’s FAIR reWordBench und DeepSeek’s Self-Principled Critique Tuning für intelligentere, skalierbare RMs entstanden.
Super begeistert, dass unsere zweite Belohnungsmodell-Bewertung veröffentlicht ist. Sie ist deutlich schwieriger, viel sauberer und gut korreliert mit nachgelagertem PPO/BoN Sampling.
Frohes Hillclimbing!
Herzlichen Glückwunsch an @saumyamalik44, die das Projekt mit vollem Einsatz für Exzellenz leitete. https://t.co/c0b6rHTXY5
— Nathan Lambert (@natolambert) 2. Juni 2025
Erkenntnisse zur Modellleistung
Mit RewardBench 2 testete Ai2 sowohl bestehende als auch neu trainierte Modelle, einschließlich Varianten von Gemini, Claude, GPT-4.1 und Llama-3.1, neben Datensätzen und Modellen wie Qwen, Skywork und Tulu.
Die Ergebnisse zeigten, dass größere Belohnungsmodelle aufgrund stärkerer Basismodelle hervorragend abschneiden. Llama-3.1 Instruct-Varianten führten den Benchmark an, wobei Skywork-Daten Fokus und Sicherheit unterstützten und Tulu in Faktenhaltigkeit gut abschnitt.
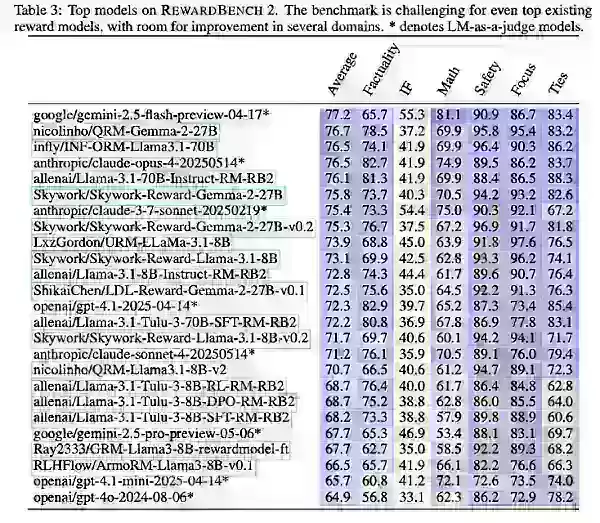
Ai2 stellte fest, dass RewardBench 2 zwar die multidomänen- und genauigkeitsorientierte Bewertung für Belohnungsmodelle vorantreibt, aber in erster Linie Unternehmen dabei leiten sollte, Modelle auszuwählen, die am besten ihren spezifischen Bedürfnissen entsprechen.
Verwandter Artikel
 WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
Empfehlungen zu verwandten Spezialthemen
Geschäft
WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
Empfehlungen zu verwandten Spezialthemen
Geschäft
 Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
 10 Tools
10 Tools
 xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai
Code
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

 Kommentare (3)
Kommentare (3)
![JeffreyThomas]()
Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
![DonaldGonzález]()
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
![CarlMartin]()
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅
Unternehmen müssen sicherstellen, dass ihre anwendungstreibenden KI-Modelle in realen Szenarien effektiv funktionieren. Die Vorhersage dieser Szenarien kann herausfordernd sein und Bewertungen erschweren. Der aktualisierte RewardBench 2-Benchmark bietet Organisationen klarere Einblicke in die praktische Leistung eines Modells.
Das Allen Institute for AI (Ai2) hat RewardBench 2 eingeführt, eine verbesserte Version seines RewardBench-Benchmarks, der entwickelt wurde, um eine umfassende Bewertung der Modellleistung und Ausrichtung auf Unternehmensziele zu bieten.
Ai2 entwickelte RewardBench mit Klassifikationsaufgaben, die Korrelationen über Inferenzzeit-Berechnungen und nachgelagertes Training bewerten. RewardBench konzentriert sich auf Belohnungsmodelle (RMs), die die Ausgaben großer Sprachmodelle bewerten, indem sie Punktzahlen oder „Belohnungen“ vergeben, um Reinforcement Learning mit menschlichem Feedback (RHLF) zu steuern.
RewardBench 2 ist da! Wir haben lange gelernt aus unserem ersten Belohnungsmodell-Bewertungstool, um eines zu entwickeln, das deutlich schwieriger ist und stärker mit nachgelagertem RLHF und Inferenzzeit-Skalierung korreliert. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2. Juni 2025
Nathan Lambert, ein leitender Forschungswissenschaftler bei Ai2, sagte VentureBeat, dass der ursprüngliche RewardBench zunächst gut funktionierte, aber sich entwickelnde Modellumgebungen aktualisierte Benchmarks erforderten.
„Da Belohnungsmodelle ausgefeilter wurden und Anwendungsfälle komplexer, sahen wir zusammen mit der Gemeinschaft, dass die erste Version die Komplexitäten menschlicher Präferenzen in der realen Welt nicht vollständig abdeckte“, erklärte er.
Lambert betonte, dass RewardBench 2 den Bewertungsumfang und die Tiefe verbessert, indem es vielfältige, herausfordernde Eingaben und verfeinerte Methoden integriert, um menschliche Urteile über KI-Ausgaben besser widerzuspiegeln. Es umfasst neue menschliche Eingaben, ein härteres Bewertungssystem und zusätzliche Domänen.
Nutzung von Bewertungen für die Modellbeurteilung
Belohnungsmodelle bewerten die Modellleistung, aber die Ausrichtung auf Unternehmenswerte ist entscheidend. Nicht ausgerichtete RMs können Probleme wie Halluzinationen verstärken, die Verallgemeinerung reduzieren oder schädliche Antworten während des Feinabstimmens und Reinforcement Learnings übermäßig begünstigen.
RewardBench 2 umfasst sechs Domänen: Faktenhaltigkeit, präzise Befolgen von Anweisungen, Mathematik, Sicherheit, Fokus und Gleichstand.
„Unternehmen können RewardBench 2 auf zwei Arten je nach ihren Bedürfnissen nutzen. Für RLHF sollten sie Best Practices und Datensätze von Top-Modellen in ihre Pipelines integrieren, da Belohnungsmodelle ein On-Policy-Training erfordern. Für Inferenzzeit-Skalierung oder Datenfilterung hilft RewardBench 2, das beste Modell für ihre Domäne mit korrelierter Leistung auszuwählen“, sagte Lambert.
Lambert betonte, dass Benchmarks wie RewardBench Nutzern ermöglichen, Modelle basierend auf ihren wichtigsten Prioritäten zu bewerten, anstatt auf eine generische Punktzahl. Er merkte an, dass die Leistung subjektiv ist, stark an den Nutzerkontext und die Ziele gebunden, wobei menschliche Präferenzen oft sehr nuanciert sind.
Ai2 brachte den ursprünglichen RewardBench im März 2024 auf den Markt und nannte ihn den ersten Benchmark und Leaderboard für Belohnungsmodelle. Seitdem sind neue Methoden wie Meta’s FAIR reWordBench und DeepSeek’s Self-Principled Critique Tuning für intelligentere, skalierbare RMs entstanden.
Super begeistert, dass unsere zweite Belohnungsmodell-Bewertung veröffentlicht ist. Sie ist deutlich schwieriger, viel sauberer und gut korreliert mit nachgelagertem PPO/BoN Sampling.
— Nathan Lambert (@natolambert) 2. Juni 2025
Frohes Hillclimbing!
Herzlichen Glückwunsch an @saumyamalik44, die das Projekt mit vollem Einsatz für Exzellenz leitete. https://t.co/c0b6rHTXY5
Erkenntnisse zur Modellleistung
Mit RewardBench 2 testete Ai2 sowohl bestehende als auch neu trainierte Modelle, einschließlich Varianten von Gemini, Claude, GPT-4.1 und Llama-3.1, neben Datensätzen und Modellen wie Qwen, Skywork und Tulu.
Die Ergebnisse zeigten, dass größere Belohnungsmodelle aufgrund stärkerer Basismodelle hervorragend abschneiden. Llama-3.1 Instruct-Varianten führten den Benchmark an, wobei Skywork-Daten Fokus und Sicherheit unterstützten und Tulu in Faktenhaltigkeit gut abschnitt.
Ai2 stellte fest, dass RewardBench 2 zwar die multidomänen- und genauigkeitsorientierte Bewertung für Belohnungsmodelle vorantreibt, aber in erster Linie Unternehmen dabei leiten sollte, Modelle auszuwählen, die am besten ihren spezifischen Bedürfnissen entsprechen.










 WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
 Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
 DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅













