
















 집
집실세계 성능을 위한 AI 모델 선택 최적화
기업은 애플리케이션을 구동하는 AI 모델이 실세계 시나리오에서 효과적으로 작동해야 합니다. 이러한 시나리오를 예측하는 것은 평가를 복잡하게 만드는 도전 과제입니다. 업데이트된 RewardBench 2 벤치마크는 조직에 모델의 실제 성능에 대한 더 명확한 통찰을 제공합니다.
Allen Institute for AI (Ai2)는 RewardBench 벤치마크의 향상된 버전인 RewardBench 2를 도입했으며, 이는 모델 성능과 기업 목표와의 정렬을 포괄적으로 평가하도록 설계되었습니다.
Ai2는 추론 시간 계산 및 하위 훈련을 통해 상관관계를 평가하는 분류 작업으로 RewardBench를 개발했습니다. RewardBench는 보상 모델(RMs)에 초점을 맞추며, 이는 대형 언어 모델의 출력에 점수 또는 "보상"을 부여하여 인간 피드백을 통한 강화 학습(RHLF)을 안내합니다.
RewardBench 2가 나왔습니다! 우리는 첫 번째 보상 모델 평가 도구에서 많은 것을 배우며 더 어렵고 하위 RLHF 및 추론 시간 스케일링과 더 높은 상관관계를 가진 도구를 만들었습니다. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2025년 6월 2일
Ai2의 선임 연구 과학자인 Nathan Lambert는 VentureBeat에 원래의 RewardBench가 초기에 잘 작동했지만, 모델 환경의 변화로 인해 업데이트된 벤치마크가 필요했다고 전했습니다.
“보상 모델이 더욱 정교해지고 사용 사례가 복잡해짐에 따라, 우리는 커뮤니티와 함께 첫 번째 버전이 실세계 인간 선호도의 복잡성을 완전히 다루지 못한다는 것을 알게 되었습니다,”라고 그는 설명했습니다.
Lambert는 RewardBench 2가 평가 범위와 깊이를 개선하여 다양하고 도전적인 프롬프트를 포함하고, AI 출력에 대한 인간 판단을 더 잘 반영하도록 세밀한 방법을 도입했다고 언급했습니다. 이는 새로운 인간 프롬프트, 더 엄격한 점수 시스템, 그리고 추가 도메인을 포함합니다.
모델 평가를 위한 평가 활용
보상 모델은 모델 성능을 평가하지만, 기업 가치와의 정렬이 중요합니다. 정렬되지 않은 보상 모델은 환각, 일반화 감소, 또는 미세 조정 및 강화 학습 중에 유해한 응답을 지나치게 선호하는 문제를 증폭시킬 수 있습니다.
RewardBench 2는 사실성, 정확한 지침 준수, 수학, 안전성, 초점, 그리고 동률 등 여섯 개의 도메인을 다룹니다.
“기업은 필요에 따라 RewardBench 2를 두 가지 방식으로 사용할 수 있습니다. RLHF의 경우, 최상위 모델의 모범 사례와 데이터셋을 파이프라인에 통합해야 하며, 보상 모델은 정책 기반 훈련이 필요합니다. 추론 시간 스케일링 또는 데이터 필터링의 경우, RewardBench 2는 상관 성능을 통해 도메인에 가장 적합한 모델을 선택하는 데 도움을 줍니다,”라고 Lambert는 말했습니다.
Lambert는 RewardBench와 같은 벤치마크를 통해 사용자가 일반적인 점수가 아닌 자신에게 가장 중요한 우선순위에 따라 모델을 평가할 수 있다고 강조했습니다. 그는 성능이 주관적이며, 사용자 맥락과 목표에 크게 좌우되며, 인간 선호도가 종종 매우 미묘하다고 언급했습니다.
Ai2는 2024년 3월에 최초의 보상 모델 벤치마크이자 리더보드인 RewardBench를 출시했습니다. 이후 Meta의 FAIR reWordBench와 DeepSeek의 Self-Principled Critique Tuning과 같은 새로운 방법이 더 똑똑하고 확장 가능한 보상 모델을 위해 등장했습니다.
두 번째 보상 모델 평가가 나와서 매우 기쁩니다. 훨씬 더 어렵고, 훨씬 더 깔끔하며, 하위 PPO/BoN 샘플링과 잘 연관되어 있습니다.
행복한 힐클라이밍하세요!
@saumyamalik44가 프로젝트를 탁월함에 대한 전적인 헌신으로 이끈 것에 큰 축하를 보냅니다. https://t.co/c0b6rHTXY5
— Nathan Lambert (@natolambert) 2025년 6월 2일
모델 성능 통찰
RewardBench 2를 통해 Ai2는 Gemini, Claude, GPT-4.1, Llama-3.1의 변형을 포함한 기존 및 새로 훈련된 모델과 Qwen, Skywork, Tulu와 같은 데이터셋 및 모델을 테스트했습니다.
결과는 더 강력한 기본 모델로 인해 더 큰 보상 모델이 뛰어났음을 보여주었습니다. Llama-3.1 Instruct 변형이 벤치마크에서 1위를 차지했으며, Skywork 데이터는 초점과 안전성에 도움을 주었고, Tulu는 사실성에서 좋은 성과를 보였습니다.
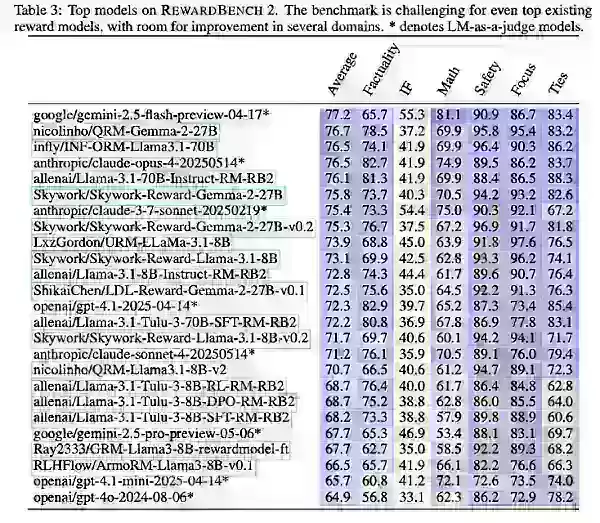
Ai2는 RewardBench 2가 다중 도메인, 정확성 중심의 보상 모델 평가를 발전시켰지만, 주로 기업이 특정 요구에 가장 적합한 모델을 선택하는 데 지침을 제공해야 한다고 언급했습니다.
관련 기사
 야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
WordPress.com에서는 이제 AI 에이전트가 게시물을 작성하고 게시할 수 있게 되었으며, 그 외에도 다양한 기능이 추가되었습니다
인기 웹 호스팅 및 게시 플랫폼인 WordPress.com이 이제 AI 에이전트를 도입하고 있으며, 이는 웹의 모습과 사용 경험을 재편할 수 있는 움직임입니다. 이 회사는 금요일, AI 에이전트가 고객 웹사이트에서 콘텐츠를 작성, 편집 및 게시할 뿐만 아니라 댓글을 관리하고, 메타데이터를 업데이트 및 수정하며, 태그와 카테고리를 통해 콘텐츠를 정리할 수 있
관련 특별 주제 추천
사업
야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
WordPress.com에서는 이제 AI 에이전트가 게시물을 작성하고 게시할 수 있게 되었으며, 그 외에도 다양한 기능이 추가되었습니다
인기 웹 호스팅 및 게시 플랫폼인 WordPress.com이 이제 AI 에이전트를 도입하고 있으며, 이는 웹의 모습과 사용 경험을 재편할 수 있는 움직임입니다. 이 회사는 금요일, AI 에이전트가 고객 웹사이트에서 콘텐츠를 작성, 편집 및 게시할 뿐만 아니라 댓글을 관리하고, 메타데이터를 업데이트 및 수정하며, 태그와 카테고리를 통해 콘텐츠를 정리할 수 있
관련 특별 주제 추천
사업
 최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
 10 도구
10 도구
 xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai
교육 및 학습
최고의 AI 데이터 과학 멘토들: SQL, Pandas 및 머신 러닝 워크플로우 마스터하기
2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai
챗봇
최고의 AI 유혹 및 대화 트레이너: 실시간으로 사회적 매력과 자신감을 높여보세요
XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai

 의견 (3)
0/500
의견 (3)
0/500
![JeffreyThomas]()
Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
![DonaldGonzález]()
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
![CarlMartin]()
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅
기업은 애플리케이션을 구동하는 AI 모델이 실세계 시나리오에서 효과적으로 작동해야 합니다. 이러한 시나리오를 예측하는 것은 평가를 복잡하게 만드는 도전 과제입니다. 업데이트된 RewardBench 2 벤치마크는 조직에 모델의 실제 성능에 대한 더 명확한 통찰을 제공합니다.
Allen Institute for AI (Ai2)는 RewardBench 벤치마크의 향상된 버전인 RewardBench 2를 도입했으며, 이는 모델 성능과 기업 목표와의 정렬을 포괄적으로 평가하도록 설계되었습니다.
Ai2는 추론 시간 계산 및 하위 훈련을 통해 상관관계를 평가하는 분류 작업으로 RewardBench를 개발했습니다. RewardBench는 보상 모델(RMs)에 초점을 맞추며, 이는 대형 언어 모델의 출력에 점수 또는 "보상"을 부여하여 인간 피드백을 통한 강화 학습(RHLF)을 안내합니다.
RewardBench 2가 나왔습니다! 우리는 첫 번째 보상 모델 평가 도구에서 많은 것을 배우며 더 어렵고 하위 RLHF 및 추론 시간 스케일링과 더 높은 상관관계를 가진 도구를 만들었습니다. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2025년 6월 2일
Ai2의 선임 연구 과학자인 Nathan Lambert는 VentureBeat에 원래의 RewardBench가 초기에 잘 작동했지만, 모델 환경의 변화로 인해 업데이트된 벤치마크가 필요했다고 전했습니다.
“보상 모델이 더욱 정교해지고 사용 사례가 복잡해짐에 따라, 우리는 커뮤니티와 함께 첫 번째 버전이 실세계 인간 선호도의 복잡성을 완전히 다루지 못한다는 것을 알게 되었습니다,”라고 그는 설명했습니다.
Lambert는 RewardBench 2가 평가 범위와 깊이를 개선하여 다양하고 도전적인 프롬프트를 포함하고, AI 출력에 대한 인간 판단을 더 잘 반영하도록 세밀한 방법을 도입했다고 언급했습니다. 이는 새로운 인간 프롬프트, 더 엄격한 점수 시스템, 그리고 추가 도메인을 포함합니다.
모델 평가를 위한 평가 활용
보상 모델은 모델 성능을 평가하지만, 기업 가치와의 정렬이 중요합니다. 정렬되지 않은 보상 모델은 환각, 일반화 감소, 또는 미세 조정 및 강화 학습 중에 유해한 응답을 지나치게 선호하는 문제를 증폭시킬 수 있습니다.
RewardBench 2는 사실성, 정확한 지침 준수, 수학, 안전성, 초점, 그리고 동률 등 여섯 개의 도메인을 다룹니다.
“기업은 필요에 따라 RewardBench 2를 두 가지 방식으로 사용할 수 있습니다. RLHF의 경우, 최상위 모델의 모범 사례와 데이터셋을 파이프라인에 통합해야 하며, 보상 모델은 정책 기반 훈련이 필요합니다. 추론 시간 스케일링 또는 데이터 필터링의 경우, RewardBench 2는 상관 성능을 통해 도메인에 가장 적합한 모델을 선택하는 데 도움을 줍니다,”라고 Lambert는 말했습니다.
Lambert는 RewardBench와 같은 벤치마크를 통해 사용자가 일반적인 점수가 아닌 자신에게 가장 중요한 우선순위에 따라 모델을 평가할 수 있다고 강조했습니다. 그는 성능이 주관적이며, 사용자 맥락과 목표에 크게 좌우되며, 인간 선호도가 종종 매우 미묘하다고 언급했습니다.
Ai2는 2024년 3월에 최초의 보상 모델 벤치마크이자 리더보드인 RewardBench를 출시했습니다. 이후 Meta의 FAIR reWordBench와 DeepSeek의 Self-Principled Critique Tuning과 같은 새로운 방법이 더 똑똑하고 확장 가능한 보상 모델을 위해 등장했습니다.
두 번째 보상 모델 평가가 나와서 매우 기쁩니다. 훨씬 더 어렵고, 훨씬 더 깔끔하며, 하위 PPO/BoN 샘플링과 잘 연관되어 있습니다.
— Nathan Lambert (@natolambert) 2025년 6월 2일
행복한 힐클라이밍하세요!
@saumyamalik44가 프로젝트를 탁월함에 대한 전적인 헌신으로 이끈 것에 큰 축하를 보냅니다. https://t.co/c0b6rHTXY5
모델 성능 통찰
RewardBench 2를 통해 Ai2는 Gemini, Claude, GPT-4.1, Llama-3.1의 변형을 포함한 기존 및 새로 훈련된 모델과 Qwen, Skywork, Tulu와 같은 데이터셋 및 모델을 테스트했습니다.
결과는 더 강력한 기본 모델로 인해 더 큰 보상 모델이 뛰어났음을 보여주었습니다. Llama-3.1 Instruct 변형이 벤치마크에서 1위를 차지했으며, Skywork 데이터는 초점과 안전성에 도움을 주었고, Tulu는 사실성에서 좋은 성과를 보였습니다.
Ai2는 RewardBench 2가 다중 도메인, 정확성 중심의 보상 모델 평가를 발전시켰지만, 주로 기업이 특정 요구에 가장 적합한 모델을 선택하는 데 지침을 제공해야 한다고 언급했습니다.










 야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
 사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
 WordPress.com에서는 이제 AI 에이전트가 게시물을 작성하고 게시할 수 있게 되었으며, 그 외에도 다양한 기능이 추가되었습니다
인기 웹 호스팅 및 게시 플랫폼인 WordPress.com이 이제 AI 에이전트를 도입하고 있으며, 이는 웹의 모습과 사용 경험을 재편할 수 있는 움직임입니다. 이 회사는 금요일, AI 에이전트가 고객 웹사이트에서 콘텐츠를 작성, 편집 및 게시할 뿐만 아니라 댓글을 관리하고, 메타데이터를 업데이트 및 수정하며, 태그와 카테고리를 통해 콘텐츠를 정리할 수 있
WordPress.com에서는 이제 AI 에이전트가 게시물을 작성하고 게시할 수 있게 되었으며, 그 외에도 다양한 기능이 추가되었습니다
인기 웹 호스팅 및 게시 플랫폼인 WordPress.com이 이제 AI 에이전트를 도입하고 있으며, 이는 웹의 모습과 사용 경험을 재편할 수 있는 움직임입니다. 이 회사는 금요일, AI 에이전트가 고객 웹사이트에서 콘텐츠를 작성, 편집 및 게시할 뿐만 아니라 댓글을 관리하고, 메타데이터를 업데이트 및 수정하며, 태그와 카테고리를 통해 콘텐츠를 정리할 수 있

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai

Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅













