
















 Lar
LarOtimizando a Seleção de Modelos de IA para Desempenho no Mundo Real
As empresas devem garantir que seus modelos de IA que impulsionam aplicações performem efetivamente em cenários do mundo real. Prever esses cenários pode ser desafiador, complicando as avaliações. O benchmark RewardBench 2 atualizado oferece às organizações insights mais claros sobre o desempenho prático de um modelo.
O Allen Institute for AI (Ai2) introduziu o RewardBench 2, uma versão aprimorada do seu benchmark RewardBench, projetada para fornecer uma avaliação abrangente do desempenho do modelo e alinhamento com objetivos empresariais.
O Ai2 desenvolveu o RewardBench com tarefas de classificação que avaliam correlações por meio de computação em tempo de inferência e treinamento downstream. O RewardBench foca em modelos de recompensa (RMs), que julgam saídas de modelos de linguagem amplos atribuindo pontuações ou “recompensas” para guiar o aprendizado por reforço com feedback humano (RHLF).
RewardBench 2 está aqui! Levamos um tempo para aprender com nossa primeira ferramenta de avaliação de modelo de recompensa para criar uma que é substancialmente mais difícil e mais correlacionada com RLHF downstream e escalonamento em tempo de inferência. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2 de junho de 2025
Nathan Lambert, cientista de pesquisa sênior no Ai2, disse ao VentureBeat que o RewardBench original funcionou bem inicialmente, mas ambientes de modelos em evolução exigiram benchmarks atualizados.
“À medida que os modelos de recompensa se tornaram mais sofisticados e os casos de uso mais complexos, vimos, junto com a comunidade, que a primeira versão não abordava completamente as complexidades das preferências humanas no mundo real,” ele explicou.
Lambert observou que o RewardBench 2 melhora o escopo e a profundidade da avaliação, incorporando prompts diversos e desafiadores e métodos refinados para refletir melhor o julgamento humano sobre saídas de IA. Ele apresenta novos prompts humanos, um sistema de pontuação mais rigoroso e domínios adicionais.
Aproveitando Avaliações para Avaliação de Modelos
Modelos de recompensa avaliam o desempenho do modelo, mas o alinhamento com os valores da empresa é crítico. RMs desalinhados podem amplificar problemas como alucinações, reduzir a generalização ou favorecer respostas prejudiciais durante o ajuste fino e o aprendizado por reforço.
O RewardBench 2 abrange seis domínios: factualidade, aderência precisa às instruções, matemática, segurança, foco e empates.
“As empresas podem usar o RewardBench 2 de duas maneiras com base em suas necessidades. Para RLHF, devem integrar as melhores práticas e conjuntos de dados de modelos de ponta em seus pipelines, pois os modelos de recompensa requerem treinamento on-policy. Para escalonamento em tempo de inferência ou filtragem de dados, o RewardBench 2 ajuda a selecionar o melhor modelo para seu domínio com desempenho correlacionado,” disse Lambert.
Lambert enfatizou que benchmarks como o RewardBench permitem que os usuários avaliem modelos com base nas prioridades mais relevantes para eles, em vez de uma pontuação genérica. Ele observou que o desempenho é subjetivo, fortemente ligado ao contexto e objetivos do usuário, com preferências humanas frequentemente muito nuançadas.
O Ai2 lançou o RewardBench original em março de 2024, chamando-o de o primeiro benchmark e leaderboard de modelo de recompensa. Desde então, novos métodos como o FAIR reWordBench da Meta e o Self-Principled Critique Tuning da DeepSeek surgiram para RMs mais inteligentes e escaláveis.
Muito animado que nossa segunda avaliação de modelo de recompensa está disponível. É substancialmente mais difícil, muito mais limpa e bem correlacionada com amostragem PPO/BoN downstream.
Feliz escalada!
Parabéns enormes a @saumyamalik44 que liderou o projeto com total compromisso com a excelência. https://t.co/c0b6rHTXY5
— Nathan Lambert (@natolambert) 2 de junho de 2025
Insights sobre o Desempenho dos Modelos
Com o RewardBench 2, o Ai2 testou modelos existentes e recém-treinados, incluindo variantes de Gemini, Claude, GPT-4.1 e Llama-3.1, ao lado de conjuntos de dados e modelos como Qwen, Skywork e Tulu.
As descobertas mostraram que modelos de recompensa maiores se destacam devido a modelos de base mais fortes. Variantes do Llama-3.1 Instruct lideraram o benchmark, com dados do Skywork ajudando no foco e segurança, e o Tulu performando bem em factualidade.
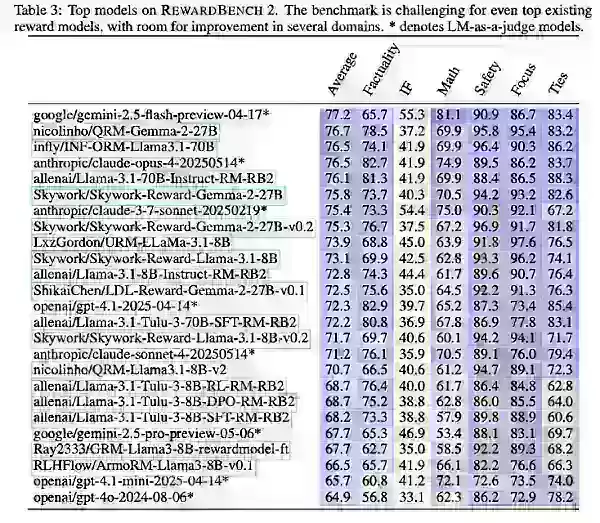
O Ai2 observou que, embora o RewardBench 2 avance na avaliação multidomínio focada em precisão para modelos de recompensa, ele deve principalmente orientar as empresas na seleção de modelos mais adequados às suas necessidades específicas.
Artigo relacionado
 Claude Opus 4.7 é lançado com a confiabilidade em detrimento da inteligência
A Anthropic manteve um ritmo acelerado este ano, lançando novos recursos quase a cada dois dias. O tão aguardado Claude Opus 4.7 acaba de ser lançado oficialmente e, curiosamente, a Anthropic foi dire
A Haier lança o robô exoesqueleto esportivo com IA mais leve do mundo, pesando apenas 1,75 kg
O Grupo Haier apresentou o robô exoesqueleto com inteligência artificial mais leve do mundo para esportes — o Haier Exoskeleton Robot W3. Este lançamento estabelece um novo recorde do setor em termos
A primeira série dramática com AIGC da Yaoke Media, “O Mistério do Bronze em Qinling”, estreia hoje com protagonistas criados por IA
Hoje marca o lançamento oficial da minissérie de mistério e fantasia com IA da Yaoke Media, “A História Secreta do Bronze de Qinling”. Estrelada pelos dois primeiros atores de IA contratados pela empr
Recomendações de tópicos especiais relacionados
Negócios
Claude Opus 4.7 é lançado com a confiabilidade em detrimento da inteligência
A Anthropic manteve um ritmo acelerado este ano, lançando novos recursos quase a cada dois dias. O tão aguardado Claude Opus 4.7 acaba de ser lançado oficialmente e, curiosamente, a Anthropic foi dire
A Haier lança o robô exoesqueleto esportivo com IA mais leve do mundo, pesando apenas 1,75 kg
O Grupo Haier apresentou o robô exoesqueleto com inteligência artificial mais leve do mundo para esportes — o Haier Exoskeleton Robot W3. Este lançamento estabelece um novo recorde do setor em termos
A primeira série dramática com AIGC da Yaoke Media, “O Mistério do Bronze em Qinling”, estreia hoje com protagonistas criados por IA
Hoje marca o lançamento oficial da minissérie de mistério e fantasia com IA da Yaoke Media, “A História Secreta do Bronze de Qinling”. Estrelada pelos dois primeiros atores de IA contratados pela empr
Recomendações de tópicos especiais relacionados
Negócios
 Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
 10 ferramentas
10 ferramentas
 xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai
chatbot
Os melhores treinadores de paquera e conversação com IA: melhore seu carisma social e sua autoconfiança em tempo real
Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

 Comentários (3)
Comentários (3)
![JeffreyThomas]()
Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
![DonaldGonzález]()
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
![CarlMartin]()
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅
As empresas devem garantir que seus modelos de IA que impulsionam aplicações performem efetivamente em cenários do mundo real. Prever esses cenários pode ser desafiador, complicando as avaliações. O benchmark RewardBench 2 atualizado oferece às organizações insights mais claros sobre o desempenho prático de um modelo.
O Allen Institute for AI (Ai2) introduziu o RewardBench 2, uma versão aprimorada do seu benchmark RewardBench, projetada para fornecer uma avaliação abrangente do desempenho do modelo e alinhamento com objetivos empresariais.
O Ai2 desenvolveu o RewardBench com tarefas de classificação que avaliam correlações por meio de computação em tempo de inferência e treinamento downstream. O RewardBench foca em modelos de recompensa (RMs), que julgam saídas de modelos de linguagem amplos atribuindo pontuações ou “recompensas” para guiar o aprendizado por reforço com feedback humano (RHLF).
RewardBench 2 está aqui! Levamos um tempo para aprender com nossa primeira ferramenta de avaliação de modelo de recompensa para criar uma que é substancialmente mais difícil e mais correlacionada com RLHF downstream e escalonamento em tempo de inferência. pic.twitter.com/NGetvNrOQV
— Ai2 (@allen_ai) 2 de junho de 2025
Nathan Lambert, cientista de pesquisa sênior no Ai2, disse ao VentureBeat que o RewardBench original funcionou bem inicialmente, mas ambientes de modelos em evolução exigiram benchmarks atualizados.
“À medida que os modelos de recompensa se tornaram mais sofisticados e os casos de uso mais complexos, vimos, junto com a comunidade, que a primeira versão não abordava completamente as complexidades das preferências humanas no mundo real,” ele explicou.
Lambert observou que o RewardBench 2 melhora o escopo e a profundidade da avaliação, incorporando prompts diversos e desafiadores e métodos refinados para refletir melhor o julgamento humano sobre saídas de IA. Ele apresenta novos prompts humanos, um sistema de pontuação mais rigoroso e domínios adicionais.
Aproveitando Avaliações para Avaliação de Modelos
Modelos de recompensa avaliam o desempenho do modelo, mas o alinhamento com os valores da empresa é crítico. RMs desalinhados podem amplificar problemas como alucinações, reduzir a generalização ou favorecer respostas prejudiciais durante o ajuste fino e o aprendizado por reforço.
O RewardBench 2 abrange seis domínios: factualidade, aderência precisa às instruções, matemática, segurança, foco e empates.
“As empresas podem usar o RewardBench 2 de duas maneiras com base em suas necessidades. Para RLHF, devem integrar as melhores práticas e conjuntos de dados de modelos de ponta em seus pipelines, pois os modelos de recompensa requerem treinamento on-policy. Para escalonamento em tempo de inferência ou filtragem de dados, o RewardBench 2 ajuda a selecionar o melhor modelo para seu domínio com desempenho correlacionado,” disse Lambert.
Lambert enfatizou que benchmarks como o RewardBench permitem que os usuários avaliem modelos com base nas prioridades mais relevantes para eles, em vez de uma pontuação genérica. Ele observou que o desempenho é subjetivo, fortemente ligado ao contexto e objetivos do usuário, com preferências humanas frequentemente muito nuançadas.
O Ai2 lançou o RewardBench original em março de 2024, chamando-o de o primeiro benchmark e leaderboard de modelo de recompensa. Desde então, novos métodos como o FAIR reWordBench da Meta e o Self-Principled Critique Tuning da DeepSeek surgiram para RMs mais inteligentes e escaláveis.
Muito animado que nossa segunda avaliação de modelo de recompensa está disponível. É substancialmente mais difícil, muito mais limpa e bem correlacionada com amostragem PPO/BoN downstream.
— Nathan Lambert (@natolambert) 2 de junho de 2025
Feliz escalada!
Parabéns enormes a @saumyamalik44 que liderou o projeto com total compromisso com a excelência. https://t.co/c0b6rHTXY5
Insights sobre o Desempenho dos Modelos
Com o RewardBench 2, o Ai2 testou modelos existentes e recém-treinados, incluindo variantes de Gemini, Claude, GPT-4.1 e Llama-3.1, ao lado de conjuntos de dados e modelos como Qwen, Skywork e Tulu.
As descobertas mostraram que modelos de recompensa maiores se destacam devido a modelos de base mais fortes. Variantes do Llama-3.1 Instruct lideraram o benchmark, com dados do Skywork ajudando no foco e segurança, e o Tulu performando bem em factualidade.
O Ai2 observou que, embora o RewardBench 2 avance na avaliação multidomínio focada em precisão para modelos de recompensa, ele deve principalmente orientar as empresas na seleção de modelos mais adequados às suas necessidades específicas.










 Claude Opus 4.7 é lançado com a confiabilidade em detrimento da inteligência
A Anthropic manteve um ritmo acelerado este ano, lançando novos recursos quase a cada dois dias. O tão aguardado Claude Opus 4.7 acaba de ser lançado oficialmente e, curiosamente, a Anthropic foi dire
Claude Opus 4.7 é lançado com a confiabilidade em detrimento da inteligência
A Anthropic manteve um ritmo acelerado este ano, lançando novos recursos quase a cada dois dias. O tão aguardado Claude Opus 4.7 acaba de ser lançado oficialmente e, curiosamente, a Anthropic foi dire
 A Haier lança o robô exoesqueleto esportivo com IA mais leve do mundo, pesando apenas 1,75 kg
O Grupo Haier apresentou o robô exoesqueleto com inteligência artificial mais leve do mundo para esportes — o Haier Exoskeleton Robot W3. Este lançamento estabelece um novo recorde do setor em termos
A Haier lança o robô exoesqueleto esportivo com IA mais leve do mundo, pesando apenas 1,75 kg
O Grupo Haier apresentou o robô exoesqueleto com inteligência artificial mais leve do mundo para esportes — o Haier Exoskeleton Robot W3. Este lançamento estabelece um novo recorde do setor em termos
 A primeira série dramática com AIGC da Yaoke Media, “O Mistério do Bronze em Qinling”, estreia hoje com protagonistas criados por IA
Hoje marca o lançamento oficial da minissérie de mistério e fantasia com IA da Yaoke Media, “A História Secreta do Bronze de Qinling”. Estrelada pelos dois primeiros atores de IA contratados pela empr
A primeira série dramática com AIGC da Yaoke Media, “O Mistério do Bronze em Qinling”, estreia hoje com protagonistas criados por IA
Hoje marca o lançamento oficial da minissérie de mistério e fantasia com IA da Yaoke Media, “A História Secreta do Bronze de Qinling”. Estrelada pelos dois primeiros atores de IA contratados pela empr

Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

Como usuario que solo tiene conocimientos básicos, elegir el modelo adecuado es un dolor de cabeza. Este artículo menciona problemas prácticos que son ciertos; a veces, el modelo parece brillar en la prueba, pero en la práctica simplemente falla. Me pregunto si el RewardBench actualizado ayuda a predecir cuándo un modelo se 'descompone' de manera realista. Si las empresas confían demasiado en las métricas, podrían terminar con un fiasco en producción 😅. ¿Habrá herramientas más accesibles para los equipos pequeños?
この記事、実運用でのAIモデルの難しさをしっかり分析してますね。特にリアルワールドでの性能評価の課題は興味深い。AI導入が進む中で、本当に役立つモデル選びができる企業が勝ち残るのかも。ユーザー体験を考えると、ベンチマークだけで選ぶのは危険かもしれない... 😅
C'est intéressant, mais j'aimerais voir plus d'exemples concrets sur comment évaluer la performance des modèles en situation réelle. Parfois les benchmarks ne reflètent pas la complexité du terrain 😅













